Sharing Database Connections
When you begin writing data access code for the middle tier, you'll notice a few things that are very different from writing data access code for a two-tier desktop application. You should know what database connection pooling is, how it works, and how it changes the way you should write data access code. This section will discuss the best way to design and write your ADO code when deploying middle-tier objects in the presence of OLE-DB connection pooling.
Why Do You Need Database Connection Pooling?
Establishing a database connection usually requires effort on the part of two computers. The client must pass the user's credentials to the database management system (DBMS), and the DBMS must verify the user's identity and return a handle back to the client. This requires network round-trips and processing cycles on both computers. The idea behind database connection pooling is simple: Because a connection is relatively expensive to open, an application can scale to accommodate more users if it can cache these connections and share them across multiple clients.
In a two-tier application, each client computer must establish its own connection to the DBMS, as shown in Figure 7-9. The fact that each client application runs in a separate process on a different machine makes it impossible to share connections. In this type of application, a database connection is often established when the user launches the client application and the connection is held open until the application terminates.
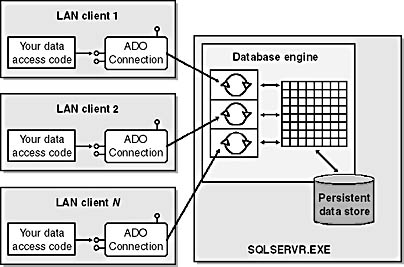
Figure 7-9 In a two-tier application, each client must establish its own connection to the DBMS. Because each client application runs on a separate computer, there's no opportunity for sharing connections across users.
In an attempt to conserve server-side resources, the designer of a two-tier application might decide to close a client's connection whenever the user allows 10 minutes to pass without any activity requiring access to the database. After the connection is closed, the user might issue a command to access the database. In such a case, the client application can transparently reestablish another connection. This approach allows the system as a whole to accommodate more users, but each user experiences a delay each time a new connection must be established with the DBMS.
The architecture for a three-tier application offers several advantages over that of a two-tier application. One significant benefit is the ability to share database connections. As clients submit requests from the presentation tier, objects running on behalf of many different users all use a common set of preopened connections. This sharing makes it possible to scale to levels that aren't possible in a two-tier application.
Figure 7-10 shows the high-level architecture of a three-tier application that uses database connection pooling. When you build this style of application, the use of connection pooling makes your code run faster and allows more users to get by on far fewer database connections. The best news of all is that you don't have to write the code to share and manage database connections across users. It's already built into OLE-DB and ODBC. As long as your OLE-DB providers and ODBC drivers support this feature, your ADO code can benefit from it automatically whenever it runs in a middle-tier environment such as COM+ or IIS.
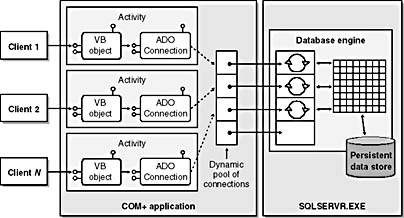
Figure 7-10 In a three-tier application, database connections can be shared. Both ODBC and OLE-DB provide the basis for connection management and automatic connection pooling.
How Does Connection Pooling Work?
Automatic connection pooling has been part of ODBC for a while, but it was not until the release of Microsoft Data Access Components (MDAC) 2 that connection pooling was added to OLE-DB as well. Connection pooling in OLE-DB is enabled by an OLE-DB service component that works with the OLE-DB provider that you use to talk to the DBMS. You simply open and close ADO connections and the connection pooling is conducted for you behind the scenes.
Let's look at an example. Suppose you're working with the native OLE-DB provider for SQL Server (SQLOLEDB). If all your data access code accesses a single database in one computer running SQL Server, OLE-DB can place and manage all your connections in a single pool. The first time an object in a COM+ server application creates a new ADO Connection object and invokes the Open method, OLE-DB must establish an actual connection to the DBMS. However, when you invoke the Close method, OLE-DB does not drop the connection to the DBMS. Instead, the connection is placed in a pool so that it can be used by other objects that need it.
When the code running on behalf of another user invokes the Open method on a second ADO Connection object, OLE-DB looks in the pool to see whether a preexisting connection is available. If it finds an established connection, your application doesn't have to contact the DBMS to establish a new connection. Instead, it can perform its work using the first connection. This speeds things up considerably.
Let's take a moment to consider the limitations of the connection-pooling scheme used by OLE-DB. A connection pool can be used only by objects in the same process. If all your objects run in a single instance of DLLHOST.EXE or INETINFO.EXE, they can all share the same pool.
You should also note that every connection in a pool must be associated with the same OLE-DB provider, server computer, database, user ID, and password. If your application is connecting to both SQL Server and ORACLE, OLE-DB maintains a separate pool for each DBMS. Likewise, you must use the same user ID and password to place all your connections in the same pool. If you want every object in a server application to use a single pool of connections, every component must use the same connect string.
When all the connections from the pool are in use and a client calls a method to open another connection, OLE-DB establishes a new connection with the DBMS. This allows the pool to grow dynamically. OLE-DB also places a timeout interval on each connection in the pool. OLE-DB automatically closes a connection that remains idle for more than 60 seconds. This allows the pool to shrink back to a more efficient size when a peak traffic time is followed by a time with lower activity.
You should also be aware that trappable ADO errors can occur when the DBMS reaches its maximum number of connections. You're on your own because neither OLE-DB nor ADO helps you handle the errors that are raised because of this problem. If SQL Server is configured to allow 50 connections and the connection-pooling scheme attempts to open the fifty-first connection, for example, your ADO code will experience an error in the call to Open. You must write contingency code to deal with this. One way to handle this error is to reattempt opening the connection another few times. The ultimate solution usually involves getting the database administrator to reconfigure the DBMS to allow for a larger number of connections.
There's another important limitation related to this database connection-pooling scheme. What happens if your COM+ application has a pool of 10 connections and the computer running the SQL Server database gets rebooted? Every connection in the pool is unusable. Should you shut down a COM+ server application when the database is restarted? This isn't an elegant solution, but many companies deal with the problem in this way.
Taking Advantage of Database Connection Pooling
So maybe writing data access code isn't as straightforward as you might have thought. A call to the Close method doesn't really mean close; it means release the connection back into the pool. Moreover, a call to Open doesn't really mean open—it means acquire a connection from the pool. As you've seen, a call to Open can result in growing the pool by one if all the existing connections are already in use.
Your objects should never be selfish with a database connection. The most important habit to get into is to acquire connections late and release them early. The sooner your objects release their connections, the greater chance that each object can acquire an existing connection in the pool. However, if your objects hold onto connections longer than necessary, your application might establish extra connections that it doesn't need. This will penalize you in terms of performance and resource usage.
You should design your components to acquire and release connections on a per-method basis. Here's a good starting point for a method that contains data access code:
Sub MyMethod() Dim conn As ADODB.Connection Set conn = New ADODB.Connection conn.Open sConnect ' (1) establish connection ' Your code goes here. (2) conduct read/write operations conn.Close ' (3) close connection Set conn = Nothing End Sub |
Declaring your ADO connection objects in the declaration section of your class modules typically doesn't help your design and can get you in trouble. In a COM+ application, your ADO Connection objects should always be closed at the end of each request. If you rely on Class_Initialize and Class_Terminate to open and close a class-level ADO Connection object, you'll likely hold onto connections longer than you need to. Look at the following class definition for the component CCustomerManager:
' Class CCustomerManager Private conn As ADODB.Connection Sub Class_Initialize() Set conn = New ADODB.Connection conn.Open sConnect End Sub Sub AddCustomer(ByVal Customer As String) ' Code to add new customer record using conn End Sub Sub Class_Terminate() conn.Close Set conn = Nothing End Sub |
CCustomerManager acquires a connection when it's created and releases the connection upon termination. The client code to use this component looks something like this:
Dim CustMgr As CCustomerManager Set CustMgr = New CCustomerManager CustMgr.AddCustomer "Bob" Set CustMgr = Nothing |
The problem with this approach is that connections are held open while you're waiting for the Visual Basic runtime to create and tear down objects. The connection is held longer than it needs to be. What's more, if the client forgets to set the CCustomerManager object equal to Nothing, it takes the Visual Basic garbage collector even longer to close the connection. Forgetting to set your objects equal to Nothing also exposes you to other problems in which objects aren't shut down properly. You're better off opening and closing your connections in methods that are explicitly called by the client.
Now imagine what would happen if you had a second component, CProductManager, that was similar to the CCustomerManager component and the client wrote code that looked like this:
Dim CustMgr As CCustomerManager Set CustMgr = New CCustomerManager CustMgr.AddCustomer "Bob" Dim ProdMgr As CProductManager Set ProdMgr = New CProductManager ProdMgr.AddProduct "Dog" |
This code has problems because it attempts to acquire a second connection before releasing the first connection within the scope of a single client request. This code requires two connections when it could get by with one.
During the design phase, you might occasionally encounter a situation in which it's acceptable to declare an ADO Connection object in the declaration section of a class module. This might be the case if you need to call multiple data access methods on one object in a single request. For example, the client might need to call the AddCustomer method multiple times and you don't want to keep releasing and reacquiring a connection from the pool in a single request. Look at the following class definition of the CCustomerManager class and note the addition of two new methods:
' Class CCustomerManager Private conn As ADODB.Connection Sub AcquireConnection() Set conn = New ADODB.Connection conn.Open sConnect End Sub Sub AddCustomer(ByVal Customer As String) ' Assume that AcquireConnection has been called. ' Code to add new customer record using conn End Sub Sub ReleaseConnection() conn.Close Set conn = Nothing End Sub |
To use this new design, the client must explicitly call methods to acquire and release the connection. The client code is rewritten to look like this:
Dim CustMgr As CCustomerManager Set CustMgr = New CCustomerManager CustMgr.AcquireConnection CustMgr.AddCustomer "John" CustMgr.AddCustomer "Paul" CustMgr.AddCustomer "George" CustMgr.AddCustomer "Ringo" CustMgr.ReleaseConnection Set CustMgr = Nothing |
As you can see, this design puts the responsibility on the client to do the right thing. Lots of programmers dream of a world in which objects can always take care of themselves. They feel that this is something that has been promised to them by object-oriented programming languages. They reason that an object should be able to transparently acquire and release its own resources. Unfortunately, this practice doesn't result in the most efficient code. The examples I've just shown you clearly demonstrate otherwise. You should open and close connections on a per-method basis or you should expect your designs to take on more complexity.
As you move into more complex designs, it's up to you to release database connections as quickly as possible once you acquire them from the pool. This usually requires more attention to detail and well thought-out collaboration between the objects in your application.
EAN: 2147483647
Pages: 70
- Article 110 Requirements for Electrical Installations
- Article 285 Transient Voltage Surge Suppressors (TVSSs)
- Article 314 Outlet, Device, Pull, and Junction Boxes; Conduit Bodies; Fittings; and Handhole Enclosures
- Notes to Tables
- Example No. D8 Motor Circuit Conductors, Overload Protection, and Short-Circuit and Ground-Fault Protection