The Birth of COM
The seeds of COM were planted in 1988, when several teams at Microsoft began to build object-oriented infrastructures that provided reuse based on components. When a group of engineers from various teams were assembled with the Microsoft Office team to help out on the OLE2 project, they decided that they needed to draft a few high-level requirements for the new architecture they would be building.
These engineers came up with four high-level requirements for their new component architecture. First, the architecture had to be based on binary reuse because maintaining and enhancing code in large, monolithic applications causes too many problems. Systems based on binary components are much easier to assemble, maintain, and extend.
Second, the architecture had to be based on an object-oriented paradigm. Most of the binary reuse in Microsoft Windows had been based on traditional DLLs, which don't commonly include object-oriented extensions. This type of binary reuse can't benefit from the encapsulation that can be achieved with a class-based design.
Third, the architecture had to be language-independent. It would be far more powerful if each component author could select a language independently of other component authors. Every programming language requires programmers to make trade-offs in productivity, flexibility, and performance. The ability to choose a language on a component-by-component basis offers many advantages over having to use a single language for an entire application.
Finally, the architecture had to address interprocess communication. It was essential to compose systems of clients and objects that ran on different machines so that the architecture could be a foundation for distributed technologies. The engineers also knew that if they could hide the details of interprocess communication from the majority of programmers, their architecture would foster much higher productivity.
The efforts of these engineers debuted in production code with Microsoft's second major release of Object Linking and Embedding (OLE), a technology that allows users to link documents produced in one application with documents produced in another application. OLE requires interprocess communication among applications. The original version of OLE was based on an interprocess mechanism called Dynamic Data Exchange (DDE). This initial release was plagued with resource and performance problems, which resulted in limited acceptance within the industry. Microsoft knew that OLE's features were valuable conceptually but that making this technology usable in a production environment would mean optimizing the underlying infrastructure. In essence, OLE needed a whole new plumbing system to be viable.
OLE2 shipped with the first generation of COM in 1993. OLE and COM are distinct entities: OLE is a technology for linking and embedding documents, while COM is an architecture for building component-based systems. Unfortunately, these two technologies have a history of being confused as one and the same. As fate would have it, COM has become far more important than OLE, the technology it was created to assist.
Creating Binary Components with C++
The COM architects designed a way to compose applications based on components built into separate binary files. However, this was no easy undertaking. They had to make some tough decisions along the way. One of the most significant decisions was that client code could not be written using class-based references. The coupling that would occur would be far too damaging. It was obvious that this new object model would have to be based on a formal separation of interface from implementation.
Long before any Visual Basic or Java programmer used keywords such as Implements and interface, the C++ community was building applications using the principles of interface-based programming. Although the C++ language has no direct support for this style of programming, you can create abstract data types (interfaces) using advanced features of the language. A C++ class can define a set of method signatures without implementation. This is what is known as an abstract base class. In just a bit, you'll see what one of these looks like, but first let's examine why these C++ developers needed abstract base classes in the first place.
C++ has a very serious shortcoming when it comes to building component-based applications: It doesn't support encapsulation at the binary level. This can be traced back to the fact that the language was designed to build monolithic applications. When a C++ class author marks a data member as private, it's off-limits to client code, as you'd expect. However, this encapsulation is enforced only in the syntax of the language. Any client that calls New on a class must have knowledge of the object's data layout. The client is responsible for allocating the memory in which the object will run. This means that the client must have knowledge of each data member for a class regardless of whether it's marked public, protected, or private.
These layout dependencies aren't a problem in a monolithic application because the client always recompiles against the latest version of the class. But in component-based development, this is a huge problem. The layout of a class within a DLL can't change without breaking all the clients that use it. The following C++ code shows a client and two versions of a class in a DLL.
// In SERVER.DLL - Version 1 // Each object will require 8 bytes of memory. class CDog { public: void Bark(){ /* implementation */ } void RollOver(int Rolls){ /* implementation */ } private: double Weight; }; // In CLIENT.EXE // Compiled against Version 1 of DLL // Client allocates 8 bytes for object. CDog* pDog = new CDog; // In SERVER.DLL - Version 2 // Each object will require 16 bytes of memory. // Replacing older DLL will break client. class CDog { public: void Bark(){ /* implementation */ } void RollOver(int Rolls){ /* implementation */ } private: double Weight; double Age; }; |
When the first version of the DLL is replaced in the field by the second version, a big problem arises. The client application continues to create objects that are 8 bytes in size, but each object thinks that it's 16 bytes. This is a recipe for disaster. For example, let's say you've rewritten the implementation of Bark in version 2 to access the Age property to determine the intensity of the dog's bark. The newer version of the object will try to access memory that it doesn't own, and the application will likely fail in strange and mysterious ways. The only way to deal with this is to rebuild all client applications whenever the object's data layout changes. This eliminates one of the biggest benefits of component-based development: the ability to modify one binary file without touching any of the others.
How can you replace the DLL without breaking any of the client applications that use it? The object's data layout must be hidden from the client. The client must also be relieved of the responsibility of calling the C++ New operator across a binary firewall. Some other agent outside the client application must take on the responsibility of creating the object.
It all boils down to this: the C++ language is broken. Its creators never intended it to be used for building component-based applications. Fortunately, C++ programmers are the smartest programmers in the industry. (Just ask any of them—they'll be happy to verify this fact.) They discovered that abstract base classes make it possible to separate interface from implementation. Abstract base classes allow C++ programmers to build client applications without any layout dependencies on the concrete classes they're using. This, in turn, makes it possible for class authors to freely change their layout details from version to version.
Abstract base classes as interfaces
In C++, an abstract base class is used to define method signatures that don't include any implementation. Here's an example of what an abstract base class looks like in C++:
class IDog { virtual void Bark() = 0; virtual void RollOver(int Rolls) = 0; }; |
A C++ member function (a method) that's marked with =0 is a pure virtual function. This means that it doesn't include an implementation. It also means that the class that defines it isn't a creatable type. Therefore, the only way to use an abstract base class is through inheritance, like this:
class CBeagle : public IDog { virtual void Bark() {/* Implementation */} virtual void RollOver(int Rolls) {/* Implementation */} }; |
C++ programmers who use abstract base classes and a little extra discipline can achieve the reusability, maintainability, and extensibility benefits that we covered in Chapter 2. The extra discipline is required to avoid any definition of data storage or method implementation inside an abstract base class. As a result, an abstract base class can formalize the separation of interface from implementation. A C++ client application can communicate with a CBeagle object through an IDog reference, which allows the client application to avoid building any layout dependencies on the CBeagle class.
You should see that a C++ abstract base class is being used as a logical interface. Even though C++ has no formal support for interface-based programming, advanced techniques in C++ allow you to reap the most significant benefits of interfaces. In fact, C++ programmers pioneered the concept of interface-based programming by using abstract base classes in large component-based applications. This technique has been used in numerous projects and is well described in Large-Scale C++ Software Design by John S. Lakos (Addison-Wesley, 1996). The principles of interface-based programming as implemented in C++ have had a profound effect on the development of COM.
The vTable as a Standard In-Memory Representation
The creators of COM concluded that if they used abstract base classes, they could achieve object-oriented binary reuse. DLLs could hold concrete class definitions. Client applications could use objects created from these DLLs as long as they communicated through abstract base classes. DLLs could be revised and replaced in the field without adversely affecting existing client applications. Arriving at this series of conclusions was a big milestone for the Microsoft engineers. They had devised a way to achieve binary reuse in an object-oriented paradigm using C++. They had achieved their first two design goals.
Interface-based programming is founded on the concept of polymorphism. As you remember from the previous chapter, polymorphism is a controlled form of uncertainty whereby the client knows what method to call but doesn't know or care how a particular object might implement it. Any language that supports polymorphism must provide a way to dynamically bind a client to any one of many possible implementations. As long as the client has been programmed against a well-known interface, an application can plug in any type-compatible object at runtime.
Different languages and compilers approach the requirement of dynamic binding in different ways. Because of its low-level nature, C++ happens to have one of the fastest binding techniques available. Dynamic binding in C++ is based on a highly efficient dispatching architecture that relies on the use of virtual functions.
The C++ compiler and linker make dynamic binding possible by generating an array of function pointers called a vTable. (The v stands for virtual.) This array of function pointers represents a set of entry points into an object. Each method defined in an abstract base class gets an associated pointer in the vTable. As long as the client knows the calling syntax of a particular method and acquires the appropriate function pointer, it can access the object without any knowledge of the concrete class from which it was created.
At this point, the COM architects made another significant decision. They decided to use C++-style vTables as the standard in-memory representation for all client-object communication. All COM objects must expose their method implementations through vTables. All clients must bind to vTables and invoke methods through the use of these function pointers. This is what's known as direct vTable binding.
Figure 3-1 shows what a vTable looks like. It's basically the same in both C++ and in COM. A vTable is a standard in-memory representation that both an object and a client agree on. On the right side of the figure is a logical view of a COM client accessing a COM object. Each lollipop represents an interface that the COM object supports. Note that an object can support multiple interfaces. An object must expose a separate vTable for each interface it implements.
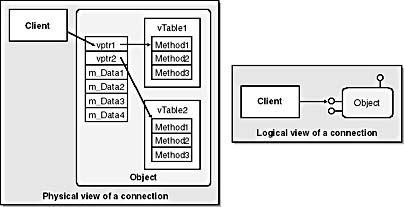
Figure 3-1 In both C++ and COM, clients are dynamically bound to objects through the use of vTables. Each physical vTable represents a logical interface implemented by the object.
Sometime after the completion of the OLE2 project, several of the engineers who designed the COM architecture drafted a specification for what they had done. This document, known as the COM Specification, defines the rules for COM programming. It also defines much of the important terminology.
COM objects are instantiated from COM-compliant classes known as coclasses. A coclass is a concrete implementation of one or more interfaces. You should note that the terms coclass and component can be used interchangeably. A component is a creatable data type from which a client creates objects. In practice, you'll create a MultiUse class for each component you want to produce.
Coclasses are compiled into and deployed in binary files called servers. In addition to containing the implementation code for one or more coclasses, a server must also support COM's infrastructure for object activation. As you'll see, a server does this by exposing well-known entry points.
Some people use the term component to mean a physical file, such as an ActiveX DLL, but I define a component as a creatable class compiled into a server. The ActiveX DLL is the server, not the component. To illustrate the potential confusion, answer the following question: If you compile two MultiUse classes into one ActiveX DLL, do you have one component or two? I'd say you have two. Others would say you have one. You should realize that there's no consistency with this issue. In this book, the terms component, coclass, and concrete class all mean the same thing. It's what you use to create an object. This usage is consistent with the programming models of MTS and COM+.
EAN: 2147483647
Pages: 70