HTTP
| < Day Day Up > |
The Hypertext Transfer Protocol (HTTP) is the basic, underlying, application-level protocol used to facilitate the transmission of data to and from a Web server. HTTP provides a simple, fast way to specify the interaction between client and server. The protocol actually defines how a client must ask for data from the server and how the server returns it. HTTP does not specify how the data actually is transferred; this is up to lower-level network protocols such as TCP.
The first version of HTTP, known as version 0.9, was used as early as 1990. HTTP version 1.0 as defined by RFC 1945, is supported by most servers and clients (Web browsers). However, HTTP 1.0 does not properly handle the effects of hierarchical proxies and caching, or provide features to facilitate virtual hosts . More important, HTTP 1.0 has significant performance problems due to the opening and closing of many connections for a single Web page.
The current version, HTTP 1.1, solves many of the past problems of the protocol. It is supported by version 4-generation Web browsers and up. There still are many limitations to HTTP, however. It is used increasingly in applications that need more sophisticated features, including distributed authoring, collaboration, multimedia support, and remote procedure calls. Various ideas to extend HTTP have been discussed and a generic Extension Framework for HTTP has been introduced by the W3C. Already, some facilities such as client capability detection and privacy negotiation between browser and server have been implemented on top of HTTP, but most of these protocols are still being worked out. For now, HTTP continues to be fairly simple, so this discussion will focus on HTTP 1.0 and 1.1.
HTTP Requests
The process of a Web browser or other user agent ¾ such as Web spider or Robot ¾ requesting a document from a Web (or more correctly HTTP) server is simple, and has been discussed throughout the book. The overall process was diagrammed in Figure 16-3. In the figure, the user first requests a document from a Web server by specifying the URL of the document desired. During this step, a domain name lookup may occur, which translates a machine name such as www.democompany.com to an underlying IP address such as 206.251.142.3. If the domain name lookup fails, an error message such as "No Such Host" or "The server does not have a DNS entry" will be returned. Certain assumptions, such as the default service port to access for HTTP requests (80), also might be made. This is transparent to the user, who simply uses a URL to access a page. Once the server has been located, the browser forms the proper HTTP request and sends the request to the server residing at the address specified by the URL. A typical HTTP request consists of the following:
HTTP-Method Identifier HTTP-version <Optional additional request headers>
In this example, the HTTP-Method would be GET or POST . An identifier might correspond to the file desired (for example, /examples/Chapter16/report.htm), and the HTTP-version indicates the dialect of HTTP being used, such as HTTP/1.0.
If a user requests a document with the URL http://www.htmlref.com/examples/chapter15/report.htm, the browser might generate a request such as the one shown here to retrieve the object from the server at www.htmlref.com:
GET /examples/chapter16/report.htm HTTP/1.0 If-Modified-Since: Tuesday, 15-Aug-00 01:39:39 GMT; Connection: Keep-Alive User-Agent: Mozilla/4.02 [en] (X11; I; SunOS 5.4 sun4m) Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */* Accept-Language: en Accept-Charset: iso-8859-1,*,utf-8
People often ask why the complete URL is not shown in the request. It isn't necessary in most cases, except when using a proxy server. The use of a relative URL in the header is adequate. The server knows where it is; it just needs to know what document to get from its own file tree. In the case of using a proxy server, which requests a document on behalf of a browser, a full URL is passed to it that later is made relative by the proxy. Aside from the simple GET method, there are various other methods specified in HTTP. Not all are commonly used. Table 16-3 provides a summary of the HTTP 1.1 request methods .
| Method | Description |
|---|---|
| GET | Returns the object specified by the identifier. Notice that it also is one of the values of the method attribute for the form element. |
| HEAD | Returns information about the object specified by the identifier, such as last modification data, but does not return the actual object. |
| OPTIONS | Returns information about the capabilities supported by a server if no location is specified, or the possible methods that can be applied to the specified object. |
| POST | Sends information to the address indicated by the identifier; generally used to transmit information from a form using the method="POST" attribute of the form element to a server-based CGI program. |
| PUT | Sends data to the server and writes it to the address specified by the identifier overwriting previous content, in basic form. This method can be used for file upload. |
| DELETE | Removes the file specified by the identifier; generally disallowed for security reasons. |
| TRACE | Provides diagnostic information by allowing the client to see what is being received on the server. |
It is interesting to note that two of the methods ( GET and POST ) supported by HTTP are the values of the form element's method attribute. Recall that this attribute indicates the method in which data is passed from the form to the server-side program. In the case of GET , it is passed through the URL because another page is simply being fetched , as a normal GET request would do. In the case of a POST value, the data of the form is passed behind the scenes to the server program that should return a result page to the browser as well. This is discussed in Chapters 12 and 13 and, as shown by the form element, it should become clear that HTML and HTTP do interact in more than a casual way.
HTTP Request Headers
Within an HTTP request, there are a variety of optional fields for creating a complete request. The fields are specified by a header name, a colon and then a value. A user agent generally sends extra header information in a request indicating the type of device making the request (user-agent), the type of data it prefers (accept), what language is in use (accept-language), and so on. The value of this header information should not be understated. With it, your server side programs can detect things such as the browser being used, the particular types of images supported by the browser, the language of the browser such as French, English, or Japanese, and so on. The common request headers and an example for each are shown in Table 16-4.
| Request Header | Description | Example |
|---|---|---|
| Accept: MIME-type/MIME-subtype | Indicates the data types accepted by the browser. An entry of */* indicates anything is accepted; however, it is possible to indicate particular content types such as image/jpeg so the server can make a decision on what to return. This facility could be used to introduce a form of content negotiation so that a browser could be served only data it understands or prefers. Apache provides this feature and IIS can be extended to provide this feature as well, but at the time of this edition's writing this concept is not widely understood or implemented by Web developers. | Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */* |
| Accept-Charset: | Indicates the character set that is accepted by the browser, such as ASCII or foreign character encodings. | Accept-Charset: iso-8859-1,*,utf-8 |
| Accept-Encoding: encoding-type | Instructs the server on what type of encoding the browser understands. Typically, this field is used to indicate to the server that compressed data can be handled. | Accept-Encoding: x-compress |
| Accept-Language: language-code | Lists the languages preferred by the browser and could be used by the server to pass back the appropriate language data. | Accept-Language: en |
| Authorization: authorization-scheme authorization-data | This header typically is used to indicate the userid and encrypted password if the user is returning authorization information. | Authorization: user joeblow:testpass |
| Content-length: | Gives the length in bytes of the message being sent to the server, if any. Remember that the browser can upload or pass data using the PUT or POST method. | Content-length: 1805 |
| Content-type : | Indicates the MIME type of a message being sent to a server, if any. The value of this field would be particularly important in the case of file upload. | Content-type: text/plain |
| Date: date-time | Indicates the date and time that a request was made in Greenwich Mean Time (GMT). GMT time is mandatory for time consistency, given the worldwide nature of the Web. | Date: Thursday, 15-Jan-98 |
| Host: hostname | Indicates the host and port of the server to which the request is being made. It is extremely important in a server that is running many domain names at once in the form of virtual servers. | Host: www. democompany.com |
| If-Modified-Since: | This field indicates file freshness to improve the efficiency of the GET method. When used in conjunction with a GET request for a particular file, the requested file is checked to see if it has been modified since the time specified in the field. If the file has not been modified, a 'not modified' code (304) is sent to the client so a cached version of the document can be used; otherwise , the file is returned normally. | If-Modified-Since: Thursday, 15-Jan-98 01:39:39 GMT |
| If-Match: | This field makes a request conditionally only if the items match some selector value passed in. Imagine only using POST to add data once it has been moved to a file called olddata. | If-Match: 'olddata' |
| If-None-Match: | This field does the opposite of If-Match . The method is conditional only if the selector does not match anything. This might be useful for preventing overwrites of existing files. | If-None-Match: 'newfile' |
| If-Range: | If a client has a partial copy of an object in its cache and wishes to have an up-to-date copy of the entire object there, it could use the Range request header with this conditional If-Range modifier to update the file. Modification selection can take place on time as well. | If-Range: Thursday, 15-Jan-98 01:39:39 GMT; |
| If-Unmodified-Since: date-time | If the requested file has not been modified since the specified time, the server should perform the requested method; otherwise, the method should fail. | If-Unmodified-Since: Thursday, 15-Jan-98 01:39:39 GMT |
| Max-Forwards: | Indicates the limit of the number of proxies or gateways that can forward the request. Often ignored in practice. | Max-Forwards: 6 |
| MIME-version: version-number | This field indicates the MIME protocol version understood by the browser that the server should use when fulfilling requests. | MIME-Version: 1.0 |
| Proxy-Authorization: authorization | Allows the client to identify itself or the user to a proxy that requires authentication. | Proxy-Authorization: joeblow: testpass; Realm: All |
| Pragma: | Passes information to a server; for example, this field can be used to inform a caching proxy server to fetch a fresh copy of a page. | Pragma: no-cache |
| Range: byte-range | Indicates a request for a particular range of a file such as a certain number of bytes. The example shows a request for the last 500 bytes of a file. | Range: bytes=-500 |
| Referer: URL | This field indicates the URL of the document from which the request originates (in other words, the linking document). This value might be empty if the user has entered the URL directly rather than by following a link. | Referer: http://www. democompany.com/ reports /index.html |
| User-Agent: | This field indicates the type of browser making the request. Very useful for browser detection but may be falsified. | User-Agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows 98) |
| Note | The request headers seem very familiar because they constitute the same environment variables that you can access from within a server-side program. Now it should be clear how this information is obtained. |
HTTP Responses
After receiving a request, the Web server attempts to process the request. The result of the request is indicated by a server status line that contains a response code; for example, the ever popular "404 Not Found." The server response status line takes this form:
HTTP-version Status-code Reason-String
For a successful query, a status line might read as follows :
HTTP/1.0 200 OK
whereas in the case of an error, the status line might read:
HTTP/1.0 404 Not Found
The status codes for the emerging HTTP 1.1 standard are shown in Table 16-5.
| Status-Code | Reason-String | Description |
|---|---|---|
| Informational Codes (Process Continues After This) | ||
| 100 | Continue | An interim response issued by the server that indicates the request is in progress but has not been rejected or accepted. This status code is in support of the persistent connection idea introduced in HTTP 1.1. |
| 101 | Switching Protocols | Can be returned by the server to indicate that a different protocol should be used to improve communication. This could be used to initiate a real-time protocol. |
| Success Codes (Request Understood and Accepted) | ||
| 200 | OK | Indicates the successful completion of a request. |
| 201 | Created | Indicates the successful completion of a PUT request and the creation of the file specified. |
| 202 | Accepted | This code indicates that the request has been accepted for processing, but that the processing has not been completed and the request might or might not actually finish properly. |
| 203 | Non-Authoritative Information | Indicates a successful request, except that returned information, particularly meta-information about a document, comes from a third source and is unverifiable. |
| 204 | No Content | Indicates a successful request, but there is no new data to send to the client. |
| 205 | Reset Content | Indicates that the client should reset the page that sent the request ( potentially for more input). This could be used on a form page that needs consistent refreshing, rather than reloading as might be used in a chat system. |
| 206 | Partial Content | Indicates a successful request for a piece of a larger document or set of documents. This response typically is encountered when media is sent out in a particular order, or byte-served, as with streaming Acrobat files. |
| Redirection Codes (Further Action Necessary to Complete Request) | ||
| 300 | Multiple Choices | Indicates that there are many possible representations for the requested information, so the client should use the preferred representation, which might be in the form of a closer server or different data format. |
| 301 | Moved Permanently | Requested resource has been assigned a new permanent address and any future references to this resource should be done using one of the returned addresses. |
| 302 | Moved Temporarily | Requested resource temporarily resides at a different address. For future requests, the original address should still be used. |
| 303 | See Other | Indicates that the requested object can be found at a different address and should be retrieved using a GET method on that resource. |
| 304 | Not Modified | Issued in response to a conditional GET; indicates to the agent to use a local copy from cache or similar action as the request object has not changed. |
| 305 | Use Proxy | Indicates that the requested resource must be accessed through the proxy given by the URL in the Location field. |
| Client Error Codes (Syntax Error or Other Problem Causing Failure) | ||
| 400 | Bad Request | Indicates that the request could not be understood by the server due to malformed syntax. |
| 401 | Unauthorized | Request requires user authentication. The authorization has failed for some reason, so this code is returned. |
| 402 | Payment Required | Obviously in support of commerce, this code is currently not well-defined . |
| 403 | Forbidden | Request is understood but disallowed and should not be reattempted, compared to the 401 code, which might suggest a reauthentication. A typical response code in response to a query for a directory listing when directory browsing is disallowed. |
| 404 | Not Found | Usually issued in response to a typo by the user or a moved resource, as the server can't find anything that matches the request nor any indication that the requested item has been moved. |
| 405 | Method Not Allowed | Issued in response to a method request such as GET , POST , or PUT on an object where such a method is not supported. Generally an indication of what methods that are supported will be returned. |
| 406 | Not Acceptable | Indicates that the response to the request will not be in one of the content types acceptable by the browser, so why bother doing the request? This is an unlikely response given the */* acceptance issued by most, if not all, browsers. |
| 407 | Proxy Authentication Required | Indicates that the proxy server requires some form of authentication to continue. This code is similar to the 401 code. |
| 408 | Request Time-out | Indicates that the client did not produce or finish a request within the time that the server was prepared to wait. |
| 409 | Conflict | The request could not be completed because of a conflict with the requested resource; for example, the file might be locked. |
| 410 | Gone | Indicates that the requested object is no longer available at the server and no forwarding address is known. Search engines might want to add remote references to objects that return this value because it is a permanent condition. |
| 411 | Length Required | Indicates that the server refuses to accept the request without a defined Content-Length. This might happen when a file is posted without a length. |
| 412 | Precondition Failed | Indicates that a precondition given in one |
| 413 | Request Entity | Indicates that the server is refusing to return data because the object might be too large or the server might be too loaded to handle the request. The server also might provide information indicating when to try again, if possible, but just as well might terminate any open connections. |
| 414 | Request-URI Too Large | Indicates that the Uniform Resource Identifier (URI), generally a URL, in the request field is too long for the server to handle. This is unlikely to occur as browsers probably will not allow such transmissions. |
| 415 | Unsupported Media Type | Indicates the server will not perform the request because the media type specified in the message is not supported. This code might be returned when a server receives a file that it is not configured to accept using the PUT method. |
| Server Error Codes (Server Can't Fulfill a Potentially Valid Request) | ||
| 500 | Internal Server Error | A serious error message indicating that the server encountered an internal error that keeps it from fulfilling the request. |
| 501 | Not Implemented | This response is to a request that the server does not support or might be understood but not implemented. |
| 502 | Bad Gateway | Indicates that the server acting as a proxy encountered an error from some other gateway and is passing the message along. |
| 503 | Service Unavailable | Indicates the server currently is overloaded or is undergoing maintenance. Headers can be sent to indicate when the server will be available. |
| 504 | Gateway Time-out | Indicates that the server, when acting as a gateway or proxy, encountered too long a delay from an upstream proxy and decided to time out. |
| 505 | HTTP Version | Indicates that the server does not support the HTTP version specified in the request. |
After the status line, the server responds with information about itself and the data being returned. There are various selected response headers, but the most important indicates the type of data in the form of a MIME-type and subtype that will be returned. Like request headers, many of these codes are optional and depend on the status of the request.
An example server response for the request shown earlier in the chapter (see "HTTP Requests") follows:
HTTP/1.1 200 OK Date: Wed, 20 Sep 2000 18:59:54 GMT Server: Apache/1.3.12 (Unix) Last-Modified: Fri, 25 Aug 2000 22:19:12 GMT Accept-Ranges: bytes Content-Length: 205 Connection: close Content-Type: text/html <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" lang="en"> <head> <title> Report 1 </title> <meta http-equiv="content-type" content="text/html; charset=ISO-8859-1" /> </head> <body> <h1> Report About Important Things </h1> <hr /> <p> Here is some information about important things. </p> </body> </html>
A list of the common server response headers for HTTP 1.1, as well as examples of each, can be found in Table 16-6.
| Response Header | Description | Example |
|---|---|---|
| Age | Shows the sender's estimate of the amount of time since the response was generated at the origin server. Age values are nonnegative decimal integers, representing time in seconds. | Age: 10 |
| Content-encoding | Indicates the encoding the data returned is in. | Content-encoding: x-compress |
| Content-language | Indicates the language used for the data returned by the server. | Content-language: en |
| Content-length | Indicates the number of bytes returned by the server. | Content-length: 205 |
| Content-range | Indicates the range of the data being sent back by the server. | Content-range: -500 |
| Content-type | This probably is the most important field and indicates what type of content is being returned by the server in the form of a MIME type. | Content-type: text/html |
| Expires | Gives the date/time after which the returned data should be considered stale and should not be returned from a cache. | Expires: Thu, 04 Dec 1997 16:00:00 GMT |
| Last-modified | The Last-Modified response-header field is used to indicate the date the content returned was last modified. This can be used by caches to decide to keep local copies of objects. | Last-modified: Thursday, 01-Aug-96 10:09:00 GMT |
| Location | Used to redirect the browser to another page. Occasionally scripts will use this method for browser redirection based on capability. | Location: |
| Proxy-authenticate | Included with a 407 (Proxy Authentication Required) response. The value of the field consists of a challenge that indicates the authentication scheme and parameters applicable to the proxy for the request. | Proxy-authenticate: GreenDecoderRing: 0124. |
| Public | Lists the set of methods supported by the server. The purpose of this field strictly is to inform the browser of the capabilities of the server when new or unusual methods are encountered. | Public: OPTIONS, MGET, MHEAD, GET, HEAD |
| Retry -after | Can be used in conjunction with a 503 (Service Unavailable) response to indicate how long the service is expected to be unavailable to the requesting client. The value of this field can be either an HTTP-date or an integer number of seconds after which to retry. | Retry-after: Fri, 31 Dec 1999 23:59:59 GMT |
| Server | Contains information about the Web software used. | Server: Apache/1.3.12 (Unix) |
| Warning | Used to carry additional information about the status of a response that might not be found in the status code. | Warning: 10 Response is stale |
| WWW-authenticate | Included with a 401 (Unauthorized) response message. The field consists of at least one challenge that indicates the authentication scheme and parameters applicable to the request made by the client. | WWW-authenticate: Magic-Key-Challenge= |
The most important header response field is the Content-type field. The MIME type indicated by this field is a device by which the browser is able to figure out what to do with the data being returned.
MIME
MIME (Multipurpose Internet Mail Extensions) was originally developed as an extension to the Internet mail protocol that allows for the inclusion of multimedia in mail messages. The basic idea of MIME is transmission of text files with headers that indicate binary data that will follow. Each MIME header is composed of two parts that indicate the data type and subtype in the following format:
Content-type: type / subtype
where type can be image, audio, text, video, application, multipart, message, or extension-token; and subtype gives the specifics of the content. Some samples are listed here:
text/html application/x-director application/x-pdf video/quicktime video/x-msvideo image/gif audio/x-wav
In addition to these basic headers, you also can include information such as the character-encoding language. For more information about MIME, refer to RFC 1521, available from many sites including http://www.faqs.org/rfcs/, or the list of registered MIME types at ftp://ftp.isi.edu/in-notes/iana/assignments/media-types/.
When a Web server delivers a file, the header information is intercepted by the browser and questioned. The MIME type, as mentioned earlier, is specified by the Content-type HTTP response field. For example, if a browser receives a basic HTML file, the text/html value in the Content-type header indicates what the browser should do. In most cases, this results in the browser rendering the file in the browser window. To determine what to do with a particular MIME type that has been sent, the browser consults a lookup table mapping MIME types to actions, as shown here:
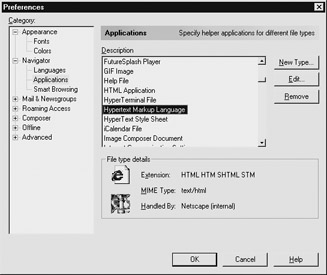
| Note | A lookup table that maps file extensions to outgoing MIME type headers exists on the server as well. |
Notice that in the example, the type is text/html and the actual HTML document is passed back after all the headers are finished. The dialog indicates that the browser itself will handle the file internally. Also notice that the browser indicates that it recognizes the file extensions .html, .htm, .stm, and .shtml as HTML files. However, other file extensions seem to appear as normal HTML when they are viewed online. The MIME type is the key to why a file with an extension such as .cfm, .asp, .jsp, and so on is treated as HTML by a Web browser when delivered over a network, but if opened from a local disk drive is not read properly. These extensions often are associated with dynamically generated pages that are stamped with the HTML MIME type by the server; when reading off the local drive, the browser relies instead on the file extension such as .htm to determine the contents of a file. If a browser attempts to read a file that it is unsure about, either because of file extension or MIME type, it should respond with a dialog box such as the one shown here, as Netscape does.
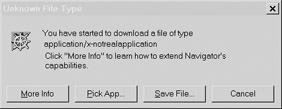
What's very interesting is how Internet Explorer prompts the user to immediately save data if the MIME type is not understood, as shown by this dialog box:
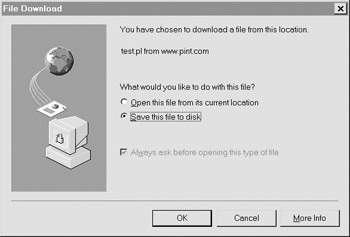
| Note | It is very easy to install a relationship between a MIME type and a program to handle the data, yet few people seem to add the relationships to directly deal with any form of data served by a Web server. |
Typically, Web pages are delivered properly, so these dialog boxes are not seen. The browser first would read the HTML being delivered and then retrieve any other objects, such as GIF images, sound files, Flash files, Java applets, and so on, that are associated with the page. Each object would result in another request to the server. If the browser encountered something such as
<img src="images/logo.gif" alt="demo company" height="100" width="200" alr="Demo Company" />
it would then form a request like the following:
GET /images/logo.gif HTTP/1.1 Connection: Keep-Alive User-Agent: Mozilla/4.0 (compatible; MSIE 5.01; Windows 98) Accept: application/x-comet, image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */* Accept-Language: en-us
The server then would respond with a similar answer as before, but this time indicating that a MIME type of image/gif is being returned, followed by the appropriate form of binary data to make up an image, as demonstrated here:
HTTP/1.1 200 OK Date: Tue, 18 Jan 2000 04:41:15 GMT Server: Apache/1.3.4 (Unix) Last-Modified: Wed, 13 Oct 1999 23:37:38 GMT Content-Length: 28531 Connection: close Content-Type: image/gif GIF87a- " '"'"{"ss ky -{""' X ?{{j s '}l {{sfT{{szjq~eUmogKv ]QljZckZoe PfegccZccRZcRX binary file continues Consider that with the MIME type set properly, it is literally possible to serve any object. Yet page authors often avoid serving custom forms of data beyond HTML or common media types such as GIF, JPEG, or WAV because of unfamiliarity with the MIME-type configuration possibilities on client and server. Probably this is due to how little is said about MIME when discussing Web site development, but how important it is in the discussion between the browser and the server, and how it is the key to making server-side programs work properly, as discussed in Chapters 12 and 13. In some sense, one can think of the core Web protocols- HTML, HTTP, and MIME-like the world-famous three tenors. People often only remember the first two, but it truly takes three to make it work!
| < Day Day Up > |
EAN: 2147483647
Pages: 252