1.1 A Layman s Approach to Normalization
|
| < Day Day Up > |
|
1.1 A Layman's Approach to Normalization
Application of the relational database model to a data set involves the removal of duplication. Removal of duplication is performed using a process called Normalization. Normalization comprises a set of rules called Normal Forms. Normalization is applied to a set of data in a database to form tables or entities. Tables are for placing directly associated data into. Tables can be related or linked to each other through the use of key or index identifiers. A key or index identifier identifies a row of data in a table much like an index is used in a book. An index in a book is used to locate an item of interest without having to read the whole title.
There are five levels or layers of Normalization called 1st, 2nd, 3rd, 4th, and 5th Normal Forms. Each Normal Form is a refinement of the previous Normal Form. 4th and 5th Normal Forms are rarely applied. In designing tables for performance it is common practice to ignore the steps of Normalization and jump directly to 2nd Normal Form. 3rd Normal Form is often not applied either, unless many-to-many joins cause an absolute need for unique values at the application level.
| Tip | Over-Normalization using 4th and 5th Normal Forms can lead to poor performance in both OLTP and data warehouse type databases. Over-Normalization is common in top-down designed Java object applications. In this situation an object structure is imposed onto a relational database. Object and relational data structures are completely different methodologies. |
That is far too much jargon. Let us make the understanding of Normalization very simple. "Forget about it!" Normalization is for academics and in its strictest form is generally impractical due to its adverse effect on performance in a commercial environment, especially 3rd, 4th, and 5th Normal Forms. The simplest way to describe what Normalization attempts to achieve can be explained in three ways:
-
Dividing the whole into smaller more manageable parts.
-
Removal of duplicated data into related subsets.
-
Linking of two indirectly related tables by the creation of a new table. The new table contains indexes (keys) from the two indirectly related tables. This is commonly known as a many-to-many join.
These three points are meaningless without further explanation of Normalization. So let us go through the rules and try to explain it in a non-academic fashion. Let us start with some relational database buzzwords.
-
A table contains many repetitions of the same row. A table defines the structure for a row. An example of a table is a list of customer names and addresses.
-
A row is a line of data. Many rows make up the data in a table. An example of a row is a single customer name and address within a table of many customers. A row is also known as a record or a tuple.
-
The structure of a row in a table is divided up into columns. Each column contains a single item of data such as a name or address. A column can also be called a field or attribute.
-
Referential Integrity is a process of validation between related tables where references between different tables are checked against each other. A primary key is placed on a parent or superset table as the primary identifier or key to each row in the table. The primary key will always point to a single row only and it is unique within the table. A foreign key is a copy of a primary key value in a subset or child table. An example of a function of Referential Integrity is that it will not allow the deletion of a primary key table row where a foreign key value exists in a child table. Primary keys are often referred to as PK and foreign keys as FK. Note that both primary and foreign keys can consist of more than one column. A key consisting of more than one column is known as a composite key.
-
An index is used to gain fast access to a table. A key is a special form of an index used to enforce Referential Integrity relationships between tables. An index allows direct access to rows by duplicating a small part of each row to an additional (index) file. An index is a copy of the contents of a small number of columns in a table, occupying less physical space and therefore faster to search through than a table. The most efficient indexes are made up of single columns containing integers.
Tip Primary and foreign keys are special types of indexes, applying Referential Integrity. Oracle Database automatically indexes primary keys but not foreign keys.
1.1.1 1st Normal Form
1st Normal Form removes repetition by creating one-to-many relationships. Data repeated many times in one table is removed to a subset table. The subset table becomes the container for the removed repeating data. Each row in the subset table will contain a single reference to each row in the original table. The original table will then contain only nonduplicated data.
In the example in Figure 1.1 a 1st Normal Form transformation is shown. The sales order table on the left contains customer details, sales order details, and descriptions of multiple items on the sales order. Application of 1st Normal Form removes the multiple items from the sales order table by creating a one-to-many relationship between the sales order and the sales order item tables. This has three benefits:
-
Saves space.
-
Reduces complexity.
-
Ensures that every sales order item will belong to a sales order.
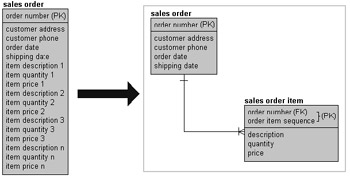
Figure 1.1: 1st Normal Form
In Figure 1.1 the crow's-foot pointing to the sales order item table indicates that for a sales order to exist, the sales order has to have at least one sales order item. The line across the pointer to the sales order table signifies that at least one sales order is required in this relationship. The crow's-foot is used to denote an inter-entity relationship.
| Tip | Inter-entity relationships can be zero, one or many TO zero, one or many. |
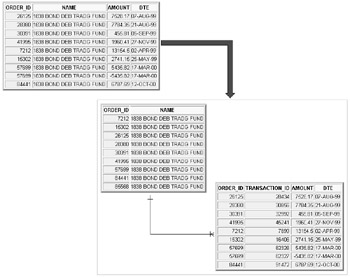
Figure 1.2: 1st Normal Form Rows for Figure 1.1
The relationship shown in Figure 1.1 between the sales order and sales order item table is that of one to one-or-many.
Example rows for the 1st Normal Form structure in Figure 1.1 are shown in Figure 1.2. Notice how the master and detail rows are now separated.
1.1.2 2nd Normal Form
2nd Normal Form creates not one-to-many relationships but many-toone relationships, effectively separating static from dynamic information. Static information is potentially repeatable. This repeatable static information is moved into separate tables. In Figure 1.3 the customer information is removed from the sales order table.
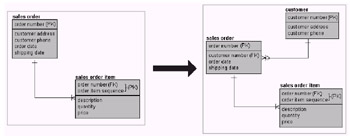
Figure 1.3: 2nd Normal Form
Customer information can be duplicated for many sales orders or have no sales orders; thus the one-and-only-one to zero-one-or-many relationship between customers and sales orders.
Example rows for the 2nd Normal Form structure in Figure 1.3 are shown in Figure 1.4. Now we have separation of master and detail rows and a single entry for our customer name; there is no duplication of information. On creation of the Customer entity one would create a primary key on the CUSTOMER_NUMBER column, as shown on the right side of the diagram in Figure 1.3. Figure 1.4 does not show a CUSTOMER_NUMBER but merely a customer name for explanatory purposes. In Figure 1.4 a primary key would be created on the name of the Customer table.
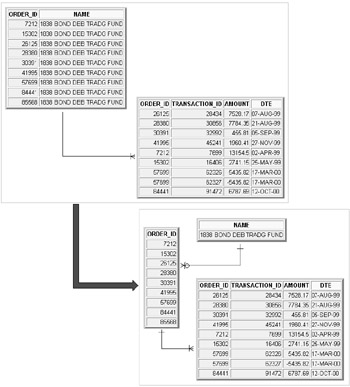
Figure 1.4: 2nd Normal Form Rows for Figure 1.3
1.1.3 3rd Normal Form
3rd Normal Form is used to resolve many-to-many relationships into unique values. In Figure 1.5 a student can be enrolled in many courses, and a course can have many students enrolled. It is impossible to find a unique course-student item without joining every student with every course. Therefore, each unique item can be found with the combination of values. Thus the CourseStudent entity in Figure 1.5 is a many-to-many join resolution entity. In a commercial environment it is very unlikely that an application will ever need to find this unique item, especially not a modern-day Java object web application where the tendency is to drill down through list collections rather than display individual items. Many-to-many join resolutions should only be created when they are specifically required by the application. It can sometimes be better to resolve these joins in the application to improve database performance, and not create new entities at all.
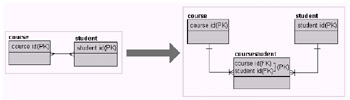
Figure 1.5: 3rd Normal Form
| Tip | Be very careful using 3rd Normal Form and beyond. |
Example rows for the 3rd Normal Form structure in Figure 1.5 are shown in Figure 1.6. Notice how the containment of both students within courses and courses within students is provided by the application of 3rd Normal Form. The question you should ask yourself when using 3rd Normal Forms is this: Does your application need both these one-to-many relationships? If not then do not create the new entity because more entities lead to more complex joins and thus slower SQL statements. Theoretically application of 3rd Normal Form under these circumstances is correct. However, in a commercial application you will not necessarily need to access the information in both orders.
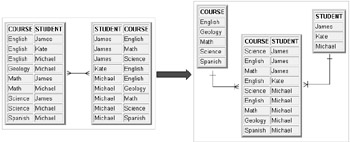
Figure 1.6: 3rd Normal Form Rows for Figure 1.5
Now let's understand this a little further. Take a look at Figure 1.7. That many-to-many relationship we had between the two tables on the left in Figure 1.6 has disappeared. That is because the two entities on the left in Figure 1.6 are the same entity; they contain the same data, only in a different order. The courses and students with the contained intra-relationships can be retrieved from a single table simply by applying a different sort order. Figure 1.7 shows the entities and the number of rows increasing with the application of 3rd Normal Form. So not only will we have more complex joins but we will also have more rows and thus more physical space usage, also leading to slower SQL statements.
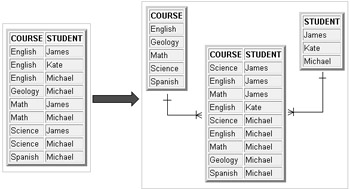
Figure 1.7: A More Concise Form of the Rows in Figure 1.6
1.1.4 4th Normal Form
4th Normal Form is intended to separate duplications independent of each other, and those values can be nulls; thus removing repeating, potentially null values into separate entities. In Figure 1.8 employee skill and certification collections are removed into separate entities. An employee could have skills or certifications, or both. Thus there is no connection between the attributes of the Employees table, other than the employee number, and the details of skills or certifications for each employee.
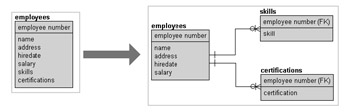
Figure 1.8: 4th Normal Form
Example rows for the 4th Normal Form structure in Figure 1.8 are shown in Figure 1.9. The rows are divided from one into three separate entities. Since skills and certifications are duplicated in the 4th Normal Form application there is further Normalization possible but it is not advisable. Once again creation of too many entities creates a propensity for complex and slow SQL statements.
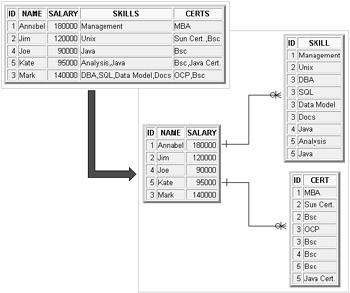
Figure 1.9: 4th Normal Form Rows for Figure 1.8
| Tip | Oracle Database will allow creation of object collections within tables. The Skills and Certifications attributes shown on the left of Figure 1.8 are candidates for a contained object collection structure, namely a TABLE or VARRAY object. However, since object and relational structures do not always mix well this is not necessarily the most efficient storage method for later fast SQL access, even if it is an elegant solution. |
1.1.5 5th Normal Form
5th Normal Form divides related columns into separate tables based on those relationships. In Figure 1.10 product, manager, and employee are all related to each other. Thus, three separate entities can be created to explicitly define those inter-relationships. The result is information that can be reconstructed from smaller parts. An additional purpose of 5th Normal Form is to remove redundancy or duplication not covered by the application of 1st to 4th Normal Forms of Normalization.
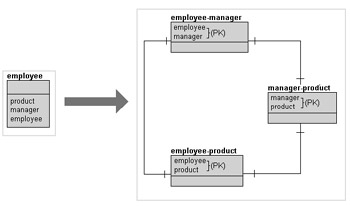
Figure 1.10: 5th Normal Form
| Tip | All the columns in the 5th Normal Forms entities on the right of the diagram in Figure 1.10 are composed of composite primary keys. |
Example rows for the 5th Normal Form structure in Figure 1.10 are shown in Figure 1.11. Note how there are two one-to-many relationships on the right side of Figure 1.11; this is caused by the nature of the data. In Figure 1.11 it should be clear that entities divide up data in an elegant and logical way. Once again this level of Normalization will be detrimental to SQL performance due to more complex SQL statement joins and more physical storage space used.
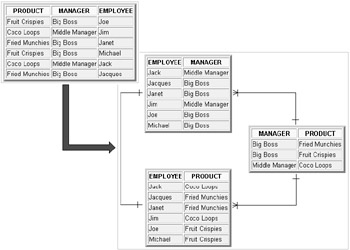
Figure 1.11: 5th Normal Form Rows for Figure 1.10
1.1.6 Let's Recap on Normalization
-
1st Normal Form removes repetition by creating one-to-many relationships.
-
2nd Normal Form creates not one-to-many relationships but many-to-one relationships, effectively separating static from dynamic information. 2nd Normal Form removes items from tables independent of the primary key.
-
3rd Normal Form is used to resolve many-to-many relationships into unique values. 3rd Normal Form allows for uniqueness of information by creation of additional many-to-many join resolution tables. These tables are rarely required in modern-day applications.
-
4th Normal Form is intended to separate duplications independent of each other, thus removing repeating, potentially null values into separate entities. 5th Normal Form divides related columns into separate tables based on those relationships. 4th and 5th Normal Forms will minimize nulls and composite primary keys by removing null capable fields and subset composite primary key dependent fields to new tables. 4th and 5th Normal Forms are rarely useful.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 164