Chapter 5. UNIX Tools - split, wc, sort, cmp, diff, comm, dircmp, cut, paste, join, and tr
| CONTENTS |
Chapter 5. UNIX Tools - split, wc, sort, cmp, diff, comm, dircmp, cut, paste, join, and tr
- Not All Commands on All UNIX Variants
- split
- wc
- sort
- cmp, diff, and comm
- dircmp
- cut
- paste
- tr
- Manual Pages for Some Commands Used in Chapter 5
Not All Commands on All UNIX Variants
A variety of commands are covered in this chapter, including:
-
split, wc, sort, cmp, diff, comm, dircmp, cut, paste, join, and tr commands
I cover many useful and enjoyable commands in this chapter. All the commands, however, are not available on all UNIX variants. If a specific command is not available on your system, then you probably have a similar command or can combine more than one command to achieve the desired result.
split
Some files are just too long. The file listing we earlier looked at may be more easily managed if split into multiple files. We can use the split command to make listing into files 25 lines long, as shown in Figure 5-1:
Figure 5-1. split Command
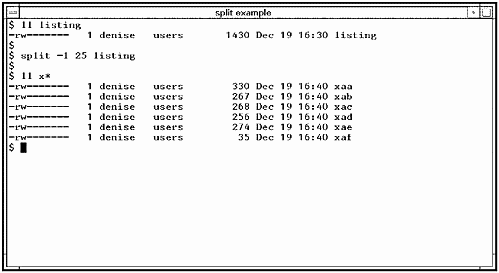
Note that the split command produced several files from listing called xaa, xab, and so on. The -l option is used to specify the number of lines in files produced by split.
Here is a summary of the split command:
split - Split a file into multiple files.
|
wc
We know that we have split listing into separate files of 25 lines each, but how many lines were in listing originally? How about the number of words in listing? Those of us who get paid by the word for some of the articles we write often want to know. How about the number of characters in a file? The wc command can produce a word, line, and character count for you. Figure 5-2 shows issuing the wc command with the -wlc options, which produce a count of words with the -w option, lines with the -l option, and characters with the -c option.
Figure 5-2. wc Command



Notice that the number of words and lines produced by wc is the same for the file listing. The reason is that each line contains exactly one word. When we display the words, lines, and characters with the wc command for the text file EMACS.tutorial, we cansee thatthe number of words is 6251, the number of lines is 825, and the number of characters is 34491. In a text file, in this case a tutorial, you would expect many more words than lines.
Here is a summary of the wc command:
wc - Produce a count of words, lines, and characters.
|
sort
Sometimes the contents of files are not sorted in the way you would like. You can use the sort command to sort files with a variety of options.

You may find, as you continue to use your UNIX system, that your system administrator is riding you about the amount of disk space you that you are consuming. You can monitor the amount of disk space you are consuming with the du command. Figure 5-3 shows creating a file called disk_space that lists the amount of disk space consumed by files and directories and shows the first 20 lines of the file:
Figure 5-3. sort Command Example #1
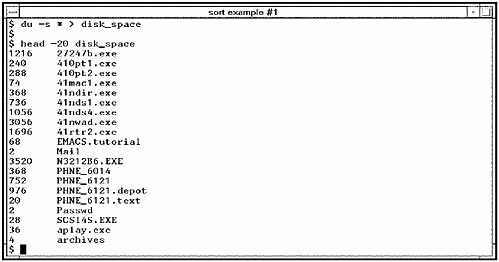
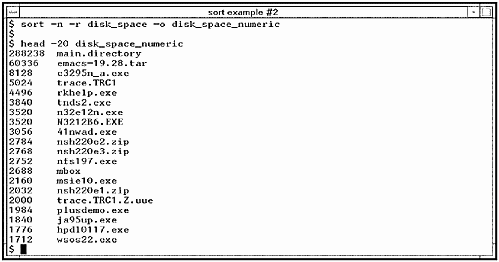
Notice that the result is sorted alphabetically. In many cases, this is what you want. If the file were not sorted alphabetically, you could use the sort command to do so. In this case, we don't care as much about seeing entries in alphabetical order as we do in numeric order, that is, the files and directories that are consuming the most space. Figure 5-4 shows sorting the file disk_space numerically with the -n option and reversing the order of the sort with the -r option so that the biggest numbers appear first. We then specify the output file name with the -o option.
Figure 5-4. sort Command Example #2
What if the items being sorted had many more fields than our two-column disk usage example? Let's go back to the passwd.test file for a more complex sort. Let's cat passwd.test so we can again see its contents:

# cat passwd.test root:PgYQCkVH65hyQ:0:0:root:/root:/bin/bash bin:*:1:1:bin:/bin: daemon:*:2:2:daemon:/sbin: adm:*:3:4:adm:/var/adm: lp:*:4:7:lp:/var/spool/lpd: sync:*:5:0:sync:/sbin:/bin/sync shutdown:*:6:11:shutdown:/sbin:/sbin/shutdown halt:*:7:0:halt:/sbin:/sbin/halt mail:*:8:12:mail:/var/spool/mail: news:*:9:13:news:/var/spool/news: uucp:*:10:14:uucp:/var/spool/uucp: operator:*:11:0:operator:/root: games:*:12:100:games:/usr/games: gopher:*:13:30:gopher:/usr/lib/gopher-data: ftp:*:14:50:FTP User:/home/ftp: man:*:15:15:Manuals Owner:/: nobody:*:65534:65534:Nobody:/:/bin/false col:Wh0yzfAV2qm2Y:100:100:Caldera OpenLinux User:/home/col:/bin/bash
Now let's use sort to determine which users are in the same group. Fields are separated in passwd.test by a colon (:). The fourth field is the group to which a user belongs. For instance, bin is in group 1, daemon in group 2, and so on. To sort by group, we would have to specify three options to the sort command. The first is to specify the delimiter (or field separator) of colon (:) using the -t option. Next, we would have to specify the field on which we wish to sort with the -k option. Finally, we want a numeric sort, so use the -n option. The following example shows a numeric sort of the passwd.test file by the fourth field:
# sort -t: -k4 -n passwd.test halt:*:7:0:halt:/sbin:/sbin/halt operator:*:11:0:operator:/root: root:PgYQCkVH65hyQ:0:0:root:/root:/bin/bash sync:*:5:0:sync:/sbin:/bin/sync bin:*:1:1:bin:/bin: daemon:*:2:2:daemon:/sbin: adm:*:3:4:adm:/var/adm: lp:*:4:7:lp:/var/spool/lpd: shutdown:*:6:11:shutdown:/sbin:/sbin/shutdown mail:*:8:12:mail:/var/spool/mail: news:*:9:13:news:/var/spool/news: uucp:*:10:14:uucp:/var/spool/uucp: man:*:15:15:Manuals Owner:/: gopher:*:13:30:gopher:/usr/lib/gopher-data: ftp:*:14:50:FTP User:/home/ftp: col:Wh0yzfAV2qm2Y:100:100:Caldera OpenLinux User:/home/col:/bin/bash games:*:12:100:games:/usr/games: nobody:*:65534:65534:Nobody:/:/bin/false
The following is a summary of the sort command.
sort - Sort lines of files (alphabetically by default).
|
cmp, diff, and comm
A fact of life is that as you go about editing files, you may occasionally lose track of what changes you have made to which files. You may then need to make comparisons of files. Let's take a look at three such commands, cmp, diff, and comm, and see how they compare files.




Let's assume that we have modified a script called llsum. The unmodified version of llsum was saved as llsum.orig. Using the head command, we can view the first 20 lines of llsum and then the first 20 lines of llsum.orig:
# head -20 llsum # #!/bin/sh # Displays a truncated long listing (ll) and # displays size statistics # of the files in the listing. ll $* | \ awk ' BEGIN { x=i=0; printf "%-25s%-10s%8s%8s\n",\ "FILENAME","OWNER","SIZE","TYPE" } $1 ~ /^[-dlps]/ {# line format for normal files printf "%-25s%-10s%8d",$9,$3,$5 x = x + $5 i++ } $1 ~ /^-/ { printf "%8s\n","file" } # standard file types $1 ~ /^d/ { printf "%8s\n","dir" } $1 ~ /^l/ { printf "%8s\n","link" } $1 ~ /^p/ { printf "%8s\n","pipe" } $1 ~ /^s/ { printf "%8s\n","socket" } $1 ~ /^[bc]/ { # line format for device files printf "%-25s% - 10s%8s%8s\n",$10,$3,"","dev" } # # head -20 llsum.orig # #!/bin/sh # Displays a truncated long listing (ll) and # displays size statistics # of the files in the listing. ll $* | \ awk ' BEGIN { x=i=0; printf "%-16s%-10s%8s%8s\n",\ "FILENAME","OWNER","SIZE","TYPE" } $1 ~ /^[-dlps]/ {# line format for normal files printf "%-16s%-10s%8d",$9,$3,$5 x = x + $5 i++ } $1 ~ /^-/ { printf "%8s\n","file" } # standard file types $1 ~ /^d/ { printf "%8s\n","dir" } $1 ~ /^l/ { printf "%8s\n","link" } $1 ~ /^p/ { printf "%8s\n","pipe" } $1 ~ /^s/ { printf "%8s\n","socket" } $1 ~ /^[bc]/ { # line format for device files printf "%-16s% - 10s%8s%8s\n",$10,$3,"","dev" }
I'm not sure what changes I made to llsum.orig to improve it, so we can first use cmp to see whether indeed differences exist between the files.

$ $ cmp llsum llsum.orig llsum llsum.orig differ: char 154, line 6 $ cmp does not report back much information, only that character 154 in the file at line 6 is different in the two files. There may indeed be other differences, but this is all we know about so far.
To get information about all of the differences in the two files, we could use the -l option to cmp:
$ cmp -l llsum llsum.orig 154 62 61 155 65 66 306 62 61 307 65 66 675 62 61 676 65 66 This is not all that useful an output, however. W want to see not only the position of the differences, but also the differences themselves.
Now we can use diff to describe all the differences in the two files:

$ diff llsum llsum.orig 6c6 < awk ' BEGIN { x=i=0; printf "%-25s%-10s%8s%8s\n",\ --- > awk ' BEGIN { x=i=0; printf "%-16s%-10s%8s%8s\n",\ 9c9 < printf "%-25s%-10s%8d",$9,$3,$5 --- > printf "%-16s%-10s%8d",$9,$3,$5 19c19 < printf "%-25s%-10s%8s%8s\n",$10,$3,"","dev" --- > printf "%-16s%-10s%8s%8s\n",$10,$3,"","dev" $ We now know that lines 6, 9, and 25 are different in the two files and these lines are also listed for us. From this listing, we can see that the number 16 in llsum.orig was changed to 25 in the newer llsum file, and this accounts for all of the differences in the two files. The less "than sign" (<) precedes lines from the first file, in this case llsum. The "greater than" sign (>) precedes lines from the second file, in this case llsum.orig. I made this change, starting the second group of information from character 16 to character 25, because I wanted the second group of information, produced by llsum, to start at column 25. The second group of information is the owner, as shown in the following example:
$ llsum FILENAME OWNER SIZE TYPE README denise 810 file backup_files denise 3408 file biography denise 427 file cshtest denise 1024 dir gkill denise 1855 file gkill.out denise 191 file hostck denise 924 file ifstat denise 1422 file ifstat.int denise 2147 file ifstat.out denise 723 file introdos denise 54018 file introux denise 52476 file letter denise 23552 file letter.auto denise 69632 file letter.auto.recover denise 71680 file letter.backup denise 23552 file letter.lck denise 57 file letter.recover denise 69632 file llsum denise 1267 file llsum.orig denise 1267 file llsum.out denise 1657 file llsum.tomd.out denise 1356 file psg denise 670 file psg.int denise 802 file psg.out denise 122 file sam_adduser denise 1010 file tdolan denise 1024 dir trash denise 4554 file trash.out denise 329 file typescript denise 2017 file The files listed occupy 393605 bytes (0.3754 Mbytes) Average file size is 13120 bytes $ When we run llsum.orig, clearly the second group of information, which is the owner, starts at column 16 and not column 32:
$ llsum.orig FILENAME OWNER SIZE TYPE README denise 810 file backup_files denise 3408 file biography denise 427 file cshtest denise 1024 dir gkill denise 1855 file gkill.out denise 191 file hostck denise 924 file ifstat denise 1422 file ifstat.int denise 2147 file ifstat.out denise 723 file introdos denise 54018 file introux denise 52476 file letter denise 23552 file letter.auto denise 69632 file letter.auto.rec denise 71680 file letter.backup denise 23552 file letter.lck denise 57 file letter.recover denise 69632 file llsum denise 1267 file llsum.orig denise 1267 file llsum.out denise 1657 file llsum.tomd.out denise 1356 file psg denise 670 file psg.int denise 802 file psg.out denise 122 file sam_adduser denise 1010 file tdolan denise 1024 dir trash denise 4554 file trash.out denise 329 file typescript denise 3894 file The files listed occupy 395482 bytes (0.3772 Mbytes) Average file size is 13182 bytes script done on Mon Dec 11 12:59:18 $ 

We can compare two sorted files using comm and see the lines that are unique to each file, as well as the lines found in both files. When we compare two files with comm, the lines that are unique to the first file appear in the first column, the lines unique to the second file appear in the second column and the lines contained in both files appear in the third column. Let's go back to the /etc/passwd file to illustrate this comparison. We'll compare two /etc/passwd files, the active /etc/passwd file in use and an old /etc/passwd file from a backup:
# comm /etc/passwd /etc/passwd.backup root:PgYQCkVH65hyQ:0:0:root:/root:/bin/bash bin:*:1:1:bin:/bin: daemon:*:2:2:daemon:/sbin: adm:*:3:4:adm:/var/adm: lp:*:4:7:lp:/var/spool/lpd: sync:*:5:0:sync:/sbin:/bin/sync shutdown:*:6:11:shutdown:/sbin:/sbin/shutdown halt:*:7:0:halt:/sbin:/sbin/halt mail:*:8:12:mail:/var/spool/mail: news:*:9:13:news:/var/spool/news: uucp:*:10:14:uucp:/var/spool/uucp: operator1:*:12:0:operator:/root: operator:*:11:0:operator:/root: games:*:12:100:games:/usr/games: gopher:*:13:30:gopher:/usr/lib/gopher-data: ftp:*:14:50:FTP User:/home/ftp: man:*:15:15:Manuals Owner:/: nobody:*:65534:65534:Nobody:/:/bin/false col:Wh0yzfAV2qm2Y:100:100:Caldera OpenLinux User:/home/col:/bin/bash You can see from this output that the user games appears only in the active /etc/passwd file, the user operator1 appears only in the /etc/passwd.backup file, and all of the other entries appear in both files.
The following is a summary of the cmp and diff commands:
cmp - Compare the contents of two files. The byte position and line number of the first difference between the two files is returned.
|
diff - Compares two files and reports differing lines.
|
dircmp
Why stop at comparing files? You will probably have many directories in your user area as well. dircmp compares two directories and produces information about the contents of directories.
To begin with, let's perform a long listing of two directories:


$ ls -l krsort.dir.old total 168 -rwxr-xr-x 1 denise users 34592 Oct 31 11:27 krsort -rwxr-xr-x 1 denise users 3234 Oct 31 11:27 krsort.c -rwxr-xr-x 1 denise users 32756 Oct 31 11:27 krsort.dos -rw-r--r-- 1 denise users 9922 Oct 31 11:27 krsort.q -rwxr-xr-x 1 denise users 3085 Oct 31 11:27 krsortorig.c $ $ ls -l krsort.dir.new total 168 -rwxr-xr-x 1 denise users 34592 Oct 31 15:17 krsort -rwxr-xr-x 1 denise users 32756 Oct 31 15:17 krsort.dos -rw-r--r-- 1 denise users 9922 Oct 31 15:17 krsort.q -rwxr-xr-x 1 denise users 3234 Oct 31 15:17 krsort.test.c -rwxr-xr-x 1 denise users 3085 Oct 31 15:17 krsortorig.c $
From this listing, you can see clearly that one file is unique to each directory. krsort.c appears in only the krsort.dir.old directory, and krsort.test.c appears in only the krsort.dir.new directory. Let's now use dircmp to inform us of the differences in these two directories:
$ dircmp krsort.dir.old krsort.dir.new krsort.dir.old only and krsort.dir.new only Page 1 ./krsort.c ./krsort.test.c Comparison of krsort.dir.old krsort.dir.new Page 1 directory . same ./krsort same ./krsort.dos same ./krsort.q same ./krsortorig.c $ This is a useful output. First, the files that appear in only one directory are listed. Then, the files common to both directories are listed.
The following is a summary of the dircmp command:
dircmp - Compare directories.
|
cut
There are times when you have an output that has too many fields in it. When we issued the llsum command earlier, it produced four fields: FILENAME, OWNER, SIZE, and TYPE. What if we want to take this output and look at just the FILENAME and SIZE? We could modify the llsum script, or we could use the cut command to eliminate the OWNER and TYPE fields with the following commands:

$ llsum | cut -c 1-25,37-43 FILENAME SIZE README 810 backup_files 3408 biography 427 cshtest 1024 gkill 1855 gkill.out 191 hostck 924 ifstat 1422 ifstat.int 2147 ifstat.out 723 introdos 54018 introux 52476 letter 23552 letter.auto 69632 letter.auto.recover 71680 letter.backup 23552 letter.lck 57 letter.recover 69632 llsum 1267 llsum.orig 1267 llsum.out 1657 llsum.tomd.out 1356 psg 670 psg.int 802 psg.out 122 sam_adduser 1010 tdolan 1024 trash 4554 trash.out 329 typescript 74 The files listed occupy 3 (0.373 Average file size is 1305 $ This has produced a list from llsum, which is piped to cut. Only characters 1 through 25 and 37 through 43 have been extracted. These characters correspond to the fields we want. At the end of the output are two lines that are only partially printed. We don't want these lines, so we can use grep -v to eliminate them and print all other lines. The output of this command is saved to the file llsum.out at the end of this output, which we'll use later:

$./llsum | grep -v "bytes" | cut -c 1-25,37-43 FILENAME SIZE README 810 backup_files 3408 biography 427 cshtest 1024 gkill 1855 gkill.out 191 hostck 924 ifstat 1422 ifstat.int 2147 ifstat.out 723 introdos 54018 introux 52476 letter 23552 letter.auto 69632 letter.auto.recover 71680 letter.backup 23552 letter.lck 57 letter.recover 69632 llsum 1267 llsum.orig 1267 llsum.out 1657 llsum.tomd.out 1356 psg 670 psg.int 802 psg.out 122 sam_adduser 1010 tdolan 1024 trash 4554 trash.out 329 typescript 1242 $ llsum | grep -v "bytes" | cut -c 1-25,37-4_3 > llsum.out $
The following is a summary of the cut command, with some of the more commonly used options:
cut - Extract specified fields from each line.
|
paste

Files can be merged in a variety of ways. If you want to merge files on a line-by-line basis, you can use the paste command. The first line in the second file is pasted to the end of the first line in the first file and so on.
Let's use the cut command just covered and extract only the permissions field, or characters 1 through 10, to get only the permissions for files. We'll then save these in the file ll.out:
$ ls -al | cut -c 1-10 total 798 drwxrwxrwx drwxrwxrwx -rwxrwxrwx -rwxrwxrwx -rwxrwxrwx drwxr-xr-x -rwxrwxrwx -rw-r--r-- -rwxrwxrwx -rwxrwxrwx -rwxr-xr-x -rw-r--r-- -rw-r--r-- -rwxrwxrwx -rw-r--r-- -rw-r--r-- -rw-r--r-- -rw-r--r-- -rw-rw- rw- -rw-r--r-- -rw-r--r-- -rwxrwxrwx -rwxr-xr-x -rw-r--r-- -rw-r--r-- -rwxrwxrwx -rwxr-xr-x -rw-r--r-- -rwxrwxrwx drwxr-xr-x -rwxrwxrwx -rw-r--r-- -rw-r--r-- $ ls -al | cut -c 1-10 > ll.out $
We can now use the paste command to paste the permissions saved in thell.out file to the other file-related information in the llsum.out file:
$ paste llsum.out ll.out FILENAME SIZE total 792 README 810 -rwxrwxrwx backup_files 3408 -rwxrwxrwx biography 427 -rwxrwxrwx cshtest 1024 drwxr-xr-x gkill 1855 -rwxrwxrwx gkill.out 191 -rw-r--r-- hostck 924 -rwxrwxrwx ifstat 1422 -rwxrwxrwx ifstat.int 2147 -rwxr-xr-x ifstat.out 723 -rw-r--r-- introdos 54018 -rw-r--r-- introux 52476 -rwxrwxrwx letter 23552 -rw-r--r-- letter.auto 69632 -rw-r--r-- letter.auto.recover 71680 -rw-r--r-- letter.backup 23552 -rw-r--r-- letter.lck 57 -rw-rw- rw- letter.recover 69632 -rw-r--r-- ll.out 1057 -rw-r--r-- llsum 1267 -rwxrwxrwx llsum.orig 1267 -rwxr-xr-x llsum.out 1657 -rw-r--r-- llsum.tomd.out 1356 -rw-r--r-- psg 670 -rwxrwxrwx psg.int 802 -rwxr-xr-x psg.out 122 -rw-r--r-- sam_adduser 1010 -rwxrwxrwx tdolan 1024 drwxr-xr-x trash 4554 -rwxrwxrwx trash.out 329 -rw-r--r-- typescript 679 -rw-r--r-- $ This has produced a list that includes FILENAME and SIZE from llsum.out and permissions from ll.out.
If both files have the same first field, you can use the join command to merge the two files.
The following is a summary of the paste and join commands, with some of the more commonly used options:

paste - Merge lines of files.
|
join - Combine two presorted files that have a common key field.
|
tr

tr translates characters. tr is ideal for such tasks as changing case. For instance, what if you want to translate all lowercase characters to uppercase? The following example shows listing files that have the suffix "zip" and then translates these files into uppercase:
$ ls -al *.zip file1.zip file2.zip file3.zip file4.zip file5.zip file6.zip file7.zip $ ls -al *.zip | tr "[:lower:]" "[:upper:]" FILE1.ZIP FILE2.ZIP FILE3.ZIP FILE4.ZIP FILE5.ZIP FILE6.ZIP FILE7.ZIP $
We use brackets in this case because we are translating a class of characters.
The following is a summary of the tr command, with some of the more commonly used options.
tr - Translate characters.
|
Manual Pages for Some Commands Used in Chapter 5
The following are the HP-UX manual pages for many of the commands used in this chapter. Commands often differ among UNIX variants, so you may find differences in the options or other areas for some commands; however, the following manual pages serve as an excellent reference.
cmp
cmp - Comparefiles.
cmp(1) cmp(1) NAME cmp - compare two files SYNOPSIS cmp [-l] [-s] file1 file2 DESCRIPTION cmp compares two files (if file1 or file2 is -, the standard input is used). Under default options, cmp makes no comment if the files are the same; if they differ, it announces the byte and line number at which the difference occurred. If one file is an initial subsequence of the other, that fact is noted. cmp recognizes the following options: -l Print the byte number (decimal) and the differing bytes (octal) for each difference (byte numbering begins at 1 rather than 0). -s Print nothing for differing files; return codes only. EXTERNAL INFLUENCES Environment Variables LANG determines the language in which messages are displayed. If LANG is not specified or is set to the empty string, a default of "C" (see lang(5)) is used instead of LANG. If any internationalization variable contains an invalid setting, cmp behaves as if all internationalization variables are set to "C". See environ(5). International Code Set Support Single- and multi-byte character code sets are supported. DIAGNOSTICS cmp returns the following exit values: 0 Files are identical. 1 Files are not identical. 2 Inaccessible or missing argument. cmp prints the following warning if the comparison succeeds till the end of file of file1(file2) is reached. cmp: EOF on file1(file2) SEE ALSO comm(1), diff(1). STANDARDS CONFORMANCE cmp: SVID2, SVID3, XPG2, XPG3, XPG4, POSIX.2
comm
comm - Produce three-column output of sorted files.
comm(1) comm(1) NAME comm - select or reject lines common to two sorted files SYNOPSIS comm [-[123]] file1 file2 DESCRIPTION comm reads file1 and file2, which should be ordered in increasing collating sequence (see sort(1) and Environment Variables below), and produces a three-column output: Column 1: Lines that appear only in file1, Column 2: Lines that appear only in file2, Column 3: Lines that appear in both files. If - is used for file1 or file2, the standard input is used. Options 1, 2, or 3 suppress printing of the corresponding column. Thus comm -12 prints only the lines common to the two files; comm -23 prints only lines in the first file but not in the second; comm -123 does nothing useful. EXTERNAL INFLUENCES Environment Variables LC_COLLATE determines the collating sequence comm expects from the input files. LC_MESSAGES determines the language in which messages are displayed. If LC_MESSAGES is not specified in the environment or is set to the empty string, the value of LANG determines the language in which messages are displayed. If LC_COLLATE is not specified in the environment or is set to the empty string, the value of LANG is used as a default. If LANG is not specified or is set to the empty string, a default of ``C'' (see lang(5)) is used instead of LANG. If any internationalization variable contains an invalid setting, comm behaves as if all internationalization variables are set to ``C''. See environ(5). International Code Set Support Single- and multi-byte character code sets are supported. EXAMPLES The following examples assume that file1 and file2 have been ordered in the collating sequence defined by the LC_COLLATE or LANG environment variable. Print all lines common to file1 and file2 (in other words, print column 3): comm -12 file1 file2 Print all lines that appear in file1 but not in file2 (in other words, print column 1): comm -23 file1 file2 Print all lines that appear in file2 but not in file1 (in other words, print column 2): comm -13 file1 file2 SEE ALSO cmp(1), diff(1), sdiff(1), sort(1), uniq(1). STANDARDS CONFORMANCE comm: SVID2, SVID3, XPG2, XPG3, XPG4, POSIX.2
cut
cut - Cut selected fields from the lines in a file.
cut(1) cut(1) NAME cut - cut out (extract) selected fields of each line of a file SYNOPSIS cut -c list [file ...] cut -b list [-n] [file ...] cut -f list [-d char] [-s] [file ...] DESCRIPTION cut cuts out (extracts) columns from a table or fields from each line in a file; in data base parlance, it implements the projection of a relation. Fields as specified by list can be fixed length (defined in terms of character or byte position in a line when using the -c or -b option), or the length can vary from line to line and be marked with a field delimiter character such as the tab character (when using the -f option). cut can be used as a filter; if no files are given, the standard input is used. When processing single-byte character sets, the -c and -b options are equivalent and produce identical results. When processing multi-byte character sets, when the -b and -n options are used together, their combined behavior is very similar, but not identical to the -c option. Options Options are interpreted as follows: list A comma-separated list of integer byte (-b option), character (-c option), or field (-f option) numbers, in increasing order, with optional - to indicate ranges. For example: 1,4,7 Positions 1, 4, and 7. 1-3,8 Positions 1 through 3 and 8. -5,10 Positions 1 through 5 and 10. 3- Position 3 through last position. -b list Cut based on a list of bytes. Each selected byte is output unless the -n option is also specified. -c list Cut based on character positions specified by list (-c 1-72 extracts the first 72 characters of each line). -f list Where list is a list of fields assumed to be separated in the file by a delimiter character (see -d); for example, -f 1,7 copies the first and seventh field only. Lines with no field delimiters will be passed through intact (useful for table subheadings), unless -s is specified. -d char The character following -d is the field delimiter (-f option only). Default is tab. Space or other characters with special meaning to the shell must be quoted. Adjacent field delimiters delimit null fields. -n Do not split characters. If the high end of a range within a list is not the last byte of a character, that character is not included in the output. However, if the low end of a range within a list is not the first byte of a character, the entire character is included in the output." -s Suppresses lines with no delimiter characters when using -f option. Unless -s is specified, lines with no delimiters appear in the output without alteration. Hints Use grep to extract text from a file based on text pattern recognition (using regular expressions). Use paste to merge files line-by-line in columnar format. To rearrange columns in a table in a different sequence, use cut and paste. See grep(1) and paste(1) for more information. EXTERNAL INFLUENCES Environment Variables LC_CTYPE determines the interpretation of text as single and/or multi-byte characters. If LC_CTYPE is not specified in the environment or is set to the empty string, the value of LANG is used as a default for each unspecified or empty variable. If LANG is not specified or is set to the empty string, a default of "C" (see lang(5)) is used instead of LANG. If any internationalization variable contains an invalid setting, cut behaves as if all internationalization variables are set to "C". See environ(5). International Code Set Support The delimiter specified with the -d argument must be a single-byte character. Otherwise, single- and multi-byte character code sets are supported. EXAMPLES Password file mapping of user ID to user names: cut -d : -f 1,5 /etc/passwd Set environment variable name to current login name: name=`who am i | cut -f 1 -d " "` Convert file source containing lines of arbitrary length into two files where file1 contains the first 500 bytes (unless the 500th byte is within a multi-byte character), and file2 contains the remainder of each line: cut -b 1-500 -n source > file1 cut -b 500- -n source > file2 DIAGNOSTICS line too long Line length must not exceed LINE_MAX characters or fields, including the new-line character (see limits(5). bad list for b/c/f option Missing -b, -c, or -f option or incorrectly specified list. No error occurs if a line has fewer fields than the list calls for. no fields list is empty. WARNINGS cut does not expand tabs. Pipe text through expand(1) if tab expansion is required. Backspace characters are treated the same as any other character. To eliminate backspace characters before processing by cut, use the fold or col command (see fold(1) and col(1)). AUTHOR cut was developed by OSF and HP. SEE ALSO grep(1), paste(1). STANDARDS CONFORMANCE cut: SVID2, SVID3, XPG2, XPG3, XPG4, POSIX.2
diff
diff - File and directory comparison.
diff(1) diff(1) NAME diff - differential file and directory comparator SYNOPSIS diff [-C n] [-S name] [-lrs] [-bcefhintw] dir1 dir2 diff [-C n] [-S name] [-bcefhintw] file1 file2 diff [-D string] [-biw] file1 file2 DESCRIPTION Comparing Directories If both arguments are directories, diff sorts the contents of the directories by name, then runs the regular file diff algorithm (described below) on text files that have the same name in each directory but are different. Binary files that differ, common subdirectories, and files that appear in only one directory are listed. When comparing directories, the following options are recognized: -l Long output format; each text file diff is piped through pr to paginate it (see pr(1)). Other differences are remembered and summarized after all text file differences are reported. -r Applies diff recursively to common subdirectories encountered. -s diff reports files that are identical but otherwise not mentioned. -S name Starts a directory diff in the middle of the sorted directory, beginning with file name. Comparing Files When run on regular files, and when comparing text files that differ during directory comparison, diff tells what lines must be changed in the files to bring them into agreement. diff usually finds a smallest sufficient set of file differences. However, it can be misled by lines containing very few characters or by other situations. If neither file1 nor file2 is a directory, either can be specified as -, in which case the standard input is used. If file1 is a directory, a file in that directory whose filename is the same as the filename of file2 is used (and vice versa). There are several options for output format. The default output format contains lines resembling the following: n1 a n3,n4 n1,n2 d n3 n1,n2 c n3,n4 These lines resemble ed commands to convert file1 into file2. The numbers after the letters pertain to file2. In fact, by exchanging a for d and reading backwards one may ascertain equally how to convert file2 into file1. As in ed, identical pairs where n1=n2 or n3=n4 are abbreviated as a single number. Following each of these lines come all the lines that are affected in the first file flagged by <, then all the lines that are affected in the second file flagged by >. Except for -b, -w, -i, or -t which can be given with any of the others, the following options are mutually exclusive: -e Produce a script of a, c, and d commands for the ed editor suitable for recreating file2 from file1. Extra commands are added to the output when comparing directories with -e, so that the result is a shell script for converting text files common to the two directories from their state in dir1 to their state in dir2 (see sh-bourne(1) -f Produce a script similar to that of the -e option that is not useful with ed but is more readable by humans. -n Produce a script similar to that of -e, but in the opposite order, and with a count of changed lines on each insert or delete command. This is the form used by rcsdiff (see rcsdiff(1)). -c Produce a difference list with 3 lines of context. -c modifies the output format slightly: the output begins with identification of the files involved, followed by their creation dates, then each change separated by a line containing about twelve asterisks (*)s. Lines removed from file1 are marked with -, and lines added to file2 are marked +. Lines that change from one file to the other are marked in both files with with !. Changes that lie within 3 lines of each other in the file are grouped together on output. -C n Output format similar to -c but with n lines of context. -h Do a fast, half-hearted job. This option works only when changed stretches are short and well separated, but can be used on files of unlimited length. -D string Create a merged version of file1 and file2 on the standard output, with C preprocessor controls included so that a compilation of the result without defining string is equivalent to compiling file1, while compiling the result with string defined is equivalent to compiling file2. -b Ignore trailing blanks (spaces and tabs) and treat other strings of blanks as equal. -w Ignore all whitespace (blanks and tabs). For example, if ( a == b ) and if(a==b) are treated as equal. -i Ignores uppercase/lowercase differences. Thus A is treated the same as a. -t Expand tabs in output lines. Normal or -c output adds one or more characters to the front of each line. Resulting misalignment of indentation in the original source lines can make the output listing difficult to interpret. This option preserves original source file indentation. EXTERNAL INFLUENCES Environment Variables LANG determines the locale to use for the locale categories when both LC_ALL and the corresponding environment variable (beginning with LC_) do not specify a locale. If LANG is not set or is set to the empty string, a default of "C" (see lang(5)) is used. LC_CTYPE determines the space characters for the diff command, and the interpretation of text within file as single- and/or multi-byte characters. LC_MESSAGES determines the language in which messages are displayed. If any internationalization variable contains an invalid setting, diff and diffh behave as if all internationalization variables are set to "C". See environ(5). International Code Set Support Single- and multi-byte character code sets are supported with the exception that diff and diffh do not recognize multi-byte alternative space characters. RETURN VALUE Upon completion, diff returns with one of the following exit values: 0 No differences were found. 1 Differences were found. >1 An error occurred. EXAMPLES The following command creates a script file script: diff -e x1 x2 >script w is added to the end of the script in order to save the file: echo w >> script The script file can then be used to create the file x2 from the file x1 using the editor ed in the following manner: ed x1 < script The following command produces the difference output with 2 lines of context information before and after the line that was different: diff -C2 x1 x2 The following command ignores all blanks and tabs and ignores uppercase-lowercase differences. diff -wi x1 x2 WARNINGS Editing scripts produced by the -e or -f option are naive about creating lines consisting of a single dot (.). When comparing directories with the -b, -w, or -i options specified, diff first compares the files in the same manner as cmp, then runs the diff algorithm if they are not equal. This may cause a small amount of spurious output if the files are identical except for insignificant blank strings or uppercase/lowercase differences. The default algorithm requires memory allocation of roughly six times the size of the file. If sufficient memory is not available for handling large files, the -h option or bdiff can be used (see bdiff(1)). When run on directories with the -r option, diff recursively descends sub-trees. When comparing deep multi-level directories, more memory may be required than is currently available on the system. The amount of memory required depends on the depth of recursion and the size of the files. AUTHOR diff was developed by AT&T, the University of California, Berkeley, and HP. FILES /usr/lbin/diffh used by -h option SEE ALSO bdiff(1), cmp(1), comm(1), diff3(1), diffmk(1), dircmp(1), ed(1), more(1), nroff(1), rcsdiff(1), sccsdiff(1), sdiff(1), terminfo(4). STANDARDS CONFORMANCE diff: SVID2, SVID3, XPG2, XPG3, XPG4, POSIX.2
dircmp
dircmp - Compare directories and produce results.
dircmp(1) dircmp(1) NAME dircmp - directory comparison SYNOPSIS dircmp [-d] [-s] [-wn] dir1 dir2 DESCRIPTION dircmp examines dir1 and dir2 and generates various tabulated information about the contents of the directories. Sorted listings of files that are unique to each directory are generated for all the options. If no option is entered, a sorted list is output indicating whether the filenames common to both directories have the same contents. -d Compare the contents of files with the same name in both directories and output a list telling what must be changed in the two files to bring them into agreement. The list format is described in diff(1). -s Suppress messages about identical files. -wn Change the width of the output line to n characters. The default width is 72. EXTERNAL INFLUENCES Environment Variables LC_COLLATE determines the order in which the output is sorted. If LC_COLLATE is not specified in the environment or is set to the empty string, the value of LANG is used as a default. If LANG is not specified or is set to the empty string, a default of ``C'' (see lang(5)) is used instead of LANG. If any internationalization variable contains an invalid setting, dircmp behaves as if all internationalization variables are set to ``C'' (see environ(5)). International Code Set Support Single- and multi-byte character code sets are supported. EXAMPLES Compare the two directories slate and sleet and produce a list of changes that would make the directories identical: dircmp -d slate sleet SEE ALSO cmp(1), diff(1). STANDARDS CONFORMANCE dircmp: SVID2, SVID3, XPG2, XPG3
join
join - Join two relations based on lines in files.
join(1) join(1) NAME join - relational database operator SYNOPSIS join [options] file1 file2 DESCRIPTION join forms, on the standard output, a join of the two relations specified by the lines of file1 and file2. If file1 or file2 is -, the standard input is used. file1 and file2 must be sorted in increasing collating sequence (see Environment Variables below) on the fields on which they are to be joined; normally the first in each line. The output contains one line for each pair of lines in file1 and file2 that have identical join fields. The output line normally consists of the common field followed by the rest of the line from file1, then the rest of the line from file2. The default input field separators are space, tab, or new-line. In this case, multiple separators count as one field separator, and leading separators are ignored. The default output field separator is a space. Some of the below options use the argument n. This argument should be a 1 or a 2 referring to either file1 or file2, respectively. Options -a n In addition to the normal output, produce a line for each unpairable line in file n, where n is 1 or 2. -e s Replace empty output fields by string s. -j m Join on field m of both files. The argument m must be delimited by space characters. This option and the following two are provided for backward compatibility. Use of the -1 and -2 options ( see below ) is recommended for portability. -j1 m Join on field m of file1. -j2 m Join on field m of file2. -o list Each output line comprises the fields specified in list, each element of which has the form n.m, where n is a file number and m is a field number. The common field is not printed unless specifically requested. -t c Use character c as a separator (tab character). Every appearance of c in a line is significant. The character c is used as the field separator for both input and output. -v file_number Instead of the default output, produce a line only for each unpairable line in file_number, where file_number is 1 or 2. -1 f Join on field f of file 1. Fields are numbered starting with 1. -2 f Join on field f of file 2. Fields are numbered starting with 1. EXTERNAL INFLUENCES Environment Variables LC_COLLATE determines the collating sequence join expects from input files. LC_CTYPE determines the alternative blank character as an input field separator, and the interpretation of data within files as single and/or multi-byte characters. LC_CTYPE also determines whether the separator defined through the -t option is a single- or multi-byte character. If LC_COLLATE or LC_CTYPE is not specified in the environment or is set to the empty string, the value of LANG is used as a default for each unspecified or empty variable. If LANG is not specified or is set to the empty string, a default of ``C'' (see lang(5)) is used instead of LANG. If any internationalization variable contains an invalid setting, join behaves as if all internationalization variables are set to ``C'' (see environ(5)). International Code Set Support Single- and multi-byte character code sets are supported with the exception that multi-byte-character file names are not supported. EXAMPLES The following command line joins the password file and the group file, matching on the numeric group ID, and outputting the login name, the group name, and the login directory. It is assumed that the files have been sorted in the collating sequence defined by the LC_COLLATE or LANG environment variable on the group ID fields. join -1 4 -2 3 -o 1.1 2.1 1.6 -t: /etc/passwd /etc/group The following command produces an output consisting all possible combinations of lines that have identical first fields in the two sorted files sf1 and sf2, with each line consisting of the first and third fields from sorted_file1 and the second and fourth fields from sorted_file2: join -j1 1 -j2 1 -o 1.1, 2.2, 1.3, 2.4 sorted_file1 sorted_file2 WARNINGS With default field separation, the collating sequence is that of sort -b; with -t, the sequence is that of a plain sort. The conventions of join, sort, comm, uniq, and awk are incongruous. Numeric filenames may cause conflict when the -o option is used immediately before listing filenames. AUTHOR join was developed by OSF and HP. SEE ALSO awk(1), comm(1), sort(1), uniq(1). STANDARDS CONFORMANCE join: SVID2, SVID3, XPG2, XPG3, XPG4, POSIX.2
paste
paste - Merge lines of files.
paste(1) paste(1) NAME paste - merge same lines of several files or subsequent lines of one file SYNOPSIS paste file1 file2 ... paste -d list file1 file2 ... paste -s [-d list] file1 file2 ... DESCRIPTION In the first two forms, paste concatenates corresponding lines of the given input files file1, file2, etc. It treats each file as a column or columns in a table and pastes them together horizontally (parallel merging). In other words, it is the horizontal counterpart of cat(1) which concatenates vertically; i.e., one file after the other. In the -s option form above, paste replaces the function of an older command with the same name by combining subsequent lines of the input file (serial merging). In all cases, lines are glued together with the tab character, or with characters from an optionally specified list. Output is to standard output, so paste can be used as the start of a pipe, or as a filter if - is used instead of a file name. paste recognizes the following options and command-line arguments: -d Without this option, the new-line characters of all but the last file (or last line in case of the -s option) are replaced by a tab character. This option allows replacing the tab character by one or more alternate characters (see below). list One or more characters immediately following -d replace the default tab as the line concatenation character. The list is used circularly; i.e., when exhausted, it is reused. In parallel merging (that is, no -s option), the lines from the last file are always terminated with a new-line character, not from the list. The list can contain the special escape sequences: \n (new-line), \t (tab), \\ (backslash), and \0 (empty string, not a null character). Quoting may be necessary if characters have special meaning to the shell. (For example, to get one backslash, use - d"\\\\"). -s Merge subsequent lines rather than one from each input file. Use tab for concatenation, unless a list is specified with the -d option. Regardless of the list, the very last character of the file is forced to be a new-line. - Can be used in place of any file name to read a line from the standard input (there is no prompting). EXTERNAL INFLUENCES Environment Variables LC_CTYPE determines the locale for the interpretation of text as single- and/or multi-byte characters. LC_MESSAGES determines the language in which messages are displayed. If LC_CTYPE or LC_MESSAGES is not specified in the environment or is set to the empty string, the value of LANG is used as a default for each unspecified or empty variable. If LANG is not specified or is set to the empty string, a default of "C" (see lang(5)) is used instead of LANG. If any internationalization variable contains an invalid setting, paste behaves as if all internationalization variables are set to "C". See environ(5). International Code Set Support Single- and multi-byte character code sets are supported. RETURN VALUE These commands return the following values upon completion: 0 Completed successfully. >0 An error occurred. EXAMPLES List directory in one column: ls | paste -d" " - List directory in four columns ls | paste - - - - Combine pairs of lines into lines paste -s -d"\t\n" file Notes pr -t -m... works similarly, but creates extra blanks, tabs and new lines for a nice page layout. DIAGNOSTICS too many files Except for the -s option, no more than OPEN_MAX - 3 input files can be specified (see limits(5)). AUTHOR paste was developed by OSF and HP. SEE ALSO cut(1), grep(1), pr(1). STANDARDS CONFORMANCE paste: SVID2, SVID3, XPG2, XPG3, XPG4, POSIX.2
sort
sort - Sort contents of files.
sort(1) sort(1) NAME sort - sort or merge files SYNOPSIS sort [-m] [-o output] [-bdfinruM] [-t char] [-k keydef] [-y [kmem]] [-z recsz] [-T dir] [file ...] sort [-c] [-AbdfinruM] [-t char] [-k keydef] [-y [kmem]] [-z recsz] [-T dir] [file ...] DESCRIPTION sort performs one of the following functions: 1. Sorts lines of all the named files together and writes the result to the specified output. 2. Merges lines of all the named (presorted) files together and writes the result to the specified output. 3. Checks that a single input file is correctly presorted. The standard input is read if - is used as a file name or no input files are specified. Comparisons are based on one or more sort keys extracted from each line of input. By default, there is one sort key, the entire input line. Ordering is lexicographic by characters using the collating sequence of the current locale. If the locale is not specified or is set to the POSIX locale, then ordering is lexicographic by bytes in machine-collating sequence. If the locale includes multi-byte characters, single-byte characters are machine-collated before multi byte characters. Behavior Modification Options The following options alter the default behavior: -A Sorts on a byte-by-byte basis using each character's encoded value. On some systems, extended characters will be considered negative values, and so sort before ASCII characters. If you are sorting ASCII characters in a non-C/POSIX locale, this flag performs much faster. -c Check that the single input file is sorted according to the ordering rules. No output is produced; the exit code is set to indicate the result. -m Merge only; the input files are assumed to be already sorted. -o output The argument given is the name of an output file to use instead of the standard output. This file can be the same as one of the input files. -u Unique: suppress all but one in each set of lines having equal keys. If used with the -c option, check to see that there are no lines with duplicate keys, in addition to checking that the input file is sorted. -y [kmem] The amount of main memory used by the sort can have a large impact on its performance. If this option is omitted, sort begins using a system default memory size, and continues to use more space as needed. If this option is presented with a value, kmem, sort starts using that number of kilobytes of memory, unless the administrative minimum or maximum is violated, in which case the corresponding extremum will be used. Thus, -y 0 is guaranteed to start with minimum memory. By convention, -y (with no argument) starts with maximum memory. -z recsz The size of the longest line read is recorded in the sort phase so that buffers can be allocated during the merge phase. If the sort phase is omitted via the -c or -m options, a popular system default size will be used. Lines longer than the buffer size will cause sort to terminate abnormally. Supplying the actual number of bytes in the longest line to be merged (or some larger value) will prevent abnormal termination. -T dir Use dir as the directory for temporary scratch files rather than the default directory, which is is one of the following, tried in order: the directory as specified in the TMPDIR environment variable; /var/tmp, and finally, /tmp. Ordering Rule Options When ordering options appear before restricted sort key specifications, the ordering rules are applied globally to all sort keys. When attached to a specific sort key (described below), the ordering options override all global ordering options for that key. The following options override the default ordering rules: -d Quasi-dictionary order: only alphanumeric characters and blanks (spaces and tabs), as defined by LC_CTYPE are significant in comparisons (see environ(5)). (XPG4 only.) The behavior is undefined for a sort key to which -i or -n also applies. -f Fold letters. Prior to being compared, all lowercase letters are effectively converted into their uppercase equivalents, as defined by LC_CTYPE. -i In non-numeric comparisons, ignore all characters which are non-printable, as defined by LC_CTYPE. For the ASCII character set, octal character codes 001 through 037 and 0177 are ignored. -n The sort key is restricted to an initial numeric string consisting of optional blanks, an optional minus sign, zero or more digits with optional radix character, and optional thousands separators. The radix and thousands separator characters are defined by LC_NUMERIC. The field is sorted by arithmetic value. An empty (missing) numeric field is treated as arithmetic zero. Leading zeros and plus or minus signs on zeros do not affect the ordering. The -n option implies the -b option (see below). -r Reverse the sense of comparisons. -M Compare as months. The first several non-blank characters of the field are folded to uppercase and compared with the langinfo(5) items ABMON_1 < ABMON_2 < ... < ABMON_12. An invalid field is treated as being less than ABMON_1 string. For example, American month names are compared such that JAN < FEB < ... < DEC. An invalid field is treated as being less than all months. The -M option implies the -b option (see below). Field Separator Options The treatment of field separators can be altered using the options: -t char Use char as the field separator character; char is not considered to be part of a field (although it can be included in a sort key). Each occurrence of char is significant (for example, <char><char> delimits an empty field). If -t is not specified, <blank> characters will be used as default field separators; each maximal sequence of <blank> characters that follows a non-<blank> character is a field separator. -b Ignore leading blanks when determining the starting and ending positions of a restricted sort key. If the -b option is specified before the first -k option (+pos1 argument), it is applied to all -k options (+pos1 arguments). Otherwise, the -b option can be attached independently to each -k field_start or field_end option (+pos1 or (-pos2 argument; see below). Note that the -b option is only effective when restricted sort key specifications are given. Restricted Sort Key -k keydef The keydef argument defines a restricted sort key. The format of this definition is field_start[type][,field_end[type]] which defines a key field beginning at field_start and ending at field_end. The characters at positions field_start and field_end are included in the key field, providing that field_end does not precede field_start. A missing field_end means the end of the line. Fields and characters within fields are numbered starting with 1. Note that this is different than the obsolete form of restricted sort keys, where numbering starts at 0. See WARNINGS below. Specifying field_start and field_end involves the notion of a field, a minimal sequence of characters followed by a field separator or a new-line. By default, the first blank of a sequence of blanks acts as the field separator. All blanks in a sequence of blanks are considered to be part of the next field; for example, all blanks at the beginning of a line are considered to be part of the first field. The arguments field_start and field_end each have the form m.n which are optionally followed by one or more of the type options b, d, f, i, n, r, or M. These modifiers have the functionality for this key only, that their command-line counterparts have for the entire record. A field_start position specified by m.n is interpreted to mean the nth character in the mth field. A missing n means .1, indicating the first character of the mth field. If the -b option is in effect, n is counted from the first non-blank character in the mth field. A field_end position specified by m.n is interpreted to mean the nth character in the mth field. If n is missing, the mth field ends at the last character of the field. If the -b option is in effect, n is counted from the first non-<blank> character in the mth field. Multiple -k options are permitted and are significant in command line order. A maximum of 9 -k options can be given. If no -k option is specified, a default sort key of the entire line is used. When there are multiple sort keys, later keys are compared only after all earlier keys compare equal. Lines that otherwise compare equal are ordered with all bytes significant. If all the specified keys compare equal, the entire record is used as the final key. The -k option is intended to replace the obsolete [+pos1 [+pos2]] notation, using field_start and field_end respectively. The fully specified [+pos1 [+pos2]] form: +w.x-y.z is equivalent to: -k w+1.x+1,y.0 (if z == 0) -k w+1.x+1,y+1.z (if z >0) Obsolete Restricted Sort Key The notation +pos1 -pos2 restricts a sort key to one beginning at pos1 and ending at pos2. The characters at positions pos1 and pos2 are included in the sort key (provided that pos2 does not precede pos1). A missing -pos2 means the end of the line. Specifying pos1 and pos2 involves the notion of a field, a minimal sequence of characters followed by a field separator or a new-line. By default, the first blank (space or tab) of a sequence of blanks acts as the field separator. All blanks in a sequence of blanks are considered to be part of the next field; for example, all blanks at the beginning of a line are considered to be part of the first field. pos1 and pos2 each have the form m.n optionally followed by one or more of the flags bdfinrM. A starting position specified by +m.n is interpreted to mean character n+1 in field m+1. A missing .n means .0, indicating the first character of field m+1. If the b flag is in effect, n is counted from the first non-blank in field m+1; +m.0b refers to the first non-blank character in field m+1. A last position specified by -m.n is interpreted to mean the nth character (including separators) after the last character of the m th field. A missing .n means .0, indicating the last character of the mth field. If the b flag is in effect, n is counted from the last leading blank in field m+1; -m.1b refers to the first non-blank in field m+1. EXTERNAL INFLUENCES Environment Variables LC_COLLATE determines the default ordering rules applied to the sort. LC_CTYPE determines the locale for interpretation of sequences of bytes of text data as characters (e.g., single- verses multibyte characters in arguments and input files) and the behavior of character classification for the -b, -d, -f, -i, and -n options. LC_NUMERIC determines the definition of the radix and thousands separator characters for the -n option. LC_TIME determines the month names for the -M option. LC_MESSAGES determines the language in which messages are displayed. LC_ALL determines the locale to use to override the values of all the other internationalization variables. NLSPATH determines the location of message catalogs for the processing of LC_MESSAGES. LANG provides a default value for the internationalization variables that are unset or null. If LANG is unset or null, the default value of "C" (see lang(5)) is used. If any of the internationalization variables contains an invalid setting, sort behaves as if all internationalization variables are set to "C". See environ(5). International Code Set Support Single- and multi-byte character code sets are supported. EXAMPLES Sort the contents of infile with the second field as the sort key: sort -k 2,2 infile Sort, in reverse order, the contents of infile1 and infile2, placing the output in outfile and using the first two characters of the second field as the sort key: sort -r -o outfile -k 2.1,2.2 infile1 infile2 Sort, in reverse order, the contents of infile1 and infile2, using the first non-blank character of the fourth field as the sort key: sort -r -k 4.1b,4.1b infile1 infile2 Print the password file (/etc/passwd) sorted by numeric user ID (the third colon-separated field): sort -t: -k 3n,3 /etc/passwd Print the lines of the presorted file infile, suppressing all but the first occurrence of lines having the same third field: sort -mu -k 3,3 infile DIAGNOSTICS sort exits with one of the following values: 0 All input files were output successfully, or -c was specified and the input file was correctly presorted. 1 Under the -c option, the file was not ordered as specified, or if the -c and -u options were both specified, two input lines were found with equal keys. This exit status is not returned if the -c option is not used. >1 An error occurred such as when one or more input lines are too long. When the last line of an input file is missing a new-line character, sort appends one, prints a warning message, and continues. If an error occurs when accessing the tables that contain the collation rules for the specified language, sort prints a warning message and defaults to the POSIX locale. If a -d, -f, or -i option is specified for a language with multi-byte characters, sort prints a warning message and ignores the option. WARNINGS Numbering of fields and characters within fields (-k option) has changed to conform to the POSIX standard. Beginning at HP-UX Release 9.0, the -k option numbers fields and characters within fields, starting with 1. Prior to HP-UX Release 9.0, numbering started at 0. A field separator specified by the -t option is recognized only if it is a single-byte character. The character type classification categories alpha, digit, space, and print are not defined for multi-byte characters. For languages with multi-byte characters, all characters are significant in comparisons. FILES /var/tmp/stm??? /tmp/stm??? AUTHOR sort was developed by OSF and HP. SEE ALSO comm(1), join(1), uniq(1), collate8(4), environ(5), hpnls(5), lang(5). STANDARDS CONFORMANCE sort: SVID2, SVID3, XPG2, XPG3, XPG4, POSIX.2
tr
tr - Substitute selected characters.
tr(1) tr(1) NAME tr - translate characters SYNOPSIS tr [-Acs] string1 string2 tr -s [-Ac] string1 tr -d [-Ac] string1 tr -ds [-Ac] string1 string1 DESCRIPTION tr copies the standard input to the standard output with substitution or deletion of selected characters. Input characters from string1 are replaced with the corresponding characters in string2. If necessary, string1 and string2 can be quoted to avoid pattern matching by the shell. tr recognizes the following command line options: -A Translates on a byte-by-byte basis. When this flag is specified tr does not support extended characters. -c Complements the set of characters in string1, which is the set of all characters in the current character set, as defined by the current setting of LC_CTYPE, except for those actually specified in the string1 argument. These characters are placed in the array in ascending collation sequence, as defined by the current setting of LC_COLLATE. -d Deletes all occurrences of input characters or collating elements found in the array specified in string1. If -c and -d are both specified, all characters except those specified by string1 are deleted. The contents of string2 are ignored, unless -s is also specified. Note, however, that the same string cannot be used for both the -d and the -s flags; when both flags are specified, both string1 (used for deletion) and string2 (used for squeezing) are required. If -d is not specified, each input character or collating element found in the array specified by string1 is replaced by the character or collating element in the same relative position specified by string2. -s Replaces any character specified in string1 that occurs as a string of two or more repeating characters as a single instance of the character in string2. If the string2 contains a character class, the argument's array contains all of the characters in that character class. For example: tr -s '[:space:]' In a case conversion, however, the string2 array contains only those characters defined as the second characters in each of the toupper or tolower character pairs, as appropriate. For example: tr -s '[:upper:]' '[:lower:]' The following abbreviation conventions can be used to introduce ranges of characters, repeated characters or single-character collating elements into the strings: c1-c2 or Stands for the range of collating elements c1 [c1-c2] through c2, inclusive, as defined by the current setting of the LC_COLLATE locale category. [:class:]or Stands for all the characters belonging to the [[:class:]] defined character class, as defined by the current setting of LC_CTYPE locale category. The following character class names will be accepted when specified in string1: alnum, alpha, blank, cntrl. digit, graph, lower, print, punct, space, upper, or xdigit, Character classes are expanded in collation order. When the -d and -s flags are specified together, any of the character class names are accepted in string2; otherwise, only character class names lower or upper are accepted in string2 and then only if the corresponding character class (upper and lower, respectively) is specified in the same relative position in string1. Such a specification is interpreted as a request for case conversion. When [:lower:] appears in string1 and [:upper:] appears in string2, the arrays contain the characters from the toupper mapping in the LC_CTYPE category of the current locale. When [:upper:] appears in string1 and [:lower:] appears in string2, the arrays contain the characters from the tolower mapping in the LC_CTYPE category of the current locale. [=c=]or Stands for all the characters or collating [[=c=]] elements belonging to the same equivalence class as c, as defined by the current setting of LC_COLLATE locale category. An equivalence class expression is allowed only in string1, or in string2 when it is being used by the combined -d and -s options. [a*n] Stands for n repetitions of a. If the first digit of n is 0, n is considered octal; otherwise, n is treated as a decimal value. A zero or missing n is interpreted as large enough to extend string2- based sequence to the length of the string1-based sequence. The escape character \ can be used as in the shell to remove special meaning from any character in a string. In addition, \ followed by 1, 2, or 3 octal digits represents the character whose ASCII code is given by those digits. An ASCII NUL character in string1 or string2 can be represented only as an escaped character; i.e. as \000, but is treated like other characters and translated correctly if so specified. NUL characters in the input are not stripped out unless the option -d "\000" is given. EXTERNAL INFLUENCES Environment Variables LANG provides a default value for the internationalization variables that are unset or null. If LANG is unset or null, the default value of "C" (see lang(5)) is used. If any of the internationalization variables contains an invalid setting, tr will behave as if all internationalization variables are set to "C". See environ(5). LC_ALL If set to a non-empty string value, overrides the values of all the other internationalization variables. LC_CTYPE determines the interpretation of text as single and/or multi-byte characters, the classification of characters as printable, and the characters matched by character class expressions in regular expressions. LC_MESSAGES determines the locale that should be used to affect the format and contents of diagnostic messages written to standard error and informative messages written to standard output. NLSPATH determines the location of message catalogues for the processing of LC_MESSAGES. RETURN VALUE tr exits with one of the following values: 0 All input was processed successfully. >0 An error occurred. EXAMPLES For the ASCII character set and default collation sequence, create a list of all the words in file1, one per line in file2, where a word is taken to be a maximal string of alphabetics. Quote the strings to protect the special characters from interpretation by the shell ( 012 is the ASCII code for a new-line (line feed) character: tr -cs "[A-Z][a-z]" "[\012*]" <file1 >file2 Same as above, but for all character sets and collation sequences: tr -cs "[:alpha:]" "[\012*]" <file1 >file2 Translate all lower case characters in file1 to upper case and write the result to standard output. tr "[:lower:]" "[:upper:]" <file1 Use an equivalence class to identify accented variants of the base character e in file1, strip them of diacritical marks and write the result to file2: tr "[=e=]" "[e*]" <file1 >file2 Translate each digit in file1 to a # (number sign), and write the result to file2. tr "0-9" "[#*]" <file1 >file2 The * (asterisk) tells tr to repeat the # (number sign) enough times to make the second string as long as the first one. AUTHOR tr was developed by OSF and HP. SEE ALSO ed(1), sh(1), ascii(5), environ(5), lang(5), regexp(5). STANDARDS CONFORMANCE tr: SVID2, SVID3, XPG2, XPG3, XPG4, POSIX.2
wc
wc - Count words, bytes, and lines.
wc(1) wc(1) NAME wc - word, line, and byte or character count SYNOPSIS wc [-c|-m] [-lw] [names] DESCRIPTION The wc command counts lines, words, and bytes or characters in the named files, or in the standard input if no names are specified. It also keeps a total count for all named files. A word is a maximal string of characters delimited by spaces, tabs, or new-lines. wc recognizes the following command-line options: -c Write to the standard output the number of bytes in each input file. -m Write to the standard output the number of characters in each input file. -w Write to the standard output the number of words in each input file. -l Write to the standard output the number of newline characters in each input file. The c and m options are mutually exclusive. Otherwise, the l, w, and c or m options can be used in any combination to specify that a subset of lines, words, and bytes or characters are to be reported. When any option is specified, wc will report only the information requested by the specified options. If no option is specified, The default output is -lwc. When names are specified on the command line, they are printed along with the counts. EXTERNAL INFLUENCES Environment Variables LC_CTYPE determines the range of graphics and space characters, and the interpretation of text as single- and/or multi-byte characters. LC_MESSAGES determines the language in which messages are displayed. If LC_CTYPE or LC_MESSAGES is not specified in the environment or is set to the empty string, the value of LANG is used as a default for each unspecified or empty variable. If LANG is not specified or is set to the empty string, a default of "C" (see lang(5)) is used instead of LANG. If any internationalization variable contains an invalid setting, wc behaves as if all internationalization variables are set to "C". See environ(5). International Code Set Support Single- and multi-byte character code sets are supported. WARNINGS The wc command counts the number of newlines to determine the line count. If a text file has a final line that is not terminated with a newline character, the count will be off by one. Standard Output (XPG4 only) By default, the standard output contains an entry for each input file of the form: "%d %d %d %s\n", <newlines>, <words>, <bytes>, <file> If the -m option is specified, the number of characters replaces the <bytes> field in this format. If any options are specified and the -l option is not specified, the number of newlines are not written. If any options are specified and the -w option is not specified, the number of words are not written. If any options are specified and neither -c nor -m is specified, the number of bytes or characters are not written. If no input file operands are specified, no flie name is written and no blank characters preceding the pathname is written. If more than one input file operand is specified, an additional line is written, of the same format as the other lines, except that the word total (in the POSIX Locale) is written instead of a pathname and the total of each column is written as appropriate. Such an additional line, if any, is written at the end of the input. Exit Status The wc utility shall exit with one of the following values 0 Successful completion. >0 An error occured. EXAMPLES Print the number of words and characters in file1: wc -wm file1 The following is printed when the above command is executed: n1 n2 file1 where n1 is the number of words and n2 is the number of characters in file1. STANDARDS CONFORMANCE wc: SVID2, SVID3, XPG2, XPG3, XPG4, POSIX.2
| CONTENTS |
EAN: 2147483647
Pages: 34