Chapter 24. Internet Programming Basics
| CONTENTS |
- Introduction
- Internet Basics
- History
- Client-Server Model of the Internet
- Protocols
- Web Browsers
Introduction
Internet programming is defined many ways. This section will discuss the Internet, what it is, its history, and some methods of programming used.
Internet Basics
What is the Internet? Most people have accessed Web pages, but the Internet is more. The Internet is the world's largest computer network, providing access to people and information around the globe. It isn't a single network; it is a vast network of networks. We can send and receive mail, listen to music, watch videos. We can create our own Web pages and access others' Web pages. The Internet can even work for us by performing services.
The Internet is evolving. The number of people around the world gaining access to the Internet is growing. Businesses now see the Internet as a place of business, a potential for new revenue. It has motivated new ideas and technology. And it is still young. It is an information revolution, and we can all be a part of it.
History
The Internet can trace its history to as early as the 1960s, when researchers began experimenting with creating links between computers via telephone hook-ups using funds provided by the U.S. Defense Department's Advanced Research Projects Agency (ARPA).
ARPA was interested in determining whether computers in different locations could communicate with a new technology called packet switching. This technology allowed several computers to share one communications line, when previously the computers had to have a line between each of them.
Packet switching sends information that has been broken into pieces or packets. The packets are sent to the proper destination, and then reassembled in the appropriate order for use by the receiving computer can use them, as seen in Figure 24-1.
Figure 24-1. Packet-Switched Network
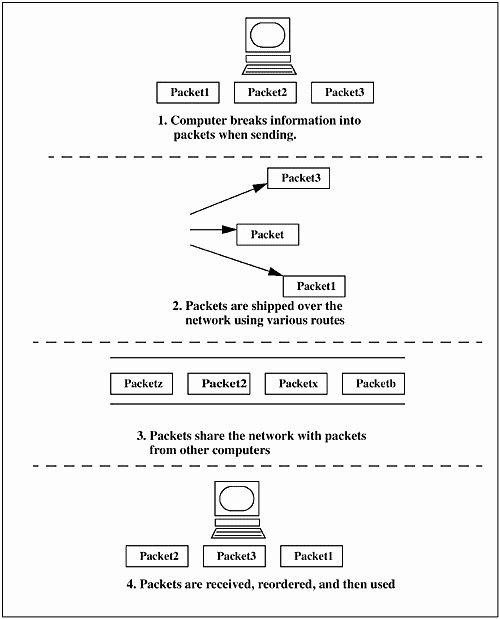
Each packet contains information about its destination. Because information travels the network in packets, many computers can share a single line, with packets, filling it like vehicles on a data highway. This enables packet-switched networks.
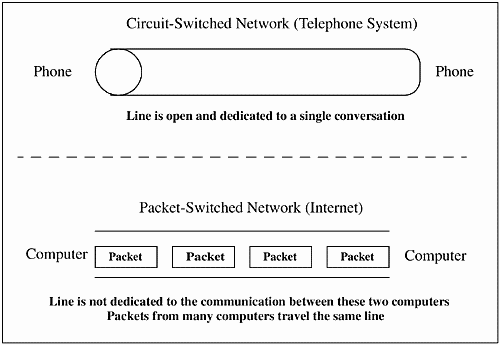
Unlike circuit-switched networks that make up our telephone system, packet-switched networks do not require a single, unbroken connection between packet sender and packet recipient. The packets can take many routes to a destination. For example, if a piece of information is broken into five packets, each packet can take a different route through the network, and then all five packets are assembled at the destination and used. In contrast, the telephone system is a circuit-switched network, requiring a part of the network to be dedicated to a single connection. This connection is open whether someone is speaking or not. A circuit-switched network and a packet-switched network can be seen in Figure 24-2.
Figure 24-2. Circuit-Switched Network vs. Packet-Switched Network
The packet-switching technology was a success and became known as ARPANet. A few enterprising students developed a way to conduct online conferences, and eventually people recognized the power of online communication.
In the 1970s, ARPA supported the development of protocols, or rules, for transferring data between different computer networks. These internetworking or internet protocols enabled the development of the Internet. The end of the 1970s saw the establishment of links between ARPANet and similar networks in other countries. The networking "web" began encompassing the globe.
Expansion of the Internet began at a phenomenal rate in the 1980s. Universities and colleges, government agencies, and research companies began to connect to this worldwide network.
The 1990s saw the invention of the Internet browser, which facilitated explosive growth. Now the data could be displayed in more creative formats, and the Internet began drawing the interest of more than hobbyists and researchers. Data transfer speeds increased, and commercial internetworking services emerged with speeds comparable to the government system. By mid-1994, the U.S. government had removed itself from the day-to-day operations over the Internet.
The Internet is more than information displayed on a browser. It is a network that carries a variety of data. The World Wide Web, or Web, is the fastest growing part of the Internet. It is an Internet facility that links documents locally and remotely and was developed at the European Center for Nuclear Research (CERN) in Geneva for sharing nuclear physics research information. Its origins lie in a proposal by Tim Berners-Lee in 1989. Soon after, in 1991, the first commandline browser was introduced, followed by the Voila X Window browser in 1993, which provided the first graphical capability for the Web. In the same year, CERN introduced its Macintosh browser and the National Center for Supercomputing Applications (NCSA) introduced the X Window version of Mosaic. Soon afterwards, Netscape brought its browser to market, followed by Microsoft.
Browsers allowed the graphical representation and formatting of data that, for the first time, gave the Internet mass appeal.
Today most new users interact with the Internet via Web browsers, but prior to that, command-line UNIX utilities were and can still be used. Programs and files were listed using the Archie utility, and information was downloaded via FTP (File Transfer Protocol). Telnet was used to log on to a computer over the Internet to run programs. Gopher provided hierarchical menus describing Internet files, and Veronica allowed more sophisticated searches on Gopher sites. In 1994, when Web browsers were in their infancy, there were approximately 500 Web sites. Today, there are millions of Web sites with more coming online every day.
Client-Server Model of the Internet
Architectures for programming have evolved over the years. The front-end, or client, is a machine that interfaces with the user and sends information to and receives information from the back-end. A back-end, or server, is a machine or a set of machines that sends information to and receives information from the client. This client-server architecture is illustrated in Figure 24-3.
Figure 24-3. Client-Server Architecture

Early architectures consisted of "dumb" terminals as the client, with super computers as the server. Dumb terminals only knew how to display text information. Later, X-terminals were introduced allowing some graphical representations. The server handled nearly everything, from number crunching and algorithms to field validation. This setup presented a problem when a field had to be validated against business logic; the contents were sent over the network to the server, validated, and sent back. If there was an error in the field, the process was repeated. This architecture increased the network traffic, and the users frequently experienced delays in response.
As technology evolved and PCs became more prevalent, the development community realized that logic, such as field validations, could reside on the client and that pre-validated information could be sent to the server, minimizing network traffic and enhancing user response time. Because clients were more sophisticated, customized and flashy graphical interfaces could be implemented. But they had a price. Complex client software had to be developed, along with server software. All software residing on the client had to be shipped to each user and installed by each user. This meant that any revisions to the client software had to be communicated to the user community, and the user was responsible for performing the update. Eventually the Internet could be used to distribute the software, allowing the users to download new versions of client software. But there was still the problem of ensuring that the user community had the correct version of the client software. And because each user had to do his or her own software updates, this opened up the possibility of errors occurring on individual systems, which meant more user support. Each user spent time performing the update, so the cost of a single client software update became expensive. If each user had to spend ten to twenty minutes on an update, multiplied by hundreds or thousands of users, the time spent for a single client update becomes enormous.
When the World Wide Web and browsers became popular, development communities began to see a possible solution to their dilemma. Browsers could be sent a standard set of commands over the Internet and instructed to display information per these commands. Therefore, developers no longer created client software, and users no longer had to update client software, they used a browser instead. But this has limitations. A developer could only create an interface using the methods provided by the browser.
This solution wasn't perfect either. The browser's capabilities were inferior to the interfaces that developers were now accustom to building. At first, browsers only provided static pages. Many client-server applications needed dynamic attributes from their client, such as buttons and field validation. Eventually Java, Javascript, and other new technologies were created, which enabled dynamic Web pages. Now developers could begin using the browser as the client software and by combining various techniques, could create a fully functioning application on the Web without the hassle of client software updates. The technology is still young and there are limitations. Developers created simple client-server applications at first, but as the technology matures, so does the ability to implement more complex applications.
When using the Internet, connection between the client and server is maintained only during the actual exchange of information. After the information is transferred from the server to the client, the connection between the two is broken, but the connection to the Internet remains.
Protocols
A protocol is a standard or set of rules for hardware and software governing transmission and receipt of data. This facilitates data exchanges via a "conversation." The following is a conceptual exchange managed by a communications protocol:
| Computer 1 wants to send data to Computer 2. | |
|---|---|
| Computer 1: | Are you there? |
| Computer 2: | Yes. |
| Computer 1: | Are you ready to receive data? |
| Computer 2: | Yes. |
| Computer 1: | The message is ...(data is sent). Did you receive it? |
| Computer2: | Yes. |
| Computer 1: | Here is more...(data is sent). Did you receive it? |
| Computer 2: | No. |
| Computer 1: | Here it is again...(data is re-sent). Did you receive it? |
| Computer 2: | Yes. |
| Computer 1: | I have no more data. Goodbye. |
| Computer 2: | Goodbye. |
This seemingly simple idea makes it possible for computers and networks all over the world to share information and messages on the Internet.
When using the Internet, a connection between the client and server is maintained only during the actual exchange of information. After the information is transferred between the client and server the connection is broken, but the Internet connection remains.
As mentioned in the previous section, data is broken into packets, sent, reassembled at the destination, and used. This process is the job of two of the most important communications protocols on the Internet: TCP (Transmission Control Protocol) and IP (Internet Protocol).
TCP/IP
TCP/IP is a communications protocol that was designed as an open protocol to enable all types of computers to transmit data to each other. The Internet uses TCP/IP because it's a packet-switched network.
TCP is a connection-oriented protocol and sets up a connection between two computers. It will guarantee reliable delivery of the data, will test for errors, and will request a retransmission of data, if necessary.
TCP/IP is a routable protocol, which means that all messages contain the address of the destination. IP provides the routing mechanism. The routing mechanism uses an IP address.
An IP address consists of four numbers separated by dots, such as 15.199.45.11. The first part of the address is the network address or netid; the second part is the host or hostid. Every client and server must have an IP address so that it can be found on the Internet.
Basically, TCP is responsible for breaking down and reassembling packets and IP is responsible for ensuring that the packets are sent to the correct destination.
HTTP
HTTP (HyperText Transfer Protocol) is the communications protocol used to connect to servers on the World Wide Web. It establishes a connection with a Web server and facilitates the transmission of HTML pages to the client's browser.
Web addresses begin with the HTTP protocol of http://. Web browsers will typically default an address to the HTTP protocol if the protocol is not entered. For example, the complete address of the Netscape site is
http://netscape.com
If netscape.com is typed without the HTTP protocol, the browser will default to it and put the http:// prefix on the address.
The HTTP connection between the client and server is maintained only while the data is transferred to the client's browser. After it is complete, the HTTP connection between the client and server is broken. When the HTTP connection closes, the TCP/IP connection to the Internet remains. Therefore, the client is still connected to the Internet but is no longer connected to the server.
HTTPS
HTTPS (HyperText Transfer Protocol Secure) is a protocol for accessing a secure Web server. Most Web servers use the default port number of 80. The Web address using https:// directs the message to a secure port number rather than the default port number. The session is then managed by a security protocol.
This protocol is used when entering a secure Web page. The https:// prefix will appear in the Web address instead of http://.
Web Browsers
As previously mentioned, the Web uses a client /server model. A web browser is client software that serves as an interface to the World Wide Web on the Internet. Published information or documents on the Web can be found and viewed using a Web browser.
Documents may contain graphics, text, executable programs such as a Java applet, or a link to another document. A browser will read the document and render it in a human-understandable format.
Browsers are available for many different computer systems. When selecting a browser, be sure that it is compatible with your computer system. Many computer systems have pre-installed browsers. PCs with Microsoft Windows typically have the Internet Explorer browser, while UNIX systems will probably have the Netscape browser. Some Internet Service Providers may provide their own browser software.
Most information on the Web is found via linked pages located on different computers that are connected to the Internet. These network computers, called servers, store and deliver information.
Information is requested via a Uniform Resource Locator or URL. The network uses the URL to find the server that has the document and request a copy. The URL contains the protocol prefix and a domain name. It may also contain a port number, subdirectory names and a document name. If no document name is given, index.html is assumed. The components of a fictional URL are labeled and described below:
URL: http://www.lizards.com:80/neon/products.html
Protocol Prefix:http://
Domain Name: www.lizards.com
Port Number::80/
Subdirectory:neon/
Document Name:products.html
Browsers accept URLs as a means of requesting a document on the Web. URLs can be either typed into a browser or can be displayed as part of a document, known as a link. A user can click on a link and jump to that document.
When a URL is entered or a link is clicked, the domain name is mapped to an IP address. An IP address can be used in place of the domain name in a URL, but this is less popular because it is easier to remember a name than a series of numbers. The IP address is used to find the appropriate server, and makes it a request for a copy of the document. The server sends a copy over the Web and back to your computer. When the data arrives, the browser interprets the data into a document, displaying any images and running any Java applets.
| CONTENTS |
EAN: 2147483647
Pages: 34