Risk Management Cycle
|
|
Many people treat risks as inevitable events that will result in loss, but this is far from the truth. Risks are the potential for loss, resulting from something that has a negative impact on project objectives or the company's ability to perform normal business functions. Risks can be natural occurrences (such as floods or fires), business related (such as mergers or changes in the economy), computer related (such as hacking attempts or other incidents), or any number of other events. Each risk merely has the potential of occurring and doing some sort of damage to a project or company.
To prevent a risk from becoming an incident that actually occurs, risk management is performed. Risk management is a process made up of multiple steps, which can be broken down into the following:
-
Identification Each risk is recognized as being potentially harmful.
-
Assessment The consequences of a potential threat are determined, and the likelihood and frequency of a risk occurring are analyzed.
-
Planning Data that is collected is put into a meaningful format, which is used to create strategies to diminish or remove the impact of a risk.
-
Monitoring Risks are tracked and strategies are evaluated.
-
Control Steps are taken to correct plans that are not working, and improvements are made to the management of a risk.
To illustrate the risk management process in a simplified way, say a team has identified computer viruses as a risk that threatens corporate data. Based on information from other companies, this risk would be assessed as being very likely to occur, and could result in sensitive data being corrupted or lost. The cost of losing this data could result in millions of dollars being lost. To reduce the likelihood of this risk occurring, a plan could be put into place where antivirus software is installed on all servers and workstations. By monitoring how many viruses the software detects, it would then be established that the plan was working. If viruses were not being detected but seemed to appear on the system, then antivirus updates or software from a different manufacturer may need to be installed. By following the steps involved in the risk management process, there is a lowered chance of viruses negatively affecting any projects or business functions within the company.
The risk management cycle begins with the identification of risks. There are a wide number of potential threats that may exist, which can have an adverse effect on a company or project. When identifying the risks involved, the security administrator would subsequently identify the assets affected by the risk. For example, if they were concerned about viruses, then assets affected by this risk would be servers, workstations, and the data residing on them. This phase of the risk management cycle is crucial because, without knowing the risks they are dealing with, they would be unable to continue with any of the other steps.
Once risks have been established, they can then be assessed. During this phase, each risk is analyzed to determine its effect and the possibilities of it occurring. While many risks may have the possibility of occurring, many may be unlikely or not worth preparing for. For example, while it is possible for odd weather conditions to cause a blizzard in California, it is highly unlikely to occur. In other situations, a threat may be probable but infrequent. While viruses may be a common occurrence, unauthorized access to a sealed server room should not be. By determining the likelihood, frequency, and consequences of potential threats, the administrator can then prioritize risks and deal with them accordingly.
The planning phase of the risk management cycle is where information gathered from the previous steps are analyzed and strategies to deal with potential and possible threats are created. It is here that decisions are made on how to deal with specific risks and policies and procedures are created to address potential threats. As will be seen later in this chapter, by designing and implementing a plan to manage risks, the risk can be avoided, accepted, managed, minimized, transferred, or deemed to need additional analysis. Once a plan has been created to deal with the risk, it can then be implemented to complete this phase.
Even though a risk has been dealt with, it cannot be forgotten. Plans to deal with a risk must be monitored to determine if the plan is working and the potential threat is effectively being dealt with. By tracking a risk and evaluating the strategy designed to deal with it, a risk management team can determine whether a risk still poses a potential threat to a company, and whether the existing strategies are still viable. In some cases, monitoring a risk may determine that the risk no longer exists. For example, while Y2K bugs were a major issue in 1999, a company may determine that upgrading all systems and changes to existing code have removed this risk. As such, any plans designed to deal with this risk may no longer be necessary. In other situations, the company may find that an existing plan is not working, and further work is required to make the plan effective.
When plans do not work as expected, or improvements need to be made, the control phase of risk management comes into effect. In this step, a team will react to indications that a plan is not working, implement a backup plan, or revisit previous steps and implement new strategies. Its purpose is to ensure that plans are modified to deal with the risk properly, so that an actual threat does not jeopardize the company or individual projects.
When following steps in the risk management process, a team does not simply go through the steps and then forget about the risk when reaching the following stage. Even after the risk has been initially managed, the process may start all over again. As shown in Figure 5.1, the risk management process is a cycle, where the steps are revisited, and it is determined whether the risk still exists or if a strategy continues to work effectively. If a plan no longer works or vulnerabilities are identified, then the risk must be reassessed and revisions to the existing plan (or a completely different plan) must be made.
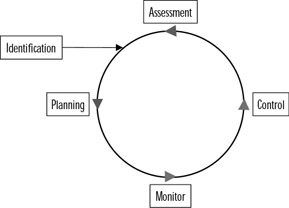
Figure 5.1: Risk Management Cycle
There are two basic approaches to risk management: proactive and reactive. A proactive approach is one in which risks are dealt with before they become problems that could result in loss. By managing risks proactively, there is a reduced chance of loss, and problems can be detected early or avoided completely.
The alternative approach to risk management is reactive. Unlike a proactive approach, reactive risk management deals with problems after they have occurred. This requires IT staff to be in a state of putting out fires, often after some damage has been done. When planning a project, resources may be assigned to fix certain problems if they occur, and deal with the consequences of a risk. When a reactive approach is used, plans are implemented to reduce the impact of a risk after it has become an actual problem, but no effort is made to reduce the risk from occurring in the first place.
As with anything dealing with security, risk management involves a tradeoff. There must be a balance between dealing with a risk and the cost involved in preventing or reducing the impact of a risk. For example, a risk for a company with large buildings in Kansas might be tornadoes. While it is possible to make the buildings tornado proof by placing the entire complex underground, the costs of doing so would be enormous. The company would pay more to protect their assets than the assets themselves were worth. When analyzing risks, it is important to put a price on loss and then create strategies that will be cost effective. At no time should the cost of eliminating or reducing risk be more expensive than the potential loss associated with a particular threat.
Exercise 5.01: Identifying Risks
Review each of the following situations and identify what risks, if any, are involved with each of the scenarios.
-
Antivirus software is installed on a network file server. Because users of the network store their files on this server, no antivirus software was ever installed on the workstations. The company that makes the software has a good reputation, so the network administrator has not bothered reviewing the system and its configuration since it was installed.
-
Morale within the IT department is at an all-time low. The company feels that morale is an issue that should be dealt with by department managers.
-
Two people working on a project are related by marriage. They are the only members of the team who are related in any way.
-
A branch office has been opened in a location where hurricanes have hit two years previously. The company's main office and other branch offices are located at opposite ends of the country.
-
A new server has been added to the network.
Answers to Exercise Questions
-
The antivirus software failing on the file server is a risk. If the antivirus software is not working, then a virus could potentially infect the server and cause damage that may result in loss. If antivirus software had been installed on workstations, this would have served as a backup to any viruses that may infect the network, but this is not the case. Also, because the network administrator has not bothered reviewing the system or configuration since the antivirus software was installed, it is possible that the antivirus software on the server has failed without their knowing about it.
-
Morale issues can be a risk. If morale is at a low point, it can impede the productivity of staff and cause other problems. Because the company removes itself from morale issues, and makes it a departmental issue, morale will fail to improve if the departmental manager fails to do anything about it. Such a problem could escalate into disgruntled employees becoming a greater security threat.
-
Two people working on a project that are related in some way is not a risk. There is no likelihood on this fact alone that could result in loss of some kind for the company.
-
The fact that hurricanes have struck the area where the branch office is located makes the possibility of such a natural disaster occurring again a risk. Because the company has no other offices nearby, if a disaster occurred, business functions might not be easily transferred to another location.
-
A new server being added to a network is not a risk in itself; however, the services that the server will support (Web, Telnet, FTP, and so forth) could present a risk and an additional potential loss to the company.
Education
Education and documentation is a vital part of any secure system. By not sharing information about risks, facts about the system, best practices to perform, and other important details, a situation may be created that puts systems and security at risk. If members of a company cannot recognize growing threats and other individuals do not know how to deal with them, then a risk can develop into a devastating problem. To effectively manage the risks facing a project or company, it is important that everyone involved-from the lowest to highest levels of the company-be informed and educated.
Decisions are based on risks, so it is important that decision makers are aware of risks facing a project or company. If management is unaware of certain risks, then decisions will be based on false information. For example, say a software development project is running late, and the project team has not notified anyone about the risk of missing the project completion date. This means that advertising, sales, and other departments would inform prospective customers that the software would be ready by an inaccurate date, and prepare for getting the product to customers on that date. When the release date comes and the product is not ready, the company would look incompetent and possibly millions of dollars would be lost on promoting the non-existent software. As seen by this, even if one area of a company is experiencing a problem, the effects can be far reaching. If decision makers had been given proper information about risks, those risks could have driven the decisions to deal with the possibility of a problem. The release date could have been revised, and the impact of the risk would not have been so significant.
Risk management requires a continuing program of executive education on potential threats. By giving management the ability to understand risks, they will be able to make better-informed decisions. While management will not need to understand every facet of every risk, they will need to have enough knowledge to follow business cases that recommend products and services used to mitigate risks. Continuing education on new and changing risks in an organization will also enable decision makers to work with IT staff in managing those risks. For example, every organization runs on money and every IT department is budgeted a limited amount of that money. By training decision makers on potential threats, they will be able to make informed decisions on budgeting issues needed to manage risks, and justify expenditures made by IT staff.
Because a major reason for risk management is to make systems more secure, it is important for users to also be aware of potential threats. Knowledgeable users can be an important line of defense, as they are in a position to identify problems as they occur, and report them to the necessary persons. If a system fails or functions unexpectedly, it is often the users who identify these issues first. Some users may find it difficult to understand why they need to take on the added responsibility of reporting problems that are not directly related to their jobs. However, education on how different problems can effect their job or personal safety can help them understand the need to report early indicators of various threats. Failing to educate them on specific risks dismisses a major resource that can be used to report emerging problems.
Despite these benefits, it is also important to remember that users are often the largest, least controlled variable in network security. Education makes this variable more stable, so that they are less likely to perform actions that compromise security. Users who are knowledgeable in how to perform certain tasks properly are less likely to put security at risk.
Training should be provided on information security policies, which outline the expectations of the organization in terms of security issues and how employees should handle information. Users who have an understanding of confidentiality and nondisclosure policies will not be as likely to reveal sensitive information, transmit classified data over the Internet, or provide access to unauthorized users. In addition, users who know how to change their passwords monthly, know that they should not use previously used passwords, and understand how to create strong passwords that will make the system more secure. Educating users on these and other security issues minimizes the risk of users making mistakes that compromise security.
An especially important target of education is the emergency response team, who will respond to any incidents that occur. If a risk becomes a genuine problem, it is important for members of such a team to know how to effectively deal with the situation. They should have a clear understanding of what their responsibilities are and what procedures they are to follow. Such information may be included as part of a business continuity plan or in a disaster recovery plan.
The emergency response team should also be aware of any relevant documentation and have easy access to it. Procedures on how to properly deal with an incident or fix a problem should be stored in a centralized location, such as printed and stored in a binder or filing cabinet, as well as stored electronically on a file or Web server. Organizational policies should also be readily available, so that they are not violated while fixing a problem. For example, if classified information should not be available to the public, then such information should not be made available to any third parties doing repairs on a system. By providing reference material in an accessible location, members of the team will not be required to solely rely on remembering information.
Methods of Providing Education
Education can be provided to members of an organization through a wide variety of methods, the most common of which is training sessions. Such sessions can be done in a classroom setting or one-on-one. In either case, a designated trainer or member of the IT staff teaches users the proper methods and techniques that should be used to perform their jobs.
In classroom or one-on-one training sessions, training handouts are often given to detail how certain actions are performed and the procedures that should be followed. These handouts can be referred to when needed, but may prove disastrous if this material falls into the wrong hands. If sensitive information is included in such training material, it is important to ensure that trainees are aware of confidentiality agreements and security policies within the organization, which would prohibit the information being shared outside of the organization.
Policies, procedures, and other documentation should be available through the network, as it will provide an easy, accessible, and controllable method of disseminating information. For example, a directory on the server can be made accessible to everyone through a mapped drive, allowing members of the organization to view documents at their leisure. A directory that is only accessible to IT staff can also be used to provide easy access to procedures, which may be referred to when problems arise. By using network resources in this way, members of an organization are not left searching for where information is located or left unaware of its existence.
Many companies utilize Web technologies internally to provide a corporate intranet for members of the organization. Sections of the internal Web site can be dedicated to a variety of purposes, for example, providing read-only copies of policies, procedures, and other documentation. A section of the site can even provide access to interactive media so that users can train themselves by viewing PowerPoint presentations, AVI and MPEG movies, and other resources for self-training.
IT staff and support specialists can also benefit from online resources. Although some claim otherwise, no one in the field of computer technology can know about every piece of software or hardware ever created. There are far too many current and legacy systems to understand, so relying on the expertise of others is important. When in doubt, consulting resources on the Internet can be essential to solving problems correctly.
Knowledge bases are databases of information providing information on the features of various systems and solutions to problems that others have reported. For example, if you were experiencing a problem with Microsoft software, you could visit their knowledge base at http://support.microsoft.com. If you were experiencing problems with Novell software, you could visit their knowledge base at http://support.novell.com. Many software and hardware manufacturers provide supports sites that contain valuable information. Not using these sites when you need them is a mistake.
Analysis
Knowing that a risk simply exists is not enough to control it. If an event threatens a project or company, employees of the organization must know whom to contact to deal with the situation, and those people in turn must know what to do. To manage risks effectively, it is important to create documentation that designates people to call in emergencies, and information that may be required to deal with problems. These lists should provide contact information, key personnel, vendors, contractors, manufacturers, and other individuals to be called to deal with incidents. Such lists can be referred to when needed to ensure that the right person is called to deal with an issue.
When creating such documentation, key personnel should be reviewed to determine their skill sets and knowledge of systems, procedures, and responsibilities. This is crucial, as not every member of an emergency response team will have duplicate experience or education. For example, a network administrator may have expertise with solving Windows 2000 Server problems, but does not know anything about how to repair the company's Web site if it were hacked. Even if the network administrator did have an understanding of the Web site and how to fix the problem, it is possible that they would not have the appropriate security to make changes to the site. To deal with an efficiency problem, a clear understanding of what each person can and cannot do must be established.
Third parties should also be reviewed, so that the security administrator has a comprehensive list of vendors, contractors, manufacturers, and other companies and individuals that support systems used by their organization. These outside firms may need to be called because the problem is beyond you're the administrator's expertise. Support personnel with these companies may be available to deal with such instances and assist in answering questions and finding solutions quickly.
In cases of software and equipment, calling a third party may be the best or only solution to solving a problem. If a bug within third party software was the cause of a problem, the administrator would be unable to reprogram it. For equipment that fails, warrantees may exist, so it is a waste of time and money fixing the problem. In other cases, fixing the problem will void a warrantee.
Third parties are also often used because it would be impossible to install and support certain technologies used by an organization. For example, if a company wanted to connect two networks in different parts of the company, they would not hand the network administrator a shovel and a fiber-optic cable, and say "start digging." Third parties, such as telephone companies, may be used to provide connectivity between branch offices, and would be called if a problem existed with the connection.
Contact lists must be reviewed regularly to ensure they contain up-to-date information. These are lists that contain the name, phone number, pager number, and other facts on how to contact key personnel and other parties when needed. It is important to review contact lists regularly, as members of an emergency response team may move to other addresses or change phone numbers. In the case of third parties, some companies may have gone out of business, merged with other companies, or are no longer used by an organization because the systems they support are not used anymore. Contact information is vital in emergencies, so time will not be wasted trying to track down someone while the problem escalates.
Contact Lists May Make the Difference When Fixing a Problem
Contact lists and other elements of risk management are not merely used when major disasters occur, but also when IT staff and other responders need to take care of problems during off-hours. Many companies do not have IT staff on site 24 hours a day, 7 days a week, but only during normal business hours during the week. On weekends and holidays, members of staff will be on-call. In such instances, contact lists may be required to fix problems.
On one occasion when I was on-call, a new system was not functioning properly, preventing numerous employees from doing their jobs. I tried doing several things, and it seemed to fix the problem, but a few hours later, I was called back. I restarted the server software, and again it seemed to fix the problem temporarily. I even restarted the server itself, but again it was a temporary solution. When I was finally able to get a hold of the IT staff member responsible for the system, he said I should call the vendor for support and that they could dial in and fix the problem. Since the contact list had never been updated after the new system was installed, I was unaware of the 24/7 support, did not have the phone number, and needed to scramble around trying to find it. When I did contact them, they fixed the problem in 15 minutes. If the contact list had been updated, the situation could have been fixed permanently the day before, and the company would have saved having to pay overtime for each time I was called in.
When updating lists of third parties that provide support to your organization's systems, you should include information on the type of support they provide. Some firms may provide limited support, while others provide support 24 hours a day, 7 days a week. By understanding when support is on hand, time will not be wasted trying to acquire assistance where it is not available.
Inventories are also important to risk management, as the purpose of managing risks is to protect the assets within an organization that hold some value. As will be seen later in this chapter, assets need to be assigned a value to determine their priority and potential of loss if a disaster occurred. Imagine a fire occurring and burning up all the computers in a department. By consulting the inventory, the losses can be recouped through insurance, by showing which machines were destroyed. When new machines are acquired, the inventory can again be used to set up the new equipment with the same configurations as those they are replacing.
Inventories and logs are also used as a reference of common tasks, to ensure they were done and to provide a record of when they were performed and who completed the job. For example, backup logs are often used to record what data was backed up on a server, which tape it was placed on, when the backup occurred, who set up the backup, and the type of backup that was performed. When certain information is needed, the log can then be referred to, so that the correct tape can be used to restore the backup. Similar logs and inventories can also be used to monitor diagnostics that are run, perform tests, and other tasks that are routinely carried out.
Another important type of documentation is one that records changes to a system. Change control documentation provides information of changes that have been made to a system, and often provides back-out steps that show how to restore the system to its previous state. Without this, changes made to a system could go unrecorded causing major issues in the future. Imagine starting a job as the new network administrator, and finding that the only documents about the network were the systems architecture documentation that your predecessor created twenty years ago, when the system was first put in. After years of adding new equipment, updating software, and making other changes, the current system would barely resemble the way it was originally. If change documentation had been created, you would have had a history of those changes, which could have been used to update the system's architecture documentation.
Change documentation can provide valuable information, which can be used in troubleshooting problems and upgrading systems. First, it should state why a change occurred. Changes should not appear to be for the sake of change but have good reason such as fixing security vulnerabilities, hardware no longer being supported by vendors, new functionality, or any number of other reasons. The documentation should also outline how these changes were made, detailing the steps performed. At times, an administrator may need to justify what was done, or need to undo the changes and restore the system to a previous state because of issues resulting from the change. In such cases, the change documentation can be used as a reference for backtracking the steps taken.
Testing
The poet Robert Burns wrote that the best laid plans of mice and men often go awry, and this is often found to be true when creating plans that deal with recovery from a disaster. Plans may be flawed, and elements that need protecting may be missed. It is vital that plans are tested well before they are needed. By doing so, security administrators can determine if existing plans address all aspects of a problem, if current strategies work, and if any modifications or additions need to be made.
Dry runs of the business continuity plan and disaster recovery plan should be staged so that everyone knows what they are expected to do during a crisis, and whether elements of the plan operate as expected. Business continuity plans are made up of numerous plans that are focused on restoring the normal business functions of the entire business, while disaster recovery plans focus on restoring the technology and data used by that business. A dry run involves everyone pretending that a particular type of disaster has occurred, and having them perform their required activities to deal with it. In doing so, tools used to deal with problems are implemented, procedures are followed, and other elements of the plan are activated and analyzed for their effectiveness. Disaster recovery plans and business continuity plans are discussed in greater detail later in this chapter.
| Exam Warning | Remember that dry runs of the business continuity plan and disaster recovery plan must be performed by members of the incident response team and any other parties that will be involved in dealing with disasters. These dry runs are necessary for training purposes, and allow members to practice the tasks necessary to deal with incidents. Dry runs will also reveal any problems in these plans, which can then be fixed before the plans are needed. |
Vulnerabilities should also be regularly assessed. A vulnerability is a weakness in a system, or the lack of a safeguard to protect the system. When either of these exists, non-authorized persons (such as hackers) or malicious programs can exploit the vulnerability. To avoid such problems, regular assessments should be made to determine whether vulnerabilities exist or pose new threats. For example, a known vulnerability may exist in a server's operating system, which could be exploited if a hacker gained entry to the internal network. While this was never an issue before, adding Internet access for networks may change the situation and allow a hacker to take advantage of it. Regular assessments would look at conditions and system weaknesses.
Validation
Testing determines whether a process works, and validation ensures that it works correctly. Validation methods may be used to ensure that data has been entered correctly into systems, or is correctly restored after a disaster occurs. This is done by performing both internal audits of processes and by using third-party validation.
Data is a major asset of organizations, so it is important to validate whether information that is entered is accurate. If an employee enters incorrect data or alters or deletes existing data, loss can occur in a number of ways. For example, if a clerk entered the wrong amount into a field, a customer could be overcharged or undercharged for a product. The result would respectively leave the customer with a poor opinion of the company, or result in the company losing money from the sale. If the errors are repetitive, then considerable amounts of money could be lost. Worse yet, if incorrect information were entered into other systems, the results could be devastating to people the organization serves. Just imagine a clerk at the Internal Revenue Service (IRS) or a credit company entering the wrong data into someone's record. In doing so, a person may have to pay a sizeable amount of taxes by mistake, or their credit rating could be damaged. Because of the implications associated with bad data, validation is imperative to ensuring that any data that is entered is correct.
When internal validation is performed, members of an organization carry out examinations internally. Designated members of the company are used to check data and verify that anything entered into the system is correct. Because checking every single record may be impossible in certain situations, these audits may only check a limited number of records at random. If problems are found with a certain employee's entries, then a more comprehensive review of that person's work may be required. Logs generated by systems may also be reviewed to determine whether tampering has occurred, and to ensure that records that were deleted were supposed to be purged from the system.
Internal validation may be used to review data input through software functionality or as part of a process. For example, a software development team may create a financial program, and then validate that formulas calculated by the software generate the correct result. If a person enters 1+1, they need to confirm that the answer equals 2. Many programs will also force a person to enter information into mandatory fields, preventing inaccurate or incomplete data from being entered. You may have experienced such validation functions when filling out registration information for software, in which you must enter your name, address, or other mandatory information. By forcing a person to provide the data, it helps to ensure that the information is complete.
External validation involves audits being performed by third parties that are external to the organization. The third party firm usually specializes in a particular area, such as security, accounting, or other areas. Their expertise helps protect the company from risks related to the processes or data being audited. For example, it is common for bookkeepers to be audited by accounting firms, to ensure that data entered into systems are correct. Validating these records helps protect the company from discrepancies in the books, financial loss, identity crimes (such as fraud or embezzlement), and may safeguard the company from additional audits conducted by the IRS. While validation through third parties costs additional money, the benefits from such audits can outweigh the expense.
Validation is also done to identify whether business functions can be restored in the event of an incident. The business continuity plan and disaster recovery plan are used to ensure that data is restored to its original state, so that business can resume normal business functions. For example, data is a major asset of companies, so backups need to be regularly performed. In doing so, copies of data are stored on tape, CD-ROM, or other media. However, security administrators do not want to wait until a disaster occurs to find out that backed up data cannot be restored. If data cannot be restored, then all the work of backing it up is pointless. To validate the backup process, they could simply restore data to a directory on a hard drive, and check to see that files can be opened and data within the file is correct and uncorrupted. Validation provides a guarantee that processes used in risk management should work when needed.
When employing safeguards to deal with potential threats to a company, validation methods should be performed on a regular basis. If data has been inaccurate or processes have not worked for a considerable length of time, then so much damage could have been done that it would be difficult (if not impossible) to correct the situation. To use the previous example of backing up data, imagine if a network administrator thought that data was being backed up properly, only to find that it had not been done for the last year. If someone needed an important database file that was accidentally deleted two months ago, that information would be irretrievable. By validating processes and data regularly, situations involving inaccurate data or nonfunctioning processes can be identified and dealt with quickly.
Many companies voluntarily validate risk management processes externally to determine whether existing security or changes to security systems are effective. Companies may hire outside firms to test and validate security changes to systems. In doing so, tests are performed to ensure the changes, and attempts may even be made to attempt hacking into systems to identify vulnerabilities.
To adhere to regulations, agreements, or legislation, validation by third parties may be a requirement. Systems may contain classified information that cannot be accessed, deleted, or modified without authorization. To secure systems or provide users with additional functionality, these rules, agreements or laws may require certain parties to approve the changes before they are implemented. For example, a police department may have access to an external network, which allows them to perform cross-country searches on offenders. If the police department decided to add Internet access and a new firewall, these changes would need to be reviewed and approved by the external agency they are connected to. Failure to do so could result in losing access to the system that allows cross-country searches to be performed. Having the external party analyze changes to the system validates that the changes will not create security issues.
|
|
EAN: 2147483647
Pages: 135