Hack 88. Automatically Collect Syndicated Feeds
| < Day Day Up > |
|
Autodiscover RSS and Atom feeds as you browse, and then generate a subscriptions file you can import into any news aggregator. Are you new to the world of syndication? If you've heard about using syndicated RSS or Atom feeds to keep up with your favorite sites in a news aggregator, here's an easy way to get started. Install the Feed Collector user script in this hack, and then simply visit the sites you visit regularly. Feed Collector will find the syndicated feeds automatically. At the bottom-right corner of your browser window, you'll see a running total of the number of feeds collected so far. When you're ready, you're one click away from creating a subscriptions file that contains all the sites you've visited. The subscriptions file is in an XML format that's compatible with virtually every news aggregator.
10.5.1. The CodeThis user script runs on all web pages. The code is longer than most of the other hacks in this book, but it breaks down into four distinct parts:
Save the following user script as feedcollector.user.js: // ==UserScript== // @name Feed Collector // @namespace http://diveintomark.org/projects/greasemonkey/ // @description collect auto-discovered feeds in visited pages // @include http://* // ==/UserScript== function getPageFeeds() { var dateNow = new Date(); var elmPossible = document.evaluate("//*[@rel][@type][@href]", document, null, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null); var arFeeds = new Array(); for (var i = 0; i < elmPossible.snapshotLength; i++) { var elm = elmPossible.snapshotItem(i); if (!elm.rel) { continue; } if (!elm.type) { continue; } if (!elm.href) { continue; } var sNodeName = elm.nodeName.toLowerCase(); if ((sNodeName != 'link') && (sNodeName != 'a')) { continue; } var sRel = elm.rel.toLowerCase(); var bRelIsAlternate = false; var arRelValues = sRel.split(/\s/); for (var j = arRelValues.length - 1; j >= 0; j--) { bRelIsAlternate = bRelIsAlternate || (arRelValues[j] == 'alternate'); } if (!bRelIsAlternate) { continue; } var sType = elm.type.toLowerCase().trim(); if ((sType != 'application/rss+xml') && (sType != 'application/atom+xml') && (sType != 'text/xml')) { continue; } var urlFeed = elm.href.trim(); var sTitle = elm.title.trim() || ''; arFeeds.push({href: urlFeed, title: sTitle, type: sType, homepage: location.href}); } return arFeeds; } function getHistoryCount() { return GM_getValue('count', 0); } function getHistoryItem(iHistoryIndex) { var urlFeed = GM_getValue(iHistoryIndex + '.href', ''); if (!urlFeed) { return null; } var sTitle = GM_getValue(iHistoryIndex + '.title', ''); var sType = GM_getValue(iHistoryIndex + '.type', ''); var sHomepage = GM_getValue(iHistoryIndex + '.homepage', ''); return {href: urlFeed, title: sTitle, type: sType, homepage: sHomepage}; } function getAllHistoryItems() { var iHistoryCount = getHistoryCount(); var arFeeds = new Array(); for (var i = 0; i < iHistoryCount; i++) { arFeeds.push(getHistoryItem(i)); } return arFeeds; } function findHistoryItemByURL(urlFeed) { var iHistoryCount = getHistoryCount(); for (var i = 0; i < iHistoryCount; i++) { var oHistory = getHistoryItem(i); if (oHistory.href == urlFeed) { return i; } } return -1; } function addToHistory(oFeedInfo) { var iHistoryCount = getHistoryCount(); if (findHistoryItemByURL(oFeedInfo.href) != -1) { return; } if (document.title && oFeedInfo.title) { sFeedTitle = document.title + ' - ' + oFeedInfo.title; } else if (document.title) { sFeedTitle = document.title; } else if (oFeedInfo.title) { sFeedTitle = oFeedInfo.title; } else { sFeedTitle = oFeedInfo.href; } sFeedTitle = sFeedTitle.replace(/\s+/g, ' '); sFeedTitle = sFeedTitle.replace(/[^A-Za-z0-9\- ]/g, ''); var sType = oFeedInfo.type; sType = sType.substring(sType.indexOf('/') + 1); if (sType.indexOf('+') != -1) { sType = sType.substring(0, sType.indexOf('+')); } else { sType = 'rss'; } GM_setValue(iHistoryCount + '.href', oFeedInfo.href); GM_setValue(iHistoryCount + '.title', sFeedTitle); GM_setValue(iHistoryCount + '.homepage', oFeedInfo.homepage); GM_setValue(iHistoryCount + '.type', sType); GM_setValue('count', iHistoryCount + 1); } function clearHistory() { var iHistoryCount = getHistoryCount(); for (var i = 0; i < iHistoryCount; i++) { GM_setValue(i + '.href', ''); GM_setValue(i + '.title', ''); GM_setValue(i + '.homepage', ''); GM_setValue(i + '.type', ''); } GM_setValue('count', 0); } function appendNew(elmRoot, elmParent, sNodeName) { var elmChild = elmRoot.createElement(sNodeName); elmParent.appendChild(elmChild); return elmChild; } function buildSubscriptionFile() { var oParser = new DOMParser(); var elmRoot = oParser.parseFromString('<opml/>', 'application/xml'); elmRoot.documentElement.setAttribute('version', '1.0'); var nodeComment = elmRoot.createComment( 'Save this using "File/Save Page As…", and then import it ' + 'into your news aggregator.'); elmRoot.documentElement.appendChild(nodeComment); var elmHead = appendNew(elmRoot, elmRoot.documentElement, 'head'); var elmTitle = appendNew(elmRoot, elmHead, 'title'); elmTitle.appendChild(elmRoot.createTextNode('Feed Collector')); var dateNow = new Date(); var elmDate = appendNew(elmRoot, elmHead, 'dateCreated'); elmDate.appendChild(elmRoot.createTextNode(dateNow.toGMTString())); var elmOwnerName = appendNew(elmRoot, elmHead, 'ownerName'); var elmBody = appendNew(elmRoot, elmRoot.documentElement, 'body'); var elmOutline = appendNew(elmRoot, elmBody, 'outline'); elmOutline.setAttribute('title', 'Subscriptions'); var iHistoryCount = getHistoryCount(); var arFeeds = getAllHistoryItems(); for (var i = 0; i < iHistoryCount; i++) { var oFeedInfo = arFeeds[i]; var elmItem = appendNew(elmRoot, elmOutline, 'outline'); elmItem.setAttribute('title', oFeedInfo.title); elmItem.setAttribute('htmlUrl', oFeedInfo.homepage); elmItem.setAttribute('type', oFeedInfo.type); elmItem.setAttribute('xmlUrl', oFeedInfo.href); } var serializer = new XMLSerializer(); return serializer.serializeToString(elmRoot); } function displayFeeds(event) { var sSubscriptionData = buildSubscriptionFile(); GM_openInTab('data:application/xml,'+ sSubscriptionData); event.preventDefault(); } function clearFeeds(event) { var iHistoryCount = getHistoryCount(); clearHistory(); var elmFeedCollector = document.getElementById('feedcollector'); if (elmFeedCollector) { elmFeedCollector.parentNode.removeChild(elmFeedCollector); } event.preventDefault() } String.prototype.trim = function() { var s = this; s = s.replace(/^\s+/, ''); s = s.replace(/\s+$/, ''); return s; } var arFeeds = getPageFeeds(); for (var i = 0; i < arFeeds.length; i++) { addToHistory(arFeeds[i]); } var iHistoryCount = getHistoryCount(); if (!iHistoryCount) { return; } var elmWrapper = document.createElement('div'); elmWrapper.id = 'feedcollector'; elmWrapper.innerHTML = '<div style="position: fixed; bottom: 0; ' + 'right: 0; padding: 1px 4px 3px 4px; background-color: #ddd; ' + 'color: #000; border-top: 1px solid #bbb; border-left: 1px ' + 'solid #bbb; font-family: sans-serif; font-size: x-small;">' + '<a href="#" title="Display collected feeds" ' + ' style="background-color: transparent; ' + 'color: black; font-size: x-small; font-family: sans-serif; ' + 'text-decoration: none;">' + iHistoryCount + ' feed' + (iHistoryCount > 1 ? 's' : '') + ' collected</a> · ' + '[<a href="#" title="Clear list of collected feeds" ' + ' style="background-color: transparent; ' + 'color: black; font-size: x-small; font-family: sans-serif; ' + 'text-decoration: none;">clear</a>]</div>'; document.body.insertBefore(elmWrapper, document.body.firstChild); document.getElementById('feedcollectordisplay').addEventListener( 'click', displayFeeds, true); document.getElementById('feedcollectorclear').addEventListener( 'click', clearFeeds, true); 10.5.2. Running the HackAfter installing the user script (Tools Figure 10-6. Three feeds collected so far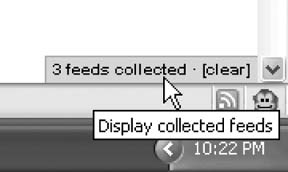 When you're ready to import your collected feeds into your news aggregator, simply click the "Display collected feeds" link. This generates an XML subscription file in a format supported by all aggregators, as shown in Figure 10-7. Figure 10-7. XML subscription file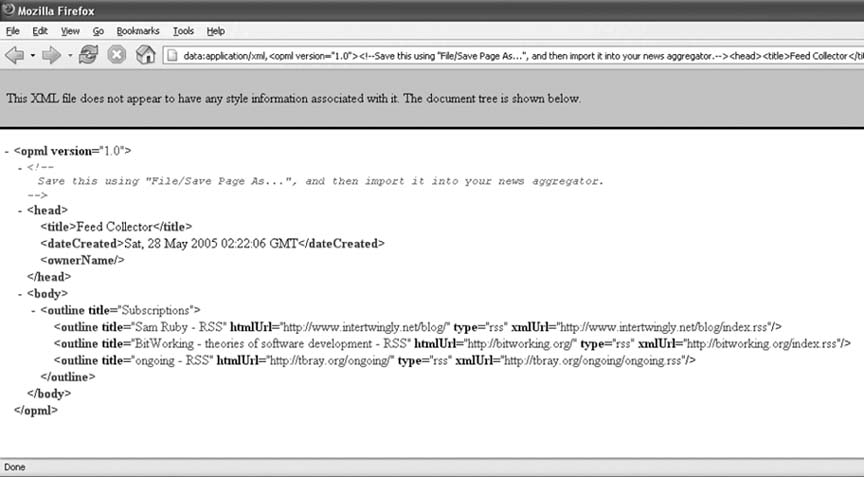 Save this subscription file to your local computer by selecting Save Page As… from the File menu. I called mine subscriptions.xml, but you can name it anything you like. Now, go to your news aggregator and find the Import Subscriptions option. In Bloglines, log in to get to My Feeds, and then choose Edit Figure 10-8. Importing subscriptions in Bloglines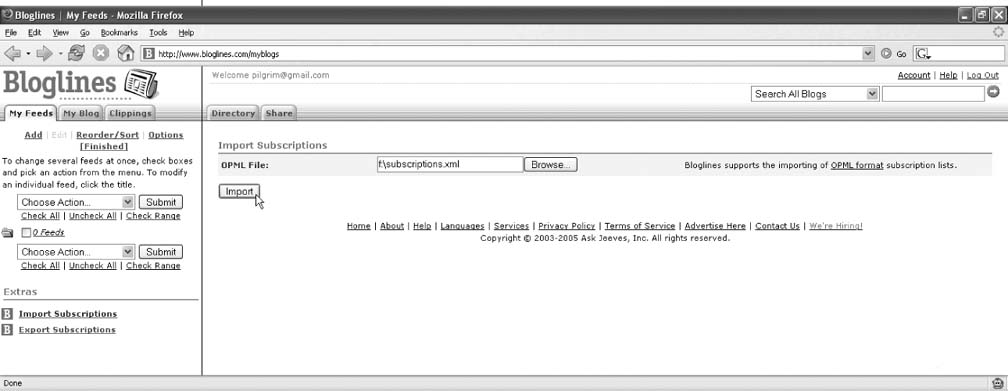 Click Import, and Bloglines will import your collected subscriptions. As shown in Figure 10-9, in this case, all three sites were imported successfully. Figure 10-9. Feeds imported successfully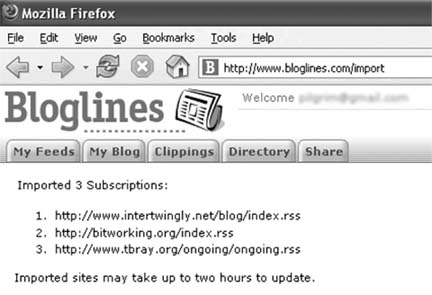 If you click My Feeds again, you will see the three imported subscriptions, as shown in Figure 10-10. Figure 10-10. Bloglines with imported subscriptions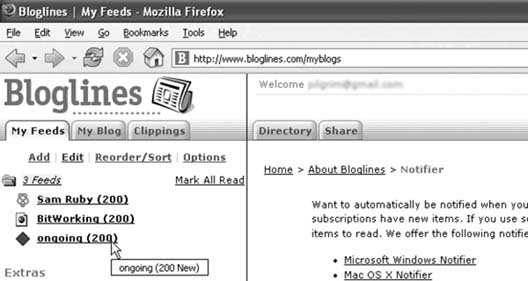 Bloglines remembers all past items, but it maxes out at showing you the most recent 200 for each site. Looks like I have a lot of reading to do! |

 Install This User Script), start visiting your favorite syndication-enabled sites. I went to three of my personal favorites: Sam Rubys (http://www.intertwingly.net/blog/), Joe Gregorio's (http://bitworking.org), and Tim Bray's (http://tbray.org/ongoing/). In the bottom-right corner of your browser window, you will see an updated count of the number of feeds collected so far, as shown in Figure 10-6.
Install This User Script), start visiting your favorite syndication-enabled sites. I went to three of my personal favorites: Sam Rubys (http://www.intertwingly.net/blog/), Joe Gregorio's (http://bitworking.org), and Tim Bray's (http://tbray.org/ongoing/). In the bottom-right corner of your browser window, you will see an updated count of the number of feeds collected so far, as shown in Figure 10-6. Import Subscriptions. Click Browse and select the subscription file you just saved, as shown in Figure 10-8.
Import Subscriptions. Click Browse and select the subscription file you just saved, as shown in Figure 10-8.| < Day Day Up > |
EAN: 2147483647
Pages: 168