Browsing the Web
| < Day Day Up > |
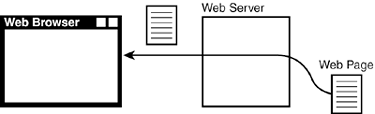
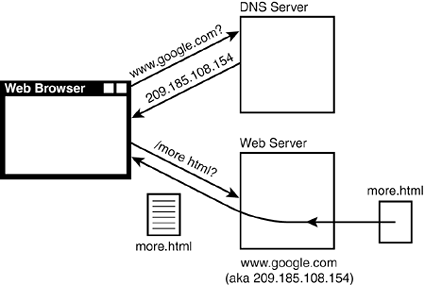
| The Web, as you know it, is simply the interaction between two different systems trying to exchange data. The system that is trying to fetch a web page is known as the client . The client system usually runs a program called a web browser, such as Safari, Firefox, Internet Explorer, Opera, and so on. This is the extent of the Web that you're used to using every day. The web browser provides navigation buttons and bookmarks and is responsible for drawing web pages on your screen. On the other end of the Web is a system known as the web server . This system takes the client's request for a page, retrieves the page from a local disk, and sends it to the client ”your web browser. This interaction is shown in Figure 21.1. Figure 21.1. Web browser fetching a page. Fetching a Static Web PageA client requests a web page by examining a Uniform Resource Locator (URL) to determine the protocol, server, and request to make on that server. A typical URL might look like the following: http://www.google.com:80/more.html The parts of the URL can be broken down like this:
The client then follows these steps for http (see Figure 21.2):
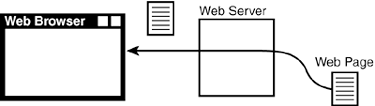
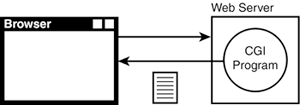
Figure 21.2. Requesting a page. The nitty-gritty of the "conversation" between the client and the server is covered in depth in Hour 24, "Manipulating HTTP and Cookies." Dynamic Web Content ”The CGIDuring a normal web page fetch, the server simply locates the document requested , retrieves it from its disk storage, and sends it to the client, as illustrated in Figure 21.3. Figure 21.3. Static web page fetch. The server in Figure 21.3 doesn't process the data at all; it simply examines the request and passes the requested data back to the client. One method to create dynamic content on the Web is through the use of CGI programs. CGI is an agreed-upon method that web servers use to run programs on the server to generate web content. When a URL indicates to a server that a CGI program should be run to generate the content, the server starts the program, the program generates the content, and the server passes the content back to the client, as illustrated in Figure 21.4. Figure 21.4. CGI script-generated web page. Each time the client requests a page that's really a CGI program, the following occurs:
The CGI program can be any kind of program. It can be a Perl script, which is what you'll learn about here. It can also be programmed in C, the Unix shell, Pascal, Lisp, TCL, or nearly any other programming language. The fact that many CGI programs are written in Perl is a happy coincidence . Perl happens to be very well-suited to writing programs that deal with text, and the output of CGI programs is often text. The output of CGI programs can be almost anything, however. It can be images, HTML-formatted text, Zip files, streaming video, or any other kinds of content you might find on the Web. For the most part, the CGI programs you'll be writing will generate HTML-formatted text. By the Way CGI is not a language; it has nothing to do specifically with Perl, it has nothing to do with HTML, and it has very little to do with HTTP. It's simply an agreed-upon interface between web servers and programs run on their behalf . This informal interface wasn't codified until October 2004 in RFC 3875. You can read about this at http://www.ietf.org. You'll pick up bits and pieces of these details over the next four hours. |
| < Day Day Up > |
EAN: 2147483647
Pages: 241