Forward Error Correction
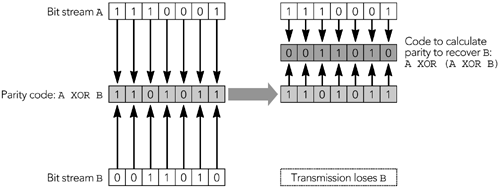
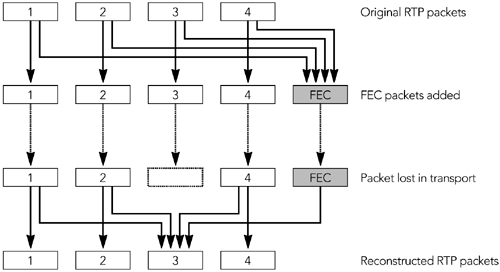
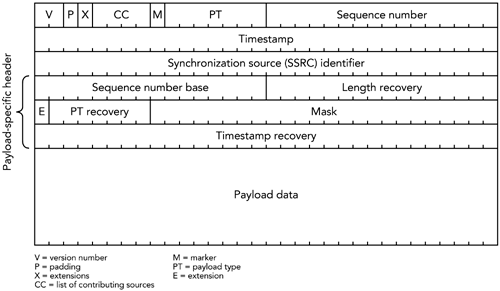
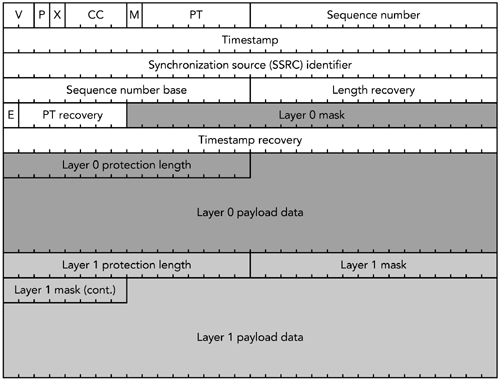
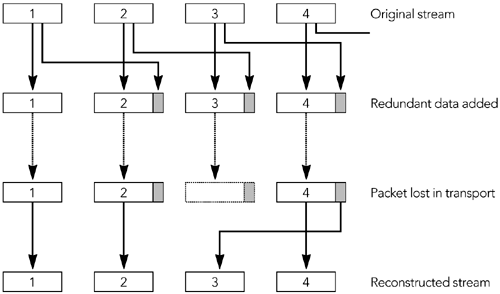
| Forward error correction (FEC) algorithms transform a bit stream to make it robust for transmission. The transformation generates a larger bit stream intended for transmission across a lossy medium or network. The additional information in the transformed bit stream allows receivers to exactly reconstruct the original bit stream in the presence of transmission errors. Forward error correction algorithms are notably employed in digital broadcasting systems, such as mobile telephony and space communication systems, and in storage systems, such as compact discs, computer hard disks, and memory. Because the Internet is a lossy medium, and because media applications are sensitive to loss, FEC schemes have been proposed and standardized for RTP applications. These schemes offer both exact and approximate reconstruction of the bit stream, depending on the amount and type of FEC used, and on the nature of the loss. When an RTP sender uses FEC, it must decide on the amount of FEC to add, on the basis of the loss characteristics of the network. One way of doing this is to look at the RTCP receiver report packets it is getting back, and use the loss fraction statistics to decide on the amount of redundant data to include with the media stream. In theory, by varying the encoding of the media, it is possible to guarantee that a certain fraction of losses can be corrected. In practice, several factors indicate that FEC can provide only probabilistic repair. Key among those is the fact that adding FEC increases the bandwidth of a stream. This increase in bandwidth limits the amount of FEC that can be added on the basis of the available network capacity, and it may also have adverse effects if loss is caused by congestion. In particular, adding bandwidth to the stream may increase congestion, worsening the loss that the FEC was supposed to correct. This issue is discussed further in the section titled At the Sender, under Implementation Considerations, later in this chapter, as well as in Chapter 10, Congestion Control. Note that although the amount of FEC can be varied in response to reception quality reports , there is typically no feedback about individual packet loss events, and no guarantee that all losses are corrected. The aim is to reduce the residual loss rate to something acceptable, then to let error concealment take care of any remaining loss. If FEC is to work properly, the loss rate must be bounded, and losses must occur in particular patterns. For example, it is clear that an FEC scheme designed to correct 5% loss will not correct all losses if 10% of packets are missing. Less obviously, it might be able to correct 5% loss only if the losses are of nonconsecutive packets. The key advantage of FEC is that it can scale to very large groups, or groups where no feedback is possible. 54 The amount of redundant data added depends on the average loss rate and on the loss pattern, both of which are independent of the number of receivers. The disadvantage is that the amount of FEC added depends on the average loss rate. A receiver with below-average loss will receive redundant data, which wastes capacity and must be discarded. One with above-average loss will be unable to correct all the errors and will have to rely on concealment. If the loss rates for different receivers are very heterogeneous, it will not be possible to satisfy them all with a single FEC stream (layered coding may help; see Chapter 10, Congestion Control). Another disadvantage is that FEC may add delay because repair cannot happen until the FEC packets arrive. If FEC packets are sent a long time after the data they protect, then a receiver may have to choose between playing damaged data quickly or waiting for the FEC to arrive and potentially increasing the end-to-end delay. This is primarily an issue with interactive applications, in which it is important to have low delay. Many FEC schemes exist, and several have been adopted as part of the RTP framework. We will first review some techniques that operate independently of the media formatparity FEC and ReedSolomon encodingbefore studying those specific to particular audio and video formats. Parity FECOne of the simplest error detection/correction codes is the parity code. The parity operation can be described mathematically as an exclusive-or (XOR) of the bit stream. The XOR operation is a bitwise logic operation, defined for two inputs in this way: 0 XOR 0 = 0 1 XOR 0 = 1 0 XOR 1 = 1 1 XOR 1 = 0 The operation may easily be extended to more than two inputs because XOR is associative: A XOR B XOR C = (A XOR B) XOR C = A XOR (B XOR C) Changing a single input to the XOR operation will cause the output to change, allowing a single parity bit to detect any single error. This capability is of limited value by itself, but when multiple parity bits are included, it becomes possible to detect and correct multiple errors. To make parity useful to a system using RTP-over-UDP/IPin which the dominant error is packet loss, not bit corruptionit is necessary to send the parity bits in a separate packet to the data they are protecting. If there are enough parity bits, they can be used to recover the complete contents of a lost packet. The property that makes this possible is that A XOR B XOR B = A for any values of A and B . If we somehow transmit the three pieces of information A , B , and A XOR B separately, we need only receive two of the three pieces to recover the values of A and B . Figure 9.1 shows an example in which a group of seven lost bits is recovered via this process, but it works for bit streams of any length. The process may be directly applied to RTP packets, treating an entire packet as a bit stream and calculating parity packets that are the XOR of original data packets, and that can be used to recover from loss. Figure 9.1. Use of Parity between Bit Streams to Recover Lost Data The standard for parity FEC applied to RTP streams is defined by RFC 2733. 32 The aim of this standard is to define a generic FEC scheme for RTP packets that can operate with any payload type and that is backward-compatible with receivers that do not understand FEC. It does this by calculating FEC packets from the original RTP data packets; these FEC packets are then sent as a separate RTP stream, which may be used to repair loss in the original data, as shown in Figure 9.2. Figure 9.2. Repair Using Parity FEC (From C. Perkins, O. Hodson, and V. Hardman, "A Survey of Packet Loss Recovery Techniques for Streaming Media," IEEE Network Magazine, September/October 1998. 1998 IEEE.) FORMAT OF PARITY FEC PACKETSThe format of an FEC packet, shown in Figure 9.3, has three parts to it: the standard RTP header, a payload-specific FEC header, and the payload data itself. With the exception of some fields of the RTP header, the FEC packet is generated from the data packets it is protecting. It is the result of applying the parity operation to the data packets. Figure 9.3. Format of a Parity FEC Packet The fields of the RTP header are used as detailed here:
The payload header protects the fields of the original RTP headers that are not protected in the RTP header of the FEC packet. These are the six fields of the payload header:
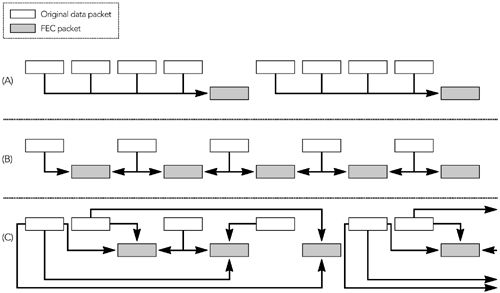
The payload data is derived as the XOR of the CSRC list (if present), header extension (if present), and payload data of the packets to be protected. If the data packets are different lengths, the XOR is calculated as if the short packets were padded out to match the length of the largest (the contents of the padding bits are unimportant, as long as the same values are used each time a particular packet is processed ; it is probably easiest to use all zero bits). USE OF PARITY FECThe number of FEC packets and how they are generated depend on the FEC scheme employed by the sender. The payload format places relatively few restrictions on the mapping process: Packets from a group of up to 24 consecutive original packets are input to the parity operation, and each may be used in the generation of multiple FEC packets. The sequence number base and mask in the payload header are used to indicate which packets were used to generate each FEC packet; there is no need for additional signaling. Accordingly, the packets used in the FEC operation can change during an RTP session, perhaps in response to the reception quality information contained in RTCP RR packets. The ability of the FEC operation to change gives the sender much flexibility: The sender can adapt the amount of FEC in use according to network conditions and be certain that the receivers will still be able to use the FEC for recovery. A sender is expected to generate an appropriate number of FEC packets in real time, as the original data packets are sent. There is no single correct approach for choosing the amount of FEC to add because the choice depends on the loss characteristics of the network, and the standard does not mandate a particular scheme. Following are some possible choices:
Figure 9.4. Some Possible FEC Schemes To make parity FEC backward-compatible, it is essential that older receivers do not see the FEC packets. Thus the packets are usually sent as a separate RTP stream, on a different UDP port but to the same destination address. For example, consider a session in which the original RTP data packets use static payload type 0 (G.711 -law) and are sent on port 49170, with RTCP on port 49171. The FEC packets could be sent on port 49172, with their corresponding RTCP on port 49173. The FEC packets use a dynamic payload typefor example, 122. This scenario could be described in SDP like this: v=0 o=hamming 2890844526 2890842807 IN IP4 128.16.64.32 s=FEC Seminar c=IN IP4 10.1.76.48/127 t=0 0 m=audio 49170 RTP/AVP 0 122 a=rtpmap:122 parityfec/8000 a=fmtp:122 49172 IN IP4 10.1.76.48/127 An alternativedescribed in the section titled Audio Redundancy Coding later in this chapteris to transport parity FEC packets as if they were a redundant encoding of the media. RECOVERING FROM LOSSAt the receiver the FEC packets and the original data packets are received. If no data packets are lost, the parity FEC can be ignored. In the event of loss, the FEC packets can be combined with the remaining data packets, allowing the receiver to recover lost packets. There are two stages to the recovery process. First, it is necessary to determine which of the original data packets and the FEC packets must be combined in order to recover a missing packet. After this is done, the second step is to reconstruct the data. Any suitable algorithm can be used to determine which packets must be combined. RFC 2733 gives an example, which operates as shown here:
Eventually, all FEC packets will be used or discarded as redundant, and all recoverable lost packets will be reconstructed. The algorithm relies on an ability to determine whether a particular set of data packets and FEC packets makes it possible to recover from a loss. Making the determination requires looking at the set of packets referenced by an FEC packet; if only one is missing, it can be recovered. The recovery process is similar to that used to generate the FEC data. The parity (XOR) operation is conducted on the equivalent fields in the data packets and the FEC packets; the result is the original data packet. In more detail, this is the recovery process:
The result is an exact reconstruction of the missing packet, bitwise identical to the original. There is no partial recovery with the RFC 2733 FEC scheme. If there are sufficient FEC packets, the lost packet can be perfectly recovered; if not, nothing can be saved. Unequal Error ProtectionAlthough some payload formats must be recovered exactly, there are other formats in which some parts of the data are more important than others. In these cases it is sometimes possible to get most of the effect while recovering only part of the packet. For example, some audio codecs have a minimum number of bits that need to be recovered to provide intelligible speech, with additional bits that are not essential but improve the audio quality if they can be recovered. A recovery scheme that recovers only the minimum data will be lower in quality than one that recovers the complete packet, but it may have significantly less overhead. Alternatively, it is possible to protect the entire packet against some degree of packet loss but give the most important part of the packet a greater degree of protection. In this case the entire packet is recovered with some probability, but the important parts have a higher chance of recovery. Schemes such as these are known as unequal layered protection (ULP) codes. At the time of this writing, there is no standard for ULP codes applied to RTP. However, there is ongoing work in the IETF to define an extension to the parity FEC codes in RFC 2733, which will provide this function. 47 This work is incomplete, and the final standard may be slightly different from that described here. The extension provides for layered coding, with each layer protecting a certain portion of the packet. Each layer may have a different length, up to the length of the longest packet in the group. Layers are arranged so that multiple layers protect the start of the packet, with later parts being protected by fewer layers . This arrangement makes it more likely that the start of the packet can be recovered. The proposed RTP payload format for ULP based on parity FEC is shown in Figure 9.5. The start of the payload header is identical to that of RFC 2733, but the extension bit is set, and additional payload headers follow to describe the layered FEC operation. The payload data section of the packet contains the protected data for each layer, in order. Figure 9.5. The RTP Payload Format for ULP Based on Parity FEC
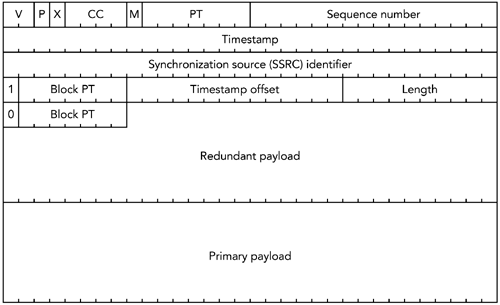
The operation of the ULP-based parity FEC format is similar to that of the standard parity FEC format, except that the FEC for each layer is computed over only part of the packet (rather than the entire packet). Each layer must protect the packets protected by the lower layers, making the amount of FEC protecting the lower layers cumulative with the number of layers. Each FEC packet can potentially contain data for all layers, stacked one after the other in the payload section of the packet. The FEC for the lowest layer appears in all FEC packets; higher layers appear in a subset of the packets, depending on the FEC operation. There is only one FEC stream, independent of the number of layers of protection. Recovery operates on a per-layer basis, with each layer potentially allowing recovery of part of the packet. The algorithm for recovery of each layer is identical to that of the standard parity FEC format. Each layer is recovered in turn , starting with the base layer, until all possible recovery operations have been performed. The use of ULP is not appropriate for all payload formats, because for it to work, the decoder must be able to process partial packets. When such partial data is useful, ULP can provide a significant gain in quality, with less overhead than complete FEC protection requires. ReedSolomon CodesReedSolomon codes 98 are an alternative to parity codes that offer protection with less bandwidth overhead, at the expense of additional complexity. In particular, they offer good protection against burst loss, where conventional parity codes are less efficient. ReedSolomon encoding involves treating each block of data as the coefficient of a polynomial equation. The equation is evaluated over all possible inputs in a certain number base, resulting in the FEC data to be transmitted. Often the procedure operates per octet, making implementation simpler. A full treatment is outside the scope of this book, but the encoding procedure is actually relatively straightforward, and there are optimized decoding algorithms. Despite advantages of ReedSolomon codes compared to parity codes, there is no standard for their use with RTP. Both equal and unequal FEC 48 using ReedSolomon codes has generated some interest, and a standard is expected to be developed in the future. Audio Redundancy CodingThe error correction schemes we have discussed so far are independent of the media format being used. However, it is also possible to correct errors in a media-specific way, an approach that can often lead to improved performance. The first media-specific error correction scheme defined for RTP was audio redundancy coding, specified in RFC 2198. 10 , 77 The motivation for this coding scheme was interactive voice telecon-ferences, in which it is more important to repair lost packets quickly than it is to repair them exactly. Accordingly, each packet contains both an original frame of audio data and a redundant copy of a preceding frame, in a more heavily compressed format. The coding scheme is illustrated in Figure 9.6. Figure 9.6. Audio Redundancy Coding (From C. Perkins, O. Hodson, and V. Hardman, "A Survey of Packet Loss Recovery Techniques for Streaming Media," IEEE Network Magazine, September/October 1998. 1998 IEEE.) When receiving a redundant audio stream, the receiver can use the redundant copies to fill in any gaps in the original data stream. Because the redundant copy is typically more heavily compressed than the primary, the repair will not be exact, but it is perceptually better than a gap in the stream. FORMAT OF REDUNDANT AUDIO PACKETSThe redundant audio payload format is shown in Figure 9.7. The RTP header has the standard values, and the payload type is a dynamic payload type representing redundant audio. Figure 9.7. The RTP Payload Format for Audio Redundancy Coding The payload header contains four octets for each redundant encoding of the data, plus a final octet indicating the payload type of the original media. The four-octet payload header for each redundant encoding contains several fields:
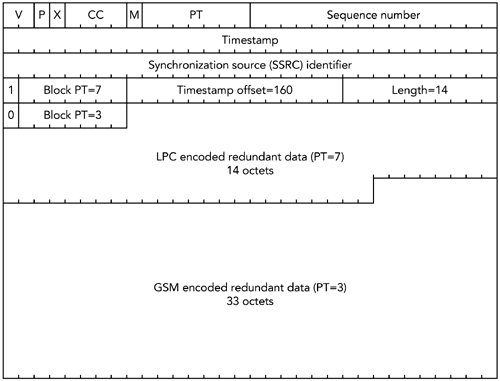
The final payload header is a single octet, consisting of one bit to indicate that this is the last header, and the seven-bit payload type of the primary data. The payload header is followed immediately by the data blocks, stored in the same order as the headers. There is no padding or other delimiter between the data blocks, and they are typically not 32-bit aligned (although they are octet aligned). For example, if the primary encoding is GSM sent with one frame20 milliseconds per packet, and the redundant encoding is a low-rate LPC codec sent with one packet delay, a complete redundant audio packet would be as shown in Figure 9.8. Note that the timestamp offset is 160 because 160 ticks of an 8kHz clock represent a 20-millisecond offset (8,000 ticks per second x 0.020 seconds = 160 ticks ). Figure 9.8. A Sample Redundant Audio Packet The format allows the redundant copy to be delayed more than one packet, as a means of countering burst loss at the expense of additional delay. For example, if bursts of two consecutive packet losses are common, the redundant copy may be sent two packets after the original. The choice of redundant encoding used should reflect the bandwidth requirements of those encodings. The redundant encoding is expected to use significantly less bandwidth than the primary encodingthe exception being the case in which the primary has a very low bandwidth and a high processing requirement, in which case a copy of the primary may be used as the redundancy. The redundant encoding shouldn't have a higher bandwidth than the primary. It is also possible to send multiple redundant data blocks in each packet, allowing each packet to repair multiple loss events. The use of multiple levels of redundancy is rarely necessary because in practice you can often achieve similar protection with lower overhead by delaying the redundancy. If multiple levels of redundancy are used, however, the bandwidth required by each level is expected to be significantly less than that of the preceding level. The redundant audio format is signaled in SDP as in the following example: m=audio 1234 RTP/AVP 121 0 5 a=rtpmap:121 red/8000/1 a=fmtp:121 0/5 In this case the redundant audio uses dynamic payload type 121, with the primary and secondary encoding being payload type 0 (PCM -law) and 5 (DVI). It is also possible to use dynamic payload types as the primary or secondary encodingfor example: m=audio 1234 RTP/AVP 121 0 122 a=rtpmap:121 red/8000/1 a=fmtp:121 0/122 a=rtpmap:122 g729/8000/1 in which the primary is PCM -law and the secondary is G.729 using dynamic payload type 122. Note that the payload types of the primary and secondary encoding appear in both the m= and a=fmtp: lines of the SDP fragment. Thus the receiver must be prepared to receive both redundant and nonredundant audio using these codecs, both of which are necessary because the first and last packets sent in a talk spurt may be nonredundant. Implementations of redundant audio are not consistent in the way they handle the first and last packets in a talk spurt. The first packet cannot be sent with a secondary encoding, because there is no preceding data: Some implementations send it using the primary payload format, and others use the redundant audio format, with the secondary encoding having zero length. Likewise, it is difficult to send a redundant copy of the last packet because there is nothing with which to piggyback it: Most implementations have no way of recovering the last packet, but it may be possible to send a nonredundant packet with just the secondary encoding. LIMITATIONS OF REDUNDANT AUDIOAlthough redundant audio encoding can provide exact repairif the redundant copy is identical to the primaryit is more likely for the redundant encoding to have a lower bandwidth, and hence lower quality, and to provide only approximate repair. The payload format for redundant audio also does not preserve the complete RTP headers for each of the redundant encodings. In particular, the RTP marker bit and CSRC list are not preserved. Loss of the marker bit does not cause undue problems, because even if the marker bit were transmitted with the redundant information, there would still be the possibility of its loss, so applications would still have to be written with this in mind. Likewise, because the CSRC list in an audio stream is expected to change relatively infrequently, it is recommended that applications requiring this information assume that the CSRC data in the RTP header may be applied to the reconstructed redundant data. USE OF REDUNDANT AUDIOThe redundant audio payload format was designed primarily for audio teleconferencing. To some extent it performs that job very well; however, advances in codec technology since the format was defined mean that the overhead of the payload format is perhaps too high now. For example, the original paper proposing redundant audio suggested the use of PCM-encoded audio160 octets per frameas the primary, with LPC encoding as the secondary. In this case, the five octets of payload header constitute an acceptable overhead. However, if the primary is G.729 with ten octets per frame, the overhead of the payload header may be considered unacceptable. In addition to audio teleconferencing, in which adoption of redundant audio has been somewhat limited, redundant audio is used in two scenarios: with parity FEC and with DTMF tones. The parity FEC format described previously requires the FEC data to be sent separately from the original data packets. A common way of doing this is to send the FEC as an additional RTP stream on a different port; however, an alternative is to treat it as a redundant encoding of the media and piggyback it onto the original media using the redundant audio format. This approach reduces the overhead of the FEC, but it means that the receivers have to understand the redundant audio format, reducing the backward compatibility. The RTP payload format for DTMF tones and other telephone events 34 suggests the use of redundant encodings because these tones need to be delivered reliably (for example, telephone voice menu systems in which selection is made via DTMF touch tones would be even more annoying if the tones were not reliably recognized). Encoding multiple redundant copies of each tone makes it possible to achieve very high levels of reliability for the tones, even in the presence of packet loss. |
EAN: 2147483647
Pages: 108