Streamlining Data Flow
| Consider the flow of data in a SQL-NS application:
The performance of the application is directly related to the efficiency of the data flow through it. The most obvious way to improve data flow efficiency is simply to move less data through the application. This section describes two strategies, data normalization and event prefiltering, that you can use to reduce the volume of data moving through a SQL-NS application. Normalizing DataIn database design, normalization refers to structuring tables so as to avoid storing redundant data. In a normalized database schema, each data element is stored only once, uniquely identified by a primary key, and related to other data elements through foreign key relationships. Normalizing data leads to more efficient storage and helps maintain data integrity. In SQL-NS applications, the principles of normalization can be applied to reduce data copying and thereby make data flow more efficient. Consider the way events are modeled in the music store application. Conceptually, each event is a description of a new song added to the music store, but rather than carry all the song properties (title, artist name, album name, and genre) with each event, we chose to store just the song ID. The song ID is a foreign key into the songs table in the music store catalog. Based on that relationship (and other relationships to the artists, albums, and genres tables), we are able to obtain all the song properties without having to copy them into the SQL-NS events table. This leads to data flow efficiency because moving a single integer identifier (the song ID) is much cheaper than moving several strings for each event. Note For a review of the music store application's event schema design, refer to the "Events" section (p. 135) in Chapter 5, "Designing and Prototyping an Application." This same technique can be applied to subscriptions and notifications as well. Anytime several rows in a table contain the same data, there is an opportunity to normalize that data into a separate table (where it is stored just once) and refer to it by a foreign key. Normalizing Subscription DataAs an example of normalizing subscription data, consider the ArtistName field in the NewSongByArtist subscription class. It's likely that many subscriptions will have the same artist name. Instead of storing the artist name in the subscription data, an alternative design could have stored an artist ID in the subscription data and kept a separate table of unique artist names (with the artist ID as the primary key). Figure 12.1 shows this normalization of the subscription data. The artists table shown could be the artists table in the music store catalog, or a separate artists table maintained as part of the SQL-NS application data. Figure 12.1. Normalizing the subscription data.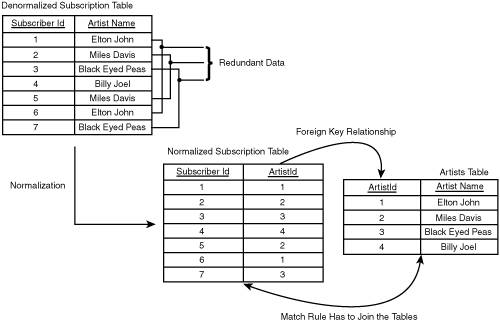 Normalizing the ArtistName field enables the application to store less data for each subscription. A similar technique could have been used to normalize the GenreName field in the NewSongByGenre subscription class. The efficiency gained from doing this normalization does come at a cost. First, the match rules would become more complex because they would each have to join an additional table to obtain all the required subscription data. Furthermore, maintenance of the subscription data would become more difficult: For each subscription added, the application would have to ensure that there was a corresponding entry in the separate artists (or genres) table. The logic to do this could be implemented in the logic layer of the SMI, but there is always the possibility that this could be circumvented. Maintaining data integrity when a subscription is removed can also be a challenge because the application can remove the corresponding row in the artists or genres tables only if no other subscriptions refer to it. In the particular case of the music store application, it's questionable whether normalizing the subscriptions would make a difference because the amount of duplicate data is small (just one string field). When designing the music store sample application, I chose not to normalize the subscription data because the gains did not seem worth the trade-off in complexity. In other applications, where the amount of redundant subscription data is much larger, normalization may be more worthwhile. Tip An often-stated motto of performance tuning experts is, "When in doubt, measure!" In other words, the best way to understand the performance characteristics of a system is to perform actual performance measurements. Measurements can turn up surprises. Often, the most thoroughly considered assumptions about performance issues turn out to be flawed. Chapter 14, "Administering a SQL-NS Instance," describes the SQL-NS reporting stored procedures and performance counters that can be used to obtain real performance data from a running SQL-NS system. Normalizing Notification DataNormalization can also be applied to the notification data, in some cases. If the notification data is merely a copy of data in other tables, you can refactor the notification class schema so that the notifications refer to the data in those other tables, instead of duplicating it. The content formatter then has to bring all the data together by joining notification data with the data in the separate tables, using foreign key relationships. Because this step often involves some custom processing, you almost always need to write a custom content formatter if you normalize your notification data. In the music store application, the NewSong notification class schema contained fields for all the song properties. This data is a copy of the information stored in the music store catalog, and significant redundancy is likely among the rows in the notifications table. As we did for events, we could have stored just the song ID in the notification data and used this to refer to the additional song properties, as shown in Figure 12.2. Figure 12.2. Normalizing the notification data.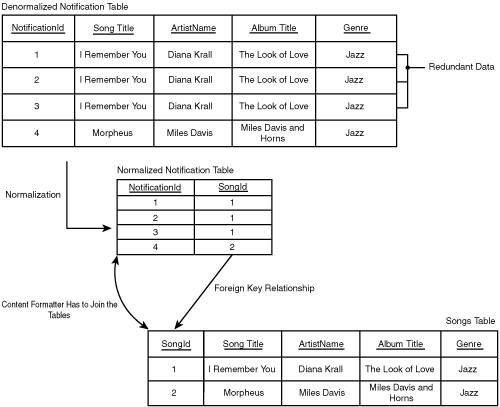 Doing this would have reduced the amount of data the generator has to write (and the distributor has to read) for each notification. However, this improved data efficiency would have come at the cost of content formatter complexity and overhead. The content formatter would need to do more work to obtain the song properties for the notifications. In the simplest implementation, this would mean an additional database read for each notification. A better implementation could have the content formatter cache the song properties in memory for the songs that it processes. As long as the cache's memory consumption is constrained, this approach would probably lead to fairly efficient performance over a large set of notifications. The biggest drawback of normalizing notification data is that it may prevent the distributor from forming meaningful digest groups. In the examples shown so far, digesting groups notifications into a batch that specifies the same subscriber, subscriber device, and locale. However, you can specify additional digesting criteria by means of the <DigestGrouping> element. In the declaration of any notification field or computed field, you can include the <DigestGrouping> element to indicate whether the field should be considered when forming digest groups. The distributor looks at any fields that have a <DigestGrouping> element set to TRue, along with the subscriber, subscriber device, and locale, when it groups notifications for digesting. Notifications can be digested together only if they have the same value for all these fields. If you set the <DigestGrouping> element on one or more notification fields to true, you cannot normalize those fields out into separate tables and still maintain the digesting behavior. The distributor's digesting algorithms work only over the notifications table; they cannot consider data in other tables. Note that this is not a problem if you digest only on the standard columns (subscriber, subscriber device, and locale) and do not set <DigestGrouping> to TRue for any other fields. Note For more information on the <DigestGrouping> element, see the SQL-NS Books Online. I chose not to normalize the notification data in the music store application in this book for the sake of simplicity and ease of explanation. Normalizing the notification data would have required the use of a complex custom content formatter from the start. However, in applications of your own, you should certainly consider normalizing your notification data as a way to improve data flow efficiency. Prefiltering EventsThe more events the event providers submit into an application, the more expensive each invocation of the chronicle and match rules becomes. One way to improve the data flow efficiency of an application is to reduce the number of events that the event providers submit, by filtering out events that won't match any subscriptions. It is ultimately the job of the match rules to determine which events match the subscriptions, but event providers can also do simple checks to prevent obviously nonmatching events from ever reaching the generator. To understand how this might work, let's revisit the stock price application that we looked at in Chapter 3, "The Simplest Notification Application: Stock Quotes." Each subscription contains a stock symbol and a target price. A match occurs if an event and a subscription have the same stock symbol, and the current stock price in the event is greater than or equal to the target price in the subscription. Events containing stock symbols for which no subscriptions exist will never generate matches. The event provider in this application can implement an event filter based on the set of stock symbols that appear in the subscription data: If there are no subscriptions for a particular symbol, no events for that symbol ever need to be submitted. Stock events that do contain symbols referenced in one or more subscriptions are submitted in the normal way, and the generator runs the application's match rule against them to generate notifications. Real stock feeds typically contain tens of thousands of stock events; this kind of filtering technique could drastically reduce the number of those events that the application actually has to process. In the extreme, the entire logic of the match rule could be run as filtering code in the event provider. However, this would defeat the purpose of the generator infrastructure, which provides ordering semantics over event batches, rule firing reliability, and scheduled subscriptions. It's not recommended that you implement full subscription matching in your event provider, but if there are simple, cheap checks that you can do to intelligently filter your events, you may realize significant performance gains. Figure 12.3 illustrates the use of prefiltering to reduce the number of events submitted to a SQL-NS application. In the music store application, we didn't do any event prefiltering because the matching logic is almost trivial (just a simple comparison on the artist name or genre name)there isn't really a simpler check we could have done in the event provider. Figure 12.3. Prefiltering event data.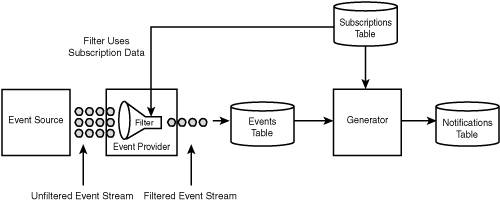 To implement prefiltering, you usually need access to the subscription data. For each subscription class, SQL-NS provides views over the subscription table that you can query to obtain the full set of subscription data. These are the same views you used to insert test subscription data in previous chapters' examples. The subscription class views contain a column for each field in the subscription class schema. The view for a subscription class is called NS<SubscriptionClass>View (where <SubscriptionClass> is the subscription class name) and is located in the application schema. For example, the view for the NewSongByArtist subscription class is called NSNewSongByArtistView and is located in the application's SongAlerts schema. You should always access subscription data through the views rather than query the subscription tables directly. Note Do not confuse the NS<SubscriptionClass>View with the view of the subscription data that you can reference in match rules. The NS<SubscriptionClass>View always contains the full set of subscription data in the subscriptions table. In contrast, the view referenced in the match rules is populated at runtime, has the same name as the subscription class, and contains only the subscription data against which the current rule execution should operate. In the case of scheduled subscriptions, this is a subset of the full subscription data. In applications that make use of event history in chronicles, you need to be careful about the way you do prefiltering. In some cases, the application state may need to be updated for a particular event, even if that event does not match any subscriptions. Prefiltering purely on subscriptions can lead to incorrect application state in these cases. Problems of this nature typically occur when an application has scheduled subscriptions that operate against event history. New scheduled subscriptions may use old event data, so the subscription data that exists at the time an event arrives is not always an accurate predictor of whether the event will be needed later. |
EAN: 2147483647
Pages: 166