Creating and Altering Database Objects
The next thing to consider is the creation of objects within the database. Database objects include constraints, indexes, stored procedures, tables, triggers, user-defined functions, views, and more. Each object is discussed in detail, paying particular attention to the impact on the system as a whole. In many implementations , there are several different approaches to meeting a particular need. Selecting the appropriate technique for a task requires trade-offs between functionality, performance, and resource utilization. Each database contains a number of tables other than those used to store data. These tables store information that enables SQL Server to keep track of objects and procedures within the database. The sysobjects and syscomments system tables maintain entries containing the object definitions and other tracking information for each object. A number of other tables also exist to maintain information about specific objects. For more information regarding system tables, refer to SQL Server Books Online. These tables are used whenever SQL Server needs object information. You should never alter system tables directly but instead allow SQL Server to manipulate the entries as needed. To help you secure the server, you might choose not to display system objects to the user from the Enterprise Manager interface. Also, hiding these objects from the user presents a cleaner interface to objects with which the user normally interacts . Step by Step 3.3 describes how to hide system objects:
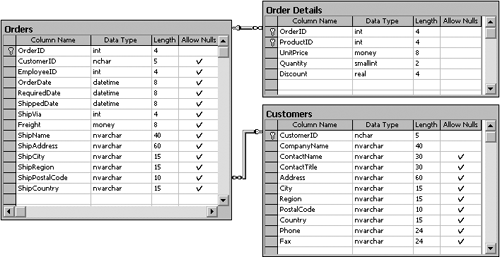
Table CharacteristicsThe makeup of a table in SQL Server is more than just simply data definition. A complete table definition includes column descriptions, storage location, constraints, relationships with other tables, indexes, and keys, as well as table-level permissions and text indexing columns . When defining tables, it is a good idea to have some form of data dictionary prepared to help you make appropriate choices for individual properties. A data dictionary defines data usage and is an extension of the logical data modeling discussed in Chapter 1. In SQL Server, the term "database diagram" is usually used rather than "dictionary," although a database diagram is not a complete data dictionary in the sense of documentation. A data dictionary is a form of documentation generally considered a complete reference for the data it describes. The dictionary is usually a lot more than just a collection of data element definitions. A complete dictionary should include schema with reference keys and an entity-relationship model of the data elements or objects. A pseudo data dictionary can be represented using the database diagram tool provided with SQL Server. A partial dictionary for the Northwind database is illustrated in Figure 3.3. Figure 3.3. Database diagram showing column properties and table relationships. Column DefinitionAfter the file structure and content of each file has been determined, the tables themselves can be created and assigned to the files. If the purpose of the table is to hold data that is frequently accessed, then the file placement of the table should take that into consideration. Tables that hold archive data and other less frequently accessed data require less maintenance and don't have to be as responsive to user queries. The initial definition of each column within a table consists of a name for the column, the type and length of data for the column, and an indicator as to whether the column must have data or allow NULL content. A number of additional column descriptors can be included to define characteristics of how the column obtains its value and how the column is treated within the table. A complete list of potential column descriptors is as follows : NOTE Object Placement Keep in mind when assigning objects to files that some objects can be placed away from the mainstream data through the use of filegroups. You can select the object placement from Table Design Properties in the Enterprise Manager or through the use of an ON clause in a CREATE/ALTER statement. SQL Server enables you to place the following table objects:
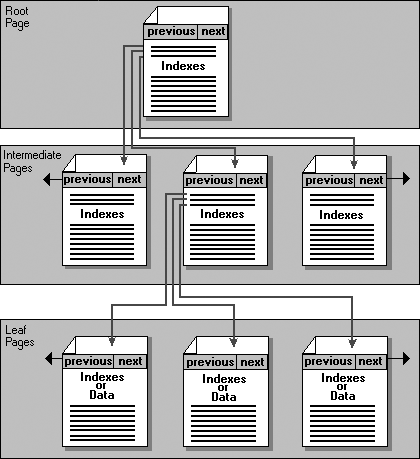
Many characteristics of column definitions affect other columns, tables, and databases. For a more complete definition of any of these properties, consult SQL Server Books Online. Using CHECK ConstraintsA CHECK constraint is one of several mechanisms that can be used to prevent incorrect data from entering the system. Restrictions on data entry can be applied at the table or column level through the use of a CHECK constraint. You might also apply more than a single check to any one column, in which case, the checks are evaluated in the order in which they were created. A CHECK constraint represents any Boolean expression that is applied to the data to determine whether the data meets the criteria of the check. The advantage of using a check is that it is applied to the data before it enters the system. However, CHECK constraints do have less functionality than mechanisms, such as stored procedures or triggers. You can find a comparison of features for a number of these mechanisms with provisions for where each one is applied at the close of this section, just before the "Review Break." One use for a CHECK constraint is to ensure that a value entered meets given criteria based on another value entered. A table-level CHECK constraint is defined at the bottom of the ALTER/CREATE TABLE statement, unlike a COLUMN CHECK constraint, which is defined as part of the column definition. For example, when a due date entered must be at least 30 days beyond an invoice date, a table-level constraint would be defined as: (DueDate InvoiceDate) >= 30 A column-level check might be used to ensure that data is within acceptable ranges, such as in the following: InvoiceAmount >= 1 AND InvoiceAmount <= 25000 A check can also define the pattern or format in which data values are entered. You might, for example, want an invoice number to have an alphabetic character in the first position, followed by five numeric values, in which case, the check might look similar to the following: InvoiceNumber LIKE '[A-Z][0-9][0-9][0-9][0-9][0-9]' Finally, you might want to apply a check where an entry must be from a range of number choices within a list. An inventory item that must be one of a series of category choices might look similar to this: ProductCategory IN ('HARDWARE', 'SOFTWARE', 'SERVICE') A COLUMN CHECK (or other constraint) is stated as a portion of the column definition itself and applies only to the column where it is defined. A TABLE CHECK (or other constraint), on the other hand, is defined independently of any column, can be applied to more than one column, and must be used if more than one column is included in the constraint. A table definition that is to define restrictions to a single column (minimum quantity ordered is 50), as well as a table constraint (date on which part is required must be later than when ordered), would be as follows: CREATE TABLE ProductOrderLine (ProductLineKey BigInt, OrderMatchKey BigInt, ProductOrdered Char(6), QtyOrdered BigInt CONSTRAINT Over50 CHECK (QtyOrdered > 50), OrderDate DateTime, RequiredDate DateTime, CONSTRAINT CK_Date CHECK (RequiredDate > OrderDate)) Usually a single table definition would provide clauses for key definition, indexing, and other elements that have been left out of the previous definition to focus in more closely on the use of CHECK constraints. Index OrganizationPutting the data into sequence to accommodate quick retrieval, and at the same time provide meaningful and usable output to an application, usually requires that a variety of indexes be defined. A clustered index provides the physical order of the data storage, whereas a nonclustered index provides an ordered list with pointers to the physical location of the data. Indexing is most easily defined and understood if you compare the data and index storage of a database to that of a book. In a book, the data itself is placed onto the pages in a sequence that is meaningful if you read the book sequentially from cover to cover. An index at the back of the book enables you to read the data randomly . You can locate a topic by looking through a list of topics that is accompanied by a physical page reference to the place where the topic can be found. To read a single topic you need not skim through the entire book. In a similar manner, data in a database can be handled randomly or in sequence. The location of a single record can be found in the database by looking it up in the index, rather than reading through all the rest of the data. Conversely, if a report is to be generated from all the data in a database, the data itself can be read sequentially in its entirety. Index storage in SQL Server has a B-tree structured storage. The indexes are maintained in 8KB pages qualified as root , intermediate , and leaf-level pages. In a clustered index, the leaf level is the data itself, and all other levels represent index pages. In a nonclustered index, all pages contain indexes (see Figure 3.4). Figure 3.4. Illustration of the B-tree structure used for index storage. If a clustered index has not been defined for a given table, then the data is stored in a "heap." A data heap does not maintain data in any particular order; it simply stores the data in the order in which it is entered. In some applications, where data is never retrieved in any particular order on a regular basis, this might actually be advantageous. Indexes can be created using the T-SQL CREATE INDEX command. When you use the Enterprise Manager to create an index, you must access the table design and then reveal the table properties. Step by Step 3.4 shows you how to use the Enterprise Manager to create an index.
Create an index using the T-SQL CREATE INDEX . The following example creates a compound, nonclustered index that is 75% full: CREATE INDEX IXProductItem ON ProductOrderLine (OrderMateKey, ProductLineKey) WITH FILLFACTOR = 75 Clustered IndexingThe selection of the appropriate column(s) on which to base a clustered index is important for a number of reasons. As previously mentioned, a clustered index represents the order in which the data is physically stored on the disk. For this reason, you can define only a single clustered index for any table. If you choose not to use a clustered index in a table, the data on disk will be stored in a heap. A clustered index, if present, has clustering keys that are used by all nonclustered indexes to determine the physical location of the data. The basis for the index usually is determined by the order in which the majority of applications and queries want their output. The clustered index values are also present in other indexes and the size of the defined index should be kept as small as possible. When you select a clustering key, try to utilize a numeric data type because character types cause index storage to occupy much more space. Always define a clustered index first before you define any of the nonclustered indexes. If you do these tasks in reverse order, then all nonclustered indexes rebuild themselves upon creation of the clustered index. Nonclustered IndexingNonclustered indexes provide a means of retrieving the data from the database in an order other than that in which the data is physically stored. The only alternative to the use of these indexes would be provisions for a sort operation that would place undue overhead on the client system and might not produce the desired response times. A data sort implementation is usually performed only for one-time operations or for applications that will have very limited usage. Although the creation of indexes saves time and resources in a lot of cases, avoid the creation of indexes that will rarely be utilized. Each time a record is added to a table, all indexes in the table must be updated, and this might also cause undue system overhead. For that reason, careful planning of index usage is necessary. Unique IndexingAt times when indexes are created, it is important to guarantee that each value is distinctive . This is particularly important for a primary key. SQL Server automatically applies a unique index to a primary key to ensure that each key value uniquely defines a row in the table. You might want to create additional unique indexes for columns that are not going to be defined as the primary key. Leaving Space for InsertsFill factor is the percent at which SQL Server fills leaf-level pages upon creation of indexes. Provision for empty pages enables the server to insert additional rows without performing a page-split operation. A page split occurs when a new row is inserted into a table that has no empty space for its placement. As the storage pages fill, page splits occur, which can hamper performance and increase fragmentation.
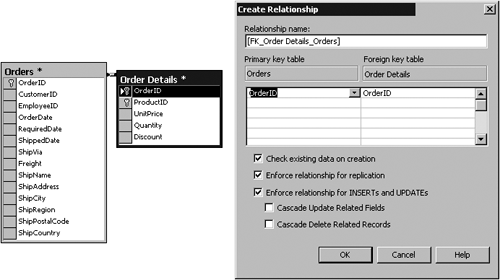
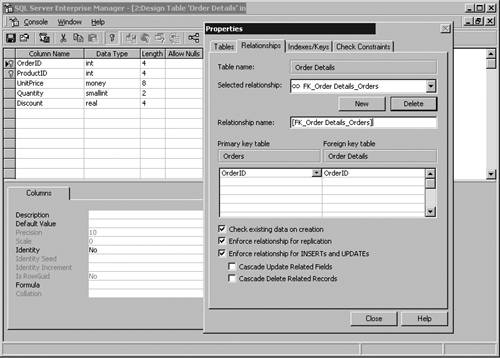
Equally, setting the fill factor too low hampers read performance because the server must negotiate a series of empty pages to actually fetch the desired data. It is beneficial to specify a fill factor when you create an index on a table that already has data and will have a high volume of inserts. If you do not specify this setting when creating an index, the server default fill factor setting is chosen . The fill factor for the server is a configuration option set through the Enterprise Manager or the sp_configure stored procedure. The percentage value for the fill factor is not maintained over time; it applies only at the time of creation. Therefore, if inserts into a table occur frequently, it's important to take maintenance measures for rebuilding the indexes to ensure that the empty space is put back in place. A specific index can be rebuilt using the CREATE INDEX T-SQL command with the DROP EXISTING option. Indexes can also be de- fragmented using the DBCC INDEXDEFRAG command, which also reapplies the fill factor. The Pad Index setting is closely related to the setting for fill factor to allow space to be left in non-leaf levels. Pad Index cannot be specified by itself and can be used only if you supply a fill factor. You do not provide a value to this setting; it matches the setting given for the fill factor. Maintaining Referential IntegrityWhen multiple tables maintained in a database are related to each other, some measures should be taken to ensure that the reliability of these relationships stays intact. To enforce referential integrity, you create a relationship between two tables. This can be done through the database diagram feature of the Enterprise Manager or through the CREATE and ALTER TABLE T-SQL statements. Normally, you relate the referencing or Foreign Key of one table to the Primary Key or other unique value of a second table. Step by Step 3.5 shows you how to use a database diagram to define a relationship:
Step by Step 3.6 shows you how to define a relationship from the Table Design Properties box:
You can define a relationship when creating or altering a table definition. The following example defines a relationship using T-SQL: CREATE TABLE OrderDetails (DetailsID smallint, OrderID smallint FOREIGN KEY (OrderID) REFERENCES Orders(OrderID), QtyOrdered bigint, WarehouseLocation smallint) The most common relationships are one-to-many, in which the unique value in one table has many subsidiary records in the second table. Another form of relationship, which is usually used to split a table with an extraordinary number of columns, is a one-to-one relationship. The use of one-to-one splits a table and associates a single unique value in one table with the same unique value in a second table. A many-to-many relationship can also be defined, but this form of referencing requires three tables and is really two separate one-to-many relationships. Utilizing referential integrity guidelines helps maintain the accuracy of data entered into the system. A database system uses referential integrity rules to prohibit subsidiary elements from being entered into the system unless a matching unique element is in the referenced table. The system also protects the data from changes and deletions, assuming that cascading actions (defined later in this chapter) have been carefully and properly implemented. Primary and Foreign KeysThe definition of a Primary Key for each table, though not a requirement of the SQL Server database environment, is recommended. A Primary Key helps records maintain their identities as unique rows of a table and also provides a means of relating tables to other tables in the database to maintain normal forms. (For further information on normalization and normal forms, see Chapter 2, "Data Modeling.") A Foreign Key is defined in a subsidiary table as a pointer to the Primary Key or other unique value in the primary table. Both Primary and Foreign Keys are defined in the form of a constraint. The pair of keys work together to accommodate table relationships. A Foreign Key refers back to the Primary Key in the parent table, forming a one-to-one or one-to-many relationship. (To see more about relationships, refer to Chapter 2.) Primary Key ConstraintA Primary Key constraint enforces entity integrity in that it does not permit any two rows in a table to have the same key value. This enables each row to be uniquely defined in its own right. Although a Primary Key should be created when a table is initially created, it can be added or changed at any time after creation. A Primary Key cannot have NULL content nor can there be any duplicate values. SQL Server automatically creates a unique index to enforce the exclusiveness of each value. If a Primary Key is referenced by a Foreign Key in another table, the Primary Key cannot be removed unless the Foreign Key relationship is removed first. A Primary Key is easily assigned in the table design window by either of the following actions:
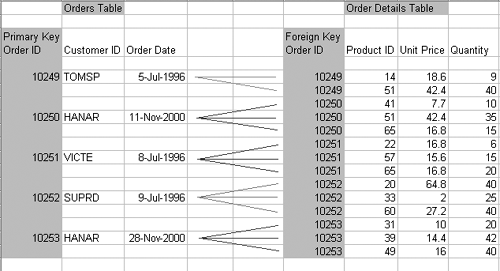
WARNING Documentation Discrepancy The capability to set a relationship to any unique column is not noted in most SQL Server documentation. SQL Server Books Online reports that a Foreign Key must be set to a Primary Key or a UNIQUE constraint. In SQL Server, you can create a relationship against a Primary Key, unique index , or a UNIQUE constraint. You need not have a Primary Key or constraint. You can even set a unique index to ignore duplicates and the operation will still be permitted. Foreign Key ConstraintA Foreign Key constraint is defined so that a primary and subsidiary table can be linked together by a common value. A Foreign Key can be linked to any unique column in the main table; it does not necessarily have to be linked to the Primary Key. It can be linked to any column that is associated with a unique index. With a Foreign Key defined, you cannot add a value to the Foreign Key column if a matching value is not present in the primary table. For instructions on setting a Foreign Key constraint, see the section on referential integrity, earlier in this chapter. EXAM TIP Go with the Documentation If you run into this on the exam, the correct answer is likely to be one chosen based on the documentation and not on actual functionality. The capability to set a relationship to any unique column is not noted in documentation. The correct technique to use when answering an exam question would be one that involves a Foreign Key set to a Primary Key or Unique constraint. Note in the example shown in Figure 3.7 that there are matching Order IDs in the child Order Details table for only those Order IDs included in the parent Orders table. An Order ID must match from a child to a parent. If a child entry with an ID were not found in the parent table, then that is known as an orphan child and would be a breach of referential integrity rules. Figure 3.7. Primary Key/Foreign Key referential integrity. Using Cascade Action to Maintain IntegrityNew to SQL Server with the 2000 release is a cascading action feature that many other database environments have been enjoying for quite some time. Cascading actions affect update and delete activity where an existing Foreign Key value is changed or removed. Cascade action is controlled through the CREATE and ALTER TABLE statements, with clauses for ON DELETE and ON UPDATE . You can also select these features using the Enterprise Manager. In a cascading update, when you change the value of a key in a situation where a Foreign Key in another table references the key value, those changed values are reflected back to the other tables. A similar thing happens with a delete operation: if a record is deleted, then all subsidiary records in other tables are also deleted. For example, if an invoice record is deleted from an invoice table that has invoice details stored in another table and referenced by a Foreign Key, then the details would also be removed. A series of cascading actions could easily result from the update or deletion of important keys. For example, the deletion of a customer could cause the deletion of all that customer's orders, which could cause the deletion of all its invoices, which in turn could cause the deletion of all the customer's invoice details. For this reason, careful system design is important and the potential archival of data through the use of triggers should be considered. EXAM TIP Cascading Actions Is a New Feature You can expect that something about it will be asked on the exam. Also be prepared for the exam by knowing all the results and implications of cascading actions. For example, you might be asked what occurs when a record contained in the parent table is deleted, or has its key value changed. In the case of multiple cascading actions, all the triggers to be fired by the effects of the original deletion fire first. AFTER triggers then fire on the original table and then the AFTER triggers in the table chain subsequently fire. Stored ProceduresA stored procedure is a set of T-SQL statements that can be saved as a database object for future and repeated executions. With stored procedures, you can enable a lot of the development and processing to be performed on the server, producing much more efficient and lightweight front-end applications. Any commands that can be entered via SQL Query tools can be included in a stored procedure. Using stored procedures is a powerful and flexible technique for performing tasks within an application. A stored procedure, when it is first used, is compiled into an execution plan that remains in the procedure cache. This provides for some of the performance over ad-hoc operations. The performance improvements in SQL 7 and 2000 are not as drastic as in previous versions because changes in the way that other operations now execute provides them with some of the same benefits as stored procedures. A stored procedure can accept parameters, process operations against any number of databases, and return results to the calling process. Performance will be discussed in more detail in Chapter 12, "Monitoring SQL Server 2000." The SQL Server 2000 implementation has many other capabilities that speed processing, secure data, reduce bandwidth usage, and enable advanced operations to be performed. Procedures that are repeatedly used will be held in memory in the SQL Server procedure cache for faster execution. A stored procedure, like other operations, can be encrypted to protect the details of the operation (the following section covers encryption). An application might need to send several operations across a network and respond conditionally to the results. This can be handled with a single call if the logic is contained in a single stored procedure. The use of local and global cursors can expose information to the application or other applications as needed, giving provisions for complex development processes with conversations between separate processes. Temporary stored procedures used frequently in earlier versions are still supported by SQL Server, although improvements in other areas should eliminate or reduce the need for their use. The most significant improvement is the capability to compile and maintain most SQL operations in cache for prolonged periods. Many system-stored procedures have already been created and are available upon installation of SQL Server. Extended stored procedures, which enable DLL files to be accessed from the operating system, are pre-established and present in the Master database. The T-SQL CREATE PROCEDURE statement is used to create a stored procedure. This statement can be executed from the Query Analyzer or it is available through the Enterprise Manager by right-clicking on Stored Procedures under the database and choosing the New Stored Procedure option. The procedure is then saved within the current database as an object. Encryption Can Secure DefinitionsData encryption is a mechanism that can be used to secure data, communications, procedures, and other sensitive information. When encryption techniques are applied, sensitive information is transformed into a non-readable form that must be decrypted to be viewed . Encryption slows performance, regardless of the method implemented, because extra processing cycles are required whenever encryption or decryption occurs. SQL Server can use data encryption at several levels:
A variety of encryption procedures can be performed by a developer or administrator depending on what level of encryption is desired. SQL Server always encrypts login and role passwords within the system tables stored on the server. This automatic encryption of the login information stored on the server can be overridden using sp_addlogin , but this is not recommended. By default, however, application role passwords are not encrypted if they are provided across the network to invoke a role. The encryption of these passwords must be coded into the invoking application by utilizing the encryption capabilities of the sp_setapprole procedure as follows: sp_setapprole 'SampleRole', (ENCRYPT N 'password'), 'odbc' SQL Server can use SSL (Secure Sockets Layer) encryption across all network libraries, although multiprotocol encryption is still supported for backward compatibility reasons. A consideration in any SQL Server installation that uses multiple instances installed on the same server is that multiprotocol encryption is not supported by named instances of SQL Server. Process definition encryption applied to stored procedures, defaults, rules, user-defined functions, triggers, and view definitions are all implemented in a similar fashion. The definition stored on the server is encrypted to prevent someone from viewing the details of the process. To encrypt these definitions, use the applicable CREATE statement, providing the WITH ENCRYPTION option as illustrated in the following VIEW definition: CREATE VIEW SampleEncryptedView WITH ENCRYPTION AS SELECT FirstName, LastName, Wage FROM PayTable Encryption can also serve the purpose of protecting the copyright that a developer might have over the processes created. In any case, before you encrypt a procedure, make sure you save a copy of the procedure to a file server or other backup mechanism, because future changes are difficult to implement if you do not have the original definition. To update any definition or remove encryption, simply supply the CREATE statement without the WITH ENCRYPTION option. This overwrites the encrypted process with a new version that is not encrypted. Schema BindingSchema binding involves attaching an underlying table definition to a view or user-defined function. Normally, if this process is not used, a function or view definition does not hold any data or other defining characteristics of a table. The definition is stored as a set of T-SQL statements and handled as a query or procedure. With binding, a view or function is connected to the underlying objects. Any attempt to change or remove the objects fails unless the binding has first been removed. Normally, you can create a view, but the underlying table might be changed so that the view no longer works. To prevent the underlying table from being changed, the view can be "schema-bound" to the table. Any table changes, which would break the view, are not allowed. Indexed views require that a view be defined with the binding option and also that any user-defined functions referenced in the view must also be bound. In previous versions of SQL Server, it was not possible to define an index on a view. With the advent of binding, however, meaningful indexes can now be defined over a view that has been bound to the underlying objects. Other system options must be set to define an indexed view. These options are discussed later in the chapter in the "Indexed Views" section. More information on the use of all types of views can be found in Chapter 7, "Working With Views." The following example uses T-SQL of the creation of a schema-bound view: CREATE VIEW SampleBoundView WITH SCHEMABINDING AS SELECT ProductID, Description, PurchPrice, PurchPrice * Markup AS SalesPrice FROM dbo.ProductTable EXAM TIP The Many Meanings of "Schema" The word schema has several different uses and definitions within SQL Server; the exam will leverage this and attempt to confuse the separate definitions. Make sure you are aware of how the term is used with relation to XML, Indexed Views, and maintaining metadata. For more information about these particulars, you can consult Chapter 5, "Advanced Data Retrieval and Modification," in the section on XML schema; Chapter 7, "Working With Views," in the section on indexed views; and Chapter 12, "Monitoring SQL Server 2000," in the section on metadata. Recompilation of ProceduresAdding or altering indexes or changing a stored procedure causes SQL Server to automatically recompile the procedure. This optimization occurs the next time the stored procedure is run, but only after SQL Server is restarted. In instances where you want to force a recompilation, you can use the sp_recompile system-stored procedure. Alternatively, you can use the WITH RECOMPILE option when you create or execute a stored procedure. Stored procedures are dealt with in depth in Chapter 9, "Stored Procedures and User-Defined Functions." Extended Stored ProceduresThese procedures, like many of the system-stored procedures, are loaded automatically when you install SQL Server. Extended stored procedures access DLL files stored on the machine to enable the calling of the functions contained in the DLLs from within a SQL Server application. You might add to this set of procedures stored in the Master database using the sp_addextendedproc procedure as follows: sp_addextendedproc 'MyFunction', 'MyFunctionSet.DLL' Trigger UtilizationTriggers are like stored procedures in that they contain a set of T-SQL statements saved for future execution. The big difference is that unlike stored procedures, triggers are executed automatically based on data activity in a table. A trigger may fire based on an UPDATE , INSERT , or DELETE operation. In SQL Server 2000, triggers can be fired AFTER an operation completes (SQL Server default) or INSTEAD OF the triggering operation. An AFTER trigger can be used to archive data when it is deleted, send a notification that the new data has been added or changed, or to initiate any other process that you might want to automate based on data activity. An INSTEAD OF trigger can be used to perform more advanced activities (such as advanced data checking), to enable updates in a view to occur across multiple tables, and to perform many other functions that might be necessary in place of a triggering activity. Many AFTER triggers can be specified for each INSERT , UPDATE , or DELETE action. If multiple triggers exist, you can specify the first and last trigger to fire. The others are fired in no particular order, and you cannot control that order. An AFTER trigger can be defined only on a table. Only one INSTEAD OF trigger can be defined for each of the triggering actions; however, an INSTEAD OF trigger can be defined on a view as well as a table. In previous releases, you could use triggers to help enforce referential integrity constraints. This was difficult and required that you eliminate other elements, such as Foreign Key constraints. In SQL Server 2000, it is far more efficient to use cascading actions, discussed earlier in this chapter, for the purpose of cascading changes and deletions. To define a trigger, you can select the Manage Triggers option from the Table Design window. You can also go to the table to which you want to attach a trigger, and you can find the option as an extension of the pop-up menu off the All Tasks option. You can use the T-SQL CREATE TRIGGER statement to create triggers for all applicable operations. You can access this command from the Enterprise Manager by using the Managing Triggers option. Managing Triggers in the Enterprise Manager (and in other objects as well) provides you with the shell of a CREATE statement even if you are changing an existing trigger. The Enterprise Manager enables you to change an existing trigger and the trigger will be first dropped prior to re-creation. The ALTER TRIGGER statement is used to change the definition of a trigger without dropping it first, and is used only through T-SQL. An example of the creation of a trigger using T-SQL is as follows: CREATE TRIGGER UpdatedCustomer ON CustomerTable FOR INSERT, UPDATE AS declare @phone nvarchar(20) declare @Contact nvarchar(100) select @phone = phoneno, @contact = contactname from inserted RAISERROR(50100, 1, 1, @Contact, @Phone) This procedure is one of my favorite implementations for use in customer applications. In the case of customer information, an automated alert that sends an email message to the salesperson could be defined around the error being raised. On an INSERT , a clerk or salesperson may make an initial client contact call based on an email that the alert may send. In the event of an UPDATE , the clerk could call the client to ensure the new information is accurate. The benefit is that the trigger automatically fires when new rows are added to the table or changes are made to the customer information. Consider some other possible implementations of triggers. A government database is present, which can be replicated into a local copy of the database. Revenues are based on the capability to ferret out new clients ahead of the competition. An INSERT trigger can fire an email directly to the client with a promotional sales package attached. The end result is that action occurs as quickly as possible, which might provide an edge over the competition. For a more complete guide to the use of triggers and other facets of this technology, see Chapter 8, "Triggers." User-Defined FunctionsIn some applications, the functions available from the SQL Server installation do not suit all needs. It is for these instances that user-defined functions were intended. The functions can contain any combination of T-SQL statements. These functions act similarly to stored procedures with the exception that any errors occurring inside the function cause the entire function to fail. SQL Server supports three varieties of user-defined functions:
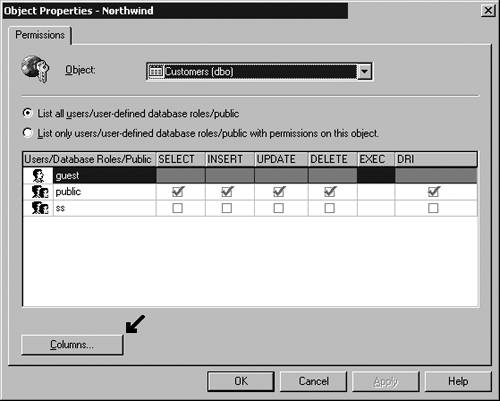
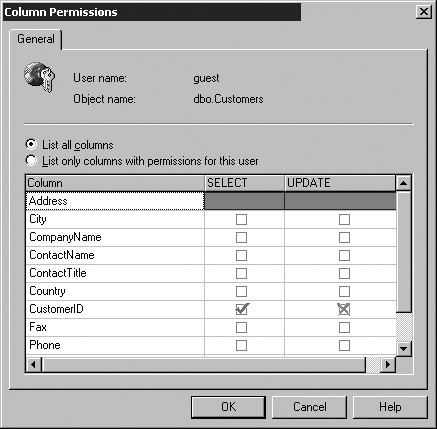
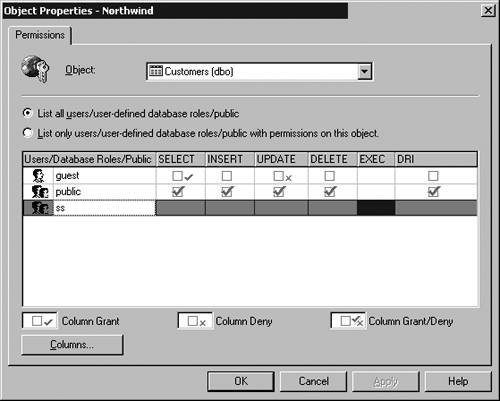
The functions defined can accept parameters if needed and return either a scalar value or a table. A function cannot change any information outside the scope of the function and therefore maintains no information when processing has been completed. Other activities that are not permitted include returning information to the user and sending email. The CREATE FUNCTION statement is used to define a user-defined function similar to the following: CREATE FUNCTION MyFunction (@Num1 smallint, @Num2 smallint) RETURNS real AS BEGIN Declare @ReturnValue real If (@Num1 > @Num2) Set @ReturnValue = @Num1 * 2 + 30 If (@Num1 = @Num2) Set @ReturnValue = @Num1 * 1.5 + 30 If (@Num1 < @Num2) Set @ReturnValue = @Num1 * 1.25 + 30 If (@Num1 < 0) Set @ReturnValue = @Num2 * 1.15 + 30 Return(@ReturnValue) End User-defined functions (UDFs) represent powerful functionality that has a wide variety of uses within the SQL Server environment. For more complete information on how to use UDFs see Chapter 9, "Stored Procedures and User-Defined Functions." Focusing Interaction with ViewsA view is a SELECT statement that is saved and given a name. In most respects, a view acts as a table. A VIEW name can be used in SELECT INSERT , UPDATE , and DELETE statements as if it were a table. No data is stored within views (except indexed views). Often you would like to design an application that gives the user a list of specific columns out of a table but does not grant the user access to all data. A view can be used to limit what the user sees and the actions the user can perform over a portion of the data in a table. An alternative to creating a view would be to handle column-level permissions over a table, which can be a true nightmare to administer. A new interface feature in SQL 2000 does enable you to use the GUI to set column-level permissions. However, this feature should be used as little as possibleif ever. (See Figures 3.8, 3.9, and 3.10 for column permission availability.) In previous releases, you could set column permissions, but only through the use of T-SQL commands. These illustrations shows that the GUI representations for column permissions are significantly different from standard permissions and thus stand out if they are set. Figure 3.8. Command button now available on the interface to set column-level permissions. Figure 3.9. Column Permissions dialog box, available from the GUI. Figure 3.10. Permissions dialog box, showing that column permissions have been set. The problem with column-level permissions is the initial creation process of the permission is time-consuming , and the granularity of maintenance of the permissions requires extremely careful documentation. Imagine a table with 100 columns and 1000 or more users, groups, and roles. Trying to document and keep track of all the permissions set is an immense task that will overwhelm even the best administrator. Use a view to simplify administration and provide a more meaningful perspective on the data for the user. The following example shows the creation of a view: CREATE VIEW InStock AS SELECT ProductID, Description, QTYOnHand FROM Products WHERE QTYOnHand > 0 Indexed ViewsIf you want to use indexed views, a number of session-level options must be set On when you create the index. You need to set NUMERIC_ROUNDABORT Off. The options that need to be set On are as follows:
Other than setting the specific set of options, nothing more needs to be done for the optimizer to utilize an index with a query on a view. Essentially, the SQL SERVER Optimizer handles the view query in the same manner that it would a standard query against a table. The view cannot reference another view; only underlying tables are permitted and you must create the view with the SCEMABINDING option. Only the Enterprise and Developer editions support the creation of an indexed view. EXAM TIP Know Your Options A lot of specific options need to be in place to allow for Indexed Views. Make sure you are confident with the set of configuration features that are needed. Make sure that you read up on this topic as presented in Chapter 7, "Working with Views." There are limitations to the content of the SELECT statement for the view definition. They are as follows:
Partitioned ViewsA partitioned view enables the creation of a view that spans a number of physical machines. These views can fall into one of two categories: local and distributed. A distinction is also made between views that are updateable and those that are read-only. The use of partitioned views can aid in the implementation of federated database servers , which are multiple machines set up to share the processing load. For more information on federated server implementations, see SQL Server Books Online, "Designing Federated Database Servers." To use partitioned views, you horizontally split a single table into several smaller tables, each having the same column definitions. Set up the smaller tables to accept data in ranges and enforce the ranges using CHECK constraints. Then you can define the distributed view on each of the participating servers. Add linked server definitions on each of the member servers. An example of a distributed view definition is as follows: CREATE VIEW AllProducts AS Select * FROM Server1.dbo.Products9999 UNION ALL Select * FROM Server2.dbo.Products19999 UNION ALL Select * FROM Server3.dbo.Products29999 Easing Data Entry with DefaultsA default is used to provide a value for a column so as to minimize data entry efforts or to provide an entry when the data is not known. A default provides a value for the column as a basis for initial input. Any data that is entered for the column overrides the default entry. You can apply a default definition to a column directly using the CREATE or ALTER TABLE statement or through the Design Table option from within the Enterprise Manager. You can also create a default as its own object and then bind it to one or more columns. A default definition provided as part of a table definition is a standard and preferred method of implementing default entries. The advantages of this technique are that the default is dropped when the table is dropped and that the definition is stored within the table itself. A default object must be created and bound to the column in a twostep operation. To create and bind a default object, use the following code: CREATE DEFAULT StateDefault AS 'IN' sp_bindefault StateDefault, 'customers.state' To create a default within a table definition, use the following: CREATE TABLE SampleDefault (SampleID smallint NOT NULL CONSTRAINT UPKCL_SampleID PRIMARY KEY CLUSTERED, City varchar(50) DEFAULT ('Woodstock'), State char(2) DEFAULT ('NY')) When an INSERT operation is performed on a table, you must supply values for all columns that do not have a default entry defined or that allow NULL content. Application of Integrity OptionsAs discussed throughout this chapter, a number of techniques are available to maintain the integrity of the database. Each of these techniques will in part provide a usable, responsive system that prevents inappropriate data from getting into the system. Table 3.1 summarizes these techniques and provides some further detail as to what can be expected in their use. Table 3.1. Integrity Maintenance Objects
Note from Table 3.1 that most integrity techniques are applied before the data is actually allowed into the system, and therefore operate faster with a much lower overhead. Triggers offer the most functionality, but at a cost: the data is allowed into the system and then reacted upon. If a trigger determines that data should not be permitted, it must be rolled back. Use triggers sparingly and only when the application requires the additional functionality. When you define the table structure from the GUI, fill in the upper portion of the Design Table dialog box with column information by supplying the column name, selecting the appropriate data type from the drop-down list box, completing the Length field if the data type allows this to be adjusted, and setting whether the column is to allow NULL content. In the lower portion of the dialog box, you can optionally complete a description for the column, provide a default value, and, for numeric data types that allow for scale and precision, supply appropriate entries. If the column is to be an Identity column, select one of the integer data types, select Identity, and provide a starting value in the seed identification and an increment for the Identity. If the column is to be a row guid, select this option. If the column value is derived from a formula, specify the formula.
WARNING Collation for an Individual Column A collation can be selected for an individual column but is not recommended because it causes great difficulty in the development of front-end applications. Using T-SQL code, you create the tables as follows: CREATE TABLE projects (project_id smallint not Null IDENTITY(1,1) PRIMARY KEY CLUSTERED, project_description varchar(25) NOT NULL DEFAULT '*Unknown*', start_date datetime NOT NULL CHECK (start_date >= getdate()), completion_date datetime NOT NULL CHECK (completion_date >= getdate())) REVIEW BREAK: Database Design, an Involved ProcessConsider the functionality that is needed for any procedure that maintains the integrity of the data. In many cases, there are a number of choices that can be made between different techniques. The highest degree of functionality is achieved from stored procedures, followed closely by triggers. Also consider the basics of database design, regardless of application. Primary Keys, for example, serve a number of purposes and it is a good practice to implement them in almost any structure. To achieve availability and performance, redundancy is the starting point. Data redundancy can be obtained at the table and database level through denormalization, and at the server level through the use of log shipping, replication, and/or partitioning. Each technique has a variety of requirements that must be closely adhered to. There is no single, basic solution for any plan. Knowledge of the environment and how the data is going to be used will answer a number of the initial questions. There is no replacement for proper system development; you can't throw a technology at a problem and just hope it will go away. Research and plan the implementation and document each step of the way. |
EAN: N/A
Pages: 228