The ClientServer Model
The Client/Server Model
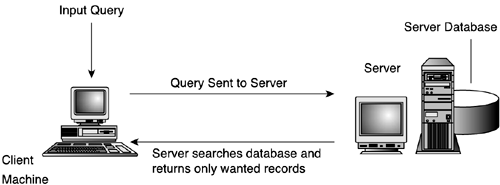
There are essentially two different models in which database systems can be described: a client/server model and a desktop database system. SQL Server can be used in both instances to store data and allow for application interaction. A client/server system divides the elements of a database system into two (or more) separate components , usually executing on two or more computers. The client component is responsible for the user interface and presents the data to the user in an attractive layout. This interface can be a Windows traditional form design or an HTML-based Internet design. The server is responsible for the data storage and actual manipulations of the data. This approach divides the processing and workload between the client, the server, and in some cases other machines as well. The client/server model can be thought of as a number of workstation computers accessing a central database from a server computer. In a concise sentence , the client/server model expresses a connection between a client program running on a workstation computer requesting a service and/or data from the server. When the client application needs certain data, it fetches that data from the server. The server application in turn runs a search against the server database to find the desired records. After the records are found, the server sends them back to the client application. In this way only data that is needed is sent back to the client, and thereby multiuser access is provided, in contrast to non-client/server desktop database systems that prefer singular access and have difficulty handling multiuser functionality. This process is shown in Figure 2.12. Figure 2.12. A basic overview of how Client/Server processes information. In a non-client/server desktop architecture, the whole database resides on the client's machine; the client then processes the query locally on the database and finds records as required. This process results in wasted disk space and is difficult to set up in a multiple-user environment. The server is concerned with uses such as concurrency, security, and backing up data. The client-side application is implemented with a nice user interface and might contain queries and forms. The roles of each computer are not, however, carved in stone, and depending on the interactions required in any given system, many machines may take part. The process of dividing up processing across many machines creates a multi-layered environment. Each layer in the environment is referred to as a tier and each tier has a specific role to play in the overall system. Application development and choice of model is a crossover stage between the logical development and the physical database structure. At times the choice of the number of tiers is accomplished before the physical database implementation. Others choose to prepare the database first. Neither is absolutely correct, but it is a good idea to have some idea of the model before determining the final physical data structure. One- and Two-Tier SystemsA one-tier system in a PC environment dates back 25 or more years to an environment where the only way to share data was to use the "sneaker net" approach. In other words, copies of the data were made and distributed manually. This approach was adequate at best and caused many headaches for anyone trying to implement a multiple-user environment. Particularly difficult was the merging of updates from multiple copies of the data. With a single-tier approach, one computer performs all the processing required to view, update, and store the data. Many products use this technique for small, single-user database systems, but this technique becomes overwhelming when the data is needed by multiple users sharing the same data. In this case, a two-tier with a central data store on a proper server is a better approach. A two-tier architecture places the user interface and data on separate machines. The client application sends queries across the network to be resolved by the data engine running on the server. The server resolves the query and sends the necessary data back across the network for the client application to display. There are two different implementations of a two-tier system: "thin client" and "thick client," which is also known as "fat client." In a thin approach the client application does little or no processing. A thin client just presents the data to the user and, when needed, communicates with the database engine on the server to work with the data. The thin client approach is best where the number of concurrent users accessing the data can be kept to a minimum. Because the server must perform the processing to validate the data as well as all other data manipulations, there is a lot of server overhead related to this approach. A thin client is a good approach for maintainability. If you need to upgrade software, for example, you do not have to do so on 1000 clients . It also works well for Internet applications. The thick client approach offloads some of the work needed to validate and process the data from the server machine to the client machine. In this approach the client may make some of the determinations as to whether data should be sent to the server based on validity checks coded in the client application. This approach enables many more users to access the same database concurrently. On the down side, though, application maintenance is more demanding and higher performance is required from the client. Although two-tier architectures allow for more flexibility and a larger number of users, it is still quite a limited architecture that can serve only small environments. When a larger number of concurrent user accesses is needed, a better choice of architecture is a multiple " n-tier " architecture or possibly an Internet architecture. Three- or More Tier SystemsIn a three-tier system, the client system presents the interface and interacts with the user. The database server manipulates the data, but there also exists a middle tier to control some of the operations. The middle tier can be represented by one or more machines that offload some processing from the database server, which allows for a very large number of users. There is usually no differentiation between three or more tiers and instead they are all categorized as n-tier systems. In an n-tier system, processing is divided into three categories. Each category represents one of the three main tiers in the three-tier system, which is also carried forward in an n-tier system regardless of the number of layers of processing. The presentation or client tier contains the components of the system that interact directly with the user. The sole purpose of this tier is to focus on the end user and present data in an attractive, organized, and meaningful fashion. The middle tier, or business tier, is responsible for communicating with the database server and also sets up the rules by which communication will be established. The idea behind the business tier is to provide mechanisms to implement the business rules that need to be applied to validate data and also perform intermediate processing that may be needed to prepare the data for presentation to the user. For this reason the business tier is often separated into two divisions: interactions with the user and interactions with the database server. With this approach business rules can be separated from data access processes. The final tier is the data tier, which is responsible for the execution of the data engine to perform all manipulations of the data. Access to the data tier is made through the middle tier. The data tier doesn't directly interact with the presentation layer. Internet ApplicationsInternet applications can be said to fall under a two- or three-tier model, depending on the complexity and physical design. In an Internet application, the web server prepares the presentation elements to be displayed on the user's browser. If a middle tier server exists, then the web server is configured to interact with that server. If no middle tier server exists, then the web server interacts directly with the database server. Depending on the implementation, the client's browser may also be considered a tier. If a set of records is sent to the browser by the web server to allow editing on the browser, then the client is considered a tier. In this case, a disconnected recordset or XML data is used for the client's data manipulation. If a round trip to the web server must take place to submit changes and interact with the data, then the client is not considered a tier ”it is more just a mechanism to display the HTML that is sent by the web server. In this case the user tier is the Internet server that acts as the user and prepares the HTML for display. Internet applications have the best scalability of all application architecture types, meaning that they can support the largest number of concurrent users. The drawback to using an Internet architecture is that it requires a greater number of development skills, and update conflict issues are inherent to the technology. Although an Internet application is usually implemented so that the database can be accessed from anywhere in the world, it can also be used for internal purposes through a configured intranet. Under this principle, users can access the database from a corporate HTML or XML site. Very Large Database ApplicationsSQL Server 2000 has high-speed optimizations that support very large database environments. Although previous versions lacked the capability to support larger systems, SQL Server 2000 and SQL Server 7.0 can effectively support terabyte- sized databases. With the implementation of partitioned views in Enterprise Edition, servers can be scaled to meet the requirements of large Web sites and enterprise environments. Federated server implementations enable a large number of servers to assist in maintaining a complex large system. Elements of the replication system can also help distribute data among a number of machines while providing mutual updatability and maintaining centralized control over the entire system. Third-Party Database InteractionsSQL Server 2000 supports heterogeneous connectivity to any data source through the use of OLE-DB and ODBC drivers, which are available for most common databases. SQL Server can move data to and from these sources using Data Transformation Services (DTS), replication, and linked server operations. SQL Server can act as a gateway to any number of data sources and either handle a copy of the data itself or pass the processing to the third-party source. The capability of SQL Server to act with almost any third-party source means that existing applications can continue to function in the environment undisturbed while SQL Server applications can also make use of the same data. |
EAN: N/A
Pages: 228