Types of Replication
| Replication can be divided into three main categories:
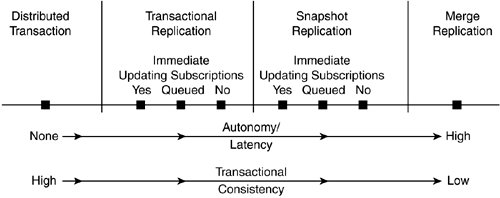
Each model provides different capabilities for distributing data and database objects. There are many considerations for selecting a replication type or determining whether replication is a suitable technique for data distribution. The many considerations to determine the suitability of each of the models include transactional consistency, the subscriber's capability or lack of capability to update data, latency, administration, site autonomy, performance, security, update schedule, and available data sources. Each of these are defined as replication and are discussed through the next several sections. Other data distribution techniques that don't involve replication can offer a different set of features but may not provide for the flexibility offered by replication. To determine which replication type is best suited to your needs, consider the three primary factors: site autonomy, transactional consistency, and latency. These three considerations are illustrated in Figure 11.6, which also compares and contrasts data distribution techniques. Figure 11.6. Site autonomy in replication. Site autonomy refers to whether one site is independent from all other sites when processing modifications. Site autonomy measures the effect of your site's operation to another. A site having full autonomy is completely independent of all other sites, meaning it can function without even being connected to any other site; high site autonomy can be achieved in SQL Server replication where it would not be possible using other data distribution techniques. Not all replication configurations achieve autonomy; such high site autonomy can be seen best with merge replication, which is detailed later. Site autonomy directly affects transactional consistency. To achieve an environment that is both autonomous and has a high degree of transactional consistency, the data definition must provide a mechanism to differentiate one site from the other. A compound Primary Key, for example, in a Central Subscriber or Multiple Publisher, Multiple Subscriber scenario allows autonomy while achieving transactional consistency. If an implementation enables each site to update the same data, then it will always have some degree of transaction inconsistency or at least a delay before consistency is achieved. Transactional Consistency in ReplicationTransactional consistency is a measure of changes made to data, specifically those changes that remain in place without being rolled back. Changes can get rolled back due to conflicts, and this will affect user changes and other user activities. In replication you have multiple distinct copies of your data, and if you allow updates to each copy, then it is possible for different copies of a piece of data to be changed differently. If this situation is allowed, as is the case in some forms of replication, you have imperfect (low) transactional consistency. If you prevent two copies from changing independently, as is the case with a distributed transaction, then you have the highest level of transactional consistency. In a distributed transaction, the application and the controlling server work together to control updates to multiple sites. Two-phase commits implemented in some forms of replication also help. The two phases used are preparation and committal . Each server is prepared for the update to take place, and when all sites are ready the change is committed at the same time on all servers. After all sites have implemented the change, transactional consistency is restored. Latency in ReplicationLatency can be thought of as how long data in the Subscriber has to wait before being updated from the copy of the data on the Publisher. Several factors contribute to latency, but it is essentially the length of time it takes changes to travel from the Publisher to the Distributor and then from the Distributor to the Publisher. If there is no need for the data to be the same, at the same time, in all Publishers and Subscribers, then the latency resident within a replication strategy will not negatively affect an application. A two-phase commit, as SQL Server implements through the use of immediate updating, can minimize latency on updates coming from the Subscriber, but has no effect on updates sent from the Publisher. Latency can be affected by the workload on the Publisher and Distributor, the speed and congestion of the network, and the size of the updates being transported. NOTE Non-Replicable Objects In a replication process, system tables in any database cannot be replicated. The following databases also cannot be replicated:
SnapshotSnapshot replication distributes data and database objects by copying the entire contents of the published items via the Distributor and passing them on to the Subscriber exactly as they appear at a specific moment in time, without monitoring updates. A snapshot is stored on the Distributor, which encapsulates data of published tables and database objects; this snapshot is then taken to the Subscriber database via the Distribution Agent. Snapshot replication is advantageous when replicated data is infrequently updated and modified. A snapshot strategy is preferable over others when data is to be updated in a batch. This does not mean that only a small amount of data is updated, but rather that data is updated in large quantities at distant intervals. Because data is replicated at a specific point in time and not replicated frequently, this type of replication is good for online catalogs, price lists, and the like, where the decision to implement replication is independent of how recent data is. Snapshot replication offers high levels of site autonomy. It also offers a great degree of transactional consistency because transactions are enforced at the Publisher. Transactional consistency also depends on whether you are allowing updating Subscribers, and what type (immediate or queued). Snapshot replication can be used alongside Immediate Updating Subscribers using two-phase commit (2PC). In this type of replication, the Subscriber needs to be in contact with the Publisher. Queued update, on the other hand, doesn't require constant connectivity. When you create a publication with queued updating, and a Subscriber performs INSERT , UPDATE , or DELETE statements on published data, the changes are stored in a queue. The queued transactions are applied at the Publisher when network connectivity is restored. After the information is delivered (by either method), the Subscriber can change the replica on its local server; hence snapshot replication provides medium-to-high autonomy. When Updating Subscribers are used, a trigger is located at the Subscriber database that monitors for changes and sends those changes to the publishing server via the Microsoft Distributed Transaction Coordinator (MS DTC). NOTE What Exactly is 2PC? 2PC, or Two-Phase Commit, is replication where modifications made at the Publisher are made at exactly the same time on the Subscriber. The two phases are "Prepare" and "Commit." All servers prepare for the changes and then, when ready, commit the changes at the same time. Snapshot replication is suited to situations where data is likely to remain unchanged, it is acceptable to have a higher degree of latency, and replication involves small volumes of data. It is preferred over Transaction replication when data changes are substantial but infrequent. Application of snapshots using native BCP or compression helps to improve performance. There are some significant points to remember about snapshot replication and how it differs from the other types of replication:
Network considerations include the application of the original data on the subscribing machines as well as ongoing operation of the replication processes. Transferring the initial data to a CD-ROM and shipping the CD to the Subscriber may be the best solution in the case of a slow or intermittent network link. Compression of the initial snapshot into .CAB files, as defined in the following process, can also preserve the network bandwidth. Step by Step 11.1 shows you how to compress and send snapshots:
Transactional ReplicationTransactional replication is defined as the moving of transactions captured from the transaction log of the publishing server database and applied to the Subscriber's database. The transactional replication process monitors data changes made on the Publisher. Transactional replication captures incremental modifications that were made to data in the published table. The committed transactions do not directly change the data on the Subscriber but are instead stored on the Distributor. These transactions held in distribution tables on the Distributor are sent to the Subscriber. Because the transactions on the Distributor are stored in an orderly fashion, each Subscriber acquires data in the same order as is in the Publisher. When replicating a publication using transactional replication, you can choose to replicate an entire table or just part of a table using a method referred to as filtering . You can also select all stored procedures on the database or just certain ones that are to be replicated as articles within the publication. Replication of stored procedures ensures that the definitions they provide are in each location where the data is located. Processes that are defined by the stored procedures can then be run at the Subscriber. Because the procedures are being replicated, any changes to these procedures are also replicated. Replication of a stored procedure makes the procedure available for execution on the local server. In transactional replication, like snapshot replication, Updating Subscribers may be used with 2PC for the immediate update option. This enables the Subscriber to change the replica at his local server. Changes made to data at the Subscriber are applied both to the Subscriber and Publisher databases at the same moment, proving high transactional consistency and less latency. It is possible to get a conflict when using the queued update option. No conflicts can occur with immediate updating of Subscribers because of the use of a 2PC that guarantees that a change is reflected on both the Publisher and the Subscriber, or neither . A Primary Key must be defined on the published table, and a WRITETEXT or UPDATETEXT operation must supply the WITH LOG option. Before implementing or going further into replication, you should be well acquainted with the preliminaries . Some transactional replication considerations are given in the following list:
Merge ReplicationMerge Replication is the process of transferring data from the Publisher to the Subscriber, enabling the Publisher and Subscriber to update data while they are connected or disconnected, and then merge the updates after they both are connected, providing virtual independence. Merge replication therefore allows the most flexibility and adds the most autonomy to the replication process. Merge replication is also the most complex replication because it enables the Publisher and Subscriber to work virtually independently. The Publisher and Subscriber can combine their results at any certain time and combine or merge their updated results. The Snapshot agent and the Merge agent help in carrying out the process of merge replication. The Snapshot agent is used for the initial synchronization of the databases. The Merge agent then applies the snapshot; after that, the job of the Merge agent is to increment the data changes and resolve any conflicts according to the rules configured. Conflicts are likely to occur with merge replication. Conflicts occur when more than one site updates the same record. This happens when two users concurrently update or modify the same record with different values. When a conflict occurs, SQL Server has to choose a single value to use. It resolves the conflict based on either the site priority on the database site or a custom conflict resolver. You could give more priority to, for instance, a user in the HR department than one from the sales department. When a conflict is detected , it is resolved immediately after the conflict resolver is executed. A conflict occurs when the publisher and subscriber have both changed the record since they last shared a common version. Conflicts can be record based or column based. The default is column based. Merge replication is well suited to scenarios where conflicts are less likely to occur. For instance, a site might make changes to its internal records only, possibly needing data from all other locations, but not changing any of it. A conflict occurs when the two participants have both changed a record (or column within a record) since they last shared the same version. Merge replication offers site autonomy at its apexbecause sites are virtually independentand low transactional consistency. These sites, or Subscribers, can freely make modifications to their local copies of the replicated data. These modifications and updates made to data are combined with modifications made at the other Subscribers and also with the modifications at the Publisher. This process ultimately ensures that all Subscribers and Publishers receive modifications and updates from all other sites; it is better known as convergence . You may think right away that this type of replication lends itself to the Multiple Subscribers, Multiple Publishers configuration, but this is not always the case. As mentioned earlier, transactional consistency is extremely low and can be a problem in merge replication because conflicts can occur when different sites change the same data. For instance, there may be users on two sites that modify the same record on their local copy of a database. If a user in Texas modifies record #5 of a table and a user in California modifies record #5 as well, a conflict will occur on record #5 when replication takes place because the same record has been modified at two different sites; thus, SQL Server has to determine which value to accept. One record has to overwrite another. There are ways to control this dilemma, the default rule being that site priority determines which record is accepted. You can also create custom stored procedures that verify which record is the correct record to use. Whether this is a conflict or not depends on the situation. If the conflict is column-based and both sites change a different column in the same record, it is not a conflict. If one of these two sites is the Publisher and the conflict is record-based, then it would be a conflict. There is a lot of activity occurring regardless of the type and model of replication being used. Management over this process requires that there be database server elements, executing on all participating machines, to perform the individual operations. In SQL Server these elements are referred to as agents . The agents involved in the process and a description of their roles is the next topic of discussion. |
EAN: N/A
Pages: 228