String Handling
[Previous] [Next]
WDM drivers can work with string data in any of four formats:
- A Unicode string, normally described by a UNICODE_STRING structure, contains 16-bit characters. Unicode has sufficient code points to accommodate the language scripts used on this planet (and on at least one other—see http://www.indigo.ie/egt/standards/csur/klingon.html ).
- An ANSI string, normally described by an ANSI_STRING structure, contains 8-bit characters. A variant is an OEM_STRING, which also describes a string of 8-bit characters. The difference between the two is that an OEM string has characters whose graphic depends on the current code page, whereas an ANSI string has characters whose graphic is independent of code page. WDM drivers would not normally deal with OEM strings because they would have to originate in user mode, and some other kernel-mode component will have already translated them into Unicode strings by the time the driver sees them.
- A null-terminated string of characters. You can express constants using normal C syntax, such as "Hello, world!" Strings employ 8-bit characters of type CHAR, which are assumed to be from the ANSI character set. The characters in string constants originate in whatever editor you used to create your source code. If you use an editor that relies on the then-current code page to display graphics in the editing window, be aware that some characters might have a different meaning when treated as part of the Windows ANSI character set.
- A null-terminated string of wide characters (type WCHAR). You can express wide string constants using normal C syntax, such as L"Goodbye, cruel world!" Such strings look like Unicode constants, but, being ultimately derived from some text editor or another, actually use only the ASCII and Latin1 code points (0020-007F and 00A0-00FF) that correspond to the Windows ANSI set.
The UNICODE_STRING and ANSI_STRING data structures both have the layout depicted in Figure 3-14. The Buffer field of either structure points to a data area elsewhere in memory that contains the string data. MaximumLength gives the length of the buffer area, and Length provides the (current) length of the string without regard to any null terminator that might be present. Both length fields are in bytes, even for the UNICODE_STRING structure.
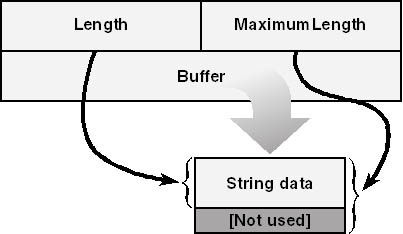
Figure 3-14. The UNICODE_STRING and ANSI_STRING structures.
Table 3-7 lists the service functions that you can use for working with Unicode and ANSI strings. I've listed them side by side because there's a fair amount of duplication. I've also listed some functions from the standard C run-time library that are available in kernel mode for manipulating regular C-style strings. The standard DDK headers include declarations of these functions, and the libraries with which you link drivers contain them, so there's no particular reason not to use them even though they've never been documented in the DDK as being available.
Table 3-7. Functions for string manipulation.
| Operation | ANSI String Function | Unicode String Function |
|---|---|---|
| Length | strlen | wcslen |
| Concatenate | strcat, strncat | wcscat, wcsncat, RtlAppendUnicodeStringToString, RtlAppendUnicodeToString |
| Copy | strcpy, strncpy, RtlCopyString | wcscpy, wcsncpy, RtlCopyUnicodeString |
| Reverse | _strrev | _wcsrev |
| Compare | strcmp, strncmp, _stricmp, _strnicmp, RtlCompareString, RtlEqualString | wcscmp, wcsncmp, _wcsicmp, _wcsnicmp, RtlCompareUnicodeString, RtlEqualUnicodeString, RtlPrefixUnicodeString |
| Initialize | _strset, _strnset, RtlInitAnsiString, RtlInitString | _wcsnset, RtlInitUnicodeString |
| Search | strchr, strrchr, strspn, strstr | wcschr, wcsrchr, wcsspn, wcsstr |
| Upper/lowercase | _strlwr, _strupr, RtlUpperString | _wcslwr, _wcsupr, RtlUpcaseUnicodeString |
| Character | isdigit, islower, isprint, isspace, isupper, isxdigit, tolower, toupper, RtlUpperChar | towlower, towupper, RtlUpcaseUnicodeChar |
| Format | sprintf, vsprintf, _snprintf, _vsnprintf | swprintf, _snwprintf |
| String conversion | atoi, atol, _itoa | _itow, RtlIntegerToUnicodeString, RtlUnicodeStringToInteger |
| Type conversion | RtlAnsiStringToUnicodeSize, RtlAnsiStringToUnicodeString | RtlUnicodeStringToAnsiString |
| Memory release | RtlFreeAnsiString | RtlFreeUnicodeString |
Many more RtlXxx functions are exported by the system DLLs, but I've listed the ones for which the DDK header files (and the SDK headers they include) define prototypes. These are the only ones we should use in drivers.
Allocating and Releasing String Buffers
I'm not going to describe the string manipulation functions in detail because the DDK documentation does this perfectly well and you already know, based on your general programming experience, how to put functions like this together to get your work done. But I do want to discuss a problem that can rear up and bite you if you don't look out for it.
You often define UNICODE_STRING (or ANSI_STRING) structures as automatic variables or as parts of your own device extension. The string buffers to which these structures point usually occupy dynamically allocated memory, but you'll sometimes want to work with string constants, too. Keeping track of who owns the memory to which a particular UNICODE_STRING or ANSI_STRING structure points can be a bit of a problem. Consider the following fragment of a function:
UNICODE_STRING foo; if (bArriving) RtlInitUnicodeString(&foo, L"Hello, world!"); else RtlAnsiStringToUnicodeString(&foo, "Goodbye, cruel world!", TRUE); ... RtlFreeUnicodeString(&foo); // |
In one case, we initialize foo.Length, foo.MaximumLength, and foo.Buffer to describe a wide character string constant in our driver. In another case, we ask the system (by means of the TRUE third argument to RtlAnsiStringToUnicodeString) to allocate memory for the Unicode translation of an ANSI string. In the first case, it's a mistake to call RtlFreeUnicodeString because it will unconditionally try to release a memory block that's part of our code or data. In the second case, it's mandatory to call RtlFreeUnicodeString eventually if we want to avoid a memory leak.
Data Blobs
I've borrowed the term data blob from the world of database management to describe a random collection of bytes that you want to manipulate somehow. Table 3-8 lists the functions (including some from the standard run-time library) that you can call in kernel mode for that purpose. Once again, I'm going to assume that you can figure out how to use these functions (based on their largely mnemonic names). I need to point out a few nonobvious facts, however:
- The difference between a memory "copy" and a memory "move" is whether the implementation can tolerate an overlap between the target and source. A move operation is more general in that it works correctly whether or not there's an overlap. The copy operation is faster because it assumes it can perform a left-to-right copy (which won't work if the target overlaps the right portion of the source).
- The difference between a "byte" and a "memory" operation is in the granularity of the operation. A byte operation is guaranteed to proceed byte by byte. A memory operation can use larger chunks internally, provided all the chunks add up to the specified number of bytes. If this distinction is meaningless on a particular platform (as is true for x86 computers), the byte operations are actually macro'ed to the corresponding memory operations. Thus, RtlCopyBytes is a different function than RtlCopyMemory on an Alpha but is #define'd equal to RtlCopyMemory on a 32-bit Intel.
Table 3-8. Service functions for working with blobs of data.
| Service Function or Macro | Description |
|---|---|
| memchr | Find a byte in a blob |
| memcpy, RtlCopyBytes, RtlCopyMemory | Copy bytes, assuming no overlap |
| memmove, RtlMoveMemory | Copy bytes when there might be an overlap |
| memset, RtlFillBytes, RtlFillMemory | Fill blob with given value |
| memcmp, RtlCompareMemory, RtlEqualMemory | Compare one blob to another |
| memset, RtlZeroBytes, RtlZeroMemory | Zero-fill a blob |
EAN: 2147483647
Pages: 93