Replication Topology
| < Day Day Up > |
| The final phase of the logical design is the design of replication topology. The approach to dealing with replication topology design varies considerably, depending on whether you are migrating from Windows NT or Windows 2000 to Windows Server 2003. Because a considerable segment of the Windows enterprises are still in Windows NT 4.0 domains, it makes sense to discuss both scenarios. note If you are in a Windows 2000 environment, and are tempted to skip this section, note that some of the greatest changes in Windows Server 2003 were made in regard to AD replication so study this section to get a full account of these changes so you can take advantage of them. Here we will discuss some basics of how replication works, some of the issues and problems in Windows 2000, and the changes in Windows Server 2003 to fix those problems and improve functionality. Like the other topics in this chapter, this is not intended to be a comprehensive discussion of AD replication, but a discussion of issues that present design challenges and how to address those challenges. Some of the improvements and changes in Windows Server 2003 replication technology might provide justification for the migration from Windows 2000. note In my five years of experience with Windows 2000 in customer support, AD replication has been the single biggest source of problems in enterprises if it isn't configured correctly. If you take time to understand replication and design it correctly using that knowledge (or that of a knowledgeable consultant), you will save yourself a lot of time and your company a lot of money in support, downtime, and troubleshooting efforts. Replication Topology BasicsMy previous book, Windows 2000: Active Directory Design and Deployment (New Riders, 2000) contained a complete chapter on AD replication. This section touches on basic concepts for a foundation, but you should refer to a more complete discussion of replication from other sources, such as the book just mentioned. note A glossary of terms used in this section describing AD replication is contained in Appendix C, "Glossary of Active Directory Replication Terminology." Refer to that Appendix for a thorough description of these terms. Single-Master versus Multiple-Master ModelsIn Windows NT, replication was a simple single-master model. That is, one DC, the PDC, is the only DC that holds a writeable copy of the directory (users, computers, and so on). The Backup Domain Controllers (BDCs) hold read-only copies and periodically pull changes down from the PDC. This model is very limited and does not scale well. There is a limit of about 40,000 objects. This presents problems for large- or even medium- size environments. Compaq, before the merger with HP in 2002, had to employ 13 Master User Domains (MUDs) to contain all the users, computers, and so on. Compaq had another 1,500 or so resource domains containing file servers, printers, and other resources, which was difficult to manage. One person's full-time job was maintaining the trusts. Furthermore, because the PDC in each Windows NT domain has the only writeable copy, all account changes (such as adding/deleting users) had to take place on the PDC, which created a bottleneck. Windows 2000 employs a multimaster replication model in which every DC holds a writeable copy of the database. Thus, write operations are distributed to the local DC rather than crossing the WAN to find the PDC. This makes Windows 2000 much more scaleable, to hundreds of millions of objects for a single domain, and Windows Server 2003 claims to be able to hold even more, all without significant performance degradation. This allows a domain structure to be built on business needs rather than business being forced into the model the OS supports, as was the case in Windows NT 4.0. For instance, when Compaq migrated to Windows 2000 from Windows NT, we were able to use a four-domain model: a root domain (cpqcorp.net) and three child domains (Americas, EMEA, and AsiaPacific). Obviously, this is a much simpler model to manage and administer, and Compaq realized huge cost savings on server consolidation. Complexity of the Multimaster ModelAD's multimaster replication model is complex and much more difficult to manage and troubleshoot than Windows NT was with its single-master model. Consider an environment where there is a DC at each site. Windows 2000 and 2003 support Site Affinity, meaning that capable clients always attempt to contact a DC that is in their local site preferentially. Clients that have "site awareness" capability include Windows 2000 Professional and Windows XP clients (built in). To get the site-awareness functionality on Windows 9x and Windows NT Workstation clients , you can install the Directory Services Client (DSClient) add-on. note The DSClient is available on Microsoft's Web site. You can get more information on the DSClient and how to obtain it in Microsoft KB 288358, "How To Install the Active Directory Client Extension," and 295168, " INFO : Files installed by Directory Services Client Extension for Windows NT 4.0." Note, however, that the DSClient isn't bulletproof and you might have mixed results with it. Site-aware clients authenticate, change passwords, and perform other tasks that modify AD objects at their local DC. The DCs then have to replicate this information to their replication partners and do the same with other replication partners until all other DCs in the domain have been updated appropriately. In a dynamic environment with a lot of DCs in a lot of sites, this means significant activity for the DCs trying to keep in sync with each other. An experienced Administrator knows that any time you make a critical change to the AD, you must wait for replication to take place, end-to-end in the forest. For instance, if you demote and remove a DC and want to promote another machine to a DC with the same name as the old one, you must wait for replication to take place before promoting the new one. However, Windows 2000 has proven itself very resilient. In one case, a customer demoted a DC and removed it from the domain, and then 5 minutes later, promoted another machine with the same name. This creates two objects, each with the same name , but a different GUID. The old object was in the process of being tombstoned on the other DCs when the new object was created. I reasoned that there would be some confusion for a while because each DC would have a different view of the AD for a while (some seeing the old one, some the new one, and some seeing both), but eventually it should work itself out. Sure enough, 63 hours later (we counted), the old DC object was tombstoned on all DCs in the domain and the new object was active. Windows Server 2003 has made an improvement on this scenario, in that the Knowledge Consistency Checker (KCC) will not propagate the new object until the old one is deleted, making it more resilient. Replication DampeningWindows 2000 and 2003 contain built-in processes to prevent excessive replication. An excellent detailed description of how replication works, including replication dampening, is contained in the replication chapter in the Distributed Systems Guide of the Windows 2000 Resource Kit (see http://www.microsoft.com/windows/reskits/). These two methods are the Highwatermark table and the up-to-dateness vector. The Highwatermark table allows a DC to determine whether its replication partner has been updated since they last replicated. If there are no new updates, then no replication is initiated. The up-to-dateness vector tells a DC's replication partner not only that a change was made to an object or attribute, but also the name of the DC that made the change (called the originating write ). This prevents objects and attributes from being replicated to any DC more than once and is referred to as replication dampening . Challenges and Issues in AD ReplicationConsidering the huge jump to multimaster replication in Windows 2000, Microsoft didn't do a bad job. Obviously with it being the first version, there were a lot of limitations that weren't apparent at the outset. The most significant issues in Windows 2000 replication that impacted the design included
Let's briefly review these issues because a good history lesson is important for those moving from Windows NT to 2003 and a good source of justification for those considering a migration from Windows 2000 to 2003. Practical Limit to Number of SitesThe most misunderstood limitation in Windows 2000 has been eliminated in Windows Server 2003, as noted in the next section. However, a brief description of the limitation will help Windows 2000 Admins understand the problem. Simply stated, the KCC runs under the LSASS process (mostly). Every time it fires up to check and generate the replication topology, it takes about 90% of the CPU (of one processor) of the machine, and then subsides. The more complex the topology, the longer it takes the KCC to generate it, and the longer it hogs the CPU. In Microsoft's KB article 244368, "How to Optimize Active Directory Replication in a Large Network," the following equation is given to calculate the KCC's topology generation time, based on a Pentium III, 500MHz server:
For instance, if you have 1,000 sites and 5 domains using Pentium III, 500MHz machines, it will take the KCC about 45 minutes to generate the topology. Because, by default, the KCC does this every 15 minutes, it will soak the CPU for 45 minutes, go to sleep for 15 minutes, and then do it all over again. Thus, you have about 15 minutes of every CPU hour to do other things, such as authentication, replication, and so on. Obviously, this isn't good. Microsoft advised that configurations of more than about 250 sites were not recommended ”not because of a hard limit, but because this is a tolerable threshold that keeps the KCC from being too intrusive on CPU time. One solution to this was to disable Auto Site Link Bridging, which would change the KCC processing time in this example to about 3 minutes. Another solution was to upgrade the hardware to Pentium 4, 2GHz machines, which could lower the KCC time in this example to 4 to 5 minutes even with Auto Site Link Bridging enabled. note Microsoft's calculation used here is very much dependant on hardware. Using a faster processor and/or more memory will reduce the KCC's time considerably. Windows Server 2003 features a completely rewritten spanning tree algorithm used to calculate the topology. The new equation to calculate the KCC topology generation time is
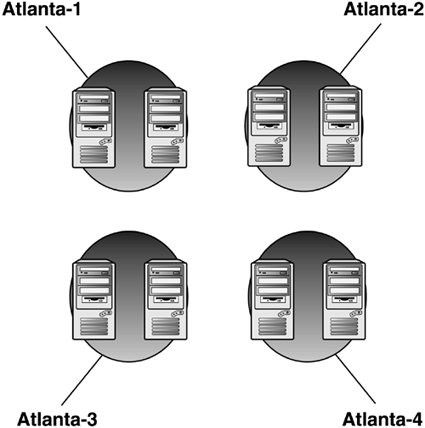
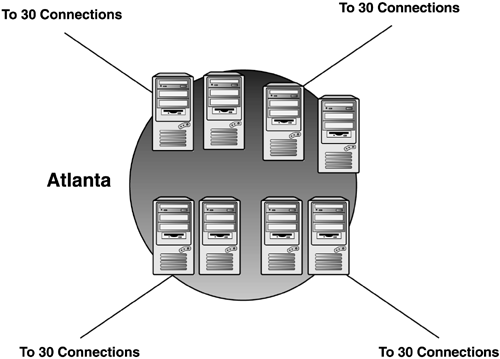
Using this new formula, the KCC can generate the topology of a single domain 5,000-site configuration in about 30 seconds with Auto Site Link Bridging turned on; hardware improvements will make it even faster. Practical Limit to Number of Sites Replicating to a Single Site and Replication Load BalancingSimilar to the practical limit to the number of sites, Microsoft determined early on that there is a practical limit to the number of BHSs that can replicate to a single BHS in the hub site. For instance, in a single domain, hub, and spoke configuration, all of the "satellite sites" replicate to a single BHS in the hub site. The capability of this configuration to replicate efficiently depends on the hardware resources (processors and memory), WAN speed and reliability, and whether they are replicating with a DC or in a multiple domain environment with a GC. Further, a BHS can handle a limit of one inbound and ten outbound replication threads at a time. HP consultants , through experience in load-balancing BHS, have determined that about 120 connections can be handled at a site, based on average network bandwidth and hardware configuration. Because each BHS can handle 10 outbound threads using a 90-minute replication interval, you can create manual connection objects and schedule them to run 10 at a time, every 30 minutes. So 10 will run at :00, 10 more will run at :30, and 10 more at :60. Thus, you can get 30 connections by having them replicate at intervals and spread out the network usage. Further, you can increase the connections by adding additional BHSs to the site, each of which can have 30 connections. Experience as cited by HP consultants has shown that it is reasonable to add 4 BHSs to a site to get up to 120 total connections. You can do this by either creating a site for each BHS (as shown in Figure 5.37) or by creating manual connection objects between remote site BHSs and the hub DCs (as shown in Figure 5.38). In the first example in the Atlanta hub, we created 4 sites ”Atlanta-1, Atlanta-2, Atlanta-3, and Atlanta-4 ”and put one DC in each one. This permits the KCC to manage the connections in each site. The 4 sites would be connected with a low-cost site link. In the second example, we simply divide the remote sites so that 30 sites replicate to DC1, 30 other sites replicate to DC2, and so on. This is accomplished by creating manual connection objects between each remote BHS and the DC at the hub you want it to replicate with. The KCC will honor those connections and effectively replicate to multiple DCs, but you must manage those connections. Figure 5.37. Bridgehead load balancing could be achieved in Windows 2000 by putting hub site DCs into separate sites connected with a low-cost site link. Figure 5.38. Bridgehead load balancing in Windows 2000 could also be achieved by creating manual connection objects from select groups of BHSs in satellite sites to specific DCs in the hub site, providing multiple BHSs in the hub site to handle the load. tip Microsoft's "Branch Office Deployment Guide" is an excellent treatise of BHS load balancing and provides a set of scripts to help in managing the connections. note Windows Server 2003 provides for multiple BHSs in each site for each domain by default and thus eliminates the problem experienced in Windows 2000. In addition, the Active Directory Load Balancing (ADLB) tool, available for free download from Microsoft, provides automatic intersite connection objects to be created and balanced among the available DCs, effectively eliminating the issues just described for Windows 2000. The ADLB can manage connections in Windows 2000 as well as Windows Server 2003 forests. Replication Over Slow LinksPerhaps the most significant breakthrough in replication design was achieved when Andreas Luther and his team at Microsoft authored the "Branch Office Deployment Guide." Enterprises that suffer with many slow links between sites were frustrated at the difficulty Windows 2000 had with replicating across those links. Deploying Exchange 2000 exacerbated the problem by requiring good connectivity to a GC because the GAL is held on the GC. This, in turn , required GCs to be located at each site running an Exchange 2000 server. Because these links suffer a high utilization and often are not reliable, replication failure rate is quite high. The solution to this would be to manually schedule the KCC to run at certain times of the day (originally described in Microsoft KB 244368 and 242780, "How to Disable the Knowledge Consistency Checker from Automatically Creating Replication Topology"). There was even a script in the Windows 2000 Resource Kit, runkcc.vbs, which helped you do it, but it was ugly. Trying to do all the work of the KCC manually for large environments is a daunting task. Another solution to prevent the overload on a BHS at the hub site in Windows 2000 was to create artificial sites for each DC at the hub site. This would force the KCC to make each DC a BHS, and the Administrator would manually distribute the site links to the remote sites among those BHSs. Of course, the problem is that there is no failover if a single BHS goes down, causing the Admin to reconfigure the remote site links until the BHS came back online. note The KCC allows a grace period of 2 hours to a failed intersite connection before it takes action to route around it, and allows 12 hours for transitive replication partners. Thus, it isn't necessary to react with failures that can be caused by network usage problems or the partner DC being unresponsive due to a temporary unavailability of resources, a required reboot, or other correctable reasons. Note also that when a failover occurs where a DC picks a new replication partner, a full synchronization of the SYSVOL tree is initiated (issuing a vvjoin operation), causing a temporary disruption of service on the sourcing DC due to the load caused by the replication. This can have a significantly negative effect on DCs in sites accessed through slow WAN links and should be avoided or scheduled for off-hours operation. For more information, refer to the vvjoin information in the "File Replication Service (FRS) Design and Implementation" section later in this chapter, as well as the "File Replication Service Terminology" section in Appendix C. The "Branch Office Deployment" whitepaper provided not only methods to manage the replication processes and topology, but a few helpful scripts as well. It is available at http://www.microsoft.com/windows2000/techinfo/planning/ activedirectory /branchoffice/default.asp. This paper describes how to set and maintain a complex schedule to minimize the impact on the WAN links. It also includes a set of Perl scripts, MKDSK, which help the Administrator manage the connections. In addition, Microsoft has established a Windows Service Branch Office team that is working with customers who deploy branch offices over slow or unreliable links to define and resolve their unique issues with deploying AD. TombstoneLifetime AttributeDeleted objects are tombstoned for 60 days (default value for the tombstonelifetime attribute). This means when an object is deleted, it's placed in the deleted objects folder container in the AD and kept until the tombstonelifetime expires . At that point, the Garbage Collection process purges them from the AD (see Microsoft KB 198793, "The Active Directory Database Garbage Collection Process"). New server objects for DCs can be given the same name as a tombstoned object with no conflict as long as end-to-end replication has occurred and the object is tombstoned on all DCs. For instance, you can demote a DC, wait for end-to-end replication to occur, and then promote another DC to use that same name without waiting for the tombstone to expire. The tombstonelifetime attribute is located in the AD at CN=Directory Service,CN=Windows NT,CN=Services, CN=Configuration, DC=company,DC=com where DC=company,DC=com is the name of the domain. Shortening the tombstonelifetime attribute is not recommended. Although end-to-end replication, even in complex environments, usually takes place within an 8- to 24-hour timeframe, the 60-day period allows DCs and GCs to be unavailable for a longer period of time and still be able to rejoin the domain without hurting the infrastructure. More importantly, the tombstonelifetime limits the lifetime of the backup media. You cannot have backup media more than tombstonelifetime days old because a restored DC would reintroduce deleted objects just like DCs that were offline for too long (see Microsoft KB 216993, "Backup of the Active Directory Has 60 Day Useful Life"). If tombstonelifetime were set to 7 days, DCs that were offline due to replication errors, hardware failures, network outage , and so on would have to be rebuilt and the AD cleaned up. In addition, backup media would only have a useable lifetime of 7 days. Lingering ObjectsIn presentations on AD troubleshooting I've made at a number of technical conferences over the past several years, only one or two people have ever heard of lingering objects . Although it's not a well-known issue, ironically, it's fairly common. Lingering objects are objects that were deleted, tombstoned, and purged, but were then reanimated by a DC or a GC that was offline during the purge and then comes back online and replicates the objects. HP's AD infrastructure team fought some interesting battles with lingering objects. Lingering objects have been deleted from the writable copy of an AD partition, but one or more direct or transitive replication partners that host writable or read-only (GC) copies of that partition did not replicate the deletion within tombstonelifetime number of days from the originating delete. Lingering objects affect inbound replication only by reanimating deleted objects. Consider a case in which you have 1,000 employees leave a company over a 60-day period. A DC, which has been offline during that 60-day period and longer, comes back online. It still has a copy of those deleted users because it never got the memo to delete (tombstone) them, and attempts to replicate these objects to its partners. This could pose a security risk if you did not disable the accounts before deleting them. The problem is further exacerbated when a GC comes back online and replicates read-only copies of the objects, which can't be deleted. Microsoft released a fix in Windows 2000 SP3, incorporated in Windows Server 2003, which allows the Administrator to define "loose" or "tight" behavior, and permits the deletion of read-only objects. Loose behavior is the default in Windows 2000 and is the behavior on DCs that are upgraded from Windows 2000 to 2003. Windows 2000 S3 provided the capability to delete the read-only objects perpetuated by an out-of-date GC. as well as the capability to change loose to tight behavior by modifying the following Registry setting: HKLM\System\CurrentControlSet\Services\NTDS\Parameters Add Value Value name: Strict Replication Consistency Data type: Reg_Dword Value Data: (enter 0 or 1) <0 = Loose 1= Tight> In addition, the following setting permits the deletion of lingering objects: HKLM\System\CurrentControlSet\Services\NTDS\Parameters Value Name: Correct Missing Objects Data type: Reg_DWORD Value Data: 1 (enabled) If a DC is configured for strict replication mode and detects a lingering object on a source DC, inbound replication of the partition that hosts the lingering object is blocked from that source DC until the lingering object is deleted from the source DC's local copy of AD. If the DC is configured for loose replication, it will permit replication of inbound lingering objects from its partners. The default behavior for Windows 2000 is loose. The default behavior for Windows Server 2003 is strict. If Windows 2000 is set to loose behavior, it will remain as loose after upgrading to Windows Server 2003. After replication stops, you need to delete these lingering objects and get replication working again. Microsoft KB article 314282, "Lingering objects may remain after you bring an out-of-date global catalog server back online," describes several ways of removing lingering objects, including a vbs script. In addition, the Windows Server 2003 version of the Repadmin.exe tool has a new switch, /removelingeringobjects, also described in the KB article. This option removes lingering objects only from Windows Server 2003 DCs, however. In a domain with both Windows 2000 and Windows Server 2003 DCs, this command removes lingering objects from the 2003 DCs, but not the 2000 DCs. The following example shows how this command works by specifying the GUID of the DCs to have the objects removed, followed by the GUID of the source DC. You can get help on this option with the command Repadmin /experthelp , which reveals additional advanced commands (use with caution). Example: E:\>repadmin /removelingeringobjects ATL-DC01 61c413db- 23fe-414e-9d46-6c881d4eabc4 dc=company,dc=com RemoveLingeringObjects successful on ATL-DC01 tip The Windows Server 2003 version of Repadmin has some exciting new features, such as /replsum , which tracks status of end-to-end replication; /options , which allows disabling of inbound and outbound replication (used in authoritative restore as noted in Chapter 10); and /siteoptions , which determines whether the ISTG is disabled and whether Universal Group Membership Caching is enabled (Windows Server 2003 only). This version of repadmin.exe, in the Windows Server 2003 support tools, can be copied to an XP workstation in a Windows 2000 domain and used for Windows 2000 supported operations. GC ServersGC servers are special-purpose DCs that hold a writeable copy of all objects and attributes for the domain in which it resides as a DC, and a read-only copy of all objects and some of their attributes from other domains in the forest. Thus, GC servers are really only important in multidomain forests and have no special function in single-domain forests. The placement of GC servers in the enterprise is an important design decision. The important tasks that GCs perform include
The placement of GCs in the enterprise has always been a much-debated issue. Some companies put a GC in every site, whereas others put multiple GCs in each site for redundancy. Compaq's strategy was to put GCs in poorly connected sites, in prime sites on the corporate backbone, and as few others as possible. The philosophy was to utilize the network bandwidth as much as possible. If the network bandwidth was sufficient between locations, Compaq would collect them into a single site with a single DC and GC, thus utilizing the network to reduce the need for GCs. For example, the entire country of Canada only had 2 sites, and enterprisewide, only about 80 sites were serving about 800 locations. Exchange 2000 caused GCs to be placed deeper in the structure than originally anticipated, since it is used for Exchange's Global Address List and is accessed frequently by users. The key to GC placement is a good understanding of the GC functions and how they fit in your computing infrastructure. In the early days of Windows 2000, customers complained that the GC authentication required them to place GCs in small, remote sites to ensure authentication capability. Microsoft provided a Registry key (see Microsoft KB 241789, "How to Disable the Requirement that a GC Server Be Available to Validate User Logons") that turned this feature off, but warned that disabling this feature and using universal groups would cause a potential security hole. To mitigate this issue, Microsoft provided the Universal Group Membership Caching feature or Global Catalog Caching feature in Windows Server 2003 (described in Chapter 1). This allows DCs to contact a GC on behalf of a user, obtain the user's universal group membership, and cache it locally so the user can log on if a GC is not available. This is done on a site-by-site basis, allowing you to apply it on poorly connected sites that have a DC, but no GC. This feature makes a big difference in deploying GCs. Now you can enable GC Caching at a site until the population grows enough to justify a GC. Another Windows Server 2003 feature that impacts GC deployment is the Install from Media (IFM) feature. As described in Chapter 1, IFM allows promotion of a member server to a DC or a GC using a restored system state backup of another DC or GC in the domain. IFM not only prevents a surge in network traffic while DCPromo runs, but also significantly reduces the amount of time it takes to build a DC or GC. HP identified IFM as a critical feature that contributed to the company's deployment of Windows Server 2003 at RC2. Consider the problem of GC failure for whatever reason. Broken replication, hardware failures, and so on can cause GCs to have to be rebuilt. With less than one GC per site, a GC failure impacted multiple sites. Further, with Exchange depending on the GC, a failure caused Exchange transactions to be serviced by a GC at another site. Rebuilding a GC of HP's size (the database was 18GB at the time) took about 3 to 5 days, depending on the location, network traffic, and so on. Using IFM, HP can rebuild a GC in about 20 minutes. Even if HP had to build the media and ship it overnight to the remote site, it's faster than doing it over the network. Remember that the backup media for IFM has the same limitation as other backup media; it has a useful shelf life of less than the tombstonelifetime period (default 60 days). Placement of GC servers is a key element in an AD design. (This issue is discussed in detail in Chapter 6, "The Physical Design and Developing the Pilot.") Other Windows Server 2003 Replication ImprovementsWindows Server 2003 made drastic improvements in AD replication. This section describes some significant improvements that have not been noted previously in this chapter. Refer to Chapter 1 for a summary of all Windows Server 2003 improvements and enhancements. Improved Spanning Tree AlgorithmThe spanning tree algorithm, used to calculate intersite topology (least cost path ), was completely rewritten using Kruskal and Dijkstra's algorithms and made much more efficient. As noted previously in the "Practical Limit to Number of Sites" section, this algorithm allowed the KCC to calculate the topology for 3,000 sites and a single domain in about 30 seconds, although the hardware resources affect this value. This is a major step in removing scalability issues that were present in Windows 2000. Even if you don't have an environment with hundreds of sites, this is important because the efficiency of the spanning tree algorithm removes any design limits that might be imposed by Windows Server 2003's scalability, allowing you to design the infrastructure based on business needs rather than Windows limits. Improved Data CompressionAnother improvement is the compression of data for intersite replication. Data compression was a two-edged sword ”it reduced the size of the data to be transferred across the network by approximately a factor of 10, but decompression required a huge hit on the BHS in the target site to the point that DCs became overwhelmed with that and other tasks, such as servicing outbound replication requests from its partners, and the outbound partners didn't get serviced in a timely manner, adding to latency. High latency can also happen if you have a large number of sites replicating to a single BHS at the hub site, a large number of sites causing the KCC to consume inordinate amounts of CPU time, or a high frequency replication schedule. High latency can cause replication to appear broken, and password changes, policy changes, and other Group Policy changes are not replicated in a timely manner. Microsoft improved the decompression engine in Windows Server 2003 to drastically reduce the load on the DC. This was done at the expense of compression ratio, being somewhat less than in Windows 2000, and slightly increasing the WAN traffic. Thus, Windows Server 2003 reduces the load on BHSs significantly, while increasing the WAN traffic only slightly. Because some environments might have low bandwidth utilization in their network and can afford to replicate uncompressed data to eliminate the decompression cost on the target BHS, Windows Server 2003 provides a way to turn off compression of intersite replicated data. This is accomplished by modifying the options attribute on the site link and NTDS-Connections object. This can be done via the ADSIedit snap-in (part of the support tools). Open the snap-in by clicking Start, Run, and then entering adsiedit.msc . Expand the Configuration container, and then go to: CN=Configuration,DC=Company,DC=com (where company.com is the name of the domain ) CN=Sites CN=Inter-Site Transports CN=IP Click on the CN=IP folder, right-click on the site link in the right pane that you want to disable intersite compression over, and select Properties. In the link properties page, scroll through the attributes list to locate the Options attribute. Double-click the Options attribute and in the ensuing Integer Attribute Editor dialog box, enter 4 , as shown in Figure 5.39. Click OK twice to close the properties dialog boxes. This will eliminate intersite compression on all connections using this link. You can optionally configure this feature on individual connection objects by setting the value of 4 on the Options attribute of the individual connection object, as shown in Figure 5.40. Figure 5.39. Disabling intersite compression on IP transport via ADSIEdit.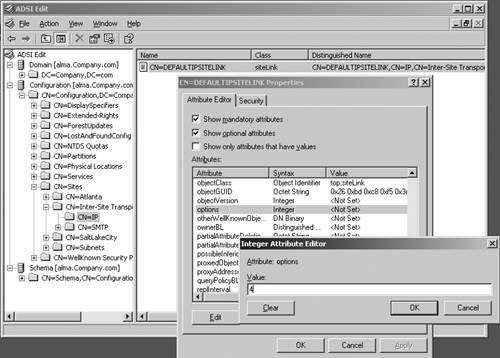 Figure 5.40. Disabling intersite compression on individual connection objects via ADSIEdit.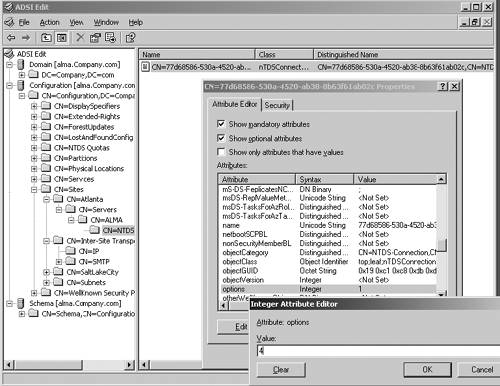 warning Disabling intersite compression is an advanced feature of replication configuration. You should understand the consequences of this action by thoroughly testing it in a lab environment that represents your production network. Disabling compression will cause an increase in traffic since you will have larger amounts of data. You should document this action for troubleshooting purposes. If your network is running close to capacity, there might not be enough margin to support this feature, and might likewise be difficult to diagnose as the cause of pushing the network over the limit. Load Balancing to BHSsIn addition, Windows Server 2003 implements a random BHS selection process. As connections are made to a site, the ISTG randomly selects an eligible DC for the BHS. This takes place as soon as the DC joins the domain, unlike Windows 2000. In addition, Windows Server 2003 implements the capability to balance replication schedules by staggering the replication schedules of downstream partners. Replication schedule staggering is implemented via Windows Server 2003's ADLB, available in the Resource Kit, downloadable from http://www.microsoft.com/windowsserver2003/techinfo/reskit/resourcekit.mspx. Unfortunately, there isn't a lot of documentation on ADLB from Microsoft, and the Resource Kit help file isn't much help either. However, here are a few pointers:
To balance the BHS, run the tool once per hub site. Run it again every time the topology changes. In a large environment, you can balance the connections in stages to soften the impact. In schedule balancing, ADLB changes schedules so that they are balanced over time rather than randomized in normal KCC behavior. Designing an Efficient Replication TopologyThis section examines some best practices concerning the design of the replication topology. One of the things I've noticed in reviewing designs and observing topologies in place from a troubleshooting perspective, is that the topology is often made much more complex than it needs to be. "Behind every simple problem is a complex solution," is certainly a true saying in replication topology design. Let's look at a checklist of some best practices in topology design, and then I'll detail some topologies I've observed that illustrate poor planning or implementation (or both) and how to fix them. Best Practices in Replication Topology DesignThis section is a summary of my experience specifying replication design topology solutions and troubleshooting broken designs, mixed in with recommendations from Microsoft. Keep the Topology as Simple as PossibleSounds logical, but this principle seems to be ignored in the heat of battle, even in simple environments. Consider Figure 5.41, which shows the actual topology snapshot of one of HP's customers, generated by HP OpenView Operations for Windows Active Directory Topology Viewer (ADTV). This tool connects to the domain and generates a 3D image of the replication topology. Although it will display sites, DCs, site links, and connection objects, I did not display connection objects in this figure for the sake of clarity. Without even looking at any logs or problem descriptions, this picture tells the story. The squares are sites, and the lines between the squares are site links. If the intent is to force replication along logical paths in an organized fashion, this is a failure. After identifying the sites that were "hub" sites, and associated sites that replicate to the hubs, we reconfigured the site links to produce the topology shown in Figure 5.42. A simple comparison should show even the novice that replication shown in Figure 5.42 will be more efficient and trouble-free than that in Figure 5.41. Obviously, a tool of this nature makes a big difference in your ability to quick
|
EAN: N/A
Pages: 214