Objections to VoIP over 802.11 (Vo802.11)
|
|
Just like concerns over 802.11 as a whole, five major objections arise in adopting VoIP over 802.11 (Vo802.11): voice quality as it relates to QoS, security, E911 (Emergency 911), Communications Assistance for Law Enforcement Act (CALEA), and range. Many suspect that an adverse tradeoff takes place between the predictability (QoS) of copper wires that deliver voice to residences and the unpredictability of the airwaves as utilized by 802.11. As regards security, some fear their conversations could be susceptible to eavesdropping if their conversation is carried in the open air. Fortunately, the industry now offers solutions to make Vo802.11 as good quality-wise and as secure as the PSTN. Many will raise objections regarding requirements for E911 and CALEA for carriers. Solutions for range issues related to 802.11 are contained in Chapter 3, "Range Is Not an Issue," and will not be covered here as no voice-specific solutions have been made regarding the range of 802.11. The following pages explain solutions for these objections to Vo802.11. No problems exist regarding Vo802.11, only solutions.
Objection 1: Voice Quality of Vo802.11
Despite the fact that telephone companies are losing thousands of lines per month in the United States to cell phone service providers, many perceive that voice over a cell phone connection would deliver inferior voice quality and, as a result, is not a viable alternative to the copper wires of the PSTN. As explored in the previous chapter, a number of new measures (primarily 802.11e) improve QoS on 802.11.
But what about voice? As wired service providers and network administrators have found, voice is the hardest service to provision on an IP network. New developments in the Vo802.11 industry point to some exciting developments that overcome the chief objection to Vo802.11. First, it is necessary to determine which metrics to use in comparing Vo802.11 to the voice quality of the PSTN.
Measuring Voice Quality in Vo802.11 How does one measure the difference in voice quality between a Vo802.11 and the PSTN? As the VoIP industry matures, new means of measuring voice quality are arriving on the market. Currently, two tests award some semblance of a score for voice quality. The first is a holdover from the circuit-switched voice industry known as Mean Opinion Score (MOS). The other has emerged with the rise in popularity of VoIP and is known as Perceptual Speech Quality Measurement (PSQM).
Mean Opinion Score (MOS) Can voice quality as a function of QoS be measured scientifically? The telephone industry employs a subjective rating system known as the MOS to measure the quality of the telephone connections. The measurement techniques are defined in ITU-T P.800 and are based on the opinions of many testing volunteers who listen to a sample of voice traffic and rate the quality of that transmission. The volunteers listen to a variety of voice samples and are asked to consider factors such as loss, circuit noise, side tone, talker echo, distortion, delay, and other transmission problems. The volunteers then rate the voice samples from 1 to 5, with 5 being excellent and 1 being bad. The voice samples are then awarded an MOS. An MOS of 4 is considered toll quality.
It should be stated here that the voice quality of VoIP applications can be engineered to be as good or better than the PSTN. Recent research performed by the Institute for Telecommunications Sciences in Boulder, Colorado, compared the voice quality of traffic routed through VoIP gateways with the PSTN. Researchers were fed a variety of voice samples and were asked to determine if the sample originated with the PSTN or from the VoIP gateway traffic. The result of the test was that the voice quality of the VoIP-gateway-routed traffic was "indistinguishable from the PSTN."[6] It should be noted that the IP network used in this test was a closed network and not the public Internet or another long-distance IP network. This report indicates that quality media gateways can deliver voice quality on the same level as the PSTN. The challenge then shifts to ensuring the IP network can deliver similar QoS to ensure good voice quality. This chapter explains how measures can be taken to engineer voice-specific solutions into a wireless network to ensure voice quality equal to the PSTN.
Perceptual Speech Quality Measurement (PSQM) Another means of testing voice quality is known as PSQM. It is based on ITU-T Recommendation P.861, which specifies a model for mapping actual audio signals to their representations inside the head of a human. Voice quality consists of a mix of objective and subjective parts, and it varies widely among the different coding schemes and the types of network topologies used for transport. In PSQM, a measurement of processed signals (compressed, encoded, and so on) derived from a speech sample are collected, and an objective analysis is performed, comparing the original and the processed version of the speech sample. From that, an opinion is rendered as to the quality of the signal-processing functions that processed the original signal. Unlike MOS scores, PSQM scores result in an absolute number, not a relative comparison between the two signals.[7] The value in this is that vendors can state the PSQM score for a given platform (as assigned by an impartial testing agency). Service providers can then make at least part of their buying decision based on the PSQM score of the platform (see Figure 6-6).
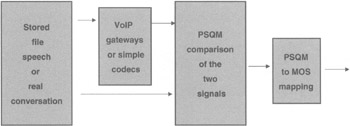
Figure 6-6: Process of PSQM
Detractors to Voice Quality in 802.11 What specifically detracts from good voice quality in an 802.11 environment? Latency, jitter, packet loss, and echo all affect voice quality on an 802.11 network. With proper engineering, the impact of these factors on voice quality can be minimized, and voice quality equal to or better than that of the PSTN can be achieved on 802.11 networks.
Latency (Also Known as Delay) Voice as a wireless IP application presents unique challenges for 802.11 networks. Primary among these is acceptable audio quality resulting from minimized network delay in a mixed voice and data environment. Ethernet, wired or wireless, is not designed for real-time streaming media or guaranteed packet delivery. Congestion on the wireless network, without traffic differentiation, can quickly render voice unusable. QoS measures must be taken to ensure voice packet delays stay under 100 milliseconds.
Voice signal processing at the sending and receiving ends that includes the time required to encode or decode the voice signal from analog or digital form into the voice-coding scheme selected for the call and vice versa adds to the delay. Compressing the voice signal also increases the delay. The greater the compression, the greater the delay. Where bandwidth costs are not a concern, a service provider can utilize G.711, which is uncompressed voice (64 Kbps) and imposes a minimum of delay due to the lack of compression.
On the transmit side, packetization delay is another factor that must be entered into the calculations. The packetization delay is the time it takes to fill a packet with data. The larger the packet size, the more time is required. Using shorter packet sizes can shorten this delay but will increase the overhead because more packets have to be sent, all containing similar information in the header. Balancing voice quality, packetization delay, and bandwidth utilization efficiency is very important to the service provider.[8]
How much delay is too much? Of all the factors discussed in Chapter 4, "Security and 802.11," that degrade VoIP, latency (delay) is the greatest. Recent testing by Mier Labs offers a metric for VoIP voice quality. That measure is to determine how much latency is acceptable comparable to the voice quality offered by the PSTN. Latency less than 100 milliseconds (ms) does not affect toll-quality voice. However, latency over 120 ms is discernable to most callers, and at 150 ms the voice quality is noticeably impaired, resulting in less than toll-quality communication. The challenge for VoIP service providers and their vendors is to get the latency of any conversation on their network to not exceed 100 ms.[9] Humans are intolerant of speech delays of more than about 200 ms. As mentioned earlier, ITU-T G.114 specifies that delay is not to exceed 150 ms one-way or 300 ms round trip. The dilemma is that although elastic applications (e-mail, for example) can tolerate a fair amount of delay, they usually try to consume every bit of network capacity they can. In contrast, voice applications need only small amounts of the network, but that amount has to be available immediately.[10]
The delay experienced in a call occurs on the transmitting side, on the network, and on the receiving side. Most of the delay on the transmitting side is due to codec delay (packetization and look-ahead) and processing delay. On the network, most of the delay stems from transmission time (serialization and propagation) and router queuing time. Finally, the jitter buffer depth, processing, and, in some implementations, the polling intervals add to the delay on the receiving side.
The delay introduced by the speech coder can be divided into algorithmic and processing delays. The algorithmic delay occurs due to framing for block processing, since the encoder produces a set of bits representing a block of speech samples. Furthermore, many coders using block processing also have a look-ahead function that requires a buffering of future speech samples before a block is encoded. This adds to the algorithmic delay. Processing delay is the amount of time it takes to encode and decode a block of speech samples.
Dropped Packets In IP networks, a percentage of the packets can be lost or delayed, especially in periods of congestion. Also, some packets are discarded due to errors that occurred during transmission. Lost, delayed, and damaged packets result in a substantial deterioration of voice quality. In conventional error-correction techniques used in other protocols, incoming blocks of data containing errors are discarded, and the receiving computer requests the retransmission of the packet. Thus, the message that is finally delivered to the user is exactly the same as the message that originated. As VoIP (and tangentially Vo802.11) systems are time sensitive and cannot wait for retransmission, more sophisticated error-detection and correction systems are used to create sound to fill in the gaps. This process stores a portion of the incoming speaker's voice and then, using a complex algorithm to approximate the contents of the missing packets, new sound information is created to enhance the communication. Thus, the sound heard by the receiver is not exactly the sound transmitted, but rather portions of it have been created by the system to enhance the delivered sound.[11]
Most of the packet losses occur in the routers, either due to a high router load or a high link load. In both situations, packets in the queues might be dropped. Another source of packet loss is errors in the transmission links, resulting in cyclic redundancy check (CRC) errors for the packet. Configuration errors and collisions might also result in packet losses. In non-real-time applications, packet losses are solved at the protocol layer by retransmission (TCP). For telephony, this is not a viable solution since retransmitted packets would arrive too late and be of no use.
Perhaps the chief challenge to Vo802.11 is that, relative to wired networks, packets are dropped at an excessive rate (upwards of 30 percent). This can lead to distortion of the voice to the extent that the conversation is unintelligible. In VoIP gateways designed for wired networks, one solution is to use a jitter buffer with a "bit bucket." The solution in the wired VoIP industry had been to simply eliminate (drop) voice packets that arrive late and out of order. This is acceptable if the percentage of late and out-of-order packets is fairly small (say, less than 10 percent). When the packet loss grows due to the many vagaries of wireless transmissions, the voice quality falls off precipitously.
Jitter Jitter occurs because packets have varying transmission times. It is caused by different queuing times in the routers and possible different routing paths. The jitter results in unequal time spacing between the arriving packets, and it requires a jitter buffer to ensure a smooth, continuous playback of the voice stream.
The chief correction for jitter is to include an adaptive jitter buffer. The jitter buffer described in the solution earlier is a fixed jitter buffer. The improvement is an adaptive jitter buffer that can dynamically adjust to accommodate for high levels of delay encountered in wireless networks.
A Word About Bit Rate (or Compression Rate) The bit rate is the number of bits per second delivered by the speech encoder and therefore determines the bandwidth load on the network. It is important to note that the packet headers (IP, UDP, and RTP) also add to the bandwidth. Speech quality generally increases with the bit rate. Very simply put, the greater the bandwidth, the greater the speech quality.
[6]Andrew Craig, "Qualms of Quality Dog Growth of IP Telephony," Network News (November 11, 1999): 3.
[7]Douskalis, 242-243.
[8]Douskalis, 230-231.
[9]Mier Communications, "Lab Report-QoS Solutions," www.sitaranetworks.com/solutions/pdfs/mier_report.pdf February 2001.
[10]John McCullough and Daniel Walker, "Interested in VoIP? How to Proceed," Business Communications Review (April 1999): 16-22.
[11]Report to Congress on Universal Service, CC Docket No. 96-45, a white paper on IP voice services, March 18, 1998.
|
|
EAN: 2147483647
Pages: 96