Interface Model
|
|
The interface model defines the structure and process of the interaction with your Web services. In this sense, you can think of a Web service as an object. Just as an object's interface may have multiple method calls, a Web service may have multiple calls to consume its functionality. However, because of its open nature, a Web service is abstracted even more than an object is to its caller. Web services consumers may have no idea how many applications are handling their requests and certainly have no idea what platform or tools they were constructed with.
For an object, defining an interface can be a daunting task if you don't have a lot of experience in determining appropriate class structures and datatypes. The abstraction of Web services allow for even more options in designing an interface, which makes the task no less daunting. The level of complexity depends primarily on the functionality and support services you want to provide. You have already seen how providing assistance with the initial presentation to an end user can turn a simple Web services request into a two-step process. That is really just the tip of the iceberg with Web services interfaces.
Because of the complexity, think of your Web services interface as a model, something that cannot effectively be defined through an existing Interface Definition Language (IDL). This model should address two specific areas of the Web services interface: process and payload. Together, these two components will help you to define the workings of your Web services and allow you to expose them to consumers. You will know the interface model for your Web service is complete when the behavior and functionality of your interface are captured in process diagrams and payload definitions.
-
IDL stands for Interface Definition Language. Every object or component protocol has some mechanism for discovering the interface of external entities with which it can communicate. These mechanisms are generally defined through data commonly referred as an IDL. WSDL is the Web Services Definition Language. It is an existing standard IDL for specifically defining Web services. We will look more closely at WSDL in Chapter 9.
Processes
A Web service can take many shapes. It can expose a very simple process, such as querying a database of information, or it can expose a complex sequence of steps, such as purchasing a car. These are very different functions, but they can both be exposed via Web services. This requires us to have some serious flexibility in how we can design our service's interface, and it also takes some careful thought into how we are going to pull it off, while not scaring off potential consumers!
The interface model's process can take one of two options. It can be a single call (request and response), or it can be a workflow. Obviously, the single call is easier to implement under any condition. It might seem at first that every step through a workflow could just be addressed as a single request and response, but, if you try to design a Web services workflow with that approach, you will quickly realize that you cannot treat the steps as independent islands.
The first issue you will encounter is a need on your part to control the entire process. The obvious example comes up in a transactional process. The classical scenario is the debit/credit process in which one event cannot happen without the successful completion of the other. This is a matter of functional usability that cannot be compromised.
The other issue you will probably encounter is implementation complexity. If a service provider exposes a series of ten independent calls that should be consumed in sequence to make up a process, how much trouble do you think consumers will have during implementation? This not only will frustrate consumers, but also can be harmful to the service provider and its systems. This starts to tread into the security model topic (which is coming up shortly), but you basically want to ensure that a consumer is utilizing every step of your process without bypassing steps or inserting its own steps. (See Figure 5-14.) Such an attempt compromises what control you do have over the process.
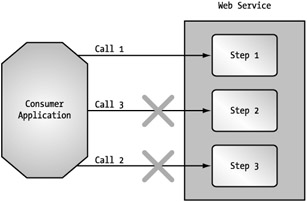
Figure 5-14: Compromising a Web service process
In these cases, you want to expose your Web service as a process, not as individual steps. Doing this requires some careful design work and some additional management on the service provider's part, but it will likely be a great service for you once it is available. It will not only be more efficient to implement, but it should allow for a better experience for any consumer.
Web Services Call
A Web services call is not much different from any other application call. You make a request and get a response. We discussed this communication process quite a bit in Chapter 2. Initially, most Web services will likely follow this model. It is fairly simple to implement and requires little complexity on the consumer's part.
However, because of the nature of Web services, you have quite a bit of flexibility in exposing your service. This requires you to think about the tasks you are trying to accomplish. In Chapter 1, I introduced the idea of heavy and light requests and responses. It is in this section of the interface model where these should be defined.
If you are using an IDL (such as WSDL) to define your interface, this model is already defined for the consumer's technical developers. They will get all the information they need from it. However, on a business level, at least internally, this needs to be determined as part of the business requirements for the Web service. The danger here is trying to do too much in one call. The nature of Web services is to expose functionality, not transfer documents. If you find you are implementing a Web service that is receiving data from a partner and sending back unrelated data in the response, you are not providing a Web service! You are merely taking a batch process and using a different transport mechanism.
I'm not saying this is bad, because it may be a good solution for the need you have. It would just be inappropriate to consider this a Web service just because it transports XML over HTTP. In fact, you might want to consider using a package for data routing and transformations so you don't end up writing custom routines every time you want to transfer some more data.
A Web service's request and response payloads are always going to be related. A consumer is making a request of your service, and you are fulfilling it. That request may be a simple identification of the caller, or it may be a collection of data that needs processing. That fulfillment may be a simple acknowledgment, or it may be a result set of data. Either way, you need to make that determination for your Web services calls before you get caught up in defining the payload itself.
This relationship can be somewhat frustrating, but that is the nature of working with communication protocols over the Web. As long as the consumer wants only one thing, this can be very easy.
Eventually, though, you will want to break out of these single transactions to accomplish something much more robust. This requires a series of interactions that you expose and manage.
Web Services Workflow
I like to refer to a process exposed through a Web service as a workflow. Whereas process might be misconstrued as just the communication or logic process, workflow gives a clear image of what you are trying to accomplish through your service and the nature of it. There is a starting point, there are decision points, and there is a conclusion. There is a sequence involved, and it takes multiple calls to complete the entire process. Many Web applications accomplish this today, but they are in control of the entire experience. Web services offer new challenges to these complex applications because they share the process. The consumer still owns the presentation, but the service actually owns the process itself. These will be some of the most complex Web services that are provided.
The first step to designing a successful workflow model for your Web service is to map out the entire process that is involved. Just like with any business application, mapping out the processes is key to meeting the necessary requirements. A flow diagram is a good method for visually capturing the process. (See Figure 5-15.)
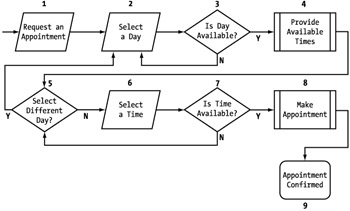
Figure 5-15: A process flow diagram
Once the workflow is defined, exposing it through a Web service is the next step. Let's look at this in more detail by considering an appointment service scenario. This Web service could be applicable to any service industry such as a barber, doctor, or auto mechanic. The use of this kind of functionality is evident when you consider situations in which portal sites or applications want to combine or at least support appointments across multiple vendors of services. Health insurance sites may allow appointments to be made with network doctors; auto manufacturers might facilitate appointments with service departments; and entertainment sites may allow reservations at restaurants, movies, or plays.
Figure 5-15 represents the process flow for an appointment process. We will step through the flow to make sure that what we are trying to accomplish is clear. Keep in mind that this is a generic process that could handle reservations or appointments.
The process is initiated by a request for an appointment (1). The first step to this is selecting the day for the appointment (2). We will run an initial check to make sure the day is valid, because we may not have appointments available on holidays, Sundays, and so on (3). If the day is acceptable, we then look up a list of times that are available and present them (4). The alternative is having the users provide times, hoping they are available. By proactively providing a list, we can reduce the amount of back-and-forth interaction that method could generate.
Based on the list of times, the user either selects one or decides to look at a different day (5). If the user selects a time (6), we run one more confirmation of the time's availability (7). If it is available, we book the opening (8) and send some sort of confirmation (9). If, during the process, another user reserves a time that was presented as available to the user, the user can select a different day (5) or a different time (6).
There are certainly other ways this process could be managed, but I have defined a relatively simple process so that we can easily work through it. Now that it's defined, we have to add the details that are necessary to make it a Web service. This starts with the introduction of the service provider and service consumer. It is always easiest to work with a Web service process in terms of two tiers: the consumer application and the Web service. This allows you to clearly determine which responsibility falls where. With the players identified, we can then identify the interactions necessary over the Internet to make the process functional. Let's step through a direct conversion of this process as a Web service. (See Figure 5-16.)
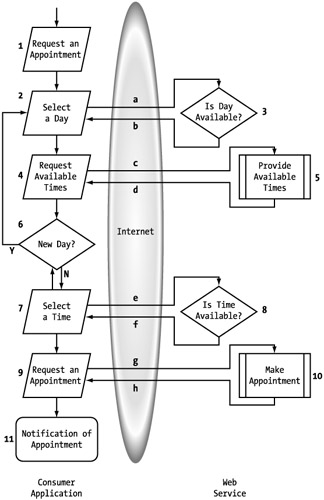
Figure 5-16: Appointment process flow as a Web service
Remember that the process must always begin and end on the consumer side. In this case, the first two steps, starting the process (1) and selecting the day (2), occur on the consumer side. There comes the first call to the service (a) to find out whether the day is available (3). If the response (b) is false, the consumer passes another request with a different day. Once an acceptable day is found, the consumer requests a list of available times for that day (4, c). The service puts the data together (5) and responds to the consumer (d).
At this point, the consumer can determine whether any of the available times are acceptable and either selects a different day (6) or sends the request (e) for one of the times (7). Because another user might have made an appointment between this client's requests, the service provider confirms the availability and reserves the time slot (8). The consumer then decides to actually book the appointment (9) with the Web service (10). The consumer then makes the appropriate notifications of the successful booking (11). The process is then complete.
This diagram (Figure 5-16) is a good visualization of what we are providing through the Web service and what we are expecting of the consumer. It shows, for instance, that we are asking the consumer to provide the mechanism for collecting the initial day of the appointment. This is not a big task, but it does require something of the consumer. At some point, you might decide that you want to provide that functionality as an extension of the main service. (See Figure 5-17.) I would call this a value-added service since it is not crucial to the process, even less so than providing a list of available times is. Available times are based on information that is proprietary to us, making the process more efficient. The consumer could easily provide a functional calendar system to provide days to choose from.
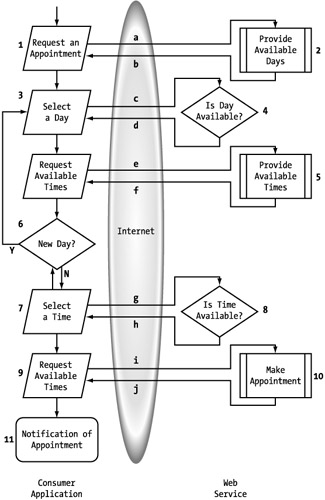
Figure 5-17: Extending the appointment Web service
When considering extensions of this nature, you need to be wary of falling into the trap of focusing more on enhancing the services than on the functional service itself. This is similar to buying a smaller house to fit in your budget and meet your needs, and then going crazy with options like marble counters, crystal chandeliers, and extravagant landscaping. Don't lose sight of the actual goal; focus on your Web service, and add only those extensions that will truly add value for the consumer.
What Figure 5-17 doesn't tell us is how to manage the process. How do we, as the provider, know whether the consumer is requesting the first step of the process or the last? The additional complexity of a Web services workflow comes from the exposure of the process to both the consuming application and, potentially, an end user. You essentially have two users, not one. A typical Web application design is intended to handle multiple users in independent sessions. With an embedded Web service, you will have two concurrent users that you are accommodating in each session. The application is actually consuming the Web service, but the end user is consuming the process. This places more demands on a Web service in managing the session. This, of course, brings us to state management.
Managing State for Two
A significant technical issue that must be addressed with Web services workflows is the state management. Most Web applications have to deal with this issue today, but Web services that support a workflow add some complexity to state management because they may have to manage two different states: the consumer of the service and the user of the consumer's application. The Web service has to know at what stage during the process a user is and also has to keep track of the consumer so it can enforce security and accommodate any tracking needs. This is especially imperative with fee-based services (which are discussed later).
Because the Web services provider does not establish a physical session with the user, you might think that all we have to do is manage the state with the consumer of our application. This kind of thinking will likely lull you into a trap, because a consumer may have multiple independent sessions occurring simultaneously. This means that you could easily get individual session references mixed up, which essentially breaks all processes in the application.
For this same reason, a consumer cannot implement a workflow Web service and make requests for users anonymously. This doesn't mean that consumers must pass on the user's identity. The provider just needs to be aware of existing users during their processes. Without this mechanism, you could not implement workflow applications consuming Web services.
State is managed in traditional Web applications through cookies, form fields, and query strings. These are all methods for communicating information between an end user and a Web application. State can be managed between the user and the consumer's application, and it can be managed between the consumer and our service. (See Figure 5-18.) Because the service cannot manage state for the end user, the consumer application is going to have to marshal this data for us. Before we get into how this can be done, let's review the methods for managing state between the user and the consumer application.
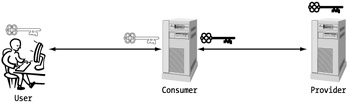
Figure 5-18: State management in a Web service application
When an application receives a request from an end user, information is passed to it in the HTTP header and the requested URL through cookies, HTTP post data, and query strings. Cookies are segments of text data that the server asks the browser to remember for it. Cookies can either be saved to a secluded place on the hard drive (designated by the browser) or just retained in the browser's memory. I will refer to these as persistent and session cookies, respectively. Obviously, a session cookie lasts only as long as the browser session is open because it is kept only in memory. Both of these cookies are passed to the server through the HTTP header every time the browser makes a request. Cookies are passed only to the site that actually generated them. (This is based on the domain name, so a Web farm of multiple servers can effectively use cookies to manage state between them as well.)
HTTP post data is data that is defined through an HTML form through a post action. This allows HTML to identify and capture data that a user has entered and send it to the server. Most fields are exposed to the user, but sometimes hidden fields are used for passing application data to the browser so the server can recognize it when it is submitted back.
Querystrings are bits of text information that are concatenated onto the end of a URL. This information can be either programmatically provided or automated through HTML forms using the GET action. Multiple pieces of information can be sent through the querystring by delimiting them with an ampersand (&). This is what a properly implemented querystring looks like:
http://www.architectingwebservices.com/wservice/purchasecar.htm?id=12345& type=fourdoor&color=blue
This is a very popular way to manage state because it is fairly efficient and easy to implement, but it does have its drawbacks. Because it is part of the address, you are exposing information to the user that would allow the user to very easily break out of the application's expectations. An educated user can certainly work around cookie or HTTP post state management, but it takes more effort. At the very least, refrain from putting any sensitive data in the querystring, because it is much easier for someone to get to there.
According to our design, we need to maintain a consumer ID and a user ID. To keep track of the process itself, we also need to maintain a state variable.
| Tip | We could save the state variable on our side, tied to the user ID, but this makes the application a little more vulnerable to state issues. With the stateless nature of the Web, just because we sent the consumer step 3 doesn't mean it arrived. The consumer might instead be resending step 2. Their view of the user's current state is almost always more accurate than ours (and it's likely the only one that matters), so maintaining state within the process is preferable. |
I will create an element called serviceVariables and place this information in child elements there. That communicates to the consumer what the information is for and perhaps assists the development staff in knowing how to handle it. The following code illustrates this:
<serviceVariables> <consumerID>987</consumerID> <userID>10203</userID> <stage>2</stage> </serviceVariables>
Now that we have this in place, what will the consumer do with it? After all, serviceVariables is not a tag standardized to mean anything, right? Although this is true, it also inherently communicates a certain level of purpose that developers might understand without any additional documentation. This is part of the beauty behind XML. The very data itself is capable of communicating information about itself. However, supporting documentation is always helpful to your consumers.
Once the data's purpose is understood, the consumer has two responsibilities. The first is to act as a proxy and simply pass the data on through one of the state mechanisms available to the consumer and their users. This choice is completely outside of our control as the service provider, but, as long as it is done, we really shouldn't concern ourselves with it. Ideally, the consumer should be able to piggyback whatever state mechanisms it uses for the application itself. That requires the least amount of effort to implement. The other thing the consumer should know not to do is actually expose the data to the user. This node should actually act as an envelope for communications between the consumer and Web services provider.
| Caution | It is important that the consumer respect the values you are passing for state management. Consumers may assume that they can insert their own representation of the user ID for the Web service's user ID. As a provider, you want to make sure that you protect yourself from this threat. We will discuss some of these options in the security model. |
We actually have a little more flexibility with the state management of the consumer of our Web services. Because a direct connection is established between us, we can certainly take advantage of other existing mechanisms such as public keys and certificates. This would remove that responsibility from the interface model and potentially from the application layer altogether. We will discuss these options much more in the security model section later in this chapter.
Another aspect of session management is session length. How long should sessions persist? A typical Web application persists a session over a 20-to 30- minute period of inactivity. Because a Web service can only establish a physical session with the consumer, we have a little more flexibility with this area as the service provider. A Web service can possibly support a shorter period of inactivity. How long will you allow between requests in a process? At some point you have to treat a delay between steps in a process as independent calls. In that case, you might want to start the process over, because continuing with a stale state may cause problems. An indefinite session period can also limit the scalability of the Web service, because sessions will consume the provider's resources while it is active.
To manage our sessions, we need to develop a method for the consumer to pass session data to the provider efficiently. Fortunately, the first step of extracting the data is not difficult, because Web servers typically have an API for accessing this information through objects or components. The trick is in automating as much as possible so the consumer can implement your service as quickly as possible, because, if it takes too long, you are likely to scare the consumer off. At some point, a vendor or two will probably provide this functionality as part of another service or application. In the meantime, we are going to have to provide our own mechanisms if we are going to keep this from being a barrier to implementing our Web services.
The first thing we can do to help is isolate state information from the rest of the application data in the payload of our service. This way, the consumer can recognize the distinction more easily than if it is all grouped together. This may seem like a simple concept, but it is easy to overlook.
Although you don't want to treat a process as an independent Web service, you still should break the process into independent transactions on your side. The key to defining the process workflow is to link these transactions together via the Web services interface. The challenge to implementing the process successfully is the cooperation necessary with the consumer. The consumer initiates every Web services request, so the service can do nothing to force a request. We can work only through the responses to the requests made by the consumer. That is our only opportunity to communicate the necessary information. If we try to tell the consumer how to perform a complicated operation, it will require many requests back and forth! Fortunately, our processes won't be that complicated, but it will sometimes take several steps to accomplish a result. We must get feedback from the client, but, every time we communicate, we are risking a misstep by the consumer or, even worse, a premature end of the process. Although these things are unavoidable, we can develop an interface model that can help the consumer to maintain the process. The key is to provide some sort of mechanism for getting the consumer to make another request for the next step of the process.
Providing Efficient Responses
Our appointment Web service process flow diagram (Figure 5-16) is a great visual aid for what our service is doing and what it provides. As is, it is certainly functional, but it is by no means optimized or efficient. In fact, our diagram also gives us a tangible view of our service, allowing us to identify inefficiencies in it. For example, you might notice right away in our diagram that we show the number of interactions across the Internet. Is there any way to streamline that number? The more interactions our service has, the more involved it is for a consumer to implement and the more potential failure points we have.
Recall that you always have one-way communication occurring because of the nature of Internet protocols. The service cannot initiate communication with the client. One solution to this problem is simply telling the consumer what the next step is through your responses. This can be communicated much the same way as state information is communicated through the header nodes. The consumer can then use this information to request the next step of the process. (See Figure 5-19.)
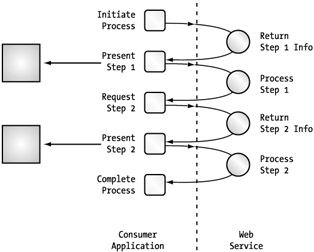
Figure 5-19: A two-step Web service workflow with individual requests
The problem with this approach is the built-in inefficiencies. You see here that it took four requests to execute a two-step process in which some presentation assistance was provided. We had one call that requested the necessary information for step 1, one call for submitting that information, one call for requesting step 2 information, and finally one more for submitting step 2 information. It works, but doubling the step load in requests leads to a very involved application.
An alternative to this model is doubling up on the information provided through the responses. (See Figure 5-20.) Earlier, we were telling the consumer to request step 2 after completing step 1. Instead, we can include the information for step 2 through the response to step 1. After all, our side of the workflow is complete once the data from step 1 has been submitted. Obviously, this can be done only when you have a defined workflow and know the next step that should be taken.
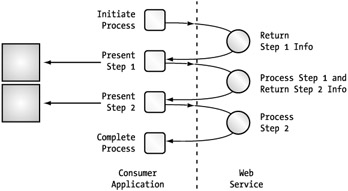
Figure 5-20: A two-step Web service workflow with double-duty responses
This solution gets our two-step process down to three requests, which eliminates 25 percent of the communication. Each additional step also adds only a single request when you continue this approach.
If we apply this approach to our appointment Web service, we can stream-line the amount of interaction between the consumer and service provider. In our original interface model, we had a minimum of four requests and responses necessary to consume the service. By being predictive, we can actually make some assumptions and cut this number in half.
The first thing we modify is providing the list of available times when a given day is submitted. Doing this eliminates one of the requests by the client. The other steps we can combine are the time selection and the appointment booking. If clients submit a successful time, we can skip the reservation of the time and simply make the meeting. This is an even easier justification if our Web service allows us to cancel meetings. You can see what our new process diagram looks like in Figure 5-21.
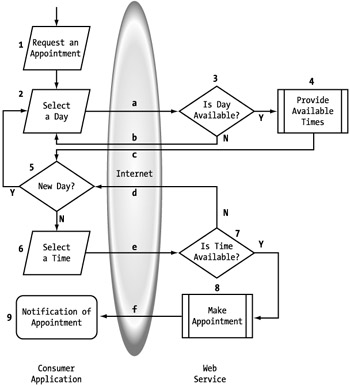
Figure 5-21: Optimized appointment process flow Web service
Let's quickly step through the process. As before, we start the first two steps on the consumer's side (1, 2) and request the availability of the selected day. If the requested day is available, the provider puts together a list of open times (4). If not, we return the process to step 2 on the consumer side. Each of these events has its own response (b and c, respectively). The next step is the consumer determining whether these times are acceptable or if a different day is preferred (5). If a different day is needed, the consumer returns to step 2; otherwise, the consumer selects a time (6). Then comes the second request (e) specifying the time for the appointment. The provider checks to make sure the time is still available (7) and either rejects the request (d) or makes the appointment (8). In the latter case, a response is provided to notify the consumer of the successful appointment booking (9). We have now completed the process.
As you might have noticed, we have eliminated two requests by the client. Instead of
-
Request day availability
-
Request available times
-
Request time availability
-
Make appointment
as we had originally, we simply have this:
-
Request day availability (a)
-
Request time availability (e)
However, also notice that we still have four responses (b, c, d, and f). What we have done is combined the variable responses to work in a two-request interface for the consumer's sake. Two different responses are available for each of the two requests, depending on what the circumstances and outcome are. These two responses are radically different in nature and content. Typically, when we work with interfaces, we are dealing with a determined payload that is consistently defined. Traditional applications achieve this effect by overloading the payload with responses to each situation, and only use the bits necessary at that particular moment.
With XML, you want to make your payloads as efficient as possible. Because of the open nature of Web services, you don't need to take the same approach as in the past. Instead, you can provide different responses based on need to any request you receive from a consumer. In fact, you can also take the opposite approach by supporting different payloads in the Web services request. The concept of dynamic interfaces leads us right into our next topic: payloads.
Payloads
We can't talk about interfaces without discussing payloads. Payloads are even more important to Web services since they contain the entire set of information for your application. There is no method invoked in our application by a payload that contains only parameter data. We also are not passing objects that have properties defined. Our payload is our request, our parameters, and our properties.
Fortunately, our payload is in XML, so we have the ultimate in flexibility. We do need some kind of structure and discipline, though, or we will make our services overly complicated and confusing. So, along with our Web services process, we need to define our payloads, whether they are simple or complex. Payloads are the second component type of the interface model for Web services.
The main distinction we really need to make in our payloads is whether they are static or dynamic. By that, I mean is the payload the same for the Web services call (static), or can it, and should it, change depending on the situation (dynamic)? This is akin to deciding how to handle versioning of a function. Should enhancements in the future be done through a new interface or adding parameters now to accommodate future functionality? There are tradeoffs either way, so we need to look at both carefully.
Static Payloads
Static payloads are easy to define and easy to implement. You do not anticipate changing anything about such a payload in the future: it is what it is, and anything else is a different Web service. You define a schema that defines exactly what format the request should be in and what format the response will be in. These calls are in no way conditional.
| Note | When I talk about static and dynamic payloads, I am referring to the XML elements, not the data in them. Obviously, the data can and will be different between different calls in different sessions. |
Let's take our original appointment process model and look at some of the payloads. They are static because there was one response option for each request.
Three questions have to be answered before defining our static payload:
-
What application data needs to be communicated?
-
What session data needs to be maintained?
-
What presentation data needs to be included?
Application Data
The application data is probably the easiest to define because it is so straightforward. Before you get to this point, you should have your process diagram completed, and it should answer most of this question for you.
In our case, we have four interactions. The day availability request passes the provider a date, and the response is some form of Boolean. The available times request also passes the date to the service and receives a list of available times. The time selection request passes either a time or some providesr-defined ID representing a time slot and gets a Boolean for that response. The final request for making the appointment includes the date and time for the appointment and the response, a comfirmation of booking.
Let's go ahead and look at the schemas for our first request, the day availablitly process. If you refer to Figure 5-18, the request is (a) and the response (b).
This is the schema for the day availability request payload:
<xsd:schema xmlns:xsd="http://www.w3.org/2000/10/XMLSchema"> <xsd:element name="appointmentMaker"> <xsd:complexType> <xsd:sequence> <xsd:element name="date" type="xsd:date"/> </xsd:sequence> </xsd:complexType> </xsd:element> </xsd:schema>
This is the schema for the day availability response payload:
<xsd:schema xmlns:xsd="http://www.w3.org/2000/10/XMLSchema"> <xsd:element name="appointmentMaker"> <xsd:complexType> <xsd:sequence> <xsd:element name="dateAvailabilityStatus"type="xsd:boolean"/> </xsd:sequence> </xsd:complexType> </xsd:element> </xsd:schema>
| Tip | If you are not comfortable reading schemas yet, I recommend getting one of the available XML tools, like XMLSpy, that allows you to load schemas and build compliant XML documents. This allows you to see an actual XML document instance defined by the schema, which may help you to read XML schemas and thus follow these examples. |
Session Data
In determining session data, we first need to ask whether this is part of a process. It is, and so we need some method for determining what stage we are at in the process. Also, because we will be booking something for the user, we need to have some identification for the user. The provider and consumer can handle this in a couple of different ways.
One option is for the provider to assign an ID to the first step of the work-flow in the session data. This is effective for state management and is really ideal for the service provider. A consumer may be annoyed at having to pass the data through, but it really should not be a problem. The main drawback for consumers is that they cannot count on it for any use of their own. Because the provider might be using it as just the session ID or part of a long-term ID model, consumers will not know how to utilize it for their own functionality.
A second approach is for consumers to pass an ID to the Web service and count on them to do so consistently. This is a bit riskier because you have to trust the consumers' systems and policies a bit more. It is one thing to ask consumers to pass along state through a process and another to expect them to design and maintain it correctly.
What we will see going forward is a combination of both approaches. The service provider has its own state management, and consumers their own. Obviously, consumers have to support the provider's information through their side of the process, but, for most applications, the consumers need not pass their information to the provider. Because they initiate the connection, they can maintain that state on their own side. Their application makes a request and waits for a response. The exception to this is an asynchronous process in which the response may actually be delivered later through a provider-initiated process.
Both of these approaches are limited in their capabilities as standalone implementations. They are good for guaranteeing a unique user in a session, but this has no long-term benefit because appointments booked by system-assigned numbers are probably not very helpful! At some point, some specific piece of identification is necessary to tie events to an end user beyond the current session.
For our appointment service, we should assign a user ID to allow us to track usage and manage the active session. We will also utilize a consumer session so we can track the consumer's activity as well. For now, let's assume we are not using this for authentication or security purposes. We will get into that topic in the security model section later in this chapter. Let's go ahead and separate this information into a separate section as discussed in the Processes section of our interface model. Here is an example of session data schema code:
<xsd:schema xmlns:xsd="http://www.w3.org/2000/10/XMLSchema"> <xsd:element name="serviceVariables"> <xsd:complexType> <xsd:all> <xsd:element name="consumerID" type="xsd:short"/> <xsd:element name="stage" type="xsd:short"/> <xsd:element name="userID" type="xsd:short"/> </xsd:all> </xsd:complexType> </xsd:element> </xsd:schema>
Session data is included in a header section for every request and response, so you then modify the payload schemas to include this definition, as shown in this code for a day availability request with session data:
<xsd:schema xmlns:xsd="http://www.w3.org/2000/10/XMLSchema"> <xsd:import schemaLocation= "http://www.architectingwebservices.com/interfaces/sessionHeader.xsd"/> <xsd:element name="appointmentMaker"> <xsd:complexType> <xsd:sequence> <xsd:element ref="serviceVariables"/> <xsd:elementname="dateisAvailable" type="xsd:boolean"/> </xsd:sequence> </xsd:complexType> </xsd:element> </xsd:schema>
The initial request from the client does not necessarily have to incorporate this header, because the service provider usually generates the data. The under-standing is that, if the header is missing from the request, it is the initial request to the service for this session.
Presentation Data
Identifying the presentation data you want to incorporate in your payloads may be the most difficult component because it is so subjective. There is no right and wrong, and certainly different cases can be made for different solutions.
The best approach is to make your payloads as lean as possible to accommodate the minimum requirements for utilizing the Web service. That means including presentation by default only when it is either key to the process or likely to be used by 80 percent of consumers. At the very least, other information can always be referenced through links provided through the payload for those who want extra services.
Because we are working with a static payload, we need to make a decision here and stick with it. For our purposes, our Web service does not require any presentation data to function effectively. We will leave it to the consumers on how to format our textual data and lay out our information. However, as part of its strategy, the provider would like to gain some branding awareness for its business. The provider may or may not have actually made this exposure part of its business agreement with consumers, but the provider will at least want to make a logo available via response payloads so that the avenue exists. We will expose presentation data schema for appointment service as a link to the logo on the provider's site, as shown here:
<xsd:schema xmlns:xsd="http://www.w3.org/2000/10/XMLSchema"> <xsd:element name="branding"> <xsd:complexType> <xsd:sequence> <xsd:element name="logo" type="xsd:uriReference"/> </xsd:sequence> </xsd:complexType> </xsd:element> </xsd:schema>
| Note | More extensive usage of presentation data for your Web services is discussed in Chapter 7. |
The following code generates what our response payload might look like if we put all three of these components together for our day availability request:
<appointmentMaker xmlns:xsi="http://www.w3.org/2000/10/XMLSchema-instance" xsi:noNamespaceSchemaLocation="C:\WINDOWS\Desktop\appointmentMaker\static\ response1.xsd"> <serviceVariables> <consumerID>12345</consumerID> <userID>5468</userID> <stage>1</stage> </serviceVariables> <branding> <logo>http://www.architectingwebservices.com/images/logo.gif</logo> </branding> <dateAvailabilityStatus>true</dateAvailabilityStatus> </appointmentMaker>
You can see how even this relatively simple function can generate a decent payload size without too many bells and whistles added to it. This is why you need to be careful not to add too much functionality that won't be used by a majority of your consumers.
Because developing static payloads is the easier and quicker solution, most Web services will likely take this approach. This approach can be very effective, but also very limiting and possibly not very efficient. A more flexible and powerful approach is the dynamic payload.
Dynamic Payloads
The idea behind dynamic payloads is to allow the flexibility and expandability of Web services. It is like taking many static payloads and grouping them together. Figure 5-21 showed the results of taking our four-request, four-response system and making it a two-request, four-response system. This is only possible by designing dynamic payloads into the interface model.
Dynamic payloads are also your avenues for personalizing your Web services. By allowing requests and providing responses that are catered for your consumers, you can expose a very efficient process that meets their needs. That said, dynamic payloads are not meant to allow you to customize your services for each and every consumer. Rather, you can develop templates that cover each of the main implementation approaches your consumers might take. Allowing personalization on an individual consumer level would likely be tedious and costly.
Dynamic payloads have three different classifications:
-
Dynamic requests
-
Dynamic responses
-
Conditional responses
A Web service may utilize any, or any combination, of these dynamic payloads to accomplish a certain goal. Each has different benefits and potential drawbacks, so I will look at each in more detail.
Dynamic Requests
The dynamic request is something that ultimately helps take a load off the consumer in working with a Web service. In this approach, the request is treated as a malleable object that can allow the provider and consumer to utilize different services and properties and incorporate them directly into the request. This is similar to the concept of object-oriented inheritance in which a base class can be extended with additional functionality. The alternative to adopting dynamic requests is creating an entirely different request, basically a new interface for every new flavor of that service.
By using dynamic requests, the provider can almost provide a very generic interface that can be suited to any consumer's needs. For instance, a consumer can request that the provider help with tracking of activity by maintaining some header data on a passthrough basis. This can be especially helpful in an asynchronous process, as discussed before.
Of course, every benefit usually has a cost. After all, if dynamic requests were so great, wouldn't everybody use them? The actual cost can be hard to determine, but it is definitely going to be in performance and potentially scalability. The provider will be adding overhead to its Web services because it will be adding some extra handling of the payload at some level. Something has to be done with the data, whether it is just maintained, saved, or acted on. Ignoring it can potentially cost nothing, but then no value is gained from having it at all.
A popular use of dynamic requests will no doubt be for search services. Whether one is searching for a book, a movie, or a CD, an enormous number of criteria can be referenced. A dynamic request potentially allows the search based on any of these criteria, each with its own specific data. Again, the extra effort is placed on the provider, which must take the extra step of determining what the search is for and handling it appropriately. (See Figure 5-22.) However, dynamic requests also allow the ultimate in flexibility by being able to provide new functionality with backward compatibility for consumers of the older functionality.
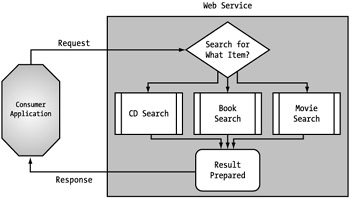
Figure 5-22: Dynamic request handling by the provider
The following code is for two XML documents that are the request payload for your hypothetical search Web service. Here is a search request for a flight from Dallas to Chicago:
<searchService> <flight> <departureCity>Dallas</departureCity> <destinationCity>Chicago</destinationCity> <departureDate>2001-09-15</departureDate> <returnDate>2001-09-17</returnDate> <criteria>fare</criteria> </flight> </searchService>
Here is a search request for albums on CD by Genesis:
<searchService> <music> <album> <artist>Genesis</artist> <format>CD</format> </album> </music> </searchService>
The only commonalities between these two payloads are the Web service invoked and the root node. These can easily be separate static requests with different root nodes invoking different services. The objective here is not to promote the idea that an application can actually service both of these requests. In fact, this shows the ability of a Web service to aggregate several functions available to it through a single interface that can have quite a bit of variation.
Dynamic Responses
A dynamic response can be very helpful in offering multiple versions of your Web services. This allows you to have different offerings around the same functionality without hindering your various customers. Perhaps you would like to provide a lot of presentation data, but you do not want to send it when you know the consumer does not need it. Based on who the consumer is or information provided through the request, the provider can send one of the two following responses to the music request just described. This code gives a simplified response:
<searchService> <music> <criteria type="artist">Genesis</criteria> <album> <title>Duke</title> <releaseYear>1980</releaseYear> </album> ... <album> <title>We Can't Dance</title> <releaseYear>1991</releaseYear> </album> </music> </searchService>
This code provides a formatted response to the music search:
<searchService> <music><table border="0"> <tr><td><b><criteria type="artist">Genesis</criteria></b></td></tr> <tr><album> <td><coverImage><img src="/books/4/149/1/html/2/http://domain.com/img/duke.jpg"/> </coverImage></td> <td><albumTitle>Duke</albumTitle></td> <td><releaseYear>1980</releaseYear></td> </album></tr> ... <tr><album> <td><coverImage><img src="/books/4/149/1/html/2/http://domain.com/ img/wecantdance.jpg"/></coverImage></td> <td><albumTitle>We Can't Dance</albumTitle></td> <td><releaseYear>1991</releaseYear></td> </album></tr> </table></music> </searchService>
| Tip | Notice how this response places all formatting outside the individual element tags. For example, the Duke album title element was not presented as <albumTitle><td>Duke</td></albumTitle>. This is a best practice that allows the consumer to still easily access the raw data. Placing the content tags inside the elements requires the consumer to build logic for stripping HTML tags out to access the data. This is important even when you are adding presentation data to your payloads. |
Although the second response provides a richer response that includes content and formatting, it also makes the response nearly three times larger. Depending on your background and experience, you may look at this difference and think it is either negligible or massive. It is usually neither of those extremes for a given scenario.
This response size difference isn't negligible to the provider if it is supporting large volumes of consumers. There is no exact correlation, but possibly a third fewer requests can be handled by a given system if a more verbose response is provided. Also, the consumer utilizes more resources to handle the data. Obviously, it is not worth decreasing possible customer value to provide verbose data if this data is extraneous.
However, the extra data can save processing time if this data allows the consumer to do less work. It just depends on the situation, and that is why dynamic payloads in general, and dynamic responses specifically, can be very valuable.
With the additional overhead of the verbose response, it might make sense to utilize dynamic responses to not waste the resources for consumers who want only raw data. In fact, it makes a lot of sense to use this model to provide a Web service that you want to support multiple presentation models. In this way, you are not overloading the consumers of the masked service, but are providing the rich content necessary for an isolated service (discussed in the "Presentation Model" section in this chapter). This is where you identify your consumer scenarios and develop your templates. Each of these responses is considered a consumer template. These might be the only ones, or you might identify others. Again, avoid developing too many "one-off" templates, because at some point the differences become somewhat negligible, but the effects on your systems are not.
Another use for dynamic responses is versioning. If you treat your response as a static instance, any enhancements will likely require a new Web service so that you do not break compatibility with your current consumers. Because you are dealing with XML, perhaps adding more data won't be a detriment to your consumers, but you cannot know for certain. If the provider establishes before-hand that there may be different instances of a response (that is, dynamic responses), its consumers will have coded their applications appropriately to simply ignore extra data until they choose to utilize it.
These are all examples of different response payloads based on the same core information and function. There may be even more extreme cases in which the direction your Web service goes may be altered by the request.
Conditional Responses
The difference between a dynamic response and a conditional response can be subtle. The distinction is ultimately made based on the intent. If the consumer can anticipate the exact format of the response, the response is considered static. A conditional response means that there is more than one possible response, not on a data level, but on a structural, or schema level. Instead of just providing a more verbose response, as we did earlier with the music search, we are providing a completely different response.
The purpose of incorporating variable responses into your interface model is to provide a more compressed process via the Web service. As you saw in our appointment service (Figure 5-21), we streamlined the entire process by eliminating two of the requests through conditional responses, allowing us to eliminate half of the necessary requests by simply providing a choice between two responses for the remaining two requests. (See Figure 5-23.)
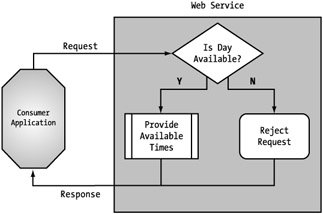
Figure 5-23: Conditional responses for the appointment service
Conditional responses can be very helpful to both the consumer and provider, but these responses definitely expect a bit more from the consumer during implementation. Just as the provider has to do some extra handling in supporting dynamic requests, conditional responses will require the consumer to take an extra step to identify what the response is and to work with the data correctly.
One solution that could take advantage of a conditional response model is a search system that does not want to return a null or infinite result set. Typically, when a null result set is presented, the user must decide how to proceed. Should the user just quit the application or should they modify some of the search criteria, guessing at what might work? On the other hand, in the case of huge result sets, users will probably have to sift through a lot of inappropriate data that they did not screen out through their criteria.
The alternative is to have the provider return a payload to the consumer either requiring further criteria to narrow the result set or recommending changes that could be made to the criteria to find a match. The user can then make a more informed decision on what to do next. Taking this idea one step further, the consumer's application itself can automatically modify the information and resubmit it to the Web service.
Another application of conditional responses that can be most effective is for error handling. When either bad data is submitted or there is some problem with the process, the necessary information has to be returned to the consumer. Without conditional responses, this information would be incorporated into every payload and simply ignored or unused. A Web service provider can have a completely separate error process that is defined for all calls and simply utilized as the response payload when necessary. This also provides a consistent mechanism for your consumers to use to handle errors as necessary. Separate routines to handle each response do not need to be developed and implemented. When designing conditional responses, you have to be careful with how far you take the concept. You aren't going to want to perform every function through a single call and multiple responses, so there is an extreme you should avoid.
Perhaps the best way to work through the appropriate uses is through use case scenarios. Such scenarios involve stepping through an application as an end user. In this case, you act as the consumer and step through each segment of your Web service's process to identify the possibilities. Assume that the first case you walk through is free of errors with no issues encountered. This starts as your baseline process. From there, you then handle the exceptions and alternative paths that might be taken and try to work them into your baseline use case.
Let's walk through this process with the appointment Web service. This process effectively takes us from the original static and isolated process (Figure 5-18) to the streamlined process (Figure 5-21). Without conditional responses, we cannot make this transition.
The first step to defining a conditional response is to walk though the process with an optimistic approach. After initiating the appointment application (see Figure 5-24, step 1), the first thing we do as a consumer is select a day for the appointment (2). Since this is an ideal scenario, we do not have to concern ourselves with a negative response. Because of this, we can immediately provide a list of times that can be selected for the appointment (3). Again, these options are assumed acceptable by default, and we just select one (4). That means we can directly make the appointment request of the service (5). The service doesn't need to worry about checking the appointment time and so can immediately book the appointment (6) and provide a response (7).
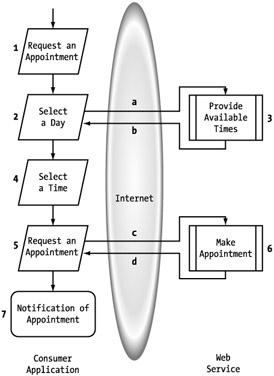
Figure 5-24: Appointment service baseline process
Next, we need to handle the exceptions. Starting with the day selection, we need to check to make sure the day is available for appointments. Because that is an exception to the day selection process, we just modify that one interaction. We will need to insert a step into the service that performs the check and handles the affirmative and negative outcomes. (See Figure 5-25, step 3.) The affirmative is in place because of our baseline, but the negative needs to be added. It should go back to the consumer and allow the selection of another day, basically repeating the current request with different data (b).
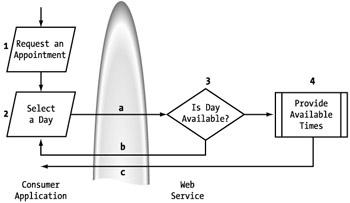
Figure 5-25: Date selection exception handling
The next use case that needs to be incorporated is canceling the current day due to a rejection of the available times provided by the service. In this case, the consumer's application must allow an avenue for also selecting a different day. (See Figure 5-26, step 5.) Otherwise, the user can proceed to select one of the provided times (6).
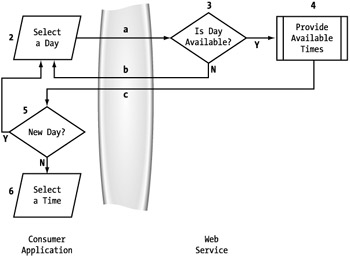
Figure 5-26: Date availability exception handling applications
The final exception that needs to be handled in the process is the time availability. This will catch any times that may have been previously reserved in between the initial time request and the actual booking process. This should prevent the double booking of any appointments.
The next decision point, similar to the day availability check, is an availability check on the time. (See Figure 5-27, step 7.) If it is not available, the response should be sent back to the consumer so that another time, and potentially another day, may be selected (d). Otherwise, the appointment is booked through the mechanism in the baseline process, and an appropriate response is returned.
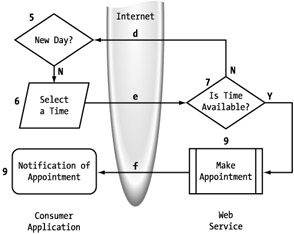
Figure 5-27: Time availability exception handling
Implementing all of these changes produces the streamlined process shown in Figure 5-21. We started with two requests from our baseline and never needed to add more. This may not always be the case, but usually you should need to add few requests to your baseline. We did add two more responses to handle the exceptions that arose, one for an unavailable day and one for an unavailable time. These additions will be much more common.
Of course, the consumer will be asked to do a bit more during the implementation of a Web service with conditional responses. More intelligence will have to be built into an application to handle these responses as they come back. Fortunately, the service will not provide just any response to any request. The responses should be well identified and documented for each request so that the consumer can plan for them appropriately. Overall, consumers will benefit from conditional responses, since it will mean fewer requests for them to implement which results for a more efficient process to be incorporated into their applications.
We have now discussed the presentation and interface models for Web services. The next model, the security model, may be the most important of the three, however, because the success of Web services depends upon its existence and successful implementation.
|
|
EAN: 2147483647
Pages: 77