An Introduction to SOA
| By Udi Dahan Both DDD and SOA are relatively new concepts, the first being quite well-defined, and the second less so. While there are those who claim that SOA has been around since the early CORBA days, never has there been such broad vendor and industry buy-in for "just an architecture." So What Is SOA Anyway?Although a number of definitions of SOA have been proposed, no one definition has been declared the victor. Most definitions are based around the idea that systems are composed of independent services. However, what exactly constitutes a service is unclear. One definition of SOA that cannot be refuted is that SOA is a way to develop software. Specifically, SOA deals with systems or applications that are, or can be, distributed. The acknowledgement that distribution is a primary architectural issue is one of the underlying currents of SOA. Why Do We Need SOA?Software that is meant to run in a distributed environment needs to be designed differently. This is a fundamental shift from distributed object thinking where applications would use non-local resources "transparently," with no knowledge of the location of these resources. The problems that arose with distributed object architectures were primarily found in performance. The semantics of working with local and remote resources need to be different, a hard-learned lesson that has become a litany in distributed systems development: "Chunky over chatty." Chunky interfaces, also known as coarse-grained interfaces, cause more work to be performed in a single call than fine-grained interfaces, which require multiple calls to perform the same amount of work. The explicit coordination and resource-locking that needs to take place over fine-grained interfaces is totally encapsulated in a single chunky call. This results in client code that is less coupled to the server code implementation. In fact, the evolution of distributed systems architecture has been punctuated by the introduction of new ideas and the sobering effects of realityperformance. Despite the fact that Moore's law has held over the years, and apparently will continue to hold, the world of large-scale systems development continues to be preoccupied with performance. However, it is not so much performance as a static measure that is interesting, but rather scalability, the dynamic measure of performance over varying loads, that architects strive to maximize. SOA is the next step on the ladder of architectural evolution that will enable new systems to be built, and older systems to be utilized, in scalable solutions. How Is SOA Different?While current distributed systems development practices design layers and deploy them in physical tiers, SOA unifies these two concepts into "services," which are both the unit of design and deployment. The other aspect that differentiates SOA from current practice is the codification of communication between services; while there are no restrictions on how layers or tiers should communicate, services must communicate according to message-exchange-patterns defined by a schema. There is also both theoretical and practical support for using only one-way asynchronous messaging for inter-service communication; however, this has not yet won industry-wide support. Note Note that "schema" doesn't necessarily dictate XML, but rather the set of messages that flow between services. While XML, and SOAP by extension, are not prerequisites of SOA, the extensibility of XML makes the versioning of schema much easier. What Is a Service?Besides being both the unit of design and the unit of deployment, services are surprisingly ill-defined for the size of the buzz surrounding SOA. Instead of defining what a service is, most of the literature describes properties of services. One such example is the four tenets of Service Orientation:
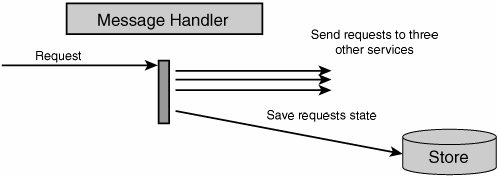
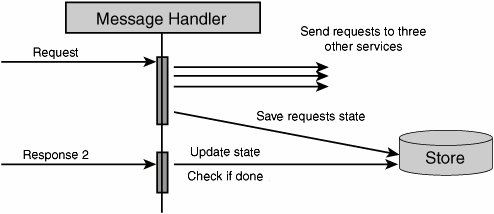
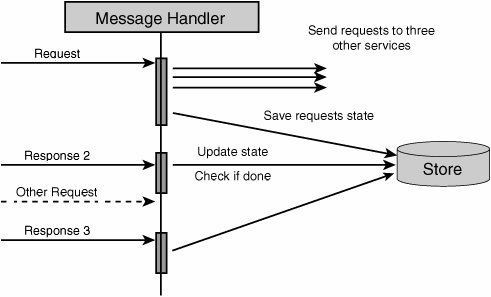
While these properties do indeed drive the design of scalable services (and will be discussed in more detail later), they apparently provide little guidance on the design of distributed systems. Architects just beginning to employ service-oriented techniques to their designs have no information about which elements should be grouped together into services, how to recognize and define service boundaries, and how these services are to be implemented using classic OO patterns. On top of that, the technologies surrounding the "pure" architectural aspects of SOA continue to be in a state of flux, and the various vendor offerings appear to be little more than repackaging of current products. Is it any wonder that SOA is already being dismissed as hype? What Goes in a Service?The question previously raised as to what elements of design are grouped together into a single service is not new to most developers and architects. This question has already been asked at the introduction of components and objects. While composing several objects/classes into a component is just fine, the same cannot be said of components and services. A service is not just a collection of components but rather a fundamental shift in how we structure our software. By taking into account that communication with a service is based on message exchanges, we find that services are composed of different types of elements and not just "components" or "objects." In order to expose functionality, services use a message schema. This schema is composed of several elements: the most basic include the "data types" (like Customer) that define entities, the messages that define what operations can be performed (not necessarily on a per-entity basis), and the service contract that defines interactions with the defined messages (a CustomerChangeRequest will result in a CustomerChangeReply, for instance). It is quite clear that a message schema is neither an object nor a component, yet it is a necessary part of a service. Another part of services that is often overlooked is the service host. A service would not be able to provide functionality without having some kind of executing environment in which to run. Web services using HTTP will likely have either IIS, Apache, WebSphere or some other Web server as their host. Other services may be hosted by COM+, a Windows Service, or even something as simple as a console application. Although the industry has been moving toward transport-independent services, certain host implementation details (like protocol) do affect services in significant ways. HTTP and other TCP-based protocols are all connection-oriented. In distributed systems where elements may fail, reboot, or simply respond slowly, connection-oriented protocols can cause performance to suffer until time-outs occur. Connectionless protocols (like UDP) cause other problemsthere are no built-in mechanisms to recognize that a message did not arrive at its destination. If anything, the necessary part of any service is its host. Beyond these atypical elements, services will indeed be composed of components and/or objects. Yet, not just any composition will meet the guidance prescribed by the 4 SOA tenets. A thorough discussion of their meaning is in order. Where Do the Four Tenets Lead Me?The first two tenets (autonomy and explicit boundaries) go hand in hand; each service is independent of other services, and it is clear where one service ends and another begins. Some ramifications of this include the fact that should one service crash, other services wouldn't crash as a result. Therefore, at the most basic level, different services should run in different processes, so a thread could not enter a different service as a result of a method call. At more profound levels, there should be no way one service could lock resources in another service transactions (of the ACID type) should be limited in scope to a single service. Note The term "transaction" was originally used to describe a way of working with relational databases and the four properties of transactions were given the acronym ACID: Atomic, Consistent, Isolated, Durable. A common implementation for databases to fulfill these requirements, the relevant rows, pages, and tables were locked within the scope of a transaction. The third tenet (schema, not class) seems to be talking about interoperability, that to communicate between services, we use XML on the wirethe so-called lowest common denominator. However, at its most basic level, this tenet is talking about separation of concerns. The class that implements the desired behavior is decoupled from the external clients that "call it." This is quite different from Java RMI, COM, or .NET remoting, where client-code must reference server types. When using schema, an explicit mapping needs to be performed between external message formats and internal class invocations. This enables us to change the internal implementation of a service, going so far as to change which class or interface is invoked without affecting external clients. There is an even deeper meaning to the third tenet, and it is versioning. While types can form hierarchies such that one type is a kind of another type, history has proven versioning types to be horrendously difficultDLL hell comes to mind. One of the goals of versioning a service is to avoid having to update client-code already deployed. This goes so far as to say that the deployed clients will continue communicating with the same endpoints as before. The benefit inherent in schemas that is absent in types is that schemas can be compatible, even though they are different. This is where the extensibility of XML is important. For example, after deploying version 1 of our service and client, we would like to roll out version 2 of the service so that we can deploy several new clients (version 2) that require more advanced functionality from the service. Obviously, we wouldn't want to break existing clients by such a change, nor would we want to have to upgrade them. In order for this to be possible, version 2 of the service's schema needs to be compatible with version 1, a task more difficult and less developer-friendly when communicating without schema. Imagine having to tack on to the end of each method signature something like "params object[] extraData". The fourth property of services in SOA (compatibility is based on policy) further reinforces the first two pointsthe service decides whether or not it will respond to a given request and adds another dimension; metadata is transferred as a part of the request. This metadata is called policy. In most presentations given, policy is described using examples such as encryption or authentication capabilities. The idea is based on a separation of concerns; the schema that defines the logical communication is independent of the encryption policy. If you have information you'd like to pass between services without expressing it in your schema, policy is one way to do it. What Is a Service? Take 2Now that we've discussed these properties of services, let's summarize with what a service is. Once upon a time, we all wrote applications, applications that the user interacted with. Today, we're going to call applications "services," and they'll be able to interact not only with users but with other "services." Note that distributed applications aren't going to be called "distributed services," but will rather be modeled as a bunch of services that work together. The rule-of-thumb for the confused is "one .exe per service," or when it comes to web applications, "one root Web directory per service." The flip-side of the coin relates to databases; while there won't necessarily be one database per service, there should not be shared databases between services. Shared databases are really back doors into the service, bypassing validity checks and logicin essence, violating its autonomy and increasing coupling between the services. The Place of OO in SOANow that it is clear that an application is really a service, a part of a larger whole, how then does object-orientation, the accepted practice for application development, fit into SOA? Although some have proclaimed SOA to be the next generation of application development, effectively replacing OO, nothing of the kind has happened yet. It has taken over two decades for mainstream development to move from procedural-oriented to OO programming. It is unlikely that were a shift from OO to SOA possible, it would happen in any less time. In fact, SOA and OO operate on different levels. OO deals with the design and code of a single deployment unit while SOA deals with a solution comprised of multiple deployment units. SOA does not suggest new or alternate ways of designing or coding the internal logic of a given application or service. There is no reason SOA and OO should not be cooperative technologies. The question that SOA does bring to the table when developing OO applications is how these applications will accept and respond to messages coming from sources other than the user, and even in parallel to user activity. The fact that a given application can receive requests and, at the same time, issue its own requests to other services brings us to the conclusion that interactions no longer follow the classic "client-server" pattern. Client-Server and SOANot so long ago, most application development was described as client-server. For example, client software would "send requests" (SQL) to a database server and receive responses from it. Later, client-server fell out of favor and was replaced with 3-Tier (or N-Tier) where the rise of the application server began. Again, requests went one way and responses the other. However, as systems grew and became more interconnected, the N-Tier concept blurred as application servers began to make requests from other application servers acting as their clients. The inherent ordering found in the tiered architectures wasn't being seen in practice. Finally, client-side software was beginning to receive events asynchronously from its servers, in essence responding to requestssomething that it wasn't explicitly designed for. Beyond the SOA theory that states that client software should also be designed as a service, there is a real need for client code to be able to receive messages. Consider the case where an action on the server takes a very long time to complete, longer than the time-out duration for HTTP, possibly even days. This is not at all unusual for operations that require human intervention. While the client may poll the server for completion, this places undue load on the server, requiring a background task on the client. If we were to use that same background task to listen for messages notifying about work completion, we could relieve the server of this load. This solution is both feasible with today's technology and simple to implement. In this manner, the client may receive any number of types of messages, effectively becoming a service. In fact, these message exchanges could better be described as conversations between an initiator and a target than requests/ response pairs between client and server. There are no inherent constraints as to which services can initiate a conversation and which can respond. One-Way Asynchronous MessagingWe have seen that in cases of long response times we must disconnect the response message from the flow of the request message. Yet, can an initiating service ever know how long it may take the target to respond to a request? Even if the previous result arrived quickly, that is no guarantee of future responsiveness. In essence, if all interactions with a service were based on this idea, that service's clients would be insulated from the impacts of load on the service. This paradigm has other benefits as well. Because the initiator no longer requires a synchronous response, the target service is now free to perform the processing at the time most beneficial to it. Should the target service be under heavy load, it could schedule the processing of new messages for a later time. In other words, we are able to perform pro-grammatic load balancing over time. For instance, we can write code that takes into account the nature of the request when scheduling it for future processing. In the previous synchronous request-response paradigm, the initiator was only capable of receiving the response from the target. Now that the initiator is listening for a response, the constraint that only the target service can return the response is lifted. The target service can now offload returning responses to other services. The advantages of using one-way asynchronous message-exchange patterns are numerous. Both the flexibility of the solution and its scalability are increased. These benefits obviously have a cost attached to them, but we will later see that the cost is not that great. How SOA Improves ScalabilityBy using one-way asynchronous messaging, a service is able to moderate load by queuing requests. This results in services that do not degrade in performance under increasing load because no performance-draining resources (like threads) are acquired. By keeping resource utilization near constant at any load above that giving maximum performance, services developed using one-way asynchronous messaging achieve better performance characteristics, as shown in Figure 10-1. Figure 10-1. Performance under load for one-way asynchronous and synchronous request-response/RPC messaging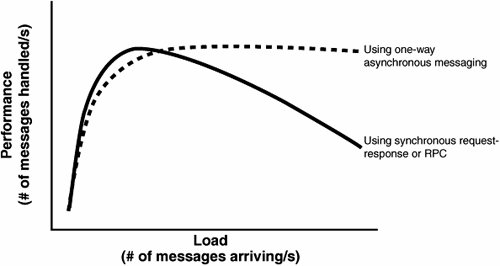 Note that while under small loads, the time to process a single message this way may well be greater than when using classic RPC. This is secondary to the greater throughput achieved under heavy load. The Design of a SOA ServiceThe high-level design of a service which employs one-way asynchronous messaging may look similar to that shown in Figure 10-2. Figure 10-2. Hypothetical high-level design of a service which employs one-way asynchronous messaging In this design, when a message is received, no processing is done on it beyond placing it in a queue (this minimizes the number of threads held open by the application server, regardless of the load or processing time). Next, a processing thread will, at some future time, take the message from the queue and process it. If this processing requires sending messages to other services, the responses will be received exactly the same way as any request. Furthermore, the processing thread will not need to wait for these responses, but can continue handling new messages; the state of the processing of previous messages is held in some store that can be retrieved when responses have arrived. Note that processes may be used instead of threads when using an out-of-process queue like MSMQ to better enable scale-out growth by running those processes on separate machines. How Would a Service Interact with Other Services?Let's consider an example of how a service would process a request that involves retrieving information from other services and focus on how the actual processing works. (Note that in the figures that follow, when one horizontal arrow appears below another arrow, this means that the lower arrow represents an event which occurred at a later point in time than that of the higher arrow.) First, a request arrives at our service, is placed into a queue, and then handled. In order to handle the request, information needs to be retrieved from three other services. After requests are dispatched to the other services, the state of processing the original request (pending responses 1, 2, and 3) is saved (see Figure 10-3). Figure 10-3. Request is dispatched to other services and state is stored When a response from service #2 arrives, it waits in the queue until it reaches a message handler. The message handler retrieves the state of the original request from the store and updates it (pending responses 1 and 3). Because the processing of the original request has not been completed, the handling of response #2 is now finished (see Figure 10-4). Figure 10-4. One response is processed Should another request arrive before processing of the previous request is complete, it would have no impact on the processing of the original request. It could begin its own processing and send requests to any number of other services in the same manner. We can interleave the processing of multiple requests with the same resources (see Figure 10-5). Figure 10-5. Another incoming request won't affect the first request that is still being processed When the response from service #3 arrives, it is handled in the same way as the response from service #2. Because not all necessary responses have been received, again no response will be sent to the initiator of the original request (see Figure 10-6). Figure 10-6. Another response comes, but one response is still lacking Finally, only when the response from service #1 arrives for message handling can the processing of the original request be completed. After updating the state of the original request in the store, the service now knows that all responses have arrived and that the response can be sent to the initiator (see Figure 10-7). Figure 10-7. Final response for first request arrives, and the result can be enqueued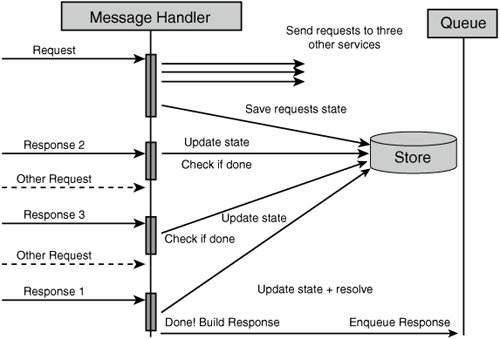 Note that the message handling logic need not send the response to the initiator directly but rather can queue the response. The benefit in separating message handling from returning responses is that we decrease the load on message handling logic. Also, from the perspective of separation of concerns, how and when responses are returned is outside the responsibility of message handling. Although we've taken into account that services may take some time to respond to our requests, the issue that we haven't dealt with yet is when no response is going to return. The current design does not solve this problem because it specifically circumvents time-outs inherent in connection-oriented protocols. SOA and Unavailable ServicesWhile in the classic RPC style of distributed systems we would receive an exception when trying to connect to a remote server that was down, in this design we may not receive any exception or response at all. What is required then is some way to know that the handling of a certain request has timed out. This can easily be taken care of by assigning a timer to each request sent. However, this is not the interesting part of the problem. When the time waiting for a response expires, what should be done? This is another area in the design where domain logic is required. The questions that need to be answered by the domain logic are varied and include the following:
The other advantage in using the previous design for services instead of the classic RPC-style design is that the domain logic performed when a remote service is unavailable is cleanly separated from the main message-handling path. In the RPC-style design, an exception would have been thrown in the middle of the message-handling code, and the code that would have to be written to handle the exception in the various ways described by the previous questions would cloud the intent of the domain logic. In the interaction diagram shown in Figure 10-8, we can see that the code that handles timeouts is not only separated from the message-handling code, but is separated in time as well. Both request and failure handling logic are encapsulated. Figure 10-8. Applying a timeout watcher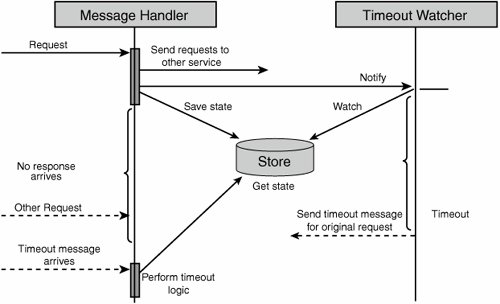 Complex Messaging ProcessesWhen developing services using the previous design, we are also able to construct complex and robust inter-service workflows. For instance, when Request A is received, send requests to services Alpha and Beta. When a response is received from either Alpha or Beta, if the response value is greater than some threshold, send a request with the threshold value to service Gamma; otherwise, send a request with the response value to service Delta. If service Delta is unavailable, partial results are to be returned. If service Alpha is unavailable or returns an error, the error should be returned to the initiator of the request, and so on. During this entire process, other messages can be processed as well, and many other complex processes can unfold concurrently. Not only is concurrent execution possible, but it is resource-efficient, even under load. Scaling ServicesWe've already seen the increased scalability SOA provides by utilizing one-way asynchronous messaging. However, can services designed this way efficiently make use of increasing numbers of processors on the same box? What about increasing numbers of servers? Let's first look at the message handling. The message handling thread/process is statelessfor each request, it finds the appropriate state in the store and processes the result accordingly. Therefore, we can increase the number of concurrent message handlers without harming correctness. Because each of the message handlers is independent of others, there will be no need for in-memory locking or for a given message handler to wait (unless it has no messages to process). For a single box with multiple processors, this means that we can increase the number of message handlers and increase throughput. For multiple servers, we could place the message receipt, queue, and store on a single server while placing more message handlers on each additional server. The ultimate advantage of the scale-out scenario described is that it enables addition of more servers at runtime. By monitoring the number of items in the queue, we can know when the system has reached peak capacity, and then add more resources without taking the system down or hindering performance in any way. SummaryThe main point to remember about SOA is that it is "merely" an evolution of best practices of distributed systems development. The core OO principles of separation of concerns and independence of interface from implementation continue to be reflected in service-oriented practices. Although many topics have been touched upon, each topic has depth that cannot be explored in such an introduction. Hopefully you have understood what SOA is not and what tools shouldn't be used between services. How the logic of a service is internally structured is a question that I assume will never be decisively answered, but I'm sure Jimmy will get you on track. Thanks, Udi! And for readers who would like to get more into depth with SOA, or more specifically messaging, a good book to start with is [Hohpe/Woolf EIP]. One of the driving forces behind SOA is to reduce coupling. Another technique for reducing coupling is the subject of the next section. I have pretty often written in this book about Dependency Injection, but I applied it only manually. To many people, injecting what the instance will need in the constructor is the most natural thing in the world. That's easy looking at it on a small scale and something we want to be able to do during test, but on a large scale during runtime it becomes tricky, cumbersome, and something that makes reuse much harder than it has to be. In the next section, Erik Dörnenburg will discuss inversion of control as the principle and Dependency Injection as the pattern. Erik, the readers are yours. |

EAN: 2147483647
Pages: 179
- Structures, Processes and Relational Mechanisms for IT Governance
- A View on Knowledge Management: Utilizing a Balanced Scorecard Methodology for Analyzing Knowledge Metrics
- Governing Information Technology Through COBIT
- Governance in IT Outsourcing Partnerships
- The Evolution of IT Governance at NB Power