Approaches to J2EE Architecture
|
| Building applications with multitier architectures involves the use of distributed computing, a complex area of software engineering. Although the J2EE platform does much to simplify the development of three-tier systems, distributed computing makes designs of this nature inherently more complex than systems comprised of only one or two tiers. This added complexity means architects should carefully consider whether the requirements of the system justify a distributed solution. In the past, the prominence of Enterprise JavaBeans (EJBs), the flagship technology of the J2EE platform, has lead some architects to produce complex multitier architectures for systems whose requirements would have been met with a simpler model. Although EJB technology has possibly the highest profile of all the J2EE services, Enterprise JavaBeans form only part of the J2EE specification, and their use is not mandatory in all J2EE applications. Furthermore, EJB architectures are possible that do not rely on the remote-method invocation services of the J2EE container. If you can avoid the use of a distributed architecture for systems that do not require it, then simpler designs result. Avoiding complexity in this way is important for rapid development projects, as complex designs can wreak havoc on tight schedules. Complexity makes:
Over the course of the next sections, we examine the strengths and weaknesses of distributed systems and consider possible architectures that do not rely upon the services of distributed components. Two-Tier Versus Multitier ArchitecturesPrior to the emergence of distributed computing technologies like J2EE and CORBA, enterprise information systems typically adopted a two-tier, or client/server architecture. Under the client/server model, business logic was implemented as an integral part of a rich, or fat, client application that accessed data housed in a central database server. The client/server model enjoyed considerable success. It was easy to understand, simple to test, and well supported by numerous high-level visual development tools. These benefits made the client/server architecture ideal for rapid development. Sadly, two-tier architectures do have some key shortcomings:
In searching for a solution to the shortcomings in the client/server model, developers concluded that you can never have too much of a good thing. If splitting systems into two physical tiers proved effective, then the addition of a further tier would also be a good thing. Experience proved them mostly right, and so the middle tier was born. The use of a middle business tier offers many benefits beyond that of the client server model:
These benefits have pushed the multitier model to the forefront as the architecture of choice for enterprise software. The technology of the J2EE platform provides a distributed component model for developing systems with multitier architectures, with Enterprise JavaBeans a key technology for developing business components for deployment to the middle tier. Enterprise JavaBeansEnterprise JavaBeans helps realize the RAD concept of developing software using component-based architectures. The EJB architecture defines components that encapsulate functionality into deployable modules with clearly defined interfaces known as enterprise beans. The J2EE platform supports three types of enterprise bean objects:
The remainder of this discussion focuses on the use of session beans for building distributed enterprise solutions. An EJB architecture provides substantial benefits when building an enterprise system:
The final point concerning location transparency is of specific interest, as this EJB technology makes possible the development of distributed architectures with the J2EE component model. Remote and Local Client ViewsClients of session bean objects can view methods on a bean's interface either remotely or locally. With a remote method invocation, a client running in a separately executing Java Virtual Machine (JVM) accesses the bean instance. With local access, the client resides within the same JVM as the bean object. Alternatively, as of the EJB 2.1 specification, clients may access session bean objects through a bean's Web Service. This is essentially another form of remote access. Clients obtain remote access to a session bean object through the enterprise bean's remote interface and remote home interface. These interfaces ultimately extend the java.rmi.Remote interface, part of standard Java Remote Method Invocation (RMI). By building on RMI, clients can access bean functionality across machines and process boundaries. The complexities surrounding network connection issues are all handled by RMI on behalf of the developer. An enterprise bean may also expose a local interface. Local interfaces do not offer location transparency, meaning that clients can access a bean only if it is executing in the same JVM through its local interface. We look at the benefits of local interfaces shortly, but first let's consider some of the implications surrounding the development of enterprise beans that expose remote interfaces to their clients. Distributed ComponentsProviding enterprise beans with remote interfaces makes possible the development of systems with distributed architectures. The J2EE platform does a very creditable job of reducing the difficulties associated with building complex architectures of this type. Nevertheless, adding remote interfaces to business components results in certain issues of which the architect must be aware before deciding upon a distributed solution. Rod Johnson eloquently raised awareness of these issues within the Java community in his book Expert One-on-One J2EE Design and Programming [Johnson, 2002]. These issues include performance overheads, complexity, and object-oriented impedance. PerformanceEJB technology relies on standard Java RMI for its distributed capabilities, which provides the client of the enterprise bean with location transparency when accessing the bean through its remote interface. However, the process involved in making a method invocation across a JVM or machine boundary, makes RMI calls several orders of magnitude more expensive than the equivalent calls on a local object. To understand why remote calls incur a performance penalty, let's review the steps involved in an RMI method call. In making the call, RMI creates a stub object on the client responsible for sending method parameters and receiving return values across the network. This packaging of method calls for transmission across the wire is called marshaling and is a common approach to remote method calls. RMI uses Java object serialization to convert parameters into a stream of bytes for sending across a network. The client stub does not talk directly to the object on the server but to an RMI skeleton object, which is the server-side equivalent of the client stub, and retrieves all calls sent across the network before forwarding them to the real object. This server-side skeleton object makes the call on the remote object on the client's behalf. This same process is followed every time a method on a session bean object's remote interface is called. The overheads of remote method calls means careful design is necessary to ensure the benefits of location transparency do not come at the cost of system performance. Tip Passing large objects as parameters in remote method calls further reduces performance. If an object contains references to other objects, then these member objects are also serialized as part of the call. To reduce the size of some objects, you can exclude unnecessary objects by marking them with the TRansient keyword. Since RMI uses Java serialization for marshaling, for very large objects you should consider overriding writeObject() on java.lang.Serializable and implementing some form of compression algorithm. Don't forget to implement a corresponding decompression algorithm for readObject(). ComplexityAlthough RMI can make the calling of remote enterprise beans a seamless process, distributed computing still introduces additional complexities for the developer. The first issue is the need for developers using RMI technology to be aware of the subtle but important differences between making remote calls and calling a local Java object. Parameters in a remote call are passed by value, due to the need for RMI to copy the parameter in order to send it across the network. If the remote object modifies the state of an object passed to it by value, then the object referenced by the caller does not reflect these changes. With a call on a local object, parameters are passed by reference. Consequently, if the called method modifies the state of an object passed as a parameter, then the object referenced by the caller does reflect these changes. This is a subtle difference in the semantics of the call, but it can cause frustration for developers unaware that Java's calling conventions have suddenly changed. Remote clients must also guard against the prospect that networking issues could cause a remote call to fail. Trapping these network errors isn't an onerous task, as you only need to catch thrown java.rmi.RemoteException exceptions. However, complexities arise with the need to handle these exceptions, because they are orthogonal to the standard exceptions a business method would normally throw. The architect must have a strategy in place for satisfactorily handling these remote exceptions and translating them into meaningful error messages for the presentation layer. Avoiding the need to deal with remote exceptions therefore has positive implications for rapid development. Object-Oriented ImpedanceEmploying the distributed capabilities of EJB technology requires a change in the way we apply object-oriented design practices. In a nondistributed architecture, developers work directly with objects from the domain model. Here, domain objects represent business entities and expose interfaces with fine-grained methods, such as get and set methods. The performance overheads of a distributed application preclude the use of objects with fine-grained methods, as they increase the number of network roundtrips when a client interacts with a remote object. To keep the number of roundtrips to a minimum, remote interfaces have to be coarse-grained, whereby methods combine the functionality of several fine-grained methods into a single call. To provide guidance when building distributed architectures, Sun Microsystems published a collection of J2EE design patterns [Deepak, 2003]. These patterns are essential reading for anyone building distributed applications. The Session Façade and Transfer Object patterns both offer effective strategies for managing the performance overheads of remote calls. Despite the existence of these patterns, they still impose on the architect's object-oriented thinking process. The architect must be aware of the constraints of the implementing technology and reflect this in all designs. Having the implementing technology dictate the makeup of a component's interface is counter to the practice of good object-oriented design. Choosing the Appropriate DesignDistributed components are not a prerequisite for all enterprise architectures. Unless the requirements of the system dictate a distributed architecture, a simpler application is possible by avoiding the need to employ the remote method invocation capabilities of the J2EE platform. The architectural decision as to whether to use distributed components therefore has a significant impact on rapid development projects. In this section, we look at two possible J2EE architectures, Web-centric and EJB-centric, although numerous permutations of the two designs presented are possible. The next two sections evaluate the merits of each design from the standpoint of a system whose main architectural driver is the delivery timeframe. Web-Centric ArchitectureOne trend in enterprise systems that has become very apparent is the move away from fat user interfaces to lightweight clients. In fact, thanks to the popularity of the browser, user interfaces have become positively anorexic. The Web application is emerging as the de facto standard for enterprise applications, a trend that has the potential to make the task of developing enterprise software far simpler. Let's consider a basic J2EE architecture to support an enterprise Web application that does not make use of the services of EJB technology. Figure 4-1 illustrates a Web-centric design. Figure 4-1. Web-centric enterprise architecture. Does anything in Figure 4-1 look familiar? The presentation tier is gone. In its place is the Web container (or Web tier), acting as a consolidated presentation and business tier. The browser-based interface enables us to return to a model similar in structure to the classic client/server architecture. Thus, the Web-centric model sees a single JVM housing presentation and business logic in a common Web tier. This design swaps a multitude of client machines for a single server and removes the deployment problems associated with the client/server model. The Web-centric design shown has just two tiers (or two-and-a-half with the browser): the Web tier, and the EIS tier. The use of layers within the Web tier separates user interface code from business logic. Note For clarity, the architecture depicted in Figure 4-1 does not show all of the layers required in an enterprise system. For example, a production system would put in place layers to split business objects from lower-level data access objects. Business objects are implemented as Plain Old Java Objects, or POJOs, in preference to heavier weight enterprise beans. The term POJO refers to a vanilla Java class that exposes no specialized interfaces. The nondistributed Web-centric architecture shown in Figure 4-1 has several key benefits:
A prerequisite for most enterprise architectures is scalability. The Web-centric design scales across application servers, although suitable load-balancing hardware or software is required to manage the allocation of requests between server nodes. Like any solution, the Web-centric architecture has its limitations, including the following:
The next section introduces enterprise beans that expose local interfaces into the Web-centric architecture. EJB-Centric ArchitectureTo counter some of the shortcomings in the Web-centric architecture presented previously, this next solution modifies the architecture to incorporate enterprise beans that provide a local view of their interfaces to clients. Figure 4-2 illustrates a possible EJB-centric architecture for our Web application. Figure 4-2. EJB-centric enterprise architecture.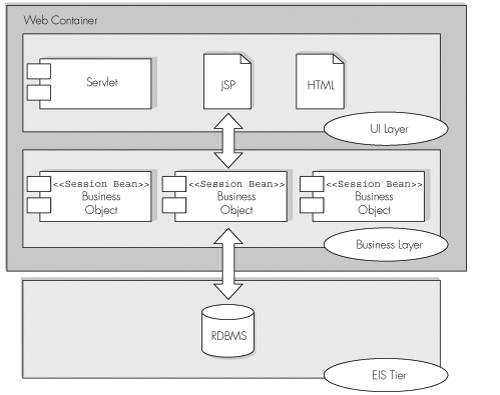 The architecture shown Figure 4-2 turns the business objects into session beans and deploys them into the J2EE server's EJB container. The session bean objects that represent the system's business components do not expose remote interfaces. Instead, they each make available a local interface to clients. The EJB 2.0 specification introduced local interfaces for enterprise beans in response to industry concerns surrounding performance issues with EJB architectures. Placing a local interface on an enterprise bean enables a client resident within the same JVM to invoke the methods on the bean instance using standard Java pass-by-reference calling conventions, avoiding the overheads incurred in a remote call. In the architecture shown in Figure 4-2, both the J2EE server's Web container and EJB container exist within the same JVM, making the components of the Web application local client's of the session bean objects. The EJB-centric architecture still has the same two-and-a-half tiers as the Web-centric version, with the Web container and EJB container acting as layers within the middle tier. The benefits of an enterprise architecture built using enterprise beans with local interfaces include the following:
The EJB-centric architecture presented represents a valid use of EJB technology where the system requirements call for declarative security and transaction management. Some of the weaknesses of this architecture include:
The architecture examples discussed are just two possible approaches to building enterprise systems. Simple architectures are faster and easier to implement than complex ones. Distributed architectures introduce complexity. Ensure the requirements of the system justify this additional level of complexity before embracing a distributed component model. |
|
EAN: 2147483647
Pages: 159