How MSDataShape Stores Data and Maintains Hierarchies
There are two main types of hierarchies: standard and parameterized. While they can use similar queries to retrieve the same data, they differ in how and when they retrieve that data. In this section, we'll take a look at both types of hierarchies.
Standard Hierarchies
The example discussed in the previous section is a standard hierarchy. The data shape provider parses the query string and passes each separate query contained in that string to the data provider.
ADO maintains the results of each query (in the case of our example, the customers query and the orders query) separately, in structures similar to Recordset objects. When you request the contents of the Orders field in the customers Recordset, ADO applies a filter to the results of the query on the Orders table, which is the data you see.
Many features available through the data shape provider make the query string and the resulting Recordset complex. We'll still categorize those complex hierarchies as standard hierarchies to reflect how the data is stored and maintained. In short, any hierarchy that isn't parameterized—a capability we'll cover momentarily—is considered standard.
Parameterized Hierarchies
A parameterized hierarchy is more than a hierarchical query that uses parameters. With a standard hierarchy, the data shape provider submits one query per level of the hierarchy to the OLE DB provider that communicates with the database. Parameterized hierarchies work differently and use a slightly different syntax. A query string similar to the string discussed in "Parsing a Hierarchical Query String," but using a parameterized hierarchy, looks like this:
strSQL = "SHAPE {SELECT * FROM Customers} AS Customers APPEND " & _ "({SELECT * FROM Orders WHERE CustomerID = ?} AS Orders " & _ "RELATE CustomerID TO PARAMETER 0) AS Orders" |
The child query within the query string uses the standard parameter marker, ?, in a WHERE clause, and I've changed the syntax slightly in the RELATE clause. Instead of retrieving all order data in a single query, the data shape provider builds a parameterized query that retrieves all orders for a particular customer. Thus, after retrieving the contents of the customers query, the data shape provider executes the parameterized query once for each customer retrieved.
But not all this data is retrieved immediately. Although the data shape provider retrieves all the customer data when you open your hierarchical Recordset, it doesn't retrieve any order data until you request it.
Choosing a parameterized hierarchical design has its pros and cons. The major benefits are that your code runs more quickly because you're not retrieving as much data initially and that you're not going to retrieve "orphaned" data, a topic I'll cover shortly. The major drawback is that this type of hierarchy requires a live connection to your database. You cannot persist a parameterized hierarchical Recordset to a file or stream by calling the Recordset object's Save method, nor can you pass such a Recordset across process boundaries. (We'll talk about passing Recordsets out of process in Chapter 15.) You also cannot reshape—a feature we'll discuss shortly—parameterized hierarchies. Hopefully, a future release of ADO will allow programmers to retrieve all data for the hierarchy and allow ADO to disconnect parameterized hierarchical Recordsets to pass them across process boundaries or persist them to files.
Comparing Standard Hierarchies with Parameterized Hierarchies
There's another major difference between the way standard hierarchies and parameterized hierarchies work: how ADO stores the contents of the hierarchy. With a standard hierarchy, ADO executes one query per level of the hierarchy and stores each level in a separate structure. Our standard hierarchy example stores the customers data in one structure and the orders data in another structure. ADO then applies a filter to the orders data so that only the orders for the current customer are visible. With the parameterized hierarchy, ADO executes a separate query to retrieve the orders for each customer. ADO stores the results of each query in separate structures. As you move from one customer to the next, you view the results of each separate query to retrieve order data.
Because the orders for each customer in a parameterized hierarchy are contained in separate structures, you might see some slightly different behavior than if you'd used a standard hierarchy. The next example is a major stretch, but it probably provides the clearest demonstration of how ADO stores the hierarchical data and what that means to you. Suppose that in your customers and orders hierarchy, you realize that the user made a couple of mistakes when entering the orders: one order was entered for customer B instead of customer A, while a second order was entered for customer A instead of customer B.
So, a supervisor uses a maintenance application that you've developed for such a case. Your code retrieves the customers and orders into a hierarchical Recordset. The supervisor uses your application to make the necessary changes and saves the data. The data in your database is now accurate.
However, depending on how you created your hierarchical Recordset, that supervisor might see some odd results displayed in your application. If you used a standard hierarchy, the orders for customer A and customer B will appear as they should in the hierarchy once the supervisor has completed the changes. The newly corrected orders will be linked to the appropriate customers in the hierarchy. When you re-reference each customer, ADO reapplies the filter to the order data and the supervisor sees the appropriate customers. With parameterized hierarchies, the orders now contain the correct information, but they're still associated with the same customers they were associated with before the supervisor made the corrections, as shown in Figure 14-2.
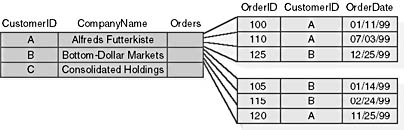
Figure 14-2 Parameterized hierarchy after switching customer IDs for two orders.
Which Type of Hierarchy Should You Use?
I use standard hierarchies rather than parameterized hierarchies so that I can persist my Recordsets to files or pass them across process boundaries. One of the drawbacks of standard hierarchies is that you can wind up retrieving and storing "orphaned" data (child data that doesn't correspond to any row at the parent level) in the hierarchy. For example, say that you wanted to retrieve the customers from a particular country and the orders for those customers in a hierarchy. You could use a query like this:
strSQL = "SHAPE {SELECT * FROM Customers WHERE Country = 'Germany'} " & _ "AS Customers APPEND ({SELECT * FROM Orders} AS Orders " & _ "RELATE CustomerID TO CustomerID) AS Orders" |
The problem is that the query the data shape provider will submit to your database will retrieve all records in the Orders table, regardless of whether they correspond to customers located in Germany.
The simple solution is to use the following parameterized query:
strSQL = "SHAPE {SELECT * FROM Customers WHERE Country = 'Germany'} " & _ "AS Customers APPEND " & _ "({SELECT * FROM Orders WHERE CustomerID = ?} AS Orders " & _ "RELATE CustomerID TO PARAMETER 0) AS Orders" |
Now you'll retrieve orders only for the customers located in Germany because the data shape provider retrieves orders in a separate query for each customer and will submit queries only for the customers retrieved in the parent query.
But what if you want to limit the amount of data you retrieve—meaning you don't want to retrieve any orphaned data—without facing the limitations of parameterized hierarchical Recordsets? There is another alternative.
Forget about hierarchies for a moment. What if you want to create a query that will retrieve only the orders for customers located in Germany? The orders are in one table, and the field that contains the location of the customer is in another table. SQL Server and Access support all the following syntaxes, each of which will retrieve the desired data:
SELECT Orders.* FROM Orders, Customers WHERE Orders.CustomerID = Customers.CustomerID AND Customers.Country = 'Germany' SELECT * FROM Orders WHERE CustomerID IN (SELECT CustomerID FROM Customers WHERE Country = 'Germany') SELECT * FROM Orders WHERE EXISTS (SELECT * FROM Customers WHERE CustomerID = Orders.CustomerID AND Country = 'Germany') |
Run some tests and see which of the syntaxes will provide the best performance.
Suppose you find that the first syntax works best for you. You could then use that query in your hierarchy:
SHAPE {SELECT * FROM Customers WHERE Country = 'Germany'} AS Customers APPEND ({SELECT Orders.* FROM Orders, Customers WHERE Orders.CustomerID = Customers.CustomerID AND Customers.Country = 'Germany'} AS Orders RELATE CustomerID TO CustomerID) AS Orders |
EAN: N/A
Pages: 131