12.7 Performance Characteristics of BSTs
The running times of algorithms on binary search trees are dependent on the shapes of the trees. In the best case, the tree could be perfectly balanced, with about lg N nodes between the root and each external node, but in the worst case there could be N nodes on the search path.
We might expect the search times also to be logarithmic in the average case, because the first element inserted becomes the root of the tree: If N keys are to be inserted at random, then this element would divide the keys in half (on the average), which would yield logarithmic search times (using the same argument on the subtrees). Indeed, it could happen that a BST would lead to precisely the same comparisons as binary search (see Exercise 12.72). This case would be the best for this algorithm, with guaranteed logarithmic running time for all searches. In a truly random situation, the root is equally likely to be any key, so such a perfectly balanced tree is extremely rare, and we cannot easily keep the tree perfectly balanced after every insertion. However, highly unbalanced trees are also extremely rare for random keys, so the trees are rather well balanced on the average. In this section, we shall quantify this observation.
Specifically, the path-length and height measures of binary trees that we considered in Section 5.5 relate directly to the costs of searching in BSTs. The height is the worst-case cost of a search, the internal path length is directly related to the cost of search hits, and external path length is directly related to the cost of search misses.
Property 12.6
Search hits require about 2 ln N 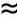 1N comparisons, on the average, in a BST built from N random keys.
1N comparisons, on the average, in a BST built from N random keys.
We regard successive equals and less operations as a single comparison, as discussed in Section 12.3. The number of comparisons used for a search hit ending at a given node is 1 plus the distance from that node to the root. Adding these distances for all nodes, we get the internal path length of the tree. Thus, the desired quantity is 1 plus the average internal path length of the BST, which we can analyze with a familiar argument: If CN denotes the average internal path length of a binary search tree of N nodes, we have the recurrence
![]()
with C1 = 1. The N - 1 term takes into account that the root contributes 1 to the path length of each of the other N - 1 nodes in the tree; the rest of the expression comes from observing that the key at the root (the first inserted) is equally likely to be the kth largest, leaving random subtrees of size k - 1 and N - k. This recurrence is nearly identical to the one that we solved in Chapter 7 for quicksort, and we can solve it in the same way to derive the stated result. 
Property 12.7
Insertions and search misses require about 2 ln N 1N comparisons, on the average, in a BST built from N random keys.
A search for a random key in a tree of N nodes is equally likely to end at any of the N + 1 external nodes on a search miss. This property, coupled with the fact that the difference between the external path length and the internal path length in any tree is merely 2N (see Property 5.7), establishes the stated result. In any BST, the average number of comparisons for an insertion or a search miss is about 1 greater than the average number of comparisons for a search hit.
Property 12.6 says that we should expect the search cost for BSTs to be about 39 percent higher than that for binary search for random keys, but Property 12.7 says that the extra cost is well worthwhile, because a new key can be inserted at about the same cost flexibility not available with binary search. Figure 12.10 shows a BST built from a long random permutation. Although it has some short paths and some long paths, we can characterize it as well balanced: Any search requires less than 12 comparisons, and the average number of comparisons for a random search hit is 7.06, as compared to 5.55 for binary search.
Figure 12.10. Example of a binary search tree
In this BST, which was built by inserting about 200 random keys into an initially empty tree, no search uses more than 12 comparisons. The average cost for a search hit is about 7.
Properties 12.6 and 12.7 are results on average-case performance that depend on the keys being randomly ordered. If the keys are not randomly ordered, the algorithm can perform badly.
Property 12.8
In the worst case, a search in a binary search tree with N keys can require N comparisons.
Figures 12.11 and 12.12 depict two examples of worst-case BSTs. For these trees, binary-tree search is no better than sequential search using singly linked lists.
Figure 12.11. A worst-case BST
If the keys arrive in increasing order at a BST, it degenerates to a form equivalent to a singly linked list, leading to quadratic tree-construction time and linear search time.
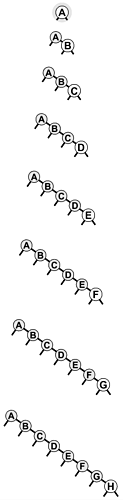
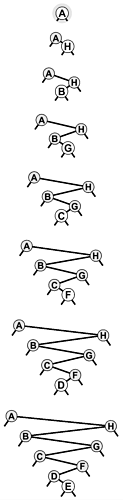
Figure 12.12. Another worst-case BST
Many other key insertion orders, such as this one, lead to degenerate BSTs. Still, a BST built from randomly ordered keys is likely to be well balanced.
Thus, good performance of the basic BST implementation of symbol tables is dependent on the keys being sufficiently similar to random keys that the tree is not likely to contain many long paths. Furthermore, this worst-case behavior is not unlikely in practice it arises when we insert keys in order or in reverse order into an initially empty tree using the standard algorithm, a sequence of operations that we certainly might attempt without any explicit warnings to avoid doing so. In Chapter 13, we shall examine techniques for making this worst case extremely unlikely and for eliminating it entirely, making all trees look more like best-case trees, with all path lengths guaranteed to be logarithmic.
None of the other symbol-table implementations that we have discussed can be used for the task of inserting a huge number of random keys into a table, then searching for each of them the running time of each of the methods that we discussed in Sections 12.3 through 12.4 goes quadratic for this task. Furthermore, the analysis tells us that the average distance to a node in a binary tree is proportional to the logarithm of the number of nodes in the tree, which gives us the flexibility to efficiently handle intermixed searches, insertions, and other symbol-table ADT operations, as we shall soon see.
Table 12.2 gives empirical results that support the analytic results that we have been examining and demonstrates the utility of BSTs for dynamic symbol tables with random keys.
Exercises
12.70 Write a recursive program that computes the maximum number of comparisons required by any search in a given BST (the height of the tree).
12.72 Give an insertion sequence for the keys E A S Y Q U E S T I O N into an initially empty BST such that the tree produced is equivalent to binary search, in the sense that the sequence of comparisons done in the search for any key in the BST is the same as the sequence of comparisons used by binary search for the same set of keys.
12.74 Draw all the structurally different BSTs that can result when N keys are inserted into an initially empty tree, for 2
N
12.75 Find the probability that each of the trees in Exercise 12.74 is the result of inserting N random distinct elements into an initially empty tree.
Table 12.2. Empirical study of symbol-table implementations
This table gives relative times for constructing a symbol table, then doing a (successful) search for each of the keys in the table. BSTs provide fast implementations of both search and insertion; all the other methods require quadratic time for one of the two tasks and therefore cannot be used for huge problems. Binary search is generally slightly faster than BST search and is therefore the method of choice for applications where the number of searches far exceeds the number of entries in the table. The price for using binary search is the cost of presorting the table (and linear-time insertion cost afterwards); the price for using BSTs is the space for the links.
construction
search hits
N
A
L
B
T
A
L
B
T
1250
0
81
90
4
123
250
5
6
2500
0
291
356
8
457
977
9
11
5000
1
1260
1445
19
1853
4077
18
24
12500
2
10848
10684
53
12749
34723
54
69
25000
169
174
50000
407
431
100000
900
995
200000
2343
2453
Key:
A Unordered array (Exercise 12.24)
L Ordered linked list (Exercise 12.25)
B Binary search (Program 12.10)
T Binary search tree (Program 12.15)
12.78 Run empirical studies to compute the average and standard deviation of the number of comparisons used for search hits and for search misses in a binary search tree built by inserting N random keys into an initially empty tree, for N = 103, 104, 105, and 106.
12.79 Write a program that builds t BSTs by inserting N random keys into an initially empty tree, and that computes the maximum tree height (the maximum number of comparisons involved in any search miss in any of the t trees), for N = 103, 104, 105, and 106 with t = 10, 100, and 1000.
12.80 Suppose that items are primitive types that are keys. Develop a BST implementation that represents the BST with three arrays (preallocated to the maximum size given in the constructor): one with the keys, one with array indices corresponding to left links, and one with array indices corresponding to right links. Compare the performance of your program with that of the standard implementation, using one of the drivers in Exercise 12.27 or Exercise 12.28.
12.81 Modify our BST implementation (Program 12.15) to implement your interface from Exercise 12.50 for using indices into client arrays (see Exercise 12.7). Compare the performance of your program with that of the standard implementation, using one of the drivers in Exercise 12.27 or Exercise 12.28.
| Top |
EAN: 2147483647
Pages: 158
- Chapter II Information Search on the Internet: A Causal Model
- Chapter VI Web Site Quality and Usability in E-Commerce
- Chapter XIII Shopping Agent Web Sites: A Comparative Shopping Environment
- Chapter XVI Turning Web Surfers into Loyal Customers: Cognitive Lock-In Through Interface Design and Web Site Usability
- Chapter XVII Internet Markets and E-Loyalty