12.3 Sequential Search
For general key values from too large a range for them to be used as indices, one simple approach for a symbol-table implementation is to store the items contiguously in an array, in order. When a new item is to be inserted, we put it into the array by moving larger elements over one position as we did for insertion sort; when a search is to be performed, we look through the array sequentially. Because the array is in order, we can report a search miss when we encounter a key larger than the search key. Moreover, since the array is in order, both select and sort are trivial to implement. Program 12.8 is a symbol-table implementation that is based on this approach.
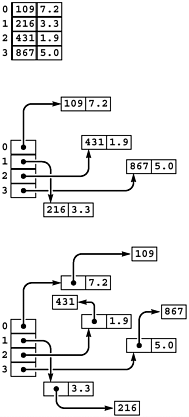
It is worthwhile to revisit the issue of item and key representation. While we do so in the context of this specific implementation, the same issues arise in most other implementations. To be specific, suppose that we have a symbol table whose records are integer keys with associated floating-point numbers (as in our example in Program 12.3). When we use the ADTs of Program 12.1, we need two references to access each key, as depicted at the bottom in Figure 12.1. These references may be no problem in an application that involves thousands of searches on thousands of keys but may represent excessive cost in an application that involves billions of searches on millions of keys. As discussed in Section 12.1, it is not difficult to use a primitive type instead of KEY, which saves one reference per item, as depicted in the center in Figure 12.1. When the associated information is also primitive (or there is none), we can use parallel arrays, with no references, as depicted at the top in Figure 12.1. This arrangement would involve changing our interfaces and implementations to accept primitive-type parameters for both keys and associated information (see Exercise 12.20). Such improvements can have substantial effects in performance-critical applications, and they apply to most of the symbol-table implementations that we will consider. We use the separate ITEM and KEY abstractions to express our algorithms with more precision and because they are quite useful in practical situations that involve complicated records and keys, which are common.
Figure 12.1. Item and key object representations
This diagram depicts Java representations for ordered-array symbol tables of records with integer keys and floating-point associated information, using three different representations for the records: parallel arrays (top); an item class with two primitive-type fields (center); and an item class that uses a key class (bottom). A fourth option, where the associated information is also an object type, is not shown.
We could slightly improve the inner loop in the implementation of search in Program 12.8 by using a sentinel to eliminate the test for running off the end of the array in the case that no item in the table has the search key. Specifically, we could reserve the position after the end of the array as a sentinel, then fill its key field with the search key before a search. Then the search loop will always terminate with an item containing the search key, and we can determine whether or not the key was in the table by checking whether that item is the sentinel.
Program 12.8 Array-based symbol table (ordered)
Like Program 12.7, this implementation uses an array of items, but it does not require the keys to be small integers. We keep the array in order when inserting a new item by moving larger items to make room, in the same manner as insertion sort. Then, the search method can scan through the array to look for an item with the specified key, returning null when encountering an item with a larger key. The select method is trivial, and the implementations of remove and toString are left as an exercise (see Exercise 12.18).
class ST { private boolean less(KEY v, KEY w) { return v.less(w); } private boolean equals(KEY v, KEY w) { return v.equals(w); } private ITEM[] st; private int N = 0; ST(int maxN) { st = new ITEM[maxN]; } int count() { return N; } void insert(ITEM x) { int i = N++; KEY v = x.key(); while (i > 0 && less(v, st[i-1].key())) { st[i] = st[i-1]; i--; } st[i] = x; } ITEM search(KEY key) { int i = 0; for ( ; i < N; i++) if (!less(st[i].key(), key)) break; if (i == N) return null; if (equals(key, st[i].key())) return st[i]; return null; } ITEM select(int k) { return st[k]; } } Alternatively, we could develop an implementation where we do not insist that the items in the array be kept in order. When a new item is to be inserted, we put it at the end of the array; when a search is to be performed, we look through the array sequentially. The characteristic property of this approach is that insert is fast but select and sort require substantially more work (they each require one of the methods in Chapters 7 through 10). We can remove an item with a specified key by doing a search for it, then moving the final item in the array to its position and decrementing the size by 1; and we can remove all items with a specified key by iterating this operation. If a handle giving the index of an item in the array is available, the search is unnecessary and remove takes constant time.
Another straightforward option for a symbol-table implementation is to use a linked list. Again, we can choose to keep the list in order, to be able to easily support the sort operation, or to leave it unordered, so that insert can be fast. Program 12.9 is an implementation of the latter. As usual, the advantage of using linked lists over arrays is that we do not have to predict the maximum size of the table in advance; the disadvantages are that we need extra space (for the links) and we cannot support select efficiently.
The unordered-array and ordered-list approaches are left for exercises (see Exercise 12.24 and Exercise 12.25). These four implementation approaches (array or list, ordered or unordered) could be used interchangeably in applications, differing only (we expect) in time and space requirements. In this and the next several chapters, we will examine numerous different approaches to the symbol-table implementation problem.
Keeping the items in order is an illustration of the general idea that symbol-table implementations generally use the keys to structure the data in some way to provide for fast search. The structure might allow fast implementations of some of the other operations, but this savings has to be balanced against the cost of maintaining the structure, which might be slowing down other operations. We shall see many examples of this phenomenon. For example, in an application where the sort operation is needed frequently, we would choose an ordered (array or list) representation because the chosen structure of the table makes the sort operation trivial, as opposed to it needing a full sort implementation. In an application where we know that the select operation might be performed frequently, we would choose an ordered array representation because this structure of the table makes select constant-time. By contrast, select takes linear time in a linked list, even an ordered one.
Program 12.9 Linked-list based symbol table (unordered)
This implementation of construct, count, search, and insert uses a singly linked list with each node containing an item with a key and a link. The insert method puts the new item at the beginning of the list and takes constant time. The search member method uses a private recursive method searchR to scan through the list.
The private equals method is the same as in Program 12.8 and is omitted. Implementations of the select and sort operations are also omitted because this data structure does not support efficient implementations of those operations, and remove is left as an exercise (see Exercise 12.22).
class ST { private class Node { ITEM item; Node next; Node(ITEM x, Node t) { item = x; next = t; } } private Node head; private int N; ST(int maxN) { head = null; N = 0; } int count() { return N; } void insert(ITEM x) { head = new Node(x, head); N++; } private ITEM searchR(Node t, KEY key) { if (t == null) return null; if (equals(t.item.key(), key)) return t.item; return searchR(t.next, key); } ITEM search(KEY key) { return searchR(head, key); } public String toString() { Node h = head; String s = ""; while (h != null) { s += h.item + "\n"; h = h.next; } return s; } } To analyze the performance of sequential search for random keys in more detail, we begin by considering the cost of inserting new keys and by considering separately the costs of successful and unsuccessful searches. We often refer to the former as a search hit, and to the latter as a search miss. We are interested in the costs for both hits and misses, on the average and in the worst case. Strictly speaking, our ordered-array implementation (see Program 12.8) uses two comparisons for each item examined (one equal and one less). For the purposes of analysis, we regard such a pair as a single comparison throughout Chapters 12 through 16, since we normally can effectively combine them into a three-way comparison (see, for example, Program 12.14).
Property 12.2
Sequential search in a symbol table with N items uses about N/2 comparisons for search hits (on the average).
See Property 2.1. The argument applies for arrays or linked lists, ordered or unordered. 
Property 12.3
Sequential search in a symbol table of N unordered items uses a constant number of steps for inserts and N comparisons for search misses (always).
These facts are true for both the array and linked-list representations and are immediate from the implementations (see Exercise 12.24 and Program 12.9).
Property 12.4
Sequential search in a symbol table of N ordered items uses about N/2 comparisons for insertion, search hits, and search misses (on the average).
See Property 2.2. Again, these facts are true for both the array and linked-list representations and are immediate from the implementations (see Program 12.8 and Exercise 12.8).
Building an ordered table by successive insertion is essentially equivalent to running the insertion-sort algorithm of Section 6.4. The total running time to build the table is quadratic, so we would not use this method for large tables. If we have a huge number of search operations in a small table, then keeping the items in order is worthwhile, because Properties 12.3 and 12.4 tell us that this policy can save a factor of 2 in the time for search misses. If items with duplicate keys are not to be kept in the table, the extra cost of keeping the table in order is not as burdensome as it might seem, because an insertion happens only after a search miss, so the time for insertion is proportional to the time for search. On the other hand, if items with duplicate keys may be kept in the table, we can have a constant-time insert implementation with an unordered table. The use of an unordered table is preferred for applications where we have a huge number of insert operations and relatively few search operations.
Beyond these differences, we have the standard tradeoff that linked-list implementations use space for the links, whereas array implementations require that the maximum table size be known ahead of time or that the table undergo amortized growth (see Section 14.5). Also, as discussed in Section 12.9, a linked-list implementation has the flexibility to allow efficient implementation of other operations such as join and remove.
Table 12.1 summarizes these results and puts them in context with other search algorithms discussed later in this chapter and in Chapters 13 and 14. In Section 12.4, we consider binary search, which brings the search time down to lg N and is therefore widely used for static tables (when insertions are relatively infrequent).
In Sections 12.5 through 12.9, we consider binary search trees, which have the flexibility to admit search and insertion in time proportional to lg N, but only on the average. In Chapter 13, we shall consider red-black trees and randomized binary search trees, which guarantee logarithmic performance or make it extremely likely, respectively. In Chapter 14, we shall consider hashing, which provides constant-time search and insertion, on the average, but does not efficiently support sort and some other operations. In Chapter 15,we shall consider the radix search methods that are analogous to the radix sorting methods of Chapter 10; in Chapter 16, we shall consider methods that are appropriate for files that are stored externally.
| The entries in this table are running times within a constant factor as a function of N, the number of items in the table, and M, the size of the table (if different from N), for implementations where we can insert new items without regard to whether items with duplicate keys are in the table. Elementary methods (first four lines) require constant time for some operations and linear time for others; more advanced methods yield guaranteed logarithmic or constant-time performance for most or all operations. The N lg N entries in the column for select represent the cost of sorting the items a linear-time select for an unordered set of items is possible in theory but is not practical (see Section 7.8). Starred entries indicate worst-case events that are extremely unlikely. | ||||||
| worst case | average case | |||||
| insert | search | select | insert | search hit | search miss | |
| key-indexed array | 1 | 1 | M | 1 | 1 | 1 |
| ordered array | N | N | 1 | N/2 | N/2 | N/2 |
| ordered linked list | N | N | N | N/2 | N/2 | N/2 |
| unordered array | 1 | N | N lg N | 1 | N/2 | N |
| unordered linked list | 1 | N | N lg N | 1 | N/2 | N |
| binary search | N | lg N | 1 | N/2 | lg N | lg N |
| binary search tree | N | N | N | lg N | lg N | lg N |
| red black tree | lg N | lg N | lg N | lg N | lg N | lg N |
| randomized tree | N* | N* | N* | lg N | lg N | lg N |
| hashing | 1 | N* | N lg N | 1 | 1 | 1 |
Exercises
12.18 Complete our ordered-array based symbol-table implementation (Program 12.8) by adding implementations of remove and toString. (Since the table is ordered, toString can put the items in order of their keys.)
12.20 Write a symbol-table ADT interface for an application that needs to associate floating-point numbers with integer keys.
12.21 Write an implementation of your interface from Exercise 12.20 that uses two arrays (an ordered array of ints and a parallel array of doubles) and no references.
12.22 Implement a remove (by key) operation for our list-based symbol-table implementation (Program 12.9).
12.23 Give the number of comparisons required to put the keys E A S Y Q U E S T I O N into an initially empty table using ADTs that are implemented with each of the four elementary approaches: ordered or unordered array or list. Assume that a search is performed for each key, then an insertion is done for search misses, as in Exercise 12.19.
12.24 Implement the construct, search, and insert operations for the symbol-table interface in Program 12.5, using an unordered array to represent the symbol table. Your program should match the performance characteristics set forth in Table 12.1.
construct, search, insert, select, and sort operations for the symbol-table interface in Program 12.5, using an ordered linked list to represent the symbol table. Your program should meet the performance characteristics set forth in Table 12.1.
12.28 Write a performance driver program that uses insert to fill a symbol table, then uses search such that each item in the table is hit an average of 10 times and there is about the same number of misses, doing so multiple times on random sequences of keys of various lengths ranging from small to large; measures the time taken for each run; and prints out or plots the average running times.
12.29 Write an exercise driver program that uses the methods in our symbol-table interface Program 12.5 on difficult or pathological cases that might turn up in practical applications. Simple examples include files that are already in order, files in reverse order, files where all keys are the same, and files consisting of only two distinct values.
12.34 Write a driver program for self-organizing search methods that uses insert to fill a symbol table with N keys, then does 10N searches to hit items according to a predefined probability distribution.
12.35 Use your solution to Exercise 12.34 to compare the running time of your implementation from Exercise 12.24 with your implementation from Exercise 12.32, for N = 10, 100, and 1000, using the probability distribution where search hits the ith largest key with probability 1/2i for 1
i
12.36 Do Exercise 12.35 for the probability distribution where search hits the ith largest key with probability 1/(iHN) for 1
12.37 Compare the move-to-front heuristic with the optimal arrangement for the distributions in Exercises 12.35 and 12.36, which is to keep the keys in increasing order (decreasing order of their expected frequency). That is, use Program 12.8, instead of your solution to Exercise 12.24, in Exercise 12.35.
| Top |
EAN: 2147483647
Pages: 158