11.3 Sorting In Place
The following amusing problem is a useful model for a variety of sorting applications. Suppose that a single driver is given the task of rearranging a sequence of trucks, which are parked in a single line, into some specified order. For example, we might imagine that the trucks arrive at a distribution center in some arbitrary order in the evening, but they need to go out in a specific order in the morning. If there is another place to park all the trucks, the task is easy: the driver just finds the first truck, drives it to the first position, finds the second truck, drives it to the second position, and so forth. However, we can easily imagine that extra space for parking all the trucks is not available. How is the driver to proceed?
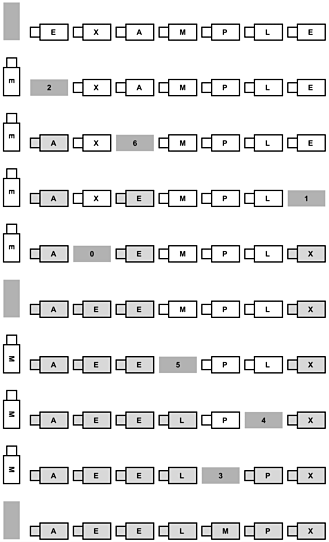
Figure 11.12 illustrates a way to solve this problem that uses just one extra parking place. The driver moves the first truck to the extra place, then finds the truck that goes into the place vacated, and so forth, continuing until vacating the place where the first truck belongs, whereupon the driver gets that truck and puts it in the space. This process may not get all the trucks moved, but the driver can find any truck that needs to be moved and repeat the same procedure, continuing until all the trucks have been moved.
Figure 11.12. Rearranging in place
This sequence shows how a single driver might rearrange a row of trucks so that they are in order, using a single extra parking place. The first step is to move the first truck (the first one labeled E, in parking place 0) to the extra place, leaving an empty space at parking place 0 (second from top). In the figure, this space is labeled with the number of the space where the truck that belongs there can be found: in this case, the truck labeled A is in parking place 2. Next, the driver moves that truck from place 2 to place 0, leaving an empty space at 2. All trucks that have been moved are marked as such (shaded gray in the figure). Now, place 2 has a label telling the driver to go to place 6 to get the other truck labeled E and bring it to place 2 and so forth. After that, the driver moves the truck labeled X from place 1 to place 6 and finds that place 1 is to be filled with the truck that was at 0, which is the truck in the extra space (the driver knows to go to the extra space because the truck at 0 is marked as already having been moved). Next, the driver finds the leftmost truck that has not been moved, moves it to the extra space, and follows the same procedure. All trucks move in and out of their places just once; some of them spend time in the extra parking place.
Problems like this arise frequently in sorting applications. For example, many external storage devices have the property that accessing data sequentially is far more efficient than random access, so we often find ourselves rearranging data so that it may be more efficiently accessed. To fix ideas, suppose that we have a disk with a large number of large blocks of data and that we know we have to rearrange the blocks because we want to scan through them repeatedly in some specific order. If the disk is filled with the data and we do not have another one available, we have no choice but to rearrange the blocks "'in place." Reading a block from disk into memory corresponds to parking a truck in the extra space, and reading one block and writing its contents at another position corresponds to moving a truck from one parking place to another.
To implement this process, we will use Disk and Block abstractions whose implementation, while straightforward, depend on characteristics of particular devices and are omitted. We assume that a Disk is an indexed sequence of N disk blocks whose contents are Blocks, and that the Disk class has a member method read that takes an integer index parameter and returns a Block with the contents of the indexed disk block and a member method write that takes an index and a Block as parameters and writes the contents of the Block to the indexed disk block. We also assume that the Block class has a member method key that returns a sort key for the block.
As already noted in Section 6.6, one way to solve this problem is to use selection sort. This would correspond to our driver moving the truck in the first parking place to the extra place, then moving the truck with the smallest key to the first place, then moving the truck in the extra place to the place vacated, and so forth. This method is less attractive than the one depicted in Figure 11.12 because it requires substantially more driving, since every move involves driving a new truck to the extra place, while we expect to move relatively few trucks to the extra place in the method depicted in Figure 11.12 (see Exercise 11.44). More important, we have not discussed how the driver finds the truck that he needs. For selection sort, with a very long line of trucks, we might imagine that the driver will be spending a substantial amount of time walking down the row of trucks looking for the one with the smallest key. In our disk-sorting problem, this corresponds to a running time quadratic in the number of blocks, which may be unacceptable.
The sorting process divides into two steps: first we must compute, for each place, the index of the block that belongs there; then we must actually do the specified rearrangement.
We can use any of our sorting algorithms for the first task, as follows: Define a class Item that implements our ITEM interface (see Section 6.2) with two fields: an index and a key. Then, create an array p of N items and initialize it (by scanning through all the blocks on the disk) by setting the index field of p[i] to i and the key field of p[i] to the key of the ith disk block. We assume that we have enough room in memory for such an array; if not, then the external sorting methods introduced in Section 11.4 apply. Now, if we define the less method to be
boolean less(ITEM w) { return this.key < ((Item) w).key; } we can use any of the sorting methods that we have discussed (quicksort, for example) to sort the index items. After the sort, the index field of p[0] is the index of the disk block with the smallest key, p[1] gives the index of the data item with the second smallest key, and so on. That is, these index numbers are none other than the numbers shown in Figure 11.12, which tell the driver where to put each truck.
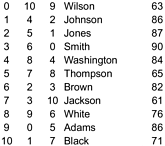
For some applications, this process is all that we need, since we can achieve the effect of sorting by accessing the keys through the indices, as we do for any Java sort where we rearrange references to objects. Also, we have the flexibility to maintain multiple different sorted index arrays on the same data base, as illustrated in Figure 11.13.
Figure 11.13. Index sorting example
By manipulating indices rather than the records themselves, we can sort an array simultaneously on several keys. For this sample data that might represent students' names and grades, the second column is the result of an index sort on the name, and the third column is the result of an index sort on the grade. For example, Wilson is last in alphabetic order and has the tenth highest grade, while Adams is first in alphabetic order and has the sixth highest grade.
A rearrangement of the N distinct nonnegative integers less than N is called a permutation in mathematics: an index sort computes a permutation. In mathematics, permutations are normally defined as rearrangements of the integers 1 through N; we shall use 0 through N - 1 to emphasize the direct relationship between permutations and Java array indices.
The cost of the sort is the space for the array of index items, the time to scan through the N records to get the keys, and the time proportional to N log N to do the index sort. The sort cost is typically dwarfed by the cost of scanning through all the disk blocks, so the process amounts to a linear-time sort. If the keys are huge, we might use an ITEM implementation that goes to disk for every key access, but this would increase the number of disk reads by a factor of log N, which is substantial (see Exercise 11.40).
Now, back to the problem at hand: How do we rearrange a file that has been sorted with an index sort? We cannot blindly copy the contents of the block at position p[i] into position i, because that would prematurely overwrite the block currently at position i. In our truck-parking scenario, this observation just amounts to noting that we cannot move a truck from position p[i] to position i without first moving the truck out of position i. If we have extra room sufficient for another copy of all the data (say, for example, on another disk), then the task is simple; if not, we need to implement a method that imitates the process depicted in Figure 11.12.
Program 11.5 is such an implementation. It uses a single pass through the file, and just enough space to save the contents of one block. The main loop scans to find the next position i that a block needs to be moved to (from position p[i], which is not equal to i). Then it saves the contents of block i in B and works through the cycle, moving the block in position p[i] to position i, moving the block in position p[p[i]] to position p[i], moving the block in position p[p[p[i]]] to position p[p[i]], until reaching the index i again, when B can be written into the place vacated by the last block moved. Continuing in this way, the entire file is rearranged in place, reading and writing each block only once (see Figure 11.14).
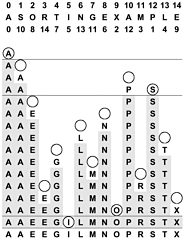
Figure 11.14. In-place rearrangement
To rearrange an array in place, we move from left to right, moving elements that need to be moved in cycles. Here, there are four cycles: The first and last are single-element degenerate cases. The second cycle starts at 1. The S goes into a temporary variable, leaving a hole at 1. Moving the second A there leaves a hole at 10. This hole is filled by P, which leaves a hole at 12. That hole is to be filled by the element at position 1, so the re-served S goes into that hole, completing the cycle 1 10 12 that puts those elements in position. Similarly, the cycle 2 8 6 13 4 7 11 3 14 9 completes the sort.
Program 11.5 In-place rearrangement
This function rearranges a set of N abstract Blocks on an abstract Disk in place, as directed by the index array p[0], ... , p[N-1],using read and write member functions that are supposed to manage the transfer of block contents from and to the disk. For all indices i, the block that is in position p[i] at the beginning of the process is moved (by reading and then writing its contents) to be in position i at the end of the process. Each time that we make such a move, we set p[i] to i, which means that the block is in place and does not need to be touched again.
Starting at the left, the outer loop scans through the array to find a block i that needs to be moved (with p[i] not equal to i). For the inner loop, it saves the contents of the ith block, initializes an index variable k to i and then finds the block to fill the hole in position k (which changes each time through the loop). That block is the one at position p[k] in other words, reading block p[k] and writing to position k puts block k into position p[k] (so we set p[k] to k) and moves the hole to p[k] (so we set k to the old value of p[k]). Iterating, the inner loop is finished when it gets to a situation where the hole needs to be filled by the block at position i, which was saved.
public static void insitu(Disk D, int[] p, int N) { for (int i = 0; i < N; i++) { Block B = D.read(i); int j, k; for (k = i; p[k] != i; k = p[j], p[j] = j) { j = k; D.write(k, D.read(p[k])); } D.write(k, B); p[k] = k; } } This process is called in situ permutation, or in-place rearrangement of the file. Although the algorithm is unnecessary in many applications (because accessing the data indirectly through references often suffices), it is a fundamental computation that is not difficult to im-plement in applications where we want to move things into sorted order without wasting space. For example, we can use the same basic idea to implement, without an auxiliary array, the shuffling and unshuffling operations of Section 11.1 (see Exercise 11.42) and the rearrangement step in key-indexed counting that underlies the radix sorts of Chapter 10 (see Exercise 11.43).
The method described in this section is flexible, easy to implement, and useful in a wide variety of sorting applications, whenever space to hold the index array is available. If the blocks are huge relative to their number, it is slightly more efficient to rearrange them with a conventional selection sort (see Property 6.6). If the number of records is truly huge and we cannot afford to manipulate references to all of them, we are led to a different family of algorithms, which we consider next.
Exercises
11.35 Give the index array that results when the keys E A S Y Q U E S T I O N are index sorted.
11.37 Give examples that minimize and maximize the number of times the driver has to drive a truck to the extra space. (Describe permutations of size N (a set of values for the array p) that maximize and minimize the number of times that the body of the for loop is entered during Program 11.5).

11.41 Prove that we are guaranteed to return to the key with which we started when moving keys and leaving holes in Program 11.5.
Top
EAN: 2147483647
Pages: 158