Implementing Failover
| | ||
| | ||
| | ||
As we discussed in Chapter 15, OPMN works to bring up any failed process within the instance. For example, if you use Unix kill -9 to abruptly kill every OHS process, OPMN will restart those processes. Therefore, you generally don't have to worry about part of an instance failing because OPMN makes sure that the processes are continually available.
Sometimes, however, a process fails and OPMN cannot restart it. Other times the entire instance can fail or otherwise become unreachable, for example, during a network or server problem. In cases like this, OPMN is irrelevant because the entire instance is effectively down. In cases like this there are other processes, like the ones listed here, which are watching the individual members of the cluster to see if they're still alive :
-
OPMN from the other clustered instances and the infrastructure is continually checking the cluster members to determine if the processes are alive. If any component within the instance isn't responding, the entire instance is marked as being down.
-
WC is configured to ping each origin server on a regular basis in order to make sure it's still available. In this case you configured WC to ping each origin server every ten seconds and accept up to three consecutive failures. WC will attempt to ping each origin server every ten seconds and if three pings in a row fail, it will mark that origin server as being down. At that point, all future incoming requests will be routed to the surviving instances. When the origin server that's down becomes available again, it will automatically be eligible to receive requests as before.
Given the role of OPMN and WC monitoring, there are adequate safeguards within 10g AS. You'll know when there's a problem with a cluster member and when to try to fix it. However, in cases in which the problem cannot be fixed from within 10g AS, the software is able to failover to surviving members, as you'll see in the next section.
Failover Test
Now you'll test the loss of the 904mt1 instance and verify that WC will automatically failover requests to the surviving 904mt2 instance. This could be used to simulate the loss of a server, network connection, or a bounce of the 904mt1 instance.
-
Since you know that killing 904mt1 processes will only result in them being automatically restarted by OPMN, the simplest method is just to shut it down cleanly, as follows :
$ opmnctl stopall
-
After a few seconds, both the infrastructure and WC "notice" that 904mt1 is unavailable. This is evident in Figures 21-33 and 21-34.
The Web Cache Manager Health Monitor page shows that the 904mt1 instance is down. Notice that mike.wessler. name :7782 , which is 904mt2 , has processed 21 requests.
-
The real test is to see if future requests to the test Servlet run successfully and if the surviving 904mt2 cluster instance processes them.
-
Issue the HelloWorldServlet request, http://j2eedevcltr1.name/j2ee/servlet/HelloWorldServlet , four more times and in each case it works.
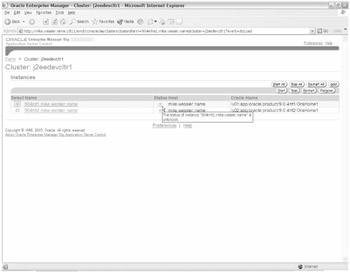
Figure 21-33: The Infrastructure Farm page indicates that the 904mt1 status is unknown.
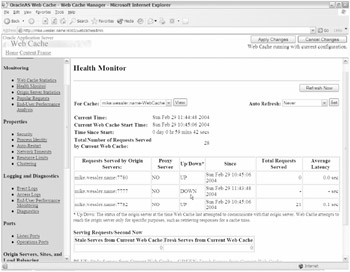
Figure 21-34: The Web Cache Manager indicates that 904mt1 is down.
You can see in Figure 21-35 that the additional requests have successfully been redirected to the surviving 904mt2 cluster instance.
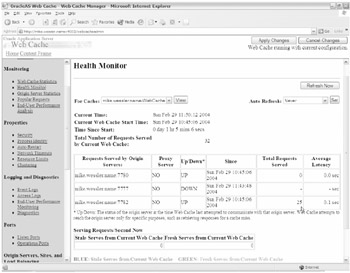
Figure 21-35: The Web Cache Manager indicates 904mt2 is processing all requests.
The total for 904mt2 is now 25 requests with 904mt1 being down. This proves that the http://j2eedevcltr1.name site is still functional even after losing a member of the cluster and that automatic failover by WC is a success.
| | ||
| | ||
| | ||
EAN: 2147483647
Pages: 150