7.12. RAID Level Performance Comparison
| < Day Day Up > |
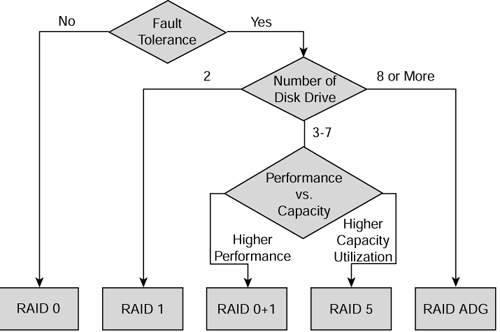
| Figure 7-14 shows a decision tree to assist you in selecting the right level of RAID for your situation. Figure 7-14. RAID level decision tree.
7.12.1 RAID 0RAID 0 shows the best overall performance. However, all data is lost if a single drive in the array fails. No storage space is required for fault tolerance. RAID 0 should not be used in servers. RAID 0 can make sense in workstations that require fast disk access. Data should be backed up as often as possible. 7.12.2 RAID 1 and RAID 1+0RAID 1 or RAID 1+0 is tolerant of multiple drive failures when more than two disks are configured for an array. It uses the most storage capacity for fault tolerance of all the RAID levels. RAID 1 or RAID 1+0 has a higher write performance than RAID 5. 7.12.3 RAID 4RAID 4 should not be used because RAID 5 is faster for reads and writes and offers the same available space and fault tolerance. RAID 4 is supported only in later Smart Array controllers if migrated from older controllers supporting RAID 4. 7.12.4 RAID 5RAID 5 can handle a single drive failure and uses the least amount of storage capacity for fault tolerance. The read performance is almost as good as with RAID 0 and RAID 1. The write performance, however, is usually lower than RAID 1 write performance. 7.12.5 RAID ADGRAID ADG delivers high fault tolerance similar to RAID 1, but keeps capacity utilization high as with RAID 5. RAID ADG protects data from multiple drive failures, but only requires the capacity of two drives to store parity information. This higher level of protection is ideal where large logical volumes, with a large number of physical drives, are required. 7.12.6 RAID Failed Drive Recovery TimeWhen a drive fails, the data recovery time is influenced by the following factors:
If the system is in use during the drive rebuild, recovery time can depend on the level of activity. Most systems should recover in nearly the same amount of time with moderate activity as they would with no load. RAID 1 implementations would be only marginally affected. RAID 5 is much more sensitive to system load during the recovery period because of the considerably heavier I/O requirements of the failed system. ! Important If you are running a mission-critical application that cannot tolerate any outages caused by disk failures, consider using online spare drives supported by HP Smart Array controllers. An online spare is a drive the controller uses when a drive failure occurs. If a drive fails, the controller rebuilds the data that was on the failed drive on the online spare. The controller also sends data that it would normally store on the failed drive directly to the online spare. 7.12.7 Optimizing the Stripe SizeSelecting the appropriate stripe (chunk) size is crucial to achieving optimum performance within an array. The stripe size is the amount of data that is read or written to each disk in the array as data requests are processed by the array controller. Note The terms chunk, block, and segment are used interchangeably. Chunk is used more often when discussing storage. The following table lists the available stripe sizes and their characteristics.
The default stripe size gives good performance in most circumstances. When high performance is important, you may need to modify the stripe size. Using the incorrect stripe size can have one of two negative impacts. If too large, there will be poor load balancing across the drives. If too small, there will be a lot of cross-stripe transfers (split I/Os) and performance will be reduced. Split I/Os involve two disks; both disks seek, rotate, and transfer data. The response time depends on the slowest disk. Split I/Os reduce the request rate because there are fewer drives to service incoming requests.
|
| < Day Day Up > |
EAN: 2147483647
Pages: 278