Implementing Advanced CLR User Defined Types
| I wanted to get you grounded in some fundamental principles before wading into some of the more advanced concepts involving UDTs. Yes, UDTs can be very code-intensive and can introduce a number of more complex issues. As I worked with the typICurrency UDT in this section, I discovered a number of nuances that are not covered in the documentation but are critical to the ability of the UDT to correctly manage the data as intended. Woven into the fabric of this section are the following topics:
For the example in this section, I'm going to start over with another UDT designed to manage international currency values. It's a variation of the code Bill used to demonstrate CLR UDTs in the years leading up to SQL Server 2005's RTM: typICurrency. The folks at Microsoft seem to think it's a good example, toothey implemented a lightweight version of it for their example in the MSDN help topics, but I'm going to take that implementation up a few notches. The typICurrency UDT is designed to manage currency (money) values, where values can be in any currency denomination. For example, typICurrency can store dollars, euros, British pounds, or any currency type in the same column. The UDT keeps track of the currency denomination and other helpful values, like the currency symbol, to make selecting and displaying the data easy. I initially implement this UDT using strings and variable-length datatypes, so I'll have to use custom serialization. User-Defined SerializationBefore long, you're going to outgrow default (Format.Native) serialization. Keep in mind that if your UDT stores values can be persisted as bool, byte, sbyte, short, ushort, int, uint, long, ulong, float, double, SqlByte, SqlInt16, SqlInt32, SqlInt64, SqlDateTime, SqlSingle, SqlDouble, SqlMoney, or SqlBoolean, it's best to simply stick with the default serialization. That is, unless you want to implement custom versioning, which permits UDT data to be identified by version. This way, you can upgrade from one implementation to anotherautomatically morphing the data as you go. I'll show you how to implement custom versioning later in this section. If you use default serialization, you should not (cannot) specify MaxByteSize, and all of the component parts (the fields) of your UDT must be serializable (all of the datatypes mentioned above are serializable). SQL Server also forces you to lay out the items in your UDT structure sequentiallyI saw how to set this order earlier in this chapter. This regimen can seem a bit stifling, and there is a viable alternative: user-defined serialization. Okay, so you want to expose an unsupported type like SqlBinary, SqlString, or some other variable-length public property value in the UDT. This complicates things a bit, as now you have to turn off the autopilot and move your data into and out of SQL Server without benefit of the automatic formatting and serialization. At first, this might feel like your first solo flight in an OH-23 helicopter with 8 hours of trainingbut not nearly as life-threatening. To start with, you'll need to specifically set the following UDT attributes when you first declare your UDT Structure (or struct):
Building the iTypCurrencyV2 UDTOnce your structure attributes are set (which is probably the last thing you'll set after the UDT is written), you need to add the IBinarySerialize Implements annotation, as shown on line 12 of Figure 13.77. This is used to expose the standard interfaces where the Read and Write methods are implemented. These are used to accept and return data from and to SQL Server. Figure 13.77. The attributes and structure declaration for typICurrencyV2.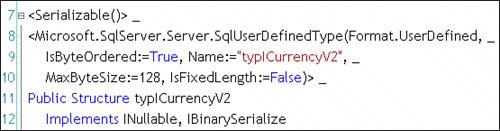
Note that I'm implementing "version 2" of the UDTtypICurrencyV2[18]. Version 1 is a good place for you to start exploring how to code a UDT. Version 2 goes quite a bit farther in the implementation to enable many of the more complex features you might need in a UDT.
The UDT attribute and structure declarations for the new UDT are shown in Figure 13.77.
When you specify which interfaces to implement, be sure to let Visual Studio help you with Intellisense. If you do, Visual Studio automatically adds the implementation prototype routines in your code. The code used in the typICurrencyV2 UDT is different enough that I'm going to step through it section by section to let you see the approach I use at each phase. One aspect of the user-defined (hand-rolled) serialization is that if you aren't careful, the UDT data written to the server tends to consume more memory, more I/O channel capacity, and more disk space. This overhead can consume more resourcesperhaps more resources than the implementation is worth in increased functionality. I coded the UDT to keep the size of the stored data and the amount of code needed to manage it to a minimum. No, writing a serializer is not hard. It might seem daunting at first, as you have to decide what's being written (in binary) to the table column. I'll show you how to inspect what you've written to the column value so you can tune it for size and functionality. Declaring and Parsing the Private VariablesThe private variables declared in the UDT define how the UDT data is stored (temporarily) within the UDT. No, they don't have any bearing on how the data is stored in the database or how it's exposed to consumers (those applications referencing the UDT data). The private variables and the supporting public properties that Set and Get them were templated with the Visual Studio Class Diagram tool. In this case, I chose SqlString variables to manage the currency symbol ("$") and the currency type ("USD") values. I could have used a string for the money value as well, but I wanted to illustrate how to handle a more complex type within the UDT. This implementation (which is different from the "version 1" basic typICurrency implementation) supports a Version property that's used to help morph data from one implementation footprint of the UDT to the next. Version 2 also knows how to recognize version 1 formatting so it can automatically upgrade to version 2 notation. Tip Remember, I discussed each of these UDT support routines earlier in this chapter. Coding the iTypCurrencyV2 ToString FunctionNote that the UDT ToString function implementation uses String.Format to return the string representation of the current UDT private variable stateassuming the UDT IsNull property persisted as m_Null is set to False. Again, this output format does not have to match the input format used when you set the UDT value with the CONVERT statement, but it helps. As a matter of fact, the string you return is not stored anywherejust used to display the contents of the UDT when a SELECT is executed or your code invokes the typICurrencyV2.ToString method directly. Note that the ToString function does not return the Version property. Figure 13.78. Declaring the private variables and the ToString function. The UDT Parse FunctionThe Parse function's job is no different here than when you use default serialization. The primary goal is to convert the string passed from SQL Server and set the private property values. Yes, the Parse should make sure that these values meet minimum validity requirements, and, no, this routine does not do thatit blindly accepts any currency name, symbol, or type and any value. However, for typICurrencyV2, I added a few extra lines of code to deal with an unknown (NULL) currency type and alternate versions. In this implementation, I depend on the CLR Split function to parse the string passed to the Parse function (see Figure 13.79, line 61). This deals with several string-parsing issuesin this case, all I need to do is separate the individual UDT values in the inbound string with a colon (":"). Figure 13.79. The typICurrency Parse function. Coding the IBinarySerialize Read and Write SubroutinesBecause the UDT code is now responsible for serializing the instance data, you need to construct subroutines to convert the private variable data to a data stream (Write) and reconstitute the private variables from that stream (Read). A few random thoughts come to mind here as you define your Read and Write routines:
The UDT Write routine is shown in Figure 13.80. Figure 13.80. Implementing the IBinarySerialize Write routine.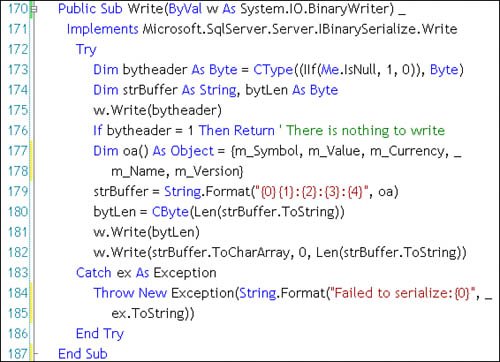 Yes, it's probably best that you design and code the Write routine before starting work on the Read routine. The Read routine (as shown in Figure 13.81) is passed an open BinaryReader accessible via Read methods. Again, I have to test the header to see if the stream is NULL, in which case I simply do nothing. Figure 13.81. The UDT Read routine. Our task in the Read routine is to populate an instance of the typICurrency and fill in the UDT instance private variables. I started by reading the byte containing the length of the persisted stream and follow that by reading the entire stream into a string. Another approach might have been to use the type-specific Read methods to directly populate the individual private variables, but this added unwanted complexity. One benefit of this approach is that I didn't have to repeat the code used to parse the inbound stream (I used the same input string format); I simply instantiated a new instance of the typICurrency class and called the Parse routine to flesh it out. Basically, that's it. As you can see, user-defined serialization is not that complex. I'm now ready to test the new UDT.
Note that all of the routines have their own Try/Catch exception handlers. I found these essential when trying to figure out what part of the UDT code had problems. Testing the typICurrencyV2 UDT
The testing strategy here is no different than for the earlier UDT examples, but the scripts are a bit different[19].
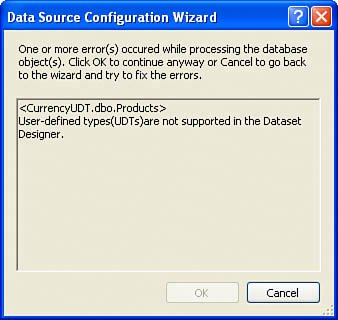
Ah, can I mention a few more points before moving on? Note that that Visual Studio 2005 Data Source Configuration Wizard does not support tables that contain UDTs. No, this is not the end of the world, but it does mean that you won't be able to create strongly typed DataTable or DataSet objects against tables containing UDTsyou'll have to use untyped data structures. And no, you can't use the DataSet designer to build an STD[20], either. SorryI guess it was a bit much to ask. Of course, you can create SQL Views that expose the UDT properties as columns. In this case, much of the code-generator functionality in Visual Studio can be used, but only to create read-only STD structures.
One other tiresome issue is that the Visual Studio IDE and SQL Server Management Studio do not know how to expose the public properties of a CLR UDT. This means that unless those developers being asked to consume the UDT have access to the source code (as if), they won't have any way (outside of using Reflector[21]) to see the private properties you define to access the specific component properties of the UDT. I guess you had best document it and keep the documentation in sync with the deployed version.
Figure 13.82. The Visual Studio Data Source Configuration Wizard chokes on UDTs. |
EAN: 2147483647
Pages: 227