Populating Data Structures
| This section explores the techniques and code needed to populate ADO.NET DataSet, DataTable, Visual Studio 2005generated TableAdapter objects, and custom structures with data without using the row-by-row DataReader Read method. Yes, I've talked about (or around) this before, but I want to take some time to explore the mechanisms behind the scenes so you'll have a better idea of why your application is taking so long to get its job done. I start by discussing application design strategies and how to populate rowsets using the DataAdapter Load and Fill methods, the DataTable Load method, and custom-generated TableAdapter methods introduced with Visual Studio 2005. Because these methods are synchronous (even in the latest versions of Visual Studio), you might want to explore how to run them asynchronously using BackgroundWorker threadsI'll show you how later in this chapter. Efficient Population by DesignPopulation (or, more precisely, rowset population) is the process of moving rows from the server to the client and into ADO.NET (or your own) data structures. These rows are generated by SQL Server in response to one or more SELECT statements executed as queries. Properly handled rowset population can play a significant role in the overall performance and scalability of any applicationregardless of the platform. Yes, if you limit the rows returned by a query, the length of time it takes to populate the client data structures is not significant; however, if your application returns more than a few dozen rows, the impact of population increases proportionately. If you multiply the overhead caused by rowset population on network bandwidth and server CPU and RAM resources by the number of client requests, you can get a better idea of how poorly managed population can pull down scalability and overall performance. By correctly populating your client-side data structures, you can ensure your application performs well and permits other applications sharing the same data to survive. While the techniques used to populate rowsets in a Windows Forms/Smart Client application are similar to those used in ASP, in Web Services, or in business objects, the (good) reasons for doing so are different. Keep in mind that in a Windows Forms application, you have client-side state to manageonce the data is fetched (your client-side rowset objects are populated), the data remains in place. In the other architectures (with the possible exception of business objects), your "client" application should be statelessand cannot depend on persisted rowsets. This means you'll want to save these rowsets in Session state or simply (if one can say that) refetch the rowset state from the server. Regardless of your design, one of the first questions you need to ask before fetching rows is, "Do I really need the rows to be transmitted to my client?" In other words, you need to decide if what you want to do with the rows could be done better, faster, and easier on the server where the rows currently reside. Do you simply want to display the rows to a human and use them in a report, or process the rows and send back changes to the server? In far too many cases, I see applications that bring rows to the client to make (sometimes complex) changes and attempt to update the server with the new data. The rationale for this approach is that some feel that TSQL is not up to the task of making these changes. In actuality, the problem might just be that the developer (that's you) might not have the TSQL skills to make these changes on SQL Server. Don't feel badlots of Visual Studio developers are a few cards light of a full deck when it comes to TSQL coding subtleties. The good news is that it can be possible to perform these changes on the server using a CLR stored procedure. Sure, the CLR code might take a bit longer to run than the TSQL equivalent, but you'll save as much as one or two (expensive) round-trips per row to query, fetch, and replace server-side rows. The next question you need to ask is, "Does the data get stale over time?" Unlike that block of yellow cheese you opened last month (or was it last fall) and stuck back in the bottom drawer of the refrigerator, data does not turn a soft shade of green if it's been sitting around too longat least, I don't think it does. IMHO Generally, fetching lots of data is like buying lots of ice cream on a hot summer dayit's not much good a couple minutes after you get it. If the data you're fetching is relatively static, fetching it and even persisting it locally can make a lot of sense. For example, the list of valid U.S. states has not changed since 1959 when Hawaii joined the Union, and even if Washington, D.C., or Puerto Rico or Iraq are granted statehood, keeping a valid states list in a client-side data structure makes a lot of sense, as it can help applications launch more quickly and reduce network and server overhead. Okay, where should these (relatively) static lists be persisted? If you say "in a JET database," go to the back of the class. However, if you say, "Why not save them to a SQL Server Everywhere database?", you win a free trip to Disneyworld. No matter how you plan to build your application, the design needs to consider the volatility of the data being referenced. If the data does not change over time, (ideally) it should be stored locally, but if it's subject to periodic change, you need to fetch as little as possible. If the data is highly volatile (like airline seat status or stock values), you should consider server-side cursors that permit you to easily query the current (up-to-the-instant) value of the server-side row. In this case, the client code fetches keys (pointers) to the server-side rows you need to monitor and subsequently fetches the current value in a separate operation. Nope, server-side cursors are not directly implemented in ADO.NET (as they are in ADOc)but they are implemented in SQL Server, as I discuss in Appendix IV, "Creating and Managing Server-Side Cursors." This means that you'll still be able to open SQL Server cursors, but you'll be responsible for every aspect of the operations, including creating the cursor, opening it with a SELECT statement, fetching the first (and each row), positioning the current row pointer, detecting EOF (and BOF), and performing update-in-place action commands. Rowset population and this section focus on the rowset(s) returned by the resultset packets generated by SQL Server. In ADO.NET, there are several ways to capture rows being returnedsome are as simple as a single method call like Fill or Load that handles all of the resultsets in a single (synchronous) operation, while others (that I discussed earlier in this chapter) require you to manually loop through each resultset to pick off the rowset column values one at a time. You can also Delegate the responsibility to fetch rows to a "complex" bound control like a DataGridView by binding the DataSource to a DataReader. As discussed earlier in this chapter, if your query execute method returns a DataReader (even asynchronously), you'll have to either fetch the rows (and column values) one at a time or use the new Load method to retrieve your dataI discuss this technique later in this section. Remember, your code must deal with all of the rows that are returned (or queued by SQL Server to be returned). This means that if you ask for 1,000, 10,000, or a bazillion rows, your code will have to accept all of them before being able to use the Connection to ask for anything else. Consider these strategies:
Regardless of how you execute a query, ADO.NET opens a DataReader behind the scenes to return the SQL Servergenerated resultsets to your applicationyes, even the DataAdapter or TableAdapter Fill methods open a DataReader, which requires an open connection to the data source that must remain open (and viable) throughout the rowset population phase. Until all of the rows you've selected are fetched, the server holds (at least) share locks on the rows and possibly database pages, extents, or tables being referenced. Yes, it's possible to use TSQL commands to manage these locks, but that's beyond the scope of this book and can cause other unfortunate side-effects. Because you're holding locks on the selected rows, it's imperative that you fetch the rows as quickly as possible to permit other applications to access and update the shared rows. This means you can't let a user or other synchronous operation interrupt the population process. Yes, this means you should not try to read rows with one connection and update them with another. If you catch yourself (or one of the programs you review) doing this, consider performing the operation on the server in TSQL or in a CLR procedure. IMHO Never let the user delay rowset population while they decide which changes to make. They might just decide to not decide. How Does Population Work?This next section discusses how ADO.NET fetches the results of your queries. If you execute a stored procedure, SQL Server can return several resultsets, each of which can contain the elements shown in Table 11.6.
Each of these resultset elements must be fetched in one or more specific ways, as shown in the table. I'll discuss each of these later in this section. Note that your code needs to fetch these elements in the order in which they're returned by SQL Serveras shown in the table. Sure, the InfoMessage, RASISERROR, and other exceptions can occur at any time, but they won't be sent until the procedure ends. Of course, an exception can end the procedure early or simply be a warning, depending on the error severity. In addition, you won't be able to fetch the OUTPUT parameters until the rowset has been completely transported to the clientreached "EOF". The same is true for the RETURN integer Parameter value. The TDS protocol sends rowsets (if any) back first, followed by PRINT and RAISERROR messages, followed at last by the OUTPUT parameters and the RETURN value. This means you won't be able to access the value of a Parameter object whose Direction property is set to Output, InputOutput, or ReturnValue until the DataReader Read returns False or the DataReader is closed (one way or another). The OUTPUT parameters won't be returned at all if the procedure throws an error. Tip As I've said earlier, it's far more efficient to return a dozen OUTPUT parameters than a single row of data. Populating InfoMessage MessagesSince the earliest days of DB-Library, the InfoMessage has been used to return "informational" messages back to the client application. These include messages generated by SQL Server to report changes in the current catalog (USE statements), changes in language settings, and other system-oriented messages. ADO.NET exposes these in the same way as its predecessorsvia an InfoMessage event. When the TSQL code includes a PRINT statement or executes a RAISERROR with a severity less than 11, the InfoMessage event fires as each message arrives. I set up an example application to illustrate this and try to get a feel for when these events were firing. The code calls a stored procedure that intentionally adds a delay between the PRINT statement to see if the InfoMessage event would fire asynchronously instead of transporting the PRINT strings as they occurit's doesn't. SQL Server caches the PRINT messages while executing the TSQL but does not send them until the final packets of the TDS stream are sentalong with the OUTPUT parameters. The InfoMessage event handler is passed an instance of the SqlInfoMessageEventArgs that contains the source (always "SqlClient.NET Data Provider"), the Message and an instance of the SqlErrorCollection that contains any "warnings" or low-severity (<11) errors that have occurred. More severe errors cause the SqlException exception to fire. However, you can program ADO.NET to re-route user errors in your procedure to the InfoMessage event by setting the Connection FireInfoMessagesEventOnUserErrors property to True (it defaults to False).[7]
The code shown in Figure 11.11 illustrates one (simple) approach to an InfoMessage event handler. It doesn't do much besides displaying the messages and errors in a list boxa practice that's discouraged for a user-interface. Figure 11.11. Capturing PRINT messages and errors in the InfoMessage event handler.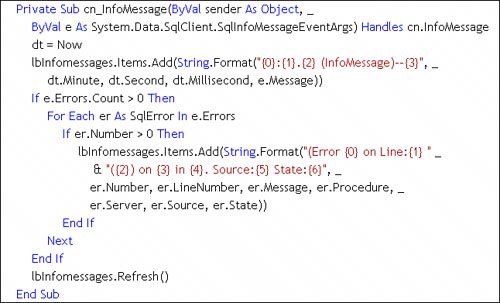 Populating the OUTPUT and RETURN Value ParametersOnce the procedure has completedwhich means after all of the resultsets have been returned in the TDS stream, the PRINT, OUTPUT, and RETURN Value parameter values are returned. Fetching the OUTPUT and RETURN Value parameters is as simple as referencing them once the rowset population is complete (as shown in Figure 11.12). The trick to using OUTPUT parameters is to create a named Parameter object for each and setting the Direction property to ParameterDirection.Output. To trap the RETURN value, set the named Parameter object Direction property to ParameterDirection.ReturnValue. Figure 11.12. Configuring the Parameters Collection, running the query, and capturing the Values.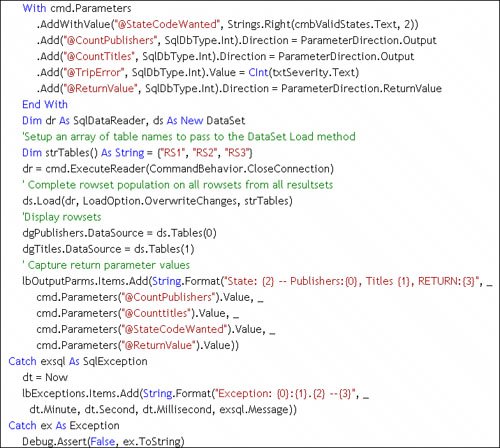 Populating with the DataTable Load MethodIntroduced in ADO.NET 2.0, the DataTable load method constructs a DataTable from a SqlDataReader. This means (for the first time) you can use a lightweight ExecuteReader call to build a data stream and pass this SqlDataReader directly to the Load method. ADO.NET takes it from thereit uses the schema returned in the SqlDataReader and builds a new DataTable (as shown in Figure 11.13[8]). This table can be added to the DataSet Tables collection as is or modified to suit your needs. The DataTable load method also supports a LoadOption that determines how existing rows in the DataTable are treatedoverlaid, merged, or "upserted". Yes, "upsert" seems to be a new word made up by the ADO.NET teamthey must have been sleepy that day. Basically, the Upsert option tells ADO.NET to write the incoming values to the "current" version of the column but not to disturb the "original" value.
Figure 11.13. Using the Load method to populate a DataTable.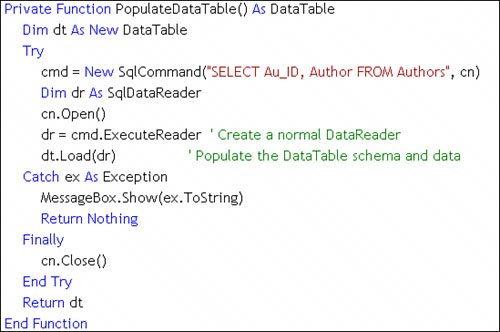 Populating with the DataSet Load MethodAnother addition for ADO.NET 2.0 is the DataSet Load method. It populates a set of DataTable objects using an array of DataTable objects passed to the Load method, which fills each DataTable in the array based on the order of the rowsets returned by the SqlDataReader. In many respects, the Load method is similar to the Fillbut in this case, you build and name the DataTable objects beforehand and use a SqlDataReader to populate the DataTable instances. The example shown in Figure 11.12 illustrates how to build a string array containing the table names and use the DataSet Load method to construct the DataTable objects. When working with multiple resultsets and the DataTable Load method, it's not necessary to call the DataReader NextResult method to step to the next resultsetthat's done automatically, as illustrated in Figure 11.14. This code runs a query that returns three rowsets and places the rowsets in three new DataTable objects created on-the-fly for this purpose. Figure 11.14. Stepping through a multiple-resultset query.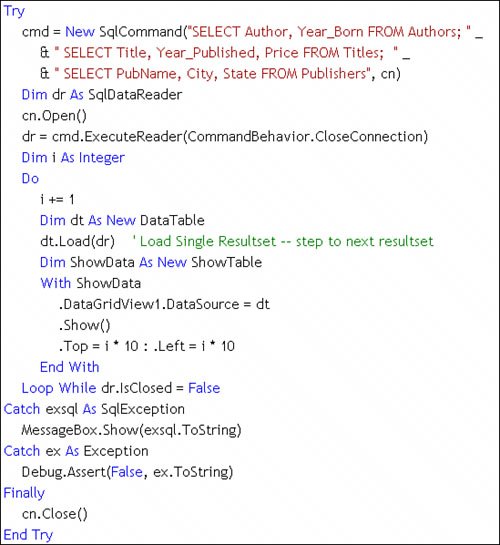 Populating Additional ResultsetsUnless you're using the DataReader, handling multiple resultsets is pretty easythe DataAdapter Fill method automatically builds a DataTable for each of the rowsets returnednot one per resultset (as not all resultsets contain rowsets). On the other hand, the TableAdapter Fill is clueless when you specify a query or call a stored procedure that returns multiple resultsetsafter all, it's a TABLE adapter designed to expose a (single) strongly typed class that maps to a specific rowset. With the 2.0 Framework, even using the DataReader is not as big an issue as beforeas long as you use the DataSet load method to generate the DataTable objects. If you find that you're in a situation where you must handle the DataReader manually, you'll need to invoke the NextResult method to step to the next resultset. Using the Fill Method to Populate DataTable ObjectsThe SqlDataAdapter Fill method executes the SelectCommand and constructs a SqlDataReader behind the scenes. This same approach is used when using a strongly typed TableAdapter and the Visual Studiogenerated Fill method. The GetTable method generated by the TableAdapter works in about the same way. Yes, the Fill and GetTable methods also handle the SqlConnection, automatically opening and closing the connection as needed. The SqlDataReader data stream is used to determine the inbound rowset schema and to construct the Columns collection. If the Fill method is passed a new (unpopulated) DataSet, ADO.NET constructs and populates a new DataTable object for each rowset returned by the SqlDataReader created by the SqlDataAdapter SelectCommand. If you don't specifically set up the SqlDataAdapter TableMappings collection, the first newly constructed DataTable is named "Table"subsequent DataTable objects are named "Table1", "Table2", and so forth. Yes, you can change this "base" name from "Table" to anything that makes sense by passing the name as an argument to the Fill method, but you'll probably want to "map" the database table names to these DataSet DataTable names configuring the SqlDataAdapter TableMappings collection. Using the DataTableMapping object's ColumnMappings collection, you can also map (and rename) inbound rowset columns to DataTable columns. I illustrate how to execute the Fill method in code in Figure 11.15[9]. Note that the SQL executed by the Fill method (the SqlDataAdapter SelectCommand) includes two SELECT statements and that each includes the primary key column(s). I name the "base" table "MyTableName", so "MyTableName" and "MyTableName1" are createdwhich is not any more useful than "Table" and "Table1".
By default, only "column" metadata is added to the new DataTable objects created by the Fill method. This means no attempt is made to identify primary key (PK) column(s) or set any of the DataTable constraint properties. However, if you set the MissingSchemaAction property to AddWithKey, as shown in Figure 11.15, ADO.NET sets these attributesbut only if the PK columns are included in the SELECT. In this case, the Au_ID and ISBN are the PK columns for the Authors and Titles tables, respectively. In addition, if your query is the product of an OUTER JOIN, ADO.NET does not try to set the PKif you need one, your code needs to set the DataTable PrimaryKey property. Figure 11.15. Using the Fill method to construct new DataTable objectsone for each rowset.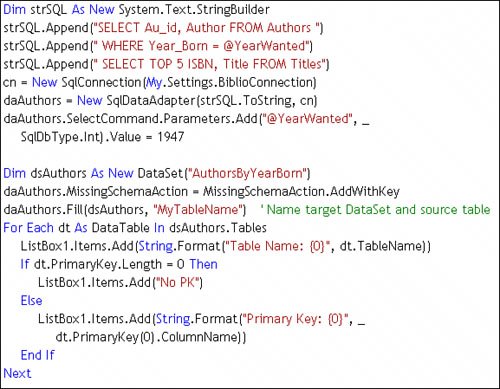 If, on the other hand, a populated DataSet or DataTable is passed to the Fill method, ADO.NET has to make several important decisionsand it needs your help. First, consider that using Fill against populated DataSet or DataTable objects implies that you want to either merge the data or append it. If you don't set up a PK or ask ADO.NET to do so, ADO.NET has no choicenew data is simply appended to the end of the existing data. If a PK is set up, ADO.NET assumes that you want to "merge" the data. Inbound rows are matched up based on the PK and the current data is updated. New rows are appended to the end. Since the inbound schema might not match the DataTable you're populating, ADO.NET has to add any new columns to the DataTable. That's one of the strengths of the DataTableit can be programmatically expanded (or contracted) at any time. The data values for rows that already existed in the DataTable (before you merged in data with new columns) are set to NULL. Hard-Coding Your Own DataTable ObjectsOne code-intensive but appealing approach is to write code to define your DataTable object and append it to an existing DataSet object's Tables collection. Once the DataTable is created, you can also add, change, or remove columnsbefore or after you append it to the Tables collection. Unlike ADOc's Recordset object, the DataTable can be easily modified to fit your current needs. The example[10] shown in Figure 11.16 illustrates the first part of this technique. Here, I construct an array of DataColumn objects that are used to populate the new DataTable Columns collection. This code is made much easier to write because I used an Enumeration to define the table column names and order. I know that specific columns have special properties, so I build a Case statement to set those properties. Notice that the DataTable uses an Identity column whose value is generated automatically by ADO.NET at runtime.
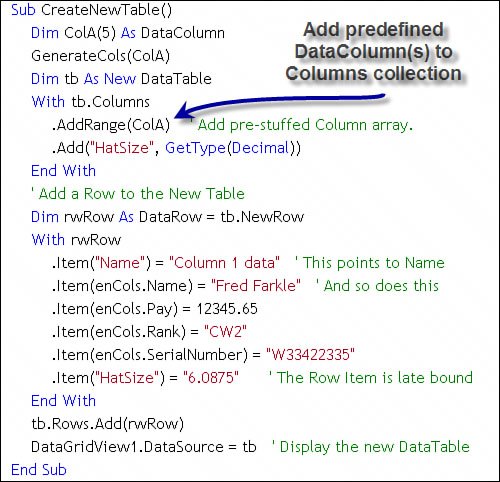
Figure 11.16. Generate an array of DataColumn objects to populate the DataTable Columns collection.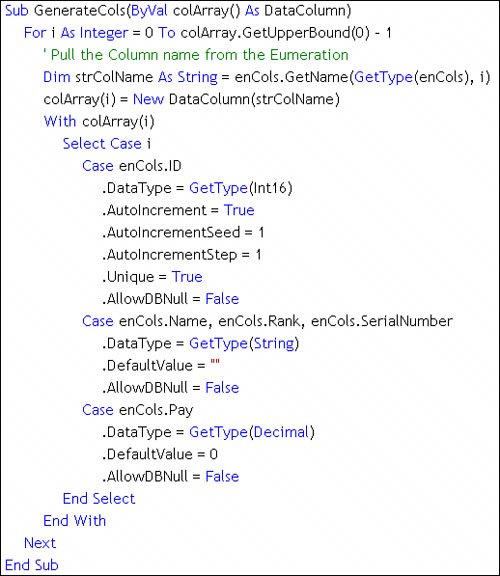 Once the array of DataColumn objects is built, your code populates the Columns collection of a new DataTable object using the Add method, as shown in Figure 11.17. In this case, I use both the AddRange method to add the pre-built array of DataColumn objects created in Figure 11.16 and the Add method, which uses the method arguments to set the name and datatype of the new DataColumn. In the latter case, I would have to visit each DataColumn property individually to make other settings. That's the advantage of using the AddRange methodall of the column definitions can be made in a central location. Once the columns have been defined, I set the initial values for all but the first columnwhich is set automatically, as it's an identity value. Figure 11.17. Creating a DataTable in codesetting the initial values. |
EAN: 2147483647
Pages: 227