5.3 Singleinstancetransaction behavior
|
| < Day Day Up > |
|
In Oracle, a transaction begins when the first executable SQL statement is encountered. This happens when the statement makes a call to the instance and includes any data manipulation language (DML) or data definition language (DDL) operation, or after the SET TRANSACTION command is explicitly issued. However, a transaction ID (TXID) is not allocated until an undo segment and transaction table slot are allocated, which occurs during the first DML statement. SET TRANSACTION only allocates a transaction state object, which is not populated with data until the first DML statement is issued, and a TXID is provided.
When a transaction begins, Oracle assigns the transaction to an undo segment or rollback segment to record the rollback entries for the new transaction and a transaction ends when any of the following occurs:
-
A commit or rollback statement is issued without any SAVEPOINT clause.
-
A DDL statement such as CREATE, DROP, ALTER, etc., is run.
-
The user session with the current transaction is disconnected from Oracle.
-
The user session is abnormally terminated, in which case the transaction is automatically rolled back by Oracle.
When a transaction is committed, the following occurs:
-
The internal transaction table for the associated rollback segment records that the transaction has committed, and the corresponding unique SCN of the transaction is assigned and recorded in the table.
-
The LGWR process writes redo log entries in the SGA's redo log buffers and the transaction's SCN to the online redo log file. The atomic event constitutes the commit of the transaction.
-
Oracle releases all the locks held on rows and tables.
-
Oracle finally marks the transaction as complete.
When a transaction is rolled back either through a regular rollback operation or when a user session is abnormally terminated, the following occurs:
-
Oracle will undo all changes made by all the SQL statements in the transaction by using the corresponding undo or rollback segment.
-
Oracle releases all the transaction's locks held on rows and tables.
-
Oracle ends the transaction by marking it complete/cancelled.
We have looked at the various background processes and the database files that are used by Oracle in Chapter 3 (Oracle database Concepts). When a user process makes a request to the database to perform an operation, almost all the background, foreground, and database files are involved in some form, either directly or indirectly, to complete the operation and to ensure that the operation has completed in a manner to ensure that its atomicity is maintained.
To analyze the transactional behavior of a user request, let us take an example where a user is attempting to modify existing data in the database. This example will help provide a basic overview of a transaction flow.
Figure 5.1 illustrates the process flow of the example being considered to illustrate the transactional behavior in a single instance system.
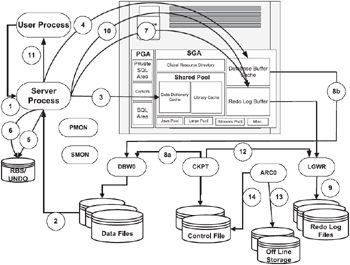
Figure 5.1: Transactional behavior.
It illustrates the involvement of the various background, foreground, and database files in completing a user request:
-
A client workstation or machine running an application in a user process establishes a connection to the server using an Oracle Net service driver. The user process sends the UPDATE statement to the server process with a request to parse or compile the query.
-
During this step of the operation, Oracle has to perform several internal steps with respect to the transaction.
-
A DML operation requires allocation of an undo segment. With an initial rule of thumb to allocate one transaction per undo segment, Oracle performs this operation on a random basis (random number has an upper limit defined by the undo segment number (USN) that has been brought online during instance startup[1]) to even out the distribution. If no suitable undo segment is found, a new number is generated; this process is repeated three times, after which Oracle tries to online an offline undo segment. It then starts its process of looking for undo segments. If this step also fails, that is, there are no more undo segments offline, Oracle tries to create a new segment. This is made online and the search continues. This loop is repeated several times until a point is reached where it is decided (when the undo tablespace is full) that undo segments will have to be shared. At this point Oracle steps down to use the Version 8 algorithm, where the undo segment with the smallest number of active transactions is chosen. Now if this also fails, a round-robin algorithm is used amongst the available undo segments.
-
Once the segment is obtained, Oracle has to create the transaction table. (An output of the segment header dump illustrating the transaction table was discussed in Chapter 4.)
-
Once the undo segment has been obtained and the transaction table has been allocated, Oracle allocates a TXID (transaction ID) for the current transaction.
-
-
After obtaining the TXID, the server process checks the shared pool for any shared SQL area that contains a similar SQL statement. If an SQL statement is found, then the server process checks the user's access privileges for the requested data and the previously existing shared SQL area is used to process the statement for the required data.
-
The blocks read are then placed in the buffer cache and the process places a lock on the data to prevent other users from accessing the same row.
Note More detailed explanation of how Oracle finds an SQL statement in the buffer cache is forthcoming toward the end of this chapter.
The changes are made to the undo segment or redo log buffers with the old value (before image) and the new value (after image), by the server process.
-
The before-image is recorded in the rollback block and updates are made to the data layer of the data block. The rollback block and data block are in the database buffer cache. Since the data in the data block and rollback block are not the same as that found on disk, they are marked as dirty buffers.
Note In the case of an INSERT operation, there is no before-image for the data being inserted. The server process only requires the row location information to be stored in the rollback.
-
Before making the changes, the server process saves the old value into a rollback or undo segment. This is done by the processes to enable an undo operation when the transaction is rolled back, to maintain read consistency, and for database recovery in the case of failure.
-
The changes are recorded in the redo log buffers by the server process. The redo log buffer stores redo records, which record changes in the blocks, the location of the change, and the value being changed.
-
The DBWn process writes the dirty buffers from the database buffer cache to the data files. This writing to the data files is a deferred process and happens when the number of dirty buffers reaches a threshold value, when (a) timeout occurs, or (b) when the server process cannot find enough free blocks.
-
The LGWR writes entries from the redo log buffer into the redo log files. This writing to the redo log files happens when the redo log buffer is one-third full, when a timeout occurs, or when the transaction commits.
-
When the user issues a COMMIT statement, the server process assigns an SCN to the transaction; this is used to synchronize data. The commit record along with the SCN is placed in the redo log buffer.
-
Before allocation of an SCN to the committed record, Oracle verifies if the new value is inferior to a theoretical maximum value based on the hypothesis that there cannot be more than 16,384 commits per second.
-
The transaction table is updated with the current SCN number.
-
The last undo block is placed in the free block pool for reuse by other transactions.
-
The commit times are propagated to the retention tables (to support the undo retention feature introduced in Oracle 9i).
Note SCNs are used for concurrency control, redo log records ordering, and recovery. The SCN base is incremented monotonically for each SCN allocation; however, there may be a jump in the SCN sequence in a distributed or RAC environment.
-
-
The server process records information that the transaction is complete, the resources are released, and the server process sends a message across the network to the application. If it was not successful for some reason, then an error message is transmitted.
-
When any of the requirements of the LGWR are satisfied, the CKPT process requests the LGWR process to make the redo log file switch.
-
If the database is running in ARCHIVE LOG mode, the redo log switch triggers the ARC0 process to make a copy of the redo log file to an offline storage destination. Normally this location is identified by the LOG_ARCHIVE_DEST parameter defined in the parameter file.
-
On successful completion of making a copy of the redo log file to the offline storage, the ARC0 process updates the control file of the specific archive log sequence number.
Throughout the entire procedure, the other background processes run, watching for conditions that require intervention. In addition, the database server manages other user transactions and prevents contention between transactions that request the same data.
If the user had executed a ROLLBACK statement instead of a COMMIT statement:
-
The transaction table is visited and the correct slot is read, using the TXID.
-
The data block address is read from the transaction table, and the last undo block is read (maybe from disk).
-
The beginning undo record for rollback is determined, and the offset is read from the record index.
-
The undo record is read, creating the redo vector to change the data block.
-
The redo record is applied, and the next undo record is found. If there are no more undo records, because a SAVEPOINT has been reached, or the last undo record has been applied, the transaction is considered fully rolled back.
The behavior of a transaction in a single instance configuration is not simple. There are quite a few steps to complete during the entire life cycle. However, all these steps have to be completed precisely and quickly enough to ensure user satisfaction, which includes transactional integrity.
5.3.1 Two-phase commit operation
We looked at handling transactions against a single database, from a single instance. In today's businesses in many cases there exist multiple databases distributed locally or geographically across various parts of the country. A distributed transaction is a transaction that includes one or more statements that update data on two or more distinct nodes of a distributed database. Users are required to perform operations or query data that span multiple databases. These operations could be either DML statements or queries. In the case of DML statements that span multiple databases, it is required to follow the ACID properties. The most prominent among these properties is that either the entire transaction against both the databases is successful when a COMMIT statement is issued or the entire operation fails and it is rolled back. This is called a two-phase commit mechanism.
A two-phase commit mechanism guarantees that all database servers participating in a distributed transaction will either all commit or roll back the transaction. Like any DML operation, the two-phase commit mechanism also protects operations performed by integrity constraints, and remote procedure calls and triggers.
In applications that are written using transaction processing monitors (TPM) or application servers such as Oracle 9iAS, Web logic, Jboss or Tuxedo, Oracle's answer to a two-phase commit mechanism is the XA compliance.[2] It follows the same two-phase protocol consisting of a prepare phase and a commit phase.
In phase one, the prepare phase, the TPM asks each resource manager (RM) to guarantee the ability to commit any part of the transaction. If this is possible, then the RM records its prepared statement and replies affirmatively to the TPM. If it is not possible, then the RM may roll back any work and reply negatively to the TPM, and forget any knowledge about the transaction. This protocol allows the application, or any RM, to roll back the transaction unilaterally until the prepare phase is complete.
In phase two, which is the commit phase, the TPM records the commit decision. Then the TPM issues a commit or rollback to all RMs that are participating in the transaction.
XA
XA is an industry standard interface between a TPM and an RM. An RM is an agent that controls a shared, recoverable resource; such a resource can be returned to a consistent state after a failure. For example, Oracle Server is an RM and uses its redo log and undo segments to be able to do this.
A TPM manages a transaction including the commit protocol and, when necessary, the recovery after a failure. Normally, Oracle Server acts as its own TPM and manages its own commitment and recovery. However, using a standards-based TPM allows Oracle to cooperate with other heterogeneous RMs in a single transaction.
Figure 5.2 is a simplified version to illustrate the XA interface component that acts as a bridge between the transaction manager and the resource managers of the application program.
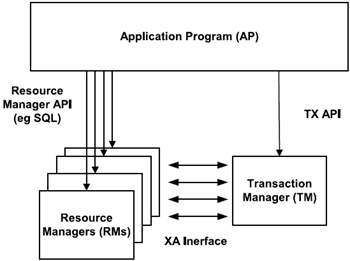
Figure 5.2: XA interface components.
The XA interface is an interface between two system components, not an application program interface. The application program does not write XA calls, nor does it need to know the details of this interface. The TM cannot do transaction coordination without the assistance of the RM; the XA interface is used to get that assistance.
5.3.2 Transaction naming
Transactions inside Oracle are identified by the session and the serial number of the process making the request. With data available in the V$SESSION and the V$TRANSACTION data dictionary views, details of a transaction could be obtained.
| Oracle 9i | New Feature: In Oracle 9i, a new feature is introduced by which a transaction could be directly identified by a name that is provided to it when the transaction is started. This feature replaces the ''commit comment'' feature available in the prior versions of Oracle. |
To assign a name to a transaction, the session should first execute the following statement before the beginning of the transaction:
SET TRANSACTION NAME <name of transaction> E.g., SET TRANSACTION NAME 'SummerSky';
By naming the transaction, the transaction name gets associated with the transaction ID. These names do not have to be unique. Different transactions can have the same transaction name.
This new feature provides considerable benefits:
-
It provides easy visibility of long-running transactions and helps resolve in-doubt distributed transactions.
-
These names are written to the transaction auditing redo record.
-
When using Log Miner to retrieve transactions in the redo logs, these names provide benefits by providing a mechanism for easy search.
-
Transactions could be identified by name in the V$TRANSACTION data dictionary views.
-
If different names are used, it provides the opportunity to distinguish different transactions by the same owner.
5.3.3 Discrete transaction management
This feature of transaction management allows changes made to any data to be deferred until the transaction commits. Using this feature does not generate rollback segment activity like other regular transactions do; however, rollback segments generated are stored in the PGA. These segments are written to the regular rollback segment space only at commit time.
Using the BEGIN_DISCRETE_TRANSACTION procedure enables the discrete transaction feature. This procedure streamlines transaction processing so that short transactions can execute more rapidly.
DBMS_TRANSACTION.BEGIN_DISCRETE_TRANSACTION;
5.3.4 Autonomous transactions
A regular transaction is an activity invoked by a user to perform a certain database operation. This transaction is complete when a commit or rollback statement is issued from within its context. If from within this transaction, i.e., between the time that a statement is processed and before a commit or rollback operation is made, if another transaction is started as a subtransaction independent of the primary transaction it is called an autonomous transaction.
Figure 5.3 illustrates an example of an autonomous transaction. LOG_PROC is another procedure that is called from procedure GET_PRODUCT. GET_PRODUCT contains a transaction that selects rows from the product table, and from this procedure LOG_PROC is called at the beginning and end to insert a row into another table. LOG_PROC handles another transaction that is independent of the transaction handled by GET_PRODUCT,and GET_PRODUCT will wait for LOG_PROC to complete its activities before continuing.
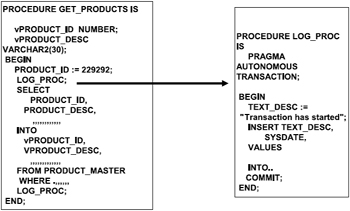
Figure 5.3: Autonomous transaction.
An autonomous transaction starts a new process or transaction that has a different context from the calling transaction, performs some SQL operations, commits or rolls back the operation and then returns to the calling transaction context and continues with that transaction. Such a transaction is totally independent of the main transaction; however, it follows all transactional integrity rules bound by the original transaction. For example, data modified or inserted by the autonomous transaction is not visible to the calling or other transactions unless the data is committed or rolled back. At this point all other transactions could view these changes, while the original or calling transaction has no visibility of this transaction until it commits its current transaction and or starts another.
An autonomous transaction can call another autonomous transaction, causing a nesting of transactions. There is no limit on the number of nested autonomous transactions that could be created. However, care should be provided when using autonomous transactions, as they could cause deadlock errors.
For example, a good usage of an autonomous transactions is when the calling transaction encounters errors, and they need to be written to a table or file while not tying the transactional properties to the main calling transaction.
5.3.5 Transaction isolation levels
A transaction isolation level is the degree to which the intermediate state of the data being modified by a session is visible to other concurrent transactions and the data being modified by other transactions is visible to it. Oracle provides the following isolation levels:
-
Read committed: This is Oracle's default isolation level. Under this level, queries executed by a transaction will only see data that was committed prior to the start of the current transaction. However, since Oracle does not prevent other transactions from modifying the data read by a query, the data retrieved by a transaction could be modified by another transaction.
-
Serializable: This type of isolation level provides visibility of only those changes that were committed at the time that the current transaction began, which includes changes made by the transaction itself through an INSERT, UPDATE, or DELETE operation.
Isolation levels are enabled at the beginning as the first step in a session before the execution of any SQL statement. For example:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
The above statement will start a transaction that only permits read operations against the tables. Isolation levels could be modified or changed midstream by issuing an ALTER statement, for example:
ALTER SESSION SET ISOLATION_LEVEL_READ COMMITTED;
So far we have looked at the various transaction methods, types and behavioral patterns in a single instance configuration of Oracle. While all of these behaviors apply to a multi-instance or a RAC configuration, RAC has certain additional behavioral patterns; this is because more than one instance could potentially participate in a given transaction.
Before we go into the behaviors that are specific to a RAC implementation through various examples, let us look at the lock management and locking architecture followed in a single instance and analyze this further with respect to a RAC configuration.
5.3.6 Lock management
Oracle uses enqueues as a locking mechanism for managing access to shared resources. In the case of an Oracle implementation, be it a single stand-alone configuration or a multi-instance configuration, there is a considerable amount of sharing of resources between sessions. These resources could be a table definition, a transaction, or any type of structure that is shareable between sessions. To ensure that the right sessions get access to these resources based on their needs to utilize these resources and the type of activity being performed, they would require some type of lock or lock mode to be placed on these resources.
For example, a session trying to perform an SQL query like SELECT * FROM PRODUCT will require a shared lock on the PRODUCT table. When a number of sessions try to access the same resource, Oracle will serialize the processing by placing a number of these sessions in a wait mode until the work of the blocking sessions has completed.
Then every session requiring access to these resources has to acquire a lock, and when it has completed the function or operation it has to release the lock. This goes on through every session and every resource on the system. Releasing of locks is performed by the sessions when they issue a commit or through a DDL statement or by the SMON process if the session was killed.
Throughout its operation, Oracle automatically acquires different types of locks at different levels of restrictiveness depending on the resource being locked and the operation being performed. Oracle locks fall into one of the following general categories.
DML locks
These locks protect data. Transactional level row locks are an example of this type of lock. Oracle uses these locks for object level locking during SELECT and DML operations. For example, if a SELECT query has a join between two tables and is using an indexed column in the WHERE clause, then the statement would require a minimum of four locks. If the table were partitioned across three partitions, then the query would require 10 object locks (4 + 3 + 3).
Table 5.1 lists the various lock types and their subtypes with their respective abbreviations. These locks are used during normal DML operations when users issue INSERT, UPDATE, and DELETE statements.
| Lock Type | Subtype | Abbreviation |
|---|---|---|
| Row Locks | TX | |
| Table Locks | TM | |
| Row Share Table Locks | RS | |
| Row Exclusive Table Locks | RX | |
| Share Table Lock | S | |
| Share Row Exclusive Table Locks | SRX | |
| Exclusive Table Locks | X |
DDL locks
DDL locks protect the definition of a schema object while the object is acted upon or referred to by an ongoing DDL operation. For example, if a user is executing a procedure, Oracle will automatically acquire DDL locks on all schema objects referenced in the procedure definition.
Latches and internal locks
Latches are low-level serialization mechanisms to protect shared data structures in the SGA. For example, latches protect the list of users currently accessing the database and protect the data structures.
Internal locks are higher-level more complex mechanisms and serve a variety of purposes. Types of internal locks include:
-
Dictionary cache locks
-
File and log management locks
-
Tablespace and rollback segment locks
Depending on the type of lock requirement, some sessions undergo lock conversion. Lock conversion is allowed if the lock mode required is a subset of the lock mode currently held or is compatible with the lock modes held by other sessions.
Unlike many other databases, Oracle maintains locks at a row level, based on TX enqueues; this is known as transactional locking. When two or more sessions make changes to one row in a table, the first session will place a transaction reference in the block containing the row header. Other sessions will query the lock information and wait on the transaction of the first instance to complete before proceeding. Now when the first session performs a COMMIT operation, the TX resource lock is released and the waiting sessions will start placing a lock on the row.
Table 5.2 describes what lock modes on DML enqueues are actually obtained for which table operations in a standard Oracle installation. It lists the lock modes for each type of DML or DDL operation. How do these DML/DDL operations and the lock modes relate or function in relation to each other? Table 5.3 illustrates the lock mode compatibility matrix. It illustrates how each type of lock is compatible with the other modes.
| Operation | Lock Mode | LMODE | Description |
|---|---|---|---|
| SELECT | NULL | 1 | NULL |
| SELECT FOR UPDATE | SS | 2 | Subshare |
| INSERT | SX | 3 | Subexclusive |
| UPDATE | SX | 3 | Subexclusive |
| DELETE | SX | 3 | Subexclusive |
| LOCK FOR UPDATE | SS | 2 | Subshare |
| LOCK SHARE | S | 4 | Share |
| LOCK EXCLUSIVE | X | 6 | Exclusive |
| LOCK ROW SHARE | SS | 2 | Subshare |
| LOCK ROW EXCLUSIVE | SX | 3 | Subexclusive |
| LOCK SHARE ROW EXCLUSIVE | SSX | 5 | Share/subExclusive |
| ALTER TABLE | X | 6 | Exclusive |
| DROP TABLE | X | 6 | Exclusive |
| CREATE INDEX | S | 4 | Share |
| DROP INDEX | X | 6 | Exclusive |
| TRUNCATE TABLE | X | 6 | Exclusive |
|
[a]Source: http://metalink.oracle.com | |||
| NULL | SS | SX | S | SSX | X | |
|---|---|---|---|---|---|---|
| NULL | YES | YES | YES | YES | YES | YES |
| SS | YES | YES | YES | YES | YES | NO |
| SX | YES | YES | YES | NO | NO | NO |
| S | YES | YES | NO | YES | NO | NO |
| SSX | YES | YES | NO | NO | NO | NO |
| X | YES | NO | NO | NO | NO | NO |
|
[a]Source: http://metalink.oracle.com | ||||||
A RAC implementation is a composition of two or more instances that communicate with a common shared database. Hence all transactional behaviors that apply to a single instance configuration will apply to a RAC implementation.
Apart from the lock management of DML, DDL, latches, and internal locks that apply to a single instance configuration, the lock management in a multi-instance configuration involves management of locks across instances and across the cluster interconnects. Sharing of resources does not happen within a single instance; however, it happens across multiple instances. Another major difference between single instance configuration and a multi- instance configuration is that while row level locks are still maintained and managed at the instance level, when it comes to interinstance locking, the object level is at a much higher level and the locks are held at the block level.
A block contains multiple rows or records of data. Figure 5.4 represents the lock structure and it illustrates the mode, role, and past image indicator. This figure should be familiar from the previous chapter where we discussed these properties of the lock structure.

Figure 5.4: RAC lock structure.
It represents the three-character lock structure in a RAC implementation where:
-
The first character indicates the mode:
N for null
S for shared
X for exclusive
-
The second character indicates the role:
L for local
G for global
-
The third character indicates whether the GRD knows about the PI:
0 for no
1 for yes
Putting these together there are potentially nine types of lock situations.
Table 5.4 lists the various combinations under which the locks could be held in a RAC implementation. Blocks held by a single instance only have a single copy. This holding instance controls its modification and writes the changes to disk. When another instance requests for the same block, its status changes from a local to a global state before the block is transferred to the requesting node. Where one or more other instances contain a copy of the current block, the original instance will keep a PI of the block.
| Chars | Mode | Description |
|---|---|---|
| NL0 | Null Local 0 | Essentially the same as N with no past image |
| SL0 | Shared Local 0 | Essentially the same as S with no past images |
| XL0 | Exclusive Local 0 | Essentially the same as X with no past images |
| NG0 | Null Global 0 | Global N lock and the instance owns a current block image |
| SG0 | Shared Global 0 | Global S lock with no past images |
| XG0 | Exclusive Global 0 | Global X lock with ownership to the block |
| NG1 | Null Global 1 | Global N lock with the instance past image |
| SG1 | Shared Global 1 | Global S lock, with instance owning past image |
| XG1 | Exclusive Global 1 | Global X lock, and instance owns a past image |
[1]Oracle by default brings online 10 undo segments per instance during instance startup.
[2]XA is the standard architecture established for distributed transaction processing by the X/Open transaction processing work group in 1991.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 174