16.4 Critical ORA errors
|
| < Day Day Up > |
|
ORA-600:internal error code, arguments: [...], [...]
An ORA-600 error indicates a kernel exception. When such an error is encountered, Oracle records certain details related to this error in the alert log file and also in a user trace file.
This error message could mean errors in different areas of the Oracle kernel. The actual area is identified by the arguments listed in the error message. For example:
ORA-600: internal error code, arguments: [784], [0x3BE577248], [0x3BE578B88],
For example, in the above ORA-600 error message the first argument 784 indicates that the error is related to the service layer. Similarly, depending on the range that the first argument falls into, the error is grouped under a specific category, as shown in Table 16.1.
| Argument | Layer |
|---|---|
| 0000 | Service layer |
| 2000 | Cache layer component base |
| 4000 | Transaction layer |
| 6000 | Data layer |
| 8000 | Access layer |
| 9000 | Parallel server |
| 10000 | Control layer |
| 12000 | User/Oracle interface layer |
| 14000 | System-dependent layer (port specific) |
| 15000 | Security layer |
| 17000 | Generic layer |
| 18000 | K2 (2-phase commit) |
| 19000 | Object layer |
| 21000 | Replication layer |
| 23000 | OLTP layer |
If an ORA-600 error is encountered, Oracle Support needs to be notified. During the notification process, all related information, including copies of the alert log and trace files referenced in the alert log, needs to be uploaded for Oracle to analyze and provide the appropriate fix.
Before notifying Oracle of the error message, as database administrator, the first step is to determine if others have encountered this error. Such information could be obtained from Metalink. Oracle has provided an ORA-600 error lookup utility that will help in obtaining this.
Figure 16.1 is an input screen for the ORA-600 argument lookup. On selecting the Oracle version and providing the first argument, the lookup will search through Metalink and provide any information that is available on the specific error argument. Based on the message the fix may already be explained.
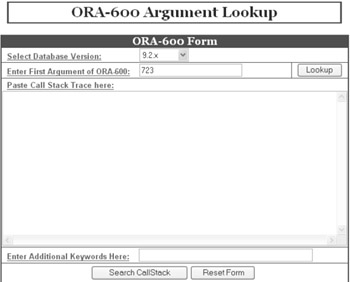
Figure 16.1: Metalink ORA-600 argument lookup.
In certain cases, depending on the type of error and occurrence of the message, information pertaining to the argument may not be available. Under these circumstances a technical assistance request (TAR) is opened with Oracle Support.
The ORA-600 lookup is accessible via Metalink note #1537881.
ORA-7445:exception encountered core dump [...][...]
ORA-7445 is also a critical error; however, the criticality is not grouped at the same level as the ORA-600 errors. The ORA-7445 error indicates that the process may have performed an illegal operation and hence was terminated by the operating system.
Like the ORA-600 error, ORA-7445 also reports arguments to the error message. Unlike the ORA-600 error argument, the ORA-7445 argument is alphanumeric rather than numeric and normally reflects an Oracle-related internal function call.
This error can occur during the following situations:
-
When starting a program, for example SQL*Plus, import, export, etc.
-
Starting a database.
-
While making a connection to the database.
-
During normal database operations, such as a query or DML operation.
-
Shutting down the database.
Steps to take upon an ORA-7445 error:
-
Check alert.log for other errors that are generated with the ORA-7445 message. For example, the following information was generated with an ORA-7445 message: please note the error ORA-00602, which indicates an internal programming exception.
Thu Oct 10 11:16:37 2002 Trace dumping is performing id =[cdmp_20021114111637] Thu Oct 10 11:16:47 2002 Errors in file /apps/admin/PRODDB/RAC2/bdump/ rac2_pmon_3908.trc: ORA-00602: internal programming exception ORA-07445: exception encountered: core dump[0000000101B3F298][SIGSEGV]
This kind of additional information helps Oracle Support to diagnose the problem quickly.
-
Check for Oracle-generated trace files. Oracle generates the trace files in the same directory as the alert log file is generated. In the previous example, rac2_pmon_3908.trc file was generated in the bdump directory.
-
If a trace file wasn't generated, one needs to be produced for Oracle to diagnose the cause of the error. Metalink note#1812.1 explains the process of getting a stack trace from a CORE file.
ORA-3113:end-of-file on communication channel
ORA-3113 is also a common error encountered when a connection to the server is lost. It basically means that the client program is not able to communicate with a shadow process. This error is normally accompanied by one of the following additional errors:
-
ORA-1041: internal error. Hostdef extension doesn't exist.
-
ORA-3114: not connected to Oracle.
-
ORA-1012: not logged on.
-
ORA-1034: Oracle not available.
An ORA-3113 error could be encountered in a RAC implementation when the TAF option is used for failover. This error happens if the tnsnames.ora file does not represent the FAILOVER and LOAD_BALANCING arguments after the ADDRESS_LIST argument. For example:
PRODDB.summerskyus.com = (DESCRIPTION = (ADDRESS_LIST = (FAILOVER =on) (LOAD_BALANCE =on) (ADDRESS =(PROTOCOL =TCP) (HOST =ora-db2.summerskyus.com) (PORT =1521)) (ADDRESS =(PROTOCOL =TCP) (HOST =ora-db1.summerskyus.com) (PORT =1521)) ) (CONNECT_DATA = (SERVICE_NAME =PRODDB.summerskyus.com) (ORACLE_HOME = /apps/oracle/product/9.2.0) (FAILOVER_MODE =(TYPE =SELECT) (METHOD =BASIC) (RETRIES =20) (DELAY =15)) ) )
ORA-1041: internal error. Hostdef extension doesn't exist
The hostdef extension referred to is a structure that is added to the control structure for client/server communication.
It is accessed via a pointer in the original structure. When the communication between the client and the server goes awry, this can result in ORA-1041 and ORA-3113 errors.
ORA-29740:evicted by member string, group incarnation string
An ORA-29740 error occurs when a member is evicted from the group by another member of the cluster database for one of several reasons, which may include a communications error in the cluster, or failure to issue a heartbeat to the control file. This mechanism is in place to prevent problems from occurring that would affect the entire database. For example, instead of allowing a cluster-wide hang to occur, Oracle will evict the problematic instance(s) from the cluster. When an ORA-29740 error occurs, a surviving instance will remove the problem instance(s) from the cluster.
When the problem is detected, the instances ''race'' to get a lock on the control file (results record lock) for updating. The instance that obtains the lock tallies the votes of the instances to decide membership. A member is evicted if:
-
A communications link is down.
-
There is a split-brain (more than one subgroup) and the member is not in the largest subgroup.
-
The member is perceived to be inactive.
The following is a sample message in the alert log of the evicted instance:
Fri Sep 27 17:11:51 2002 Errors in file /apps/oracle/export/PRODDB/lmon_26410_tick2.trc: ORA-29740: evicted by member %d, group incarnation %d Fri Sep 27 17:11:53 2002 Trace dumping is performing id =[cdmp_20010928171153] Fri Sep 27 17:11:57 2002 Instance terminated by LMON, pid = 26410
The key to resolving the ORA-29740 error is to review the LMON trace files from each of the instances. On the evicted instance we will see something like:
Fri Sep 27 17:11:57 2002 kjxgrdtrt: Evicted by 0, seq (3, 2)
This indicates which instance initiated the eviction.
On the evicting instance the following information is reported:
kjxgrrcfgchk: Initiating reconfig, reason 3 Fri Sep 27 17:11:57 2002 kjxgmrcfg: Reconfiguration started, reason 3 ... Fri Sep 27 17:11:57 2002 Obtained RR update lock for sequence 2, RR seq 2 Fri Sep 27 17:11:57 2002 Voting results, upd 0, seq 3, bitmap: 0 Evicting mem 1, stat 0x0047 err 0x0002
From the above information it is clear that the instance initiated a reconfiguration for reason 3. After reconfiguration has started and this instance obtains the RR lock (results record lock), this instance will tally the votes of the instances to decide membership.
In troubleshooting ORA-29740 errors, the ''reason'' will be very important. The possible reasons are as follows:
-
Reason 0 = No reconfiguration.
-
Reason 1 = The node monitor generated the reconfiguration.
-
Reason 2 = An instance death was detected.
-
Reason 3 = Communications failure.
-
Reason 4 = Reconfiguration after suspend.
In the above output, the first section indicated the reason for the initiated reconfiguration. In this case the reason reported was #3, ''communications failure.'' For ORA-29740 errors, the most likely reasons would be 1, 2, or 3.
Reason 1: The node monitor generated the reconfiguration
This can happen if:
-
An instance joins the cluster.
-
An instance leaves the cluster.
-
A node is halted.
It should be easy to determine the cause of the error by reviewing the alert logs and LMON trace files from all instances. If an instance joins or leaves the cluster or a node is halted, then the ORA-29740 error is not a problem.
Reason 2: An instance death was detected
This can happen if an instance fails to issue a heartbeat to the control file. When the heartbeat is missing, LMON will issue a network ping to the instance not issuing the heartbeat. As long as the instance responds to the ping, LMON will consider the instance alive. If, however, the heartbeat is not issued for the length of time of the control file enqueue timeout, the instance is considered to be problematic and will be evicted. This latter scenario is generally not observed, since an ORA-600 [2103] failure will generally occur prior to the eviction.
Reason 3: Communications failure
This can occur where:
-
The LMON processes lose communication between one another.
-
One instance loses communication with the LMD process of another instance.
-
An LMON process is blocked, spinning, or stuck and is not responding to the other instance(s) LMON process.
-
An LMD process is blocked or spinning.
In this case the ORA-29740 error is recorded when there are communication issues between the instances. It is an indication that an instance has been evicted from the configuration when IPC sends a timeout. A communications failure between a foreground, or background processes other than LMON, and a remote LMD will also generate an ORA-29740 with reason 3. When this occurs, the trace file of the process experiencing the error will print a message:
Reporting communication error with instance:
If communication is lost at the cluster layer (e.g., network cables are pulled), the cluster software may also perform node evictions in the event of a cluster split-brain. Oracle will detect a possible split-brain and wait for cluster software to resolve the split-brain. If cluster software does not resolve the split-brain within a specified interval, Oracle proceeds with evictions.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 174