Chapter 7 -- Web Services
The Web as we know it today is built on a series of innovations driven by technology standards created over the past decade or so. As Figure 7-1 illustrates, each innovation built on the successes of the previous one, leading up to the current ability to write network programs that take advantage of data and processes all over the network.
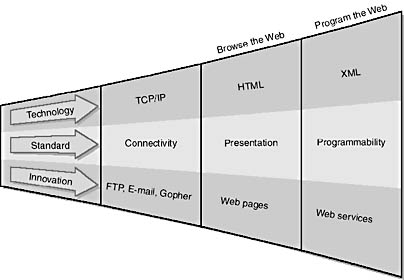
Figure 7-1. The Web as we know it evolved from a series of technological innovations.
In the 1980s, the U.S. Department of Defense (DoD) developed TCP/IP (Transmission Control Protocol/Internet Protocol). TCP/IP is a simple protocol that gave us physical connectivity between proprietary networks by sending packets over a public network. Once networked computers could be connected to each other, applications emerged to take advantage of that capability. The first technologies, File Transfer Protocol (FTP) and e-mail, sit on top of TCP/IP to allow people to communicate. This revolutionized the way we do business.
As good as FTP and e-mail were, they did not provide a way to look at information in a consistent manner with a consistent interface. HTML was designed as a simple tagging structure for creating a pleasing way for users to view information in what we now know as a Web browser. One of the tags in HTML—the "link" tag—created a way to take advantage of the new interconnected network by providing a means of jumping to another point on the page or to another page entirely.
Sharing hyperlinked documents over a public network revolutionized the way we look at information because users could share information in a standard way no matter what operating system platform or software version they used. Now anyone can browse the entire network from a single application.
HTML is an integral technology for communicating information to humans, but it falls short when we want our computers to talk to each other. First of all, HTML is designed to create a two-dimensional presentation of document information for consumption by eyeballs. Computers don't have eyeballs yet, so HTML doesn't do computers much good. HTML forces us to flatten our information to fit on a screen, and it also forces us to leave much interpretation up to our cognitive ability to understand ambiguity.
Think about a travel agent. Her job is to interpret what her clients want to do and come up with a travel package that they will buy. If I ask my travel agent to find me a vacation spot that's "cheap, warm, and for families," she's got enough information to get started. She knows what "warm" means, because that's a pretty standard term, although she might ask me to clarify: Do I want Death Valley warm or Orlando warm? I'll also probably clarify what "cheap" means (to make sure she finds us a place with indoor plumbing!). She would also ask what my "family" consists of—teenagers or toddlers, for example—and then she would go to work.
First, she researches places around the world that will be warm at the time of year I want to take my vacation. Then she looks at airfare, hotels, car rentals, and a dozen other factors that influence price. She might use printed travel brochures provided by hotels and vacation packagers, or she might consult any of hundreds of Web sites for the information she needs.
As Figure 7-2 illustrates, my travel agent becomes an information aggregator, looking for a combination of services that fit my needs. She is at the center of an information universe.
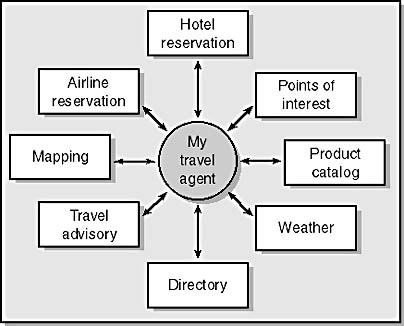
Figure 7-2. A travel agent is an information aggregator, relying on many different information sources to create a travel package for her customers.
After researching various information sources, my travel agent starts making decisions. For example, the temperature might be 85 degrees in Grand Cayman Island, but hotels are expensive and limited flights are available from Denver. St. Thomas is only 82 degrees, but also much cheaper and more easily accessible. However, St. Thomas doesn't have a lot for kids to do. The Bahamas are a little more expensive and not quite as warm, but have plenty of activities for kids. In other words, I'll need to make some trade-offs to accommodate all of my requirements. Finally, she comes up with a couple of plans and runs them past me.
My travel agent is human and can do only a couple of things at once. Plus, she has other customers; she can't spend all year on my project. Because of these limitations, my travel agent can consider only a small number of alternatives before proposing one or two to me. It is conceivable that a small, warm, family-friendly island is out there somewhere, and maybe the locals are cutting prices to attract more tourists. If that information doesn't get to my overloaded travel agent, she can't consider it and I've lost an opportunity.
Wouldn't it be nice if computers could help to broaden my travel agent's effectiveness by allowing her to consider more alternatives? Nice fantasy, but not very workable. The problem is the format of the available data.
If my travel agent gets information from the Web, that information is probably delivered using HTML and viewed by her eyeballs in a Web browser. Many of the HTML pages she views were created on the fly by the site's middle-tier applications. When my travel agent visits a hotel's Web site looking for room availability, some program at the hotel's Web operation queries a database containing room information and then creates a page for her.
If I were to create a computer program that could access this information in the same way as my travel agent, the computer would have trouble. It would look at an HTML page as a one-dimensional string of markup characters, not as a two-dimensional photograph or text conveying certain information. For example, when you see the text "76°F", you recognize that it means seventy-six degrees Fahrenheit, and that many people would consider that a pleasant, warm temperature. But the computer sees four ASCII characters and can't interpret them as humans do.
Take the example of the hotel page. We know valuable data is out there somewhere. The server-side application "dumbs down" the data so that humans can interpret it. Wouldn't it be nice if we could circumvent the flattening of the data for eyeballs and allow computers to talk to computers?
If I could somehow indicate from my computer program to the hotel site that a computer would be interpreting the information instead of a human, the hotel site could send the following back to my program, which would be much easier to process:
<avg-temperature deg="f">76</avg-temperature> |
A program that provides this kind of computer-to-computer communication is called a Web service, and it is the next major innovation available in the infrastructure of the Web.
The existence of the Web, with millions of computers hooked to it, has encouraged companies all over the world to put their information online so that it can be accessible to customers and potential customers. A huge amount of data sits right behind server-side scripts, waiting to be accessed by Web browsers.
If your company has valuable information, wouldn't you benefit from the ability to repackage it and sell it in different ways? And if your company needs information, wouldn't it be cheaper to buy the information from someone on an as-needed basis than to build it yourself?
Think of Web services as applications that make it possible for you to program using data available on the Web, just as you can program now using data available internally. This ability to program the Web will be essential to how we use the Internet in the coming years.
EAN: 2147483647
Pages: 150
- Chapter IV How Consumers Think About Interactive Aspects of Web Advertising
- Chapter XI User Satisfaction with Web Portals: An Empirical Study
- Chapter XII Web Design and E-Commerce
- Chapter XVI Turning Web Surfers into Loyal Customers: Cognitive Lock-In Through Interface Design and Web Site Usability
- Chapter XVIII Web Systems Design, Litigation, and Online Consumer Behavior