W3C
The World Wide Web Consortium (W3C), based in Cambridge, Massachusetts, is an international association of companies interested in maintaining standards for the World Wide Web. (You learned a little about the W3C in Chapter 2.)
W3C standards are the result of global input refined through an extensive process that eventually leads to consensus. The steps in the W3C specification approval process include the following:
- A member of the W3C sends a Submission to the consortium. The consortium considers whether the submission is within the W3C charter, and whether the consortium should expend the energy necessary to refine the submission into a recommendation. Some member companies make submissions to the W3C just to get a jump on the competition or to say they are implementing a "W3C Submission." It is important to note that any W3C member can submit a spec. Simply submitting a spec, however, does not mean that the W3C will accept the spec's viability.
- Sometimes, submissions become Notes. A Note is a dated public record of an idea, a comment, or a document. Once the W3C reviews a Note, the Note becomes an Acknowledged Submission. A Note does not represent a commitment by the W3C to pursue work related to the Note. Members who want to have their ideas published on the W3C site as Notes follow a formal submission process.
- Once a submission becomes acknowledged, a Working Group forms. This group usually consists of a representative from the member group that submitted the draft, plus other representatives from interested parties. Every so often, the Working Group issues a Working Draft that represents work in progress and a commitment by the W3C to pursue work in this area. A Working Draft does not imply consensus by a group or the W3C. Working Drafts are usually posted on the W3C Web site, along with an invitation for comments from the public. These Working Drafts are sometimes implemented by software vendors, who are eager to see whether the specification is usable. Input from these vendors is valuable to the Working Group, but the implementing companies understand that the spec might change considerably, rendering their work obsolete.
- Once the Working Group is comfortable that its work is ready to finalize, it will issue a Proposed Recommendation, which represents the group's consensus. The Working Group sends the Proposed Recommendation to an Advisory Committee for review.
- A Recommendation represents consensus within the W3C and has the W3C Director's stamp of approval. The W3C considers whether the ideas or technology specified by a Proposed Recommendation are appropriate for widespread deployment and whether they promote the W3C's mission.
- Complex specifications might require more input for final consideration. If this is the case, the committee will issue a Candidate Recommendation, which is designed to tell the world that the Working Group thinks that the specification is mostly complete and stable, and that it is safe to spend resources to implement software for the specification. The Working Group invites feedback from implementers to gauge how their Recommendation can be implemented. However, a Candidate Recommendation might change based on the input the Working Group receives when the group releases the final Recommendation.
W3C Standards
The W3C has created many Recommendations during its lifetime. HTML and CSS are two of the most widely used. In 1996, a group of Web-savvy SGML gurus submitted an idea to the W3C for a slimmed-down version of SGML that would fit easily into Web browsers or server-side applications. This effort became known as XML.
XML 1.0 was formally adopted as a W3C Recommendation in February 1998. To create the XML Recommendation, the W3C XML Working Group started with SGML, removed all the optional features, and streamlined the syntax. This resulted in a small, terse syntax that small, fast parsers can process. As you learned in earlier chapters, XML provides only a way of describing your data; it doesn't have features for processing the data. XML is small, and it will stay that way. However, many users have found the need to do certain common types of processing, so the W3C is working on standards to use with XML to provide more processing functionality.
In this section, we'll look at the standards established by the W3C that support XML and make programming it more efficient. Figure 3-1 illustrates how these various standards are related.
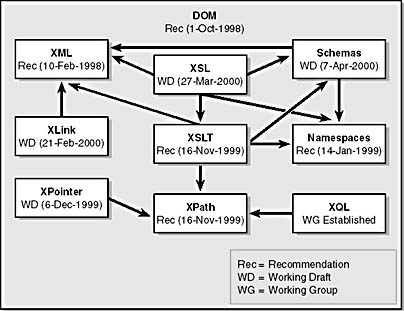
Figure 3-1. The W3C publishes a rich set of standards that support XML. By plugging into the base spec (DOM), an implementer can select specific technologies for a particular task.
XLink and XPointer
An example of a standard that addresses the need for better processing functionality is one that deals with linking. XML expresses information in terms of hierarchical relationships. An element can have children, which, in turn, can have their own children. The structure of an XML document describes only this model. Some data structures, however, have nonhierarchical relationships; an object might have a relationship with another object in a different location. This type of relationship must be expressed in terms of a link rather than as a parent-child relationship.
Two W3C Working Drafts provide a standard way of representing linking: XLink and XPointer. I can best illustrate these specifications with an example. Consider the HTML anchor element, <A>. The element's form looks like this:
<A HREF= "http://architag.com/solutions/senior.html#btravis"> Brian Travis</A> |
This element consists of two distinct pieces:
- The <A> tag, which indicates the semantics, or processing characteristics, of the link The HTML parser looks at the <A> element and extracts the string in the HREF attribute. The text between the <A> tag and the closing </A> tag is usually underlined in the browser. The browser does not display the address contained in the HREF string.
- The HREF attribute, which indicates the location of the hypertext link The string in the HREF attribute consists of a filename (usually an HTML file), with an optional domain name and path in front of it and an optional hash sublocation. In our example, HREF tells the A-element processor to grab the file senior.html in the solutions directory from the site http://architag.com by using the HTTP get method, and then to scroll down to the marker in that file indicated with the name btravis.
What if we want to indicate a different processing semantic to our own links? For example, what if I want to create a link that allows a user to select one destination from a number of different destinations? A link in a document that refers to Beethoven might lead to different places, depending on what the user wants to see. It could lead to a biography of the composer Ludwig van Beethoven, a symphony score by the composer, or a showing of Beethoven, the movie about a slobbering dog.
If I want to include such a link on my page, I need to create a script that shows a pop-up window, allows the user to select an option, and then goes to the selected destination. XLink provides this functionality. A browser that supports XLink can do such one-to-many links declaratively, without requiring special scripting.
XLink also allows inline links. What if I want to include bits and pieces of many different documents in my document? Inline links allow me to grab several documents from different locations and include them all on the same page. In this way, I can have a page consisting of only a set of links. I think XLink offers the <A> tag on steroids.
By the same token, XPointer works like the HREF attribute on steroids. In the previous example, the URL points to a location inside the document referenced. This bookmark pointer simply causes the browser to scroll to a marked location after the page is loaded.
But what if I don't want to see the whole page? What if I want to include only the paragraphs concerning btravis and not the rest of the document? The XPointer syntax allows you to target a portion of a page with more granularity than the HREF can. For example, you can present an XPointer string to tell an XLink tag that you want to include only the third through the sixth paragraphs of a section with an identifier of chapter2.
Schemas
A schema describes the structure of an information set. XML 1.0 specifies a schema syntax named a document type definition (DTD). The DTD is a relic of SGML and as such does not have modern data processing capabilities built in. The DTD is great for expressing textual documents such as technical manuals, business plans, and training guides. However, the DTD schema syntax has some limitations when XML is used to transmit real-time database data and business documents between trading partners in an e-commerce environment.
Shortly after the W3C XML Working Group finalized the XML 1.0 Recommendation, several groups made formal submissions to the W3C for a schema syntax that extends the capabilities of the DTD. These were XML Data, Document Definition Markup Language (DDML), Schema for Object-oriented XML (SOX), and Document Content Description for XML (DCD). I discuss XML schemas in depth in Chapter 4.
Namespaces
Namespaces indicate to the XML processor where to find the structural rules (the schema) to apply to a document. A namespace declaration points to a resource containing the schema that describes the document.
Let's look at how a namespace works in practice. In the preceding XLink and XPointer discussion, I mentioned that you can link to pages in a more granular way. Suppose I pull in several different fragments from various XML documents on the Web. Each of these documents might use the same element name, but each element name might imply something different to each particular document creator. For example, I want to grab three paragraphs from George's document and four paragraphs from Martha's document and make them all appear on a single page. I'll then write a style sheet that formats the finished page to make it presentable in the browser.
Well, George has an element named date that represents a day of the week:
<date>Feb 13, 2000</date> |
Martha also has a date element, but Martha thinks a date is a night on the town with George:
<date>Dinner, then a movie</date> |
If I include both these elements in the same virtual document, I'll have what is called a namespace collision.
Namespaces provide a way of differentiating elements in a single document. To prevent a namespace collision, I declare two namespaces that point to the two schemas that describe the structure of the two documents. Then I prefix each element with the appropriate namespace prefix:
<document xmlns:george="http://no1prez.com/schemas/schema1.xdr" xmlns:martha="http://schemas.martha.com/funstuff.xdr"> ... <george:date>Feb 13, 2000</george:date> ... <martha:date>Dinner, then a movie</martha:date> ... </document> |
I've thereby eliminated the identical element names. Once I prefix these elements, I can use a style sheet to create two rules to identify the elements independently, and an application can process each element separately. I'll discuss namespaces further in Chapter 5.
XSL, XSLT, and XPath
It's important to note that the XML 1.0 Recommendation doesn't provide any standard way of formatting the content in XML documents. Enter XSL, the Extensible Stylesheet Language. The W3C XSL Working Group was formed by some of the same people who worked on the Document Style Semantic Specification Language (DSSSL). DSSSL is an ISO standard that provides a syntax for adding style semantics to an SGML document. DSSSL is terribly complex because of the intricate page-definition tasks it must perform. The XSL Working Group used DSSSL as a starting point for adding semantics but quickly decided that DSSSL would need to change too much, so the group redirected its focus.
To that end, XSL consists of two main functions: XML document transformation and formatting object interpretation. The main purpose of XSL is to convert XML documents into some formatted representation. The latter function—interpreting the formatting object string—is really only necessary if you are creating printed documents. (By printed, I mean on paper or a paper equivalent, such as a Web site or a CD-ROM image.)
As the XSL standard progressed, the Working Group realized that document transformation could have a lot of value even if an XML document was never rendered for human consumption. The XSL committee extracted the transformation part from XSL and created a new standard, XSL Transformations (XSLT). XSLT is a W3C Recommendation, and several software vendors have created XSLT processors to work with the spec. XSLT is a general-purpose transformation engine that you can use in many places. You should learn XSLT if you use XML in any serious way.
The W3C extracted the pattern-matching syntax from XSL and created the XPath specification. XPath provides a way to describe the structure of a source document so that you can transform the document. I discuss both XSLT and XPath in depth in Chapter 6.
XQL
Many people in the XML community felt the need for a standard way to query a set of XML documents. This standard would be equivalent to the Structured Query Language (SQL) used to query relational databases from many different vendors.
Currently, there is no standard way of querying the contents of a collection of XML documents. The XML Query Language (XQL) Working Group is currently working on a specification to do just that: provide a standardized syntax that looks into the structure of a database of XML documents and returns a result set that can be processed in a standard way.
DOM
All the specifications I've mentioned so far can be included in an implementation that processes XML documents. The W3C formed a committee to work on a model that described an XML document for the purpose of developing standardized applications. The Document Object Model (DOM) specification is the result of that committee's work.
The DOM provides a standard set of interfaces that expose the properties and methods of XML and HTML documents. Although the W3C DOM is an agreed-upon standard, the developers left out implementation specifics, preferring that individual implementers do the heavy lifting. I'll discuss the DOM in Chapter 5.
EAN: 2147483647
Pages: 150