| The purpose of full-text searching is to identify data sources, such as documents, that contain a specified search term . The search engine must quickly and accurately provide results to the user. It must handle a variety of file formats and storage locations. Finally, the search results should be sorted in a way to make the most useful documents most visible to the user . We can differentiate between two large categories of searches: search against a well-defined source using SQL-type language and fuzzy search against weakly structured data sources like files, images, web sites, and so on. SQL Server, for example, employs both approaches through SQL queries (for example, SELECT FirstName , LastName FROM tblPeople WHERE LastName LIKE 'SMIT%' ) and through its full-text search capabilities for performing searches within fields. Searches can also look at the metadata surrounding a document, such as the title, author, or keywords that are entered as document properties. A sequential search of files for a character string is not a practical approach for any but the smallest number of documents. For instance, Windows XP and Outlook perform sequential searches by looking at files or messages one at a time. You probably have noticed how long these searches take for even a relatively small number of documents. Therefore, to solve the performance problem, much of the work of searching must be done in advance using inverted indexes ”files that contain a list of all the words in a group of documents along with pointers to the documents that contain the words. A search does not result in a sequential read of any source files, but rather in an examination of the index file. Any matches can then be quickly identified. The search engine consists of several architectural elements. At its most basic, a search engine must provide a means for creating an index of content, storing the index and providing search results based on user criteria from the index. Figure 13.1 shows key elements and concepts for search engines. Figure 13.1. Search Engine Elements (Source: Uri Barash, "Enterprise Search with SharePoint Portal Server," Tech-Ed Israel, 2003.) 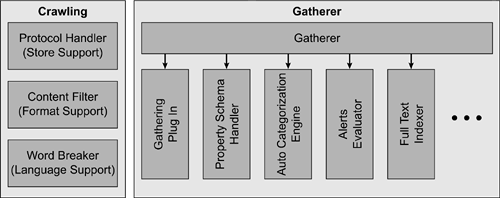
Microsoft Researches Search Technology Microsoft has made a tremendous investment in computer science research relating to information retrieval through its Microsoft Research organization. The research findings are incorporated into products in order to make computing easier. SharePoint Portal Server uses the advanced probabilistic ranking algorithm developed by Microsoft Researcher and City University Professor Stephen Robertson (research.microsoft.com/users/robertson/), winner of the prestigious Association for Computing Machinery Special Interest Group on Information Retrieval (ACM SIGIR) 2000 Salton Award. The ranking formula uses the following factors to determine the relevance of a document: -
Length of the document -
Frequency of the query term in the entire collection of documents -
Number of documents containing the query term -
Number of documents in the entire collection of documents For more information on Microsoft research in this area, see research.microsoft.com/research/ir/. There are a number of research papers on the Microsoft site of interest to students of information retrieval. For instance, "Inferring Informational Goals from Free-Text Queries: A Bayesian Approach" by David Heckerman and Eric Horvitz at research.microsoft.com/users/horvitz/aw.HTM and "Hierarchical Indexing and Flexible Element Retrieval for Structured Documents" by Hang Cui and Ji-Rong Wen at research.microsoft.com/users/jrwen/jrwen_files/ publications /Hierarchical%20Indexing%20and%20Flexible%20Retrieval%20for%20Structured%20Document.doc. |
The two main activities of the search engine are crawling and gathering. The crawling consists of reading content to be indexed, whether on the web, in file directories, or other content sources such as Exchange public folders or Lotus Notes databases. The crawler must understand the protocols used to access the content, such as HTTP for web content. Next , it must be able to read the file formats to be indexed. This software component is called a filter . It converts the source document to text that can be indexed. Finally, the crawler must process the text and perform conversions that make it more searchable, such as converting plural to singular or various verb forms to words that are easier to search. For instance, you would want a document containing the word "mice" to appear even if your search term were "mouse." The gatherer takes the input from the crawler and organizes it to produce search results. The most common gatherer function in nearly all search engines is full-text indexing. All words found in the content are indexed along with pointers to the documents that contain them. The gatherer also may perform advanced search techniques such as binary file comparisons or automatic categorization of documents based on words contained therein. The gatherer alerts users who are subscribing to search results so they are made aware of new content as it is found. The following are elements that make up the crawling and the gatherer: -
Content sources . A repository of content to be indexed and therefore searched. SharePoint can crawl Exchange Server folders, file shares, web pages and sites, and Lotus Notes databases. Content sources can be located on multiple file servers in different domains, including public Internet web sites. -
Protocol handlers . A protocol handler is a component that accesses data over a particular protocol or from a particular store. Common protocol handlers include the file protocol, Hypertext Transfer Protocol (HTTP), Messaging Application Programming Interface (MAPI), and HTTP Distributed Authoring and Versioning (HTTPDAV). The gatherer passes URLs or URIs to the protocol handler. -
Content indexes . A full-text index of content sources specified by the SharePoint administrator. The indexes include file metadata as well as text in the target files. These are inverted indexes, which means that they contain entries for each word found in the content sources along with pointers to documents or pages that contain the word. -
Search scopes . Users can restrict their search to certain content sources based on a search scope. These are often displayed to the user in a dropdown list next to the search box. If you have many content sources that do not overlap, you can speed searches and provide better search results for users by allowing them to target a specific content source. For instance, the Microsoft web site allows you to search only within the TechNet section when you are looking for technical information rather than bringing you results from their product marketing data or financial results. -
Index updating . The process of indexing or crawling content and updating the index files. Indexes are usually updated periodically on a scheduled basis rather than continually. -
Best bets . Highlighted search results that are most relevant to the user. Administrators may tag content as best bets so it will be placed higher in the search results than the ranking that would be ascribed to the document by the contents of the text alone. Users may suggest best bets for approval by administrators. -
Gatherer . A software component that maintains the queue of files to be accessed. A gatherer uses techniques to optimize the efficiency of a web site crawl. For instance, some web sites restrict accesses to pages faster than they may be read by humans to curtail indexing activity. To overcome this, the gatherer interleaves URLs from one remote web location with URLs from other web locations, or with local file system documents or other stores. SharePoint also includes additional logic to improve crawl efficiency called adaptive crawling . Adaptive crawling balances the load imposed on crawled servers. When each document is accessed, the gatherer directs the stream of content from the protocol handler and passes it on to the appropriate filter. -
Filters . Filters (also known as IFilters) extract textual information from a specific document format, such as Microsoft Word documents or text files. Microsoft provides filters for Microsoft Office that can extract terms from Word, Microsoft Excel, and Microsoft PowerPoint files. Other filters work with HTML or email messages. Adobe provides third-party filters to extract text from PDF files. The filter passes the stream of text to the indexing engine. All filters are written to an application programming interface (API), which is documented as part of the Microsoft Platform Software Development Kit (SDK). -
Word breakers and stemmers . A word breaker determines where the word boundaries are in the stream of characters in the document being crawled. A stemmer extracts the root form of a word. For example, "go," "gone," and "going" are variants of the word "go." The word breakers are different for different human languages. The code for determining where words are broken is built into the Microsoft Search (MSSearch) service and cannot be changed. -
Indexing engine . The indexing engine prepares an inverted index of content ”that is, a data structure with a row for each term. The row contains information about the documents in which the term appears, the number of occurrences, and the relative position of the term within each document. The inverse index provides the ability to apply statistic and probabilistic formulas to quickly compute the relevance of documents. This means that the search engine can calculate the ranking of search results without looking at the source documents at all. -
Ranking . In a search for unstructured data, ranking assists the user with prioritizing the search results based on their relevance. Ranking is not used for a structured, relational database search because structured data often lends itself to producing a single authoritative answer in response to a query. Full-text searches, on the other hand, tend to be less precise and often produce a large number of hits that must be sorted to maximize their value. The ranking algorithm is the "secret sauce" of the search engine. It makes the difference between mediocre and excellent search results. This is the reason why Internet users choose one search engine over another as their starting place to find new web pages and sites. The search server naturally must be able to access and read a file in order to index it. In the case of password-protected files, this means that the account used by the server must have rights to the files that are to be indexed. SharePoint reads files by means of software called an IFilter. SharePoint comes with IFilters for Office documents, Microsoft Publisher files, Visio, HTML, text, and Tagged Image File Format (TIFF) files. Third parties offer additional IFilters for other file formats. Adding an IFilter to your server expands the range of file formats that can be indexed. The IFilters only need to be present on the search server that crawls content. They do not provide viewing functionality to end users. Users must have software installed to open a file that they find in a search. |