The Swing HTML Package The HTML package has been subject to frequent changes during the development of Swing and it continues to evolve even after the release of Swing as a fully supported product. One of the areas that has changed most noticeably is the subset of HTML that the package actually supports. Because the HTML specification itself is still expanding rapidly, it is likely that the Swing HTML package will continue to change to recognize more tags and to provide better support for some features that are currently not fully implemented. Because of this, what you'll find in this chapter is mainly intended to acquaint you with the architecture of the HTML package rather than to cover in great detail exactly what is and is not available. However, you will see how to find out which tags and attributes are recognized by the version of the package that you are using without having to search the source code. The first part of this section looks at the various pieces that work together to turn the JEditorPane into a simple Web browser. You'll see how an HTML file is parsed and the how the tags and content are represented in the Document model and we'll look at the features of the HTMLEditorKit, which are currently somewhat limited. Having seen the storage mechanism, we'll then move on to look at how the Document is rendered by the HTML package's Views and how you can subclass them to adjust the way that a Web page is presented to suit your needs. The HTML Document Model As you've already seen in this chapter, when you load an HTML document into a JEditorPane, an HTMLEditorKit is created and installed. Like all editor kits, HTMLEditorKit creates a Document class that can handle the type of content that it is responsible for; in this case, an HTMLDocument will be created. Because HTMLDocument is derived from DefaultStyledDocument, the way in which HTML pages are stored within the JEditorPane is fundamentally very similar to the way in which the documents are stored that we saw in Chapter 2 when we looked at how to use JTextPane the content is mapped by an Element structure and the way in which the text should be rendered is described by attributes attached to those Elements. However, HTML is a fairly rich and flexible document description language, so there is quite a bit more complexity surrounding not only the way in which it is stored within the model, but also in the architecture of the HTML package itself. In fact, there are several classes that are involved in maintaining an HTML document that have no parallel in the simpler RTF package or the small set of classes used to display plain text. A complete picture of the most important of these classes and their relationships is shown in Figure 4-10. Figure 4-10. The components of an HTML document.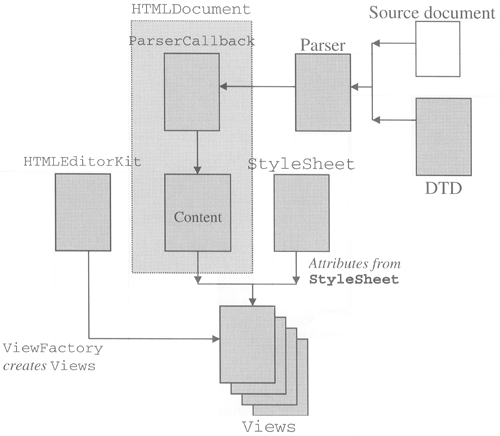 The collection of classes shown in Figure 4-10 is created and assembled by the HTMLEditorKit when its read method is called. In many cases, there are override points available that allow you to substitute your own implementation of some of the pieces. To make full use of the HTML package, you need to understand what all these classes are and how they interact with each other. Brief descriptions of each of them will be found in the sections that follow. When we've looked at each of the component parts, we'll then move on to examine in more detail the structure of the document model itself and how it differs from what we have seen so far. The DTD There have been several versions of HTML, the most recent of which, at the time of writing, is HTML 4.0. The official specification of HTML itself is maintained by the World Wide Web Consortium (W3C), and can be found on its Web site at http://www.w3c.org. Each version of HTML is specified by a document type definition, or DTD, which describes the legal elements of an HTML page and the way in which they can be combined. A DTD is written partly using a formal description language known as the Structured Generalized Markup Language (SGML) and partly with informal comments that add more detail to aid understanding. For example, here is how the HTML markup for a paragraph is defined in the HTML 3.2 DTD: <!ELEMENT P - 0 (%text)*> <!ATTLIST P align(left|center|right) #IMPLIED > This short extract defines an element called P which has an associated set of possible attributes defined in the ATTLIST description. These two definitions are tied together by the common tag P, which is defined by the ELEMENT description to be the tag to be used within the HTML itself. The - following the P indicates that the start tag for this element is mandatory, while the o means that the corresponding end tag is optional. In practice, this says that a paragraph is introduced by a tag written like this: <P> and may be terminated by one that looks like this: </P> although the second of these tags may be omitted at the option of the person writing the HTML. The body of the paragraph is described by the rest of the element definition, namely: (%text)* The asterisk means zero or more instances of the item that precedes it, which in this case is whatever is meant by %text. This term is defined earlier in the DTD like this: <!ENTITY % text "#PCDATA | %font %phrase %special | %form"> This definition is itself framed in terms of other definitions and the SGML term #PCDATA, which means Parsed Character Data. Parsed Character Data is a sequence of characters that may contain raw data that represents itself (such as ASCII characters) as well as other markup such as & which would be taken as an ampersand (&) character. The | character means OR, so this description says that text is made up of either pcdata or whatever the DTD means by %font or %phrase or %special or %form. If you want to see how these terms are defined, you can find them in the DTD itself on the W3C Web site. The ATTLIST specification describes the attributes that may accompany the paragraph tag. Attributes always appear within the angle brackets that surround the tag itself and are given in the form: name = value According to the DTD extract shown earlier, for a <P> tag, the only recognized attribute is called align and it can take one of the values left, center, or right, where (as always with HTML) case does not matter. The word #IMPLIED indicates that this attribute need not be specified, so either of the following would be valid: <P> <P ALIGN=LEFT> Which of the alignment values is assumed when the alignment is not explicitly given is not specified by the DTD. If the keyword #REQUIRED were used in place of #IMPLIED, it would be mandatory to supply an explicit value for the align attribute and it would have to be one of the three possible values from the DTD. Because HTML is defined in terms of a DTD, it makes sense to write software that interprets HTML in such a way that it can be driven directly by the DTD. That's exactly what happens in the HTML package. If you have Java 2 or Swing for JDK 1.1 installed on your machine, you'll find in the JAR file (swingall.jar or rt.jar depending on which JDK you are using) a file called javax/swing/text/html/parser/html32.bdtd, which contains a binary-encoded form of a DTD describing HTML. The encoding used in this file is a private one and, fortunately, you don't need to understand it to make full use of the HTML package. The version of the DTD that this encoding represents contains all the elements defined by HTML 3.2 and some extras that were not part of the official specification of that HTML version, such as the ability to define and use style sheets, a feature that has greatly influenced the design of the HTMLDocument class, as you'll see later. Core Note If you want to find out more about the binary encoding of the DTD file, the classes that are used to reading it are in the javax.swing,text.htm1.parser package, the source code for which is included with Java 2 and with the Swing add-on package forJDK 1.1.
The Parser and the ParserCallback The binary DTD is used by an HTML parser, which reads HTML from a Reader and validates it against the rules contained in the DTD. The interface supplied by the parser is defined by the abstract class HTMLEditorKit.Parser, which contains only one method: public static abstract class Parser { public abstract void parse (Reader r, ParserCallback cb, boolean ignoreCharSet) throws IOException; } The parser uses the DTD to validate the structure of the document, which is read through the Reader supplied as the first argument. However, nothing outside the parser itself knows or cares that it might be using a DTD to do its job, so you won't see any code that passes a particular DTD to the parser. The parser in the Swing text package is hard-coded to use the binary DTD for HTML 3.2 that is located in the javax.swing.text.html.parser package. The ParserCallback given by the second argument is called as the HTML document is parsed. ParserCallback is an inner class of HTMLEditorKit that defines seven empty methods: public static class ParserCallback { public void handleComment (char[] data, int pos) { } public void handleStartTag (HTML.Tag t, MutableAttributeSet a, int pos) { } public void handleEndTag (HTML.Tag t, int pos) { } public void handleSimpleTag (HTML.Tag t, MutableAttributeSet a, int pos) { } public void handleText(char[] data, int pos) { } public void handleError(String errorMsg, int pos){ } public void flush() throws BadLocationException { } } The parser considers the pieces of an HTML document to be of five different types and it invokes the corresponding method of the ParserCallback class as each element type is encountered. A short description of each type follows. Comments The handleComment method is called when an HTML comment is encountered. Comments begin with the sequence <!-- and are terminated with -->. These delimiters are not useful in the internal representation of the HTML document, so they are not passed when the handleComment method is called only the text of the comment itself is given, in the form of an array of characters, including any spaces that follow the opening delimiter and precede the closing one. The pos argument gives the offset of the first character after the end of the comment, including the terminating delimeter. Thus, for example, if an HTML document started with the following sequence: <!-- A comment --> the handleComment method would be called with the characters "A comment" as the character array (note the leading and trailing space, which come from the text as typed into the document) and with the pos argument set to 18. The current implementations of the parser and the DTD consider the body of the comment to be raw characters they do not recognize embedded HTML tags and so there is no support for features that are hosted with HTML comments, such as JavaScript. You could, of course, provide this support yourself by capturing the output of the parser and performing further processing of comments. Complete support for JavaScript also requires extra work when handling most aspects of creating and displaying the HTMLDocument, one example of which is the extra attributes that are used with some HTML tags to invoke JavaScript functions when certain events occur. These attributes are not recognized by the HTML 3.2 DTD. Although adding JavaScript functionality to the HTML support provided by the Swing HTML package would be an interesting project, it is well beyond the scope of this book. You should, however, be able to work out how to add most of the extra facilities for JavaScript from the information in this section. Start and End Tags As mentioned in the discussion of the HTML DTD, many HTML tags come in pairs that start and end a section to which the markup specified by the tag applies. The parser calls the handleStartTag and handleEndTag methods as each element of the pair is encountered. A start tag and its matching end tag might be quite widely separated from each other and other markup may be encountered while the text between a start tag and its corresponding end tag is being processed. The HTML reader must, therefore, be prepared to stack tags and handle new tag pairs while the parser is searching for the matching end tag. As with the handleComment method, the pos argument corresponds to the character after the tag. The other two arguments require a little more explanation. The first argument passed to both handleStartTag and handleEndTag is of type HTML.Tag, which describes the tag that has been encountered. There is one HTML.Tag constant for every tag recognized by the DTD. The tag constant that represents a paragraph break, for example, is called HTML.Tag.P. As well as containing the name of the tag (which is held in lowercase), the HTML.Tag object has two other attributes associated with it: The causesBreak attribute indicates whether this tag will cause a break in the text flow. This is true for tags such as <P>, but false for tags like <FONT> and <B> that simply change the formatting of the current text line. The is Block attribute is true for a tag that starts a new block within the document. The <P> tag is an example for which this attribute is true, because it starts a block that is ended by the corresponding </P> tag, if there is one, or by the next <P> tag if </P> tags are not being used (which is usually the case). The second argument passed to handleStartTag is MutableAttributeSet that contains the HTML attributes that qualify the tag. Because closing tags do not have associated attributes, this argument is not used with handleEndTag. As an example of what is meant by an attribute in this context, consider the <FONT> tag, which can modify the size and color of the text that it bounds. A typical <FONT> tag might look like this: <FONT COLOR=red SIZE=+1> When the parser encounters this tag, it will call the handleStartTag method with the first argument set to HTML.Tag.FONT, while the second will be a reference to a MutableAttributeSet containing an attribute called color with value red and another called size with value +1. You'll see later in this section exactly how these attributes are encoded. The parser keeps a stack of tags, which is added to as each opening tag is encountered. When a closing tag is detected, the entry for the opening tag is popped from the stack. However, it is common practice not to supply end tags where their presence can be inferred from context and the DTD permits this, as you saw earlier in the case of the </P> tag. In cases like this, the parser will internally generate the tag that has been omitted and invoke the handleEndTag method exactly as if the tag had been present in the input stream. The same is true of certain start tags, such as <HTML>, <HEAD>, and <BODY>, some or all of which are routinely omitted from HTML documents. This allows the code that handles the parsed document to be simpler, because it does not need to specifically cater for missing start or end tags. Simple Tags The handleSimpleTag method is called when the parser encounters a tag that is not part of a start/end pair. An example of a tag in this category is <BR>, which always appears on its own in a document there is no corresponding </BR> tag. A simple tag may, however, have associated attributes so, in addition to the universal pos argument, the handleSimpleTag method is called with both an HTML.Tag object for the tag itself and a MutableAttributeSet for the qualifying HTML attributes. Text Anything that is not markup and is not a comment is considered to be text and is handled by calling the handleText method. Text can only legally appear where the DTD allows content of type PCDATA. Because text is described in this way, it may contain ordinary characters or character entities that specify characters in a manner that is independent of the character set in which the document is encoded, such as & which, as noted earlier, signifies an ampersand. Ordinary characters are translated directly to Unicode by the Reader that handles the document input stream before it is seen by the parser, but character entities are not. Instead, these are detected by the parser and converted to the appropriate Unicode value before the handleText method is called. A text run will be interrupted by the occurrence of any markup other than character entities: The text on either side of the markup will be delivered in separate invocations of handleText. For example, if the following sequence occurred in an HTML document: This is <B>bold</B> text handleText would be called three times, with an invocation of handleStartTag for the <B> tag and handleEndTag when </B> is reached. Errors Parsing errors are reported via the handleError method, which passes a textual error message and the offset at which the error was detected. In some cases, HTML that does not strictly match the DTD is not reported as being in error, because there is quite a large number of Web pages that would not format properly if strict adherence to the DTD were enforced. This is consistent with the behavior of the more popular browsers, which generally tend to skip over markup that they don't understand. The Swing HTML package tries to correct common mistakes by introducing extra tags into the input stream or, in some cases, ignoring duplicate or invalid tags. When an error that cannot be automatically corrected or ignored is encountered, the handleError method is invoked. The default processing for this method (in HTMLDocument.HTMLReader) does nothing at all, so errors are not actually reported and parsing will continue. Whether further parsing will be useful will, as with all languages, depend on the nature and context of the error. The flush Method The last of the ParserCallback methods is the flush method, which is invoked once, when the parser reaches the end of its input stream, to notify the ParserCallback object that there is nothing more to parse. This method is present to allow the ParserCallback implementation to buffer whatever it creates from the results of parsing and to flush its cache of unprocessed items when the document has been completely read. An implementation is, of course, not obliged to buffer, but the default implementation in HTMLDocument.HTMLReader does provide this feature. As it receives items from the parser, HTMLReader would like to create document Elements and attributes and insert them into the HTMLDocument, building up the model as the Web page is parsed. However, this is usually inefficient, especially if the HTMLDocument is already installed in a JEditorPane (as it would be for the usual case of asynchronous loading via the JEditorPane setPage method) because changes to the HTMLDocument cause events that might kick off other processing. In particular, the Views that render the document content will be notified of changes. This will cause new Views to be created as the document is built and the screen to be updated, if the component is visible. There is no real point in doing this in most cases, so HTMLReader waits until it has a large set of document updates and makes them all together, so that the Views redraw only relatively infrequently during the loading process. The flush method allows the HTMLReader to push any Elements that have not been created into the HTMLDocument at the end of the process. Core Note When the arrangement in Figure 4-10 is created from the HTMLEditorKit read method (which will be the cose unless you write code to initialize the component), the HTMLReader will buffer approximately 100 changes to the document before a real update occurs. The number is only approximate because it is only checked when text is being added.
The Default Parser The parser that is installed by default is obtained by invoking the getParser method of HTMLEditorKit, which is invoked from the HTMLEditorKit read method. This method returns an instance of the class javax.swing.text.html.parser.ParserDelegator in fact, a single instance of this class is created the first time the getParser method is called and is shared by every copy of HTMLEditorKit that is subsequently created. This class is not the parser itself, however: Its only job is to load the DTD and provide an implementation of the parse method required by the HTMLEditorKit.Parser interface. The real parser resides in a class called javax.swing.text.htm1.parser.DocumentParser. One instance of this class is created each time the parse method of ParserDelagator is invoked in other words, a new copy is created each time an HTML document is parsed. Having created the DocumentParser, the ParserDelagator parse method simply delegates to the same method of DocumentParser, which has the same signature as the parse method in the HTMLEditorKit.Parser interface. If you want to supply your own parser, you must create a class that provides the parse method and calls the methods of the ParserCallback object passed to the parse method as the HTML document is being scanned, as outlined in this section. To arrange for your parser to be installed, you'll need to override the HTMLEditorKit getParser method and return a reference to your own parser instead of the default one. This, of course, requires you to implement a subclass of HTMLEditorKit. You'll see an example that installs a modified HTMLEditorKit in the next section. While this example won't actually create a new parser, you will see the code required to use a replacement editor kit. Replacing the ParserCallback By default, the HTMLDocument.HTMLReader class is used as the ParserCallback. Under normal circumstances, you would not need to install your own ParserCallback but it is possible to use a different class by overriding the getReader method of HTMLDocument: public HTMLEditorKit.ParserCallback getReader (int pos); We'll make use of this facility to install an enhanced ParserCallback that allows us to see exactly what the parser does when it reads an HTML page. To do this, we'll create a thin layer of code that wraps the existing HTMLReader class and, as each of the ParserCallback methods of this class is invoked, some debugging information will be printed and the call will be passed to the original HTMLReader implementation so that the JEditorPane continues to function normally. The code is shown in Listing 4-6. Listing 4-6 Installing a Custom HTML Reader package AdvancedSwing.Chapter4; import javax.swing.*; import javax.swing.text.*; import javax.swing.text.html.*; import java.io.*; public class ReplaceReader { public static void main(String[] args){ JFrame f = new JFrame( "JEditorPane with Custom Reader"); JEditorPane ep = new JEditorPane(); f.getContentPane().add(new JScrollPane(ep)); f.setSize(400, 300); f.setVisible(true); HTMLEditorKit kit = new HTMLEditorKit(){ public Document createDefaultDocument(){ HTMLDocument doc = new CustomHTMLDocument(getStyleSheet()); doc.setAsynchronousLoadPriority(4); doc.setTokenThreshold(100); return doc; } }; ep.setEditorKit(kit); try { Document doc = ep.getDocument(); doc.putProperty("IgnoreCharsetDirective", new Boolean(true)); kit.read(new FileReader(args[0]), doc, 0) ; } catch (Exception e){ System.out.println( "Exception while reading HTML " + e) ; } } } class CustomHTMLDocument extends HTMLDocument { CustomHTMLDocument(StyleSheet styles) { super(styles); } public HTMLEditorKit.ParserCallback getReader(int pos) { return new CustomReader(pos); } class CustomReader extends HTMLDocument.HTMLReader { public CustomReader(int pos) { super(pos); } public void flush() throws BadLocationException { System.out.println("flush called"); super.flush(); } public void handleText(char[] data, int pos) { indent(); System.out.println("handleText <" + new String(data) +">, pos " + pos); super.handleText(data, pos); } public void handleComment(char[] data, int pos) { indent(); System.out.println("handleComment <" + new String(data) +">, pos " + pos); super.handleComment(data, pos); } public void handleStartTag( HTML.Tag t, MutableAttributeSet a, int pos) { indent(); System.out.println( "handleStartTag <" + t +">, pos " + pos); indent(); System.out.println("Attributes: " + a); tagLevel++; super.handleStartTag(t, a, pos); } public void handleEndTag(HTML.Tag t, int pos) { tagLevel--; indent(); System.out.println( "handleEndTag <" + t +">, pos " + pos); super.handleEndTag(t, pos); } public void handleSimpleTag( HTML.Tag t, MutableAttributeSet a, int pos) { indent(); System.out.println("handleSimpleTag <" + t +">, pos " + pos); indent(); System.out.println("Attributes: " + a); super.handleSimpleTag(t, a, pos); } public void handleError(String errorMsg, int pos){ indent(); System.out.println("handleError <" + errorMsg + ">, pos " + pos); super.handleError(errorMsg, pos); } protected void indent() { for (int i = 0; i < tagLevel; i++) { System.out.print(" "); } } int tagLevel; } } The mechanics of this example are very simple. To install a new ParserCallback, we need to override the HTMLDocument getReader method, which requires us to implement a subclass of HTMLDocument. In this case, the subclass is called CustomHTMLDocument and, as you can see, it has an inner class called CustomHTMLReader, derived from HTMLDocument. HTMLReader, which overrides all the ParserCallback methods. In every case, the replacement method just prints its arguments and invokes the original code in its superclass so that the results of the parsing operation will be reflected in the HTMLDocument as usual. The rest of the example code arranges for the CustomHTMLDocument to be installed in a JEditorPane. As you may recall, HTMLEditorKit creates an empty HTMLDocument when it is installed in a JEditorPane; to alter this behavior and have it use a CustomHTMLDocument instead, we subclass HTMLEditorKit and override its createDefaultDocument method to return an instance of our custom Document. This customized HTMLEditorKit will use a CustomHTMLDocument whenever it is connected to a JEditorPane. In this example, we explicitly create an instance of our HTMLEditorKit and install it using the setEditorKit method, and then invoke its read method to load an HTML page using a path name supplied on the program's command line. If you wanted to use this HTMLEditorKit to read a file over the Internet using setPage, you would need to arrange for it to be the default editor kit for handling files with MIME type text/html. To do this, you need to pass an instance of the editor kit to the JEditorPane setEditorKitForContentType method that you saw earlier in this chapter: ep.setEditorKitForContentType("text/html", kit); To run the example, type the following command: java AdvancedSwing.Chapter4.ReplaceReader pathname where pathname is the full path name of an HTML page. If you have installed the example source code that accompanies this book in the directory c:\AdvancedSwing\Examples, you'll find a very simple HTML page that demonstrates some of the workings of the parser in the file c:\AdvancedSwing\Examples\AdvancedSwing\Chapter4\ ReplaceReader.html This file contains the following (trivial) HTML: <!-- A trivial HTML example --> <H1>Level 1 Heading</H1> <P align=center> A paragraph with some <B>bold</B> <FONT COLOR=red>red</FONT> text. Here is the output generated by running the example with this HTML file: handleComment < A trivial HTML example >, pos 31 handleStartTag <html>, pos 40 Attributes: handleStartTag <head>, pos 40 Attributes: handleEndTag <head>, pos 40 handleStartTag <body>, pos 40 Attributes: handleStartTag <h1>, pos 40 Attributes: handleText <Level 1 Heading>, pos 60 handleEndTag <h1>, pos 60 handleStartTag <p>, pos 80 Attributes: align=center handleText <A paragraph with some >, pos 105 handleStartTag <b>, pos 105 Attributes: handleText <bold>, pos 113 handleEndTag <b>, pos 113 handleText < >, pos 131 handleStartTag <font>, pos 131 Attributes: color=red handleText <red>, pos 141 handleEndTag <font>, pos 141 handleText < text.>, pos 148 handleEndTag <p>, pos 148 handleEndTag <body>, pos 148 handleEndTag <html>, pos 148 handleSimpleTag <__EndOfLineTag__>, pos 148 Attributes: _EndOfLineString__= flush called This output illustrates several aspects of the parser that we mentioned earlier in this section. If you compare what the parser generates with the HTML that it was given, you'll notice that despite the fact that the source document did not contain <HTML>, <HEAD>, and <BODY> tags, the parser still called the handleStartTag and handleEndTag methods just as if these tags had all been specified. The entire document therefore appears to be bracketed by an <HTML>, </HTML> pair and there is also an empty <HEAD> block. The fact that these tags are fabricated by the parser means that the HTMLDocument implementation can assume that it will always see a certain minimum set of elements no matter what the original document actually looks like. Looking a bit further down, you'll see how the parser handled the <H1> tag. As you can see, it passed on the opening and closing tags as they occurred and, in between, called handleText with the characters that make up the actual text of the heading. All text is passed to the handleText method, so there is nothing to distinguish heading text from the actual document content, except the context in which it was received. As you'll see later, the structure of the HTMLDocument that is created as a result of the method calls made by the parser reflects the context in which each of these methods were invoked. This simple document contains only one paragraph of real content (if you can call it that!). The start of the paragraph is marked with a <P> tag, which is reflected by the parser calling handleStartTag. In typical Iazy style, however, the optional closing tag (</P>) has been omitted, but the parser still called handleEndTag as if it had been present, as you can see near the end of the parser output. In fact, all the last three tags were invented by the parser. How does this happen? Internally, the parser keeps a stack of tags. As a new opening tag is detected, it is processed and then pushed onto the stack. Even opening tags that aren't found in the document (such as <HTML> in this case) are pushed onto the tag stack. When the corresponding end tag is found, the original tag is popped off the stack. In some cases, though, end tags are omitted and two consecutive start tags will be found together. For example, in a case like this: <p> First paragraph <P> the first <P> will be pushed onto the tag stack and the text will be processed. When the second <P> is encountered, the parser will check the stack and will see the original <P> there. Because paragraphs cannot be nested, the first <P> will be popped off the stack and handleEndTag will be called with <P> as the tag, thus simulating the occurrence of </P>. The second <P> will then be pushed and the process will continue. Because most HTML documents omit the </P> tag, this particular scenario occurs very frequently when parsing HTML documents. When the end of the input document is reached, the tag stack should be empty, but the odds are that it is not, because most HTML documents leave out as many tags as they can get away with. In the case of this example, an <HTML> tag and a <BODY> tag are pushed onto the stack before any content is processed and these tags stay there until the corresponding end tag is found which, in this case, will not happen. As well as these tags, there also will be the <P> tag that marked the start of the only paragraph of content in the document. Because there is no further input to read, the parser pops any tags that are left on the stack and calls the handleEndTag method for each of them. This is why it appears from the parser output as if the document ended with the sequence: </p> </BODY> </HTML> none of which actually present in the document. The text in this small document contains some markup that affects the way it will be formatted. The word bold will be rendered in bold because of the <B>, </B> tag pair, while the <FONT> tag will cause the word red to appear in red. The parser calls handleStartTag and handleEndTag once for each of these pairs of tags, with the content supplied in intervening invocations of handleText. The handleStartTag call for the <FONT> tag is more interesting because this call passes a non-empty MutableAttributeSet. As you can see from the parser output, the attributes from the parser exactly mirror the ones used with the tag the attribute name is color and its value is red. You'll see later exactly how these attributes are stored in the HTMLDocument and how they are subsequently used by the View that will draw the text. If you look at the handleStartTag call for the <P> tag, you'll see that this call passed the ALIGN=CENTER attribute in the same way. If we wanted text that was both bold and red, we would have nested the markup like this: This is <B><FONT COLOR=red>bold and red</FONT></B> text so that both attribute changes apply to the enclosed content. It is a common mistake to create plausible but incorrect markup like the following: This is <B><FONT COLOR=red>bold and red</B></FONT> text This is wrong because the </B> tag should appear after the </FONT>, unwinding the markup in the order in which it was applied. When the parser reads this sequence, it stacks the <B> and <FONT> tags, calling handleStartTag for both of them. When it reaches the </B> tag, it expects to find a <B> tag at the top of the stack, but instead it finds <FONT> and detects that the end tag </FONT> is missing. If the DTD specified that the </FONT> tag were optional then, as you saw with .the <P> tag, the parser would assume the presence of </FONT> and just call handleEndTag with the tag argument set to HTML.Tag.FONT. Because this end tag is not optional, however, this is an error and the parser instead calls handleError with an error message that describes what has happened. You can see this by running the ReplaceReader command and passing it the filename c:\AdvancedSwing\Examples\AdvancedSwing\Chapter4\ReplaceReader2.html as its argument. This file contains the markup section shown previously. You may be surprised to find that the text actually appears as it was intended to that is, the words bold and red are as they describe themselves and the word text is in black. The output from this command looks like this: handleStartTag <html>, pos 9 Attributes: handleStartTag <head>, pos 17 Attributes: handleEndTag <head>, pos 17 handleStartTag <body>, pos 17 Attributes: handleText <This is >, pos 28 handleStartTag <b>, pos 28 Attributes: handleStartTag <font>, pos 44 Attributes: color=red handleText <bold and red>, pos 60 handleError <end.missingfont??>, pos 60 handleEndTag <font>, pos 60 handleEndTag <b>, pos 60 handleError <unmatched.endtagfont??>, pos 67 handleText < text>, pos 81 handleEndTag <body>, pos 81 handleEndTag <html>, pos 89 handlesimpleTag <__EndOfLineTag__>, pos 89 Attributes: __EndOfLineString__= flush called Immediately after the handleText call for the text bold and red, you can see the handleError call that reports the missing tag. To recover the situation, the parser calls handleEndTag anyway, effectively generating the </FONT> tag that it was expecting. The effect of this is to store correct HTML in the HTMLDocument. This is why the text is correctly rendered, despite the fact that the tags were in the wrong order. Next, handleEndTag is called for the </B> tag that started the error recovery sequence. Next, the parser finds the </FONT> tag that was expected earlier. This tag, too, is incorrect in the context in which the parser finds it, because the tag at the top of the stack is now <BODY>, not <FONT> so, as you can see, handleError is called again. Notice, however, that the two invocations of handleError are slightly different: the first declares a missing tag, while the second claims there is an unmatched end tag. However, both of these calls were made when the parser found an end tag for a tag that was not at the top of the tag stack, so why does it generate different errors for these two cases? This happens because when the parser finds an end tag that seems to be out of sequence, it looks down the tag stack to see if it can find the matching open tag. If it can, as would be the case with the </B> tag, it clears the tag stack up to the matched tag and generates a missing tag error. In the second case, however, there is no <FONT> tag on the stack, so a different error results. The HTMLDocument class Now that you've seen what the HTML parser does and how the results of the parsing operation are received by the HTMLReader class, it's time to look at how the parsers output is turned into a Document. The document class used when an HTML page is loaded into JEditorPane is HTMLDocument, which is derived from DefaultStyledDocument. We spent some time in Chapter 2 looking at the internals of DefaultStyledDocument, examining the Elements and AttributeSets that are created when you use JTextPane to create documents with a mixture of fonts, colors, and other components. All of this, of course, still applies to some degree to HTMLDocument, because it inherits the behavior and implementation of DefaultStyledDocument. However, as you'll see in this section, the way in which HTMLDocument uses the basic facilities offered by DefaultStyledDocument is quite different from the way that you saw when we looked at JTextPane in Chapter 2. The Structure of an HTMLDocument Before looking in detail at the internals of HTMLDocument, let's recap the document structure used by DefaultStyledDocument upon which that of HTMLDocument is based: The logical layout of the document is built using Elements. There are two Element subclasses that are used to build a tree structure reflecting a document's organization: LeafElements that hold the actual document content and BranchElements that permit nesting by holding references to other BranchElements or to LeafElements. A LeafElement cannot contain other Elements and is always the terminal Element of a branch of the tree. In practice, in DefaultStyledDocument a BranchElement typically represents a paragraph, while a LeafElement holds a run of text. Each Element can hold an AttributeSet that describes the way in which the text that it encloses should be rendered. The AttributeSet attached to a BranchElement contains paragraph-level attributes, while those at the LeafElement level are attached to the text covered by the element. The attributes are hierarchical, so that those associated with the LeafElement take precedence over the attributes in its containing BranchElement. The attributes directly describe the way in which the associated text will be rendered. For example, there are attributes that control the foreground color and font of the text and the margins of paragraphs. To see how an HTMLDocument is structured, type the following command: java AdvancedSwing.Chapter4.ShowHTMLDocument url where url is the URL of an HTML page. A simple page that contains enough HTML to show most of the internals of HTMLDocument is included with the examples supplied with this book. If you installed these examples in the recommended location, the following URL will load the page: file:///c:\AdvancedSwing\Examples\AdvancedSwing\Chapter4\ SimplePage.html The content of the model after the page has been loaded is displayed on standard output. Because there is quite a lot of output, you might want to redirect it to a file and view it using an editor. The content of this basic HTML page is shown here: <HTML> <HEAD> <TITLE>Simple HTML Page</TITLE> </HEAD> <BODY> <!-- An HTML comment --> <H1>Level 1 heading</H1> <P> Standard paragraph with <FONT COLOR=red SIZE=+2>large red</ FONT> text. <P ALIGN=right> Right-aligned paragraph. <P> <BL> <LI>Bullet 1. <LI>Bullet 2. <LI>Bullet 3. </BL> <P> A paragraph with an embedded <IMG src="/books/3/341/1/html/2/images/lemsmall.jpg" ALT="LEM image">image. </BODY> </HTML> As you can see, this is a very basic (and not very useful) HTML page, containing a heading, a couple of paragraphs of text, a bulleted list, and an embedded image. Nevertheless, it creates an HTMLDocument that is surprisingly large. Here is the output produced by ShowHTMLDocument for this page: ===== Element Class: HTMLDocument$BlockElement Offsets [0, 161] ATTRIBUTES: (name, html) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$BlockElement Offsets [0, 5] ATTRIBUTES: (name, p-implied) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$RunElement Offsets [0, 1] ATTRIBUTES: (name, head) [StyleConstants/HTML$Tag] [ ] ===== Element Class: HTMLDocument$RunElement Offsets [1, 2] ATTRIBUTES: (name, title) [StyleConstants/HTML$Tag] [ ] ===== Element Class: HTMLDocument$RunElement Offsets [2, 3] ATTRIBUTES: (name, title) [StyleConstants/HTML$Tag] (endtag, true) [HTML$Attribute/String] [ ] ===== Element Class: HTMLDocument$RunElement Offsets [3, 4] ATTRIBUTES: (name, head) [StyleConstants/HTML$Tag] (endtag, true) [HTML$Attribute/String] [ ] ===== Element Class: HTMLDocument$RunElement Offsets [4, 5] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ ] ===== Element Class: HTMLDocument$BlockElement Offsets [5, 161] ATTRIBUTES: (name, body) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$BlockElement Offsets [5, 7] ATTRIBUTES: (name, p-implied) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$RunElement Offsets [5, 6] ATTRIBUTES: (name, comment) [StyleConstants/HTML$Tag] (comment, An HTML comment ) [HTML$Attribute/String] [ ] ===== Element Class: HTMLDocument$RunElement Offsets [6, 7] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ ] ===== Element Class: HTMLDocument$BlockElement Offsets [7, 23] ATTRIBUTES: (name, h1) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$RunElement Offsets [7, 22] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [Level 1 heading] ===== Element Class: HTMLDocument$RunElement Offsets [22, 23] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ ] ===== Element Class: HTMLDocument$BlockElement Offsets [23, 63] ATTRIBUTES: (name, p) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$RunElement Offsets [23, 47] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [Standard paragraph with ] ===== Element Class: HTMLDocument$RunElement Offsets [47, 56] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] (font, size=+2 color=red ) [ HTML$Tag/SimpleAttributeSet] [large red] ===== Element Class: HTMLDocument$RunElement Offsets [56, 62] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ text.] ===== Element Class: HTMLDocument$RunElement Offsets [62, 63] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ ] ===== Element Class: HTMLDocument$BlockElement Offsets [63, 88] ATTRIBUTES: (name, p) [StyleConstants/HTML$Tag] (align, right) [HTML$Attribute/String] ===== Element Class: HTMLDocument$RunElement Offsets [63, 87] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [Right-aligned paragraph.] ===== Element Class: HTMLDocument$RunElement Offsets [87, 88] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ ] ===== Element Class: HTMLDocument$BlockElement Offsets [88, 90] ATTRIBUTES: (name, p) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$RunElement Offsets [88, 89] ATTRIBUTES: (name, b1) [StyleConstants/HTML$UnknownTag] [ ] ===== Element Class: HTMLDocument$RunElement Offsets [89, 90] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ ] ===== Element Class: HTMLDocument$BlockElement Offsets [90, 160] ATTRIBUTES: (name, u1) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$BlockElement Offsets [90, 100] ATTRIBUTES: (name, li) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$BlockElement Offsets [90, 100] ATTRIBUTES: (name, p-implied) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$RunElement Offsets [90, 99] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [Bullet 1.] ===== Element Class: HTMLDocument$RunElement Offsets [99, 100] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ ] ===== Element Class: HTMLDocument$BlockElement Offsets [100, 110] ATTRIBUTES: (name, li) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$BlockElement Offsets [100, 110] ATTRIBUTES: (name, p-implied) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$RunElement Offsets [100, 109] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [Bullet 2.] ===== Element Class: HTMLDocument$RunElement Offsets [109, 110] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ ] ===== Element Class: HTMLDocument$BlockElement Offsets [110, 160] ATTRIBUTES: (name, li) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$BlockElement Offsets [110, 122] ATTRIBUTES: (name, p-implied) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$RunElement Offsets [110, 120] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [Bullet 3. ] ===== Element Class: HTMLDocument$RunElement Offsets [120, 121] ATTRIBUTES: (name, bl) [StyleConstants/HTML$UnknownTag] (endtag, true) [HTML$Attribute/String] [ ] ===== Element Class: HTMLDocument$RunElement Offsets [121, 122] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ ] ===== Element Class: HTMLDocument$BlockElement Offsets [122, 160] ATTRIBUTES: (name, p) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$RunElement Offsets [122, 151] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [A paragraph with an embedded ] ===== Element Class: HTMLDocument$RunElement Offsets [151, 152] ATTRIBUTES: (name, img) [StyleConstants/HTML$Tag] (src, images/lemsmall.jpg) [HTML$Attribute/String] (alt, LEM image) [HTML$Attribute/String] [ ] ===== Element Class: HTMLDocument$RunElement Offsets [152, 159] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ image.] ===== Element Class: HTMLDocument$RunElement Offsets [159, 160] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ ] ===== Element Class: HTMLDocument$BlockElement Offsets [160, 161] ATTRIBUTES: (name, p) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$RunElement Offsets [160, 161] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ ] You should recognize the general structure from our earlier discussions of JTextPane in Chapter 2. Each element in the document is shown separately, with the indentation reflecting the nesting of elements. If you scan through the output, you'll notice that there are two different types of element, one of class HTMLDocument.BlockElement, the other HTMLDocument.RunElement. These are, in fact, the only element types used by HTMLDocument; the first is a BranchElement and the second a LeafElement. As their names suggest, the former basically represents a block within the original HTML document while the latter marks out actual renderable content. If you work down from the top, you probably won't be surprised to see that the document opens with a BlockElement. This Element is the root of the document structure and contains everything else within it, as you can see from the range of offsets that it covers. Associated with this Element (and with every Element) is an AttributeSet that actually contains most of the useful information from the original HTML. In the case of the root element, there is only one attribute: ===== Element Class: HTMLDocument$BlockElement Offsets [0, 161] ATTRIBUTES: (name, html) [StyleConstants/HTML$Tag] The attributes are displayed first by value and then by class. In this case, there is an attribute whose name is name with the value html. As you know, an attribute is just a key-value pair in which both the key and the value are Objects of some kind: In the representation shown here, what you see is the result of extracting both the attribute name and attribute value objects and applying the toString method to each of them. In fact, the attribute name is an object of type javax. swing, text. StyleConstants, while the class of the value is javax.swing.text.html.HTML.Tag. For clarity and to save space, we have removed the package prefix and only shown the class names themselves. The attribute that describes itself as name is the very same StyleConstants .Name-Attribute object that you were introduced to in "Attribute Sets" in Chapter 2, where we said it was the name of the AttributeSet that contained it; in a Style, it contains the name of the Style itself. In this context, the Name-Attribute is being used slightly differently. Instead of naming a Style, when it would have a string value associated with it, its value is instead of type HTML.Tag. Earlier in this section, we said that Objects of this type are the internal representation of an HTML tag and, in this case, the NameAttribute has the value HTML.Tag.HTML. In fact, this attribute represents the occurrence within the original page of the opening <HTML> tag. In general, when an HTML tag is encountered in the source Web page, it becomes an Element with an AttributeSet containing an attribute called name whose value is the Object representing that tag from the set of constant HTML.Tag objects defined by the class javax. swing. text. html. HTML. The next couple of Elements look like this: ===== Element Class: HTMLDocument$BlockElement Offsets [0, 5] ATTRIBUTES: (name, p-implied) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$RunElement Offsets [0, 1] ATTRIBUTES: (name, head) [StyleConstants/HTML$Tag] [ ] The first of these describes itself as p-implied, which means an implied paragraph. While an HTMLDocument is being built, an implied paragraph Element is usually generated as a substitute for a missing <P> tag. Here, however, it would be unusual to have a <P> tag directly after <HTML>. The only purpose that this tag appears to serve is to act as a container for the part of the HTMLDocument that precedes the <BODY> tag. The following Element represents the <HEAD> tag. In the case of this particular Web page, the <HEAD> tag was actually present but it need not have been as you saw when we looked at the Parser, if this tag had not been found in the source document, the Parser would have synthesized one and this Element would have been inserted in the HTMLDocument anyway. In our simple Web page, the HEAD block contains only <TITLE>, the text of the title itself and the closing </TITLE> tag. The representation of this sequence in the HTMLDocument is the following: ===== Element Class: HTMLDocument$RunElement Offsets [1, 2] ATTRIBUTES: (name, title) [StyleConstants/HTML$Tag] [ ] ===== Element Class: HTMLDocument$RunElement Offsets [2, 3] ATTRIBUTES: (name, title) [StyleConstants/HTML$Tag] (endtag, true) [HTML$Attribute/String] [ ] ===== Element Class: HTMLDocument$RunElement Offsets [3, 4] ATTRIBUTES: (name, head) [StyleConstants/HTML$Tag] (endtag, true) [HTML$Attribute/String] [ ] ===== Element Class: HTMLDocument$RunElement Offsets [4, 5] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ ] The first Element in this set is not a BlockElement, but a RunElement, which usually indicates that it contains renderable content. In this case, though, the RunElement has an AttributeSet containing a NameAttribute with value HTML.Tag.TITLE, identifying it as the beginning of the document title. The title itself is not actually stored in the Document as you can see, this Element is followed immediately not by the title text, but by another Element whose NameAttribute is HTML.Tag.TITLE representing the </TITLE> tag that follows the title text in the source page. Even though it has the same NameAttribute as that of the Element for the <TITLE> tag, you can tell that it represents a closing tag because it has a second attribute called HTML.Attribute.ENDTAG with the associated String value true. At this point, we have to start being careful with our terminology. In the context of DefaultStyledDocument, when we use the term attribute, we mean a member of an AttributeSet such as StyleConstants.NameAttribute or, in the case of HTMLDocument, HTML.Tag.HTML. In the context of HTML itself, though, the term attribute has a more precise meaning. Here, an attribute is a qualifier to an HTML tag. Like DefaultStyledDocument attributes, HTML attributes are specified as name-value pairs, such as ALIGN="CENTER" where ALIGN is the HTML attribute and CENTER is its value. Each HTML tag has a set of valid HTML attributes that may be used with it, defined by the DTD. Elements in an HTMLDocument may have attributes whose names are Objects that represent HTML attributes, of which the </TITLE> tag is an example. Every end tag contains the HTML.Attribute.ENDTAG attribute to distinguish it from the corresponding opening tag. Just as the javax. swing. text. html. HTML. Tag class defines a set of constant Objects that represent all the HTML tags that it recognizes, there is also a corresponding set of Objects of type HTML.Attribute that represent the valid HTML attributes. The sets of HTML tags and HTML attributes defined in this class are both supersets of those in the HTML 3.2 DTD, because the current Swing HTML package can parse and represent (but not necessarily display) everything in HTML 3.2 as well as some extensions from HTML 4.0 (such as style sheets, a topic that will be covered later). Because we now have two different meanings for the word attribute in use at the same time, where it is not clear from the context which is meant, we will explicitly use the term HTML attribute where necessary. Just to confuse matters further, later in this chapter, you'll meet another use of the word attribute with another, slightly different meaning. Returning to the content of the HTMLDocument, you may be wondering what happened to the document title text. It isn't stored as content within the model and it doesn't appear in the JEditorPane either, as you can see from Figure 4-11, which shows what this example Web page looks like when loaded using the ShowHTMLDocument application. Figure 4-11. A simple HTML document loaded using JEditorPane. In fact, when the HTMLReader is given the title text by the Parser, it stores it as a property of the document called Document.TitleProperty; if you want to use it to set the caption of the frame that the JEditorPane is installed in, you can use the following code to do so: frame.setTitle((String)doc.getProperty(Document.TitleProperty)); Unfortunately, the Document properties are not bound properties, so it isn't possible to register a PropertyChangeListener to pick up the title as soon as it is known. Instead, you'll either have to wait until the document has been loaded or add this code to the ParserCallback using the technique you saw earlier. The Element following the </TITLE> tag is a RunElement with the NameAttribute set to HTML.Tag.CONTENT. This special tag value represents raw content from the HTML document itself; the original text is held in the Document at the offsets indicated by the Element. In this case, the text itself consists of a single newline character. This final tag completes the <HEAD> section of the document, as you can see from the indentation of the tags in the program output. The next Element is a BlockElement that encloses the document body; as you might expect by now, it has an associated NameAttribute with value HTML.Tag.BODY. The body of this HTML file begins with a single-line comment, delimited by the usual start and end comment tags. Although the start and end markers could be considered to be tags, the HTMLDocument doesn't store the comment as a start tag/content/end tag triplet. Instead, the entire comment is stored in one Element, which makes it easy for the View that will render this comment to access it. The Element for the comment looks like this: ===== Element Class: HTMLDocument$RunElement Offsets [5, 6] ATTRIBUTES: (name, comment) [StyleConstants/HTML$Tag] (comment, An HTML comment ) [HTML$Attribute/String] [ ] Notice that this Element has a NameAttribute with value comment, as you might expect, and also an attribute called comment with the comment string stored as its value. These are, in fact, different Objects the first is an HTML.Tag.COMMENT and the second an HTML.Attribute.COMMENT. The HTML DTD does not define a COMMENT attribute this is an additional attribute created for the purpose of storing the comment within an HTMLDocument, just as the tag HTML.Tag.CONTENT was added to distinguish real document content from the internal representation of a tag and its accompanying HTML attributes. If you look at the offsets associated with this Element, you'll see that the comment isn't stored inline with the rest of the Document data it is actually held as the value of the COMMENT attribute. By contrast to the comment, the level 1 heading is not compressed into a second Element; instead, it is broken up into its constituent parts: ===== Element Class: HTMLDocument$BlockElement Offsets [7, 23] ATTRIBUTES: (name, h1) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$RunElement Offsets [7, 22] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [Level 1 heading] ===== Element Class: HTMLDocument$RunElement Offsets [22, 23] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ ] The heading is created as a BlockElement labeled as HTML.Tag.H1 wrapping a RunElement containing the heading text (the tag for which is, of course, HTML.Tag.CONTENT) and a terminating newline character. It might seem to be overkill to use a BlockElement for this purpose why not use the same shortcut used for the comment and place the heading text in a single RunElement with name HTML.Tag.H1 and the text stored as the value of another special attribute? The advantage of using a BlockElement for this is that it allows the heading to be made up of more than one run of text, yet still be rendered as heading text. This means that you can write something like this: <H1>A heading with <I>italic</I> text</H1> This particular heading would be split into three logical pieces the text before the italicized region, the italicized part itself, and the text that follows it, all bounded by the HTML.Tag.H1 BlockElement. The effect of bounding these three parts within a BlockElement is that all of them will be rendered with the drawing attributes (color, font, and so forth) appropriate for a level 1 heading, with the italics added as an extra for the word italic only. This actually works much like the paragraph and character level attributes that you saw in connection with JTextPane and DefaultStyledDocument in Chapter 2 where, in this case, the BlockElement is acting as a paragraph. You'll see more about how the drawing attributes are determined when we look at Style Sheets and Views later in this chapter. The next section of output covers the first paragraph of text in the document: ===== Element Class: HTMLDocument$BlockElement Offsets [23, 63] ATTRIBUTES: (name, p) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$RunElement Offsets [23, 47] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [Standard paragraph with ] ===== Element Class: HTMLDocument$RunElement Offsets [47, 56] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] (font, size=+2 color=red) [HTML$Tag/SimpleAttributeSet] [large red] ===== Element Class: HTMLDocument$RunElement Offsets [56, 62] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ text.] ===== Element Class: HTMLDocument$RunElement Offsets [62, 63] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ This part of the HTMLDocument is a paragraph, as indicated by the Block-view with the NameAttribute set to HTML.Tag.P, containing four RunElements, all of type HTML.Tag.CONTENT in other words, real text from the original document. The first and the last two of these Elements are relatively uninteresting because they represent text drawn with whatever rendering attributes are applied to text within a paragraph. The second Element, though, is different, because it results from the following piece of HTML: <FONT COLOR=red SIZE=+2>large red</FONT> As you can see, the <FONT> and </FONT> tags do not have separate Elements within the model as other tags seem to. Instead, the <FONT> tag has been reduced to an attribute attached to the RunElement for the text that it affects. The value associated with this attribute is another AttributeSet (actually a SimpleAttributeSet) that contains the HTML attributes from the tag. Not surprisingly, although it is not shown that way here, there is one entry in this set for each HTML attribute, together with its value. In this case, the SimpleAttributeSet contains: Notice that the attribute in the original Element that represents <FONT> is actually of type HTML.Tag and not HTML.Attribute as you might have expected, because <FONT> is, after all, an HTML tag and not an HTML attribute. A similar thing would have happened to the following HTML sequence: <I>italic text</I> where the <I> tag would have been replaced by an attribute with the name HTML.Tag.I in the RunElement for the associated text. The structure and content of the rest of the HTMLDocument follows a similar pattern and should now be readily understandable. You might find it interesting, though, to look at the structure of the bulleted list. As you would probably expect, the entire list resides within a BlockElement, within which each <LI> item has a child Element of its own. You may be surprised to see, though, that the <LI> Elements are themselves BlockElements, not RunElements. As with the heading text, the reason for this is that an <LI> tag may contain other markup we could, for example, write <LI> Bullet <FONT=RED>1</FONT> and it is clear that a BlockElement would be needed to group together the pieces of this item. Finally, the image at the end of the document is represented as a RunElement associated with a single character of data (which does not actually exist in the original HTML document itself and will not be drawn by the View that eventually renders the image): ===== Element Class: HTMLDocument$RunElement Offsets [151, 152] ATTRIBUTES: (name, img) [StyleConstants/HTML$Tag] (src, images/lemsmall.jpg) [HTML$Attribute/String] (alt, LEM image) [HTML$Attribute/String] [ ] Here, the RunElement has a NameAttribute of HTML.Tag.IMG instead of HTML.Tag.CONTENT, so you can tell immediately that this Element does not represent text. The two HTML attributes that appeared in the Web page have become attributes in the associated AttributeSet, both of type HTML.Attribute and with String values. The value associated with the ALT attribute is, of course, the string from the original HTML, as is also the case with the SRC attribute. Here, though, the SRC attribute doesn't contain a full URL specification, because only a relative URL was supplied in the original HTML. When this image is displayed, it will be located by using the URL of the page itself as the base URL, together with the partial URL stored in the SRC attribute. The page URL is actually stored in the HTMLDocument as a document property called Document.StreamDescriptionProperty and, as you'll see later, it is used whenever a relative URL within the document needs to be resolved typically when following the target of a hypertext link. Supported HTML Tags and Attributes The set of HTML tags and HTML attributes recognized by the Swing HTML package is ultimately determined both by the DTD and by the set of constant HTML.Tag and HTML.Attribute objects defined by the javax. swing. text. html. HTML class. You can find out what is supported by looking in the source code, or you can use the following static methods of the HTML class: public static HTML.Tag[ ] getAllTags () ; public static HTML.Attribute[ ] getAllAttributeKeys(); The example code that accompanies this book contains a simple program that invokes these two methods and prints the results, which you can run using the command java AdvancedSwing.Chapter4.ListHTMLValues The results obtained from this command using the version of Swing available at the time are summarized in Tables 4-3 and 4-4. If you are using a later version of Swing, you might want to run this command to check for extra tags and attributes. Table 4-3. Recognized HTML Tags | a | address | applet | area | b | base | base-font | big | | block-quote | body | br | caption | center | cite | code | dd | | dfn | dir | di | d1 | dt | em | font | form | | frame | frameset | h1 | h2 | h3 | h4 | h5 | h6 | | head | hr | html | I | img | input | isindex | kbd | | li | link | map | menu | meta | noframes | object | ol | | option | P | param | pre | samp | script | select | small | | strike | s | strong | style | sub | sup | table | td | | textarea | th | title | tr | tt | u | ul | var | Table 4-4. Recognized HTML Attributes | action | align | alink | alt | archive | background | bgcolor | border | | cellpadding | cellspacing | checked | class | classid | clear | code | codebase | | codetype | color | cols | colspan | comment | compact | content | coords | | data | declare | dir | dummy | enctype | frameborder | halign | height | | href | hspace | http-equiv | id | ismap | lang | language | link | | lowsrc | marginheight | marginwidth | maxlength | method | multiple | name | nohref | | noresize | noshade | nowrap | prompt | rel | rev | rows | rowspan | | scrolling | selected | src | shape | shapes | size | standby | start | | style | target | text | title | type | usemap | valign | value | | valuetype | version | vlink | vspace | width | | | | Note, however, that the appearance of a tag or an attribute in these tables does not imply that the associated semantics are supported by the Swing HTML package. An example of this is the APPLET tag, which appears in Table 4-3 but which is not actually supported if found, it will be included in the HTMLDocument but will have no effect on the rendering of the page in JEditorPane. Loading Content into an HTMLDocument Earlier in this chapter, we saw several example programs that loaded HTML pages for the purposes of displaying them in a JEditorPane. All those examples used either the JEditorPane setPage method or the lower-level read method of HTMLEditorKit. Although in many cases this is the most convenient way to load an HTML page, there are circumstances under which it is better to use a more direct approach. Suppose, for example, that you want to fetch an HTML page and scan through it looking for hypertext links to other pages, and then fetch the targets of those links and analyze those too, continuing the process until there are no further linked documents or some threshold is reached. A good reason for doing this would be to create an index of Web documents together with their titles and, perhaps, the first few lines of content, that could be used as the basis for a document search engine. If this is what you want to do, using JEditorPane would not be appropriate because you don't actually want to display the HTML at all. It would still be useful, however, to make use of the parsing capabilities of the Swing HTML package and of the structure of the HTMLDocument that it builds, which allows easy access to the content of the original page in a form that is appropriate for automated processes like scanning for tags or creating a document content summary. All this is possible using the facilities provided by the Swing HTML package and a little extra code that you'll see in this section and the two that follow. A Class That Loads HTML Let's start with the problem of loading a document without using a JEditorPane. As you've already seen, most of the mechanics of loading an HTML page are contained in the HTMLEditorKit read method, which is called either from either the read or the setPage method of JEditorPane. Here's the definition of the HTMLEditorKit read method: public void read(Reader in, Document doc, int pos) throws IOException, BadLocationException This method reads the content from the given Reader into the Document starting at location pos. It does this by connecting a Parser to a ParserCallback that will build the structure of the HTMLDocument. As you've seen, both the Parser and the ParserCallback are implemented in the Swing text package and the read method uses them by default. To create a class that can load HTML documents without using a JEditorPane, it seems that all you would need to do would be to call the read method of HTMLEditorKit directly, having first created an HTMLDocument instance to receive the parsed content and a Reader with access to the original document source. This sounds relatively straightforward, but there are two problems: A specific Reader reads bytes from an InputStream and converts it to Unicode characters according to the encoding of the data being delivered from the InputStream. To create the appropriate Reader, you need to know the encoding of the incoming data. The header block of an HTML page can contain an HTTP-EQUIV tag that specifies a character set for the body of the HTML page. This tag must be processed properly to read the page correctly. We've already discussed how this problem is solved by JEditorPane. Initially, the source document is assumed to be in the encoding of the platform on which the JEditorPane is running, so a Reader suitable for that encoding is created. If the encoding changes as a result of an HTTP-EQUIV tag or because the Web server returns an encoding specification in the content type information that precedes the HTML itself, a ChangedCharSetException is thrown by the Parser. The result of this is that a new Reader is created, using the correct character encoding, and the input stream is read again from the beginning. The problem is that all of this logic is provided not by the HTMLEditorKit read method, but by JEditorPane itself. If you want to read documents without using JEditorPane, you have to implement something equivalent to this yourself. Loading HTML is not, then, as simple as calling the HTMLEditorKit read method. If we're going to have to write additional code anyway, it's worth looking at what benefit the HTMLEditorKit gives us to determine whether it is worth calling its read method, or whether we should invoke the lower level interfaces directly. In fact, if you look at the read method, you'll find that all it does is the following: Gets a Parser by calling its own getParser method. Gets a ParserCallback by invoking the getReader method of HTMLDocument. Starts the parsing process by calling the Parser parse method, and passing it the ParserCallback, the Reader, and a boolean that indicates whether it should ignore changes of character encoding within the document. When parsing is complete, calls the ParserCallback flush method to cause it to finish building the HTMLDocument. None of these steps requires access to state information held within the HTMLEditorKit, so it doesn't seem worthwhile creating an HTMLEditorKit instance for each HTMLDocument we want to load. Because there is very little code involved in the process outlined earlier, we might as well implement it ourselves and save the memory overhead of an HTMLEditorKit for each document being loaded. If you want to load several documents in parallel, this could be a significant saving. Listing 4-7 shows the implementation of a class that can load HTML documents without using a JEditorPane. Listing 4-7 A Free-Standing Loader for HTML Documents package AdvancedSwing.Chapter4; import java.io.*; import java.net.*; import java.util.*; import javax.swing.text.*; import javax.swing.text.html.*; public class HTMLDocumentLoader { public HTMLDocument loadDocument(HTMLDocument doc, URL url, String charSet) throws IOException { doc.putProperty(Document.StreamDescriptionProperty, url); /* * This loop allows the document read to be retried if * the character encoding changes during processing. */ InputStream in = null; boolean ignoreCharSet = false; for (;;) { try { // Remove any document content doc.remove(0, doc.getLength()); URLConnection urlc = url.openConnection(); in = urlc.getInputStream(); Reader reader = (charSet == null) ? new InputStreamReader(in): new InputStreamReader(in, charSet); HTMLEditorKit.Parser parser = getParser(); HTMLEditorKit.ParserCallback htmlReader = getParserCallback(doc); parser.parse(reader, htmlReader, ignoreCharSet); htmlReader.flush(); // All done break; } catch (BadLocationException ex) { // Should not happen - throw an IOException throw new IOException(ex.getMessage()); } catch (ChangedCharSetException e) { // The character set has changed - restart charSet = getNewCharSet(e); // Prevent recursion by suppressing // further exceptions ignoreCharSet = true; // Close original input stream in.close(); // Continue the loop to read with the correct // encoding } } return doc; } public HTMLDocument loadDocument(URL url, String charSet) throws IOException { return loadDocument(kit.createDefaultDocument(), url, charSet); } public HTMLDocument loadDocument(URL url) throws IOException { return loadDocument(url, null); } // Methods that allow customization of the parser and // the callback public synchronized HTMLEditorKit.Parser getParser() { if (parser == null) { try { Class c = Class.forName("javax.swing.text.html. parser.ParserDelegator"); parser = (HTMLEditorKit.Parser)c.newInstance(); } catch (Throwable e) { } } return parser; } public synchronized HTMLEditorKit.ParserCallback getParseCallback( HTMLDocument doc) { return doc.getReader(0); } protected String getNewCharSet( ChangedCharSetException e) { String spec = e.getCharSetSpec(); if (e.keyEqualsCharSet()) { // The event contains the new CharSet return spec; } // The event contains the content type // plus ";" plus qualifiers which may // contain a "charset" directive. First // remove the content type. int index = spec.indexOf(";"); if (index != -1} { spec = spec.substring(index + 1); } // Force the string to lower case spec = spec.toLowerCase(); StringTokenizer st = new StringTokenizer(spec, " \t=", true); boolean foundCharSet = false; boolean foundEquals = false; while (st.hasMoreTokens()) { String token = st.nextToken(); if (token.equals(" ") || token.equals("\t")) { continue; } if (foundCharSet == false && foundEquals == false && token.equals("charset")) { foundCharSet = true; continue; } else if (foundEquals == false && token.equals("=")) { foundEquals = true; continue; } else if (foundEquals == true && foundCharSet == true) { return token; } // Not recognized foundCharSet = false; foundEquals = false; } //No charset found - return a guess return "8859_1"; } protected static HTMLEditorKit kit; protected static HTMLEditorKit.Parser parser; static { kit = new HTMLEditorKit(); } } This class provides three methods, all called loadDocument, that can be used to parse an HTML page into an HTMLDocument: public HTMLDocument loadDocument(HTMLDocument doc, URL url, String charSet) throws IOException public HTMLDocument loadDocument(URL url, String charSet) throws IOException public HTMLDocument loadDocument(URL url) throws IOException The first of these three methods is the most generalized version and is the one that actually does all of the real work; the other two simply call the first one, supplying defaults for some of it arguments. If you use the first form, you can supply the HTMLDocument that you would like to have populated as well as the initial character encoding for the Reader that will be created to read the page, or null if you want to use the local platform default (which will usually be the case). Supplying your own HTMLDocument is useful if you want to use a non-standard style sheet, a topic that will be covered later in this chapter. Most often, though, you'll probably use one of the two simplified methods that require you to supply only the URL of the page to be read and the source character set in the case of the second method. The third method, of course, uses the native platform encoding. The first thing that the loadDocument method does is to store the URL of the page within the document as a property called StreamDescriptionProperty. As has been mentioned before, this property is used when resolving relative URLs that might be found within the page (for example, references to images from with IMG tags). It then enters a loop that contains the logic for actually reading the page into the HTMLDocument. Before explaining why there needs to be a loop here, let's examine the code that actually loads the document content: // Remove any document content doc.remove(0, doc.getLength()); URLConnection urlc = url.openConnection(); in = urlc.getInputstream(); Reader reader = (charSet == null) ? new InputStreamReader(in) : new InputStreamReader(in, charSet); HTMLEditorKit.Parser parser = getParser(); HTMLEditorKit.ParserCallback htmlReader = getParserCallback(); parser.parse(reader, htmlReader, ignoreCharSet); htmlReader.flush(); This code starts by removing any existing content from the HTMLDocument. In most cases, there won't actually be anything in the HTMLDocument, but there are two reasons for taking this step: - Step 1.
The HTMLDocument is created by the caller of this method. Although the caller will usually be one of the other loadDocument methods, which creates an empty HTMLDocument, it could be called directly from application code, so there is no guarantee that the document is initially empty. - Step 2.
This code is executed within a loop. On the second pass of this loop, as you'll see, the HTMLDocument might contain data left over from the first pass. The next step is to create a Reader through which the document itself can be read, given the document's URL. This is a two-step process. First, a connection to the source of the document is obtained using the URL openConnection method. If the source is a Web server, this step will make a connection to the server across the network. If the file is on a local disk, the file will be opened at this point. In either case, the URLConnection object that is returned has an associated InputStream to the document that can be obtained using its getInputStream method. The second step is to wrap the InputStream with the appropriate Reader so that the incoming bytes can be correctly converted to Unicode. As we've said, creating a Reader from an InputStream is done by using the InputStreamReader class, which requires an encoding name. If an encoding is supplied as an argument to the loadDocument method, it is used here. If it is null, then the platform's default encoding will be used. Conveniently, the InputStreamReader class has two constructors, one of which allows you to supply the encoding while the other uses the default, so the correct constructor is used depending on whether this methods charSet argument is null. As we'll see later, the charSet argument can be changed while the page is being read, but let's not worry about that now. The last step is to create the Parser and the ParserCallback and call the Parser's parse method to read the Web page into the HTMLDocument. Under normal circumstances, the Parser would be supplied by HTMLEditorKit and the ParserCallback by HTMLDocument. Here, though, we delegate the creation of both of these objects to methods of the HTMLDocumentLoader class. The intention is that you can subclass HTMLDocumentLoader if you want to provide your own implementations of either of these objects. Here is how both of these methods are implemented: public HTMLEditorKit.Parser getParser() { if (parser == null) { try { Class c = Class.forName("javax.swing.text.html. parser.ParserDelegator"); parser = (HTMLEditorKit.Parser)c.newInstance(); } catch (Throwable e) { } } return parser; } public HTMLEditorKit.ParserCallback getParserCallback() { return doc.getReader(0); } The code in the getParser method is basically the same as the code used by HTMLEditorKit itself, so if this method is not overridden, HTMLDocumentLoader will use the standard Swing HTML package Parser. Similarly, the getParserCallback method uses the default ParserCallback supplied by HTMLDocument, which it obtains by calling the HTMLDocument getReader method. Another way to use a custom ParserCallback is to pass the loadDocument method your own HTMLDocument subclass with an overridden getReader method that returns your custom HTML reader, as we did in Listing 4-6. Finally, having created the Parser and ParserCallback objects, loadDocument calls the Parser parse method, giving it the ParserCallback and the Reader as arguments. The parsing takes place inside the method; when it's complete, control is returned and the parserCallback's flush method is invoked to complete the process of building the HTMLDocument. The parse method also has a third argument, a boolean, that is initially passed with value false. You'll see the purpose of this argument shortly. Assuming that all goes well, when the flush method returns, the loop that we referred to earlier is terminated and the loadDocument method returns the HTMLDocument to its caller. Now let's look at what might go wrong and why all this code is enclosed in a loop. There are a couple of error conditions that this code does not really attempt to handle. The first is the BadLocationException that, theoretically, could be thrown by the flush method. Many of the methods in the text package that deal with a Document declare that they throw this exception because badly-behaved code could supply them with an illegal document offset, or cause them to generate an illegal document offset. Because the code shown here cannot do that, this exception should never be seen, but the compiler requires us to deal with it anyway, so we simply rethrow it to the caller as an IOException. The other possible error that we can do nothing about in this method is a real IOException, which can be thrown by any method that directly or indirectly reads the page source for example, the parse method. This error is not caught here, because there is no possible recovery action at this level. The caller of loadDocument is responsible for catching IOException and doing whatever is appropriate. There is one other exception that can be thrown by the parse method ChangedCharSetException. As we said earlier in this chapter, this exception is thrown by the Parser when it detects an HTTP-EQUIV tag that directly or indirectly specifies a character encoding for the HTML page. There are two ways that this can be specified: <META HTTP-EQUIV="Charset" content="cp1251"> <META HTTP-EQUIV="Content-Type" content="text/html; charset=cp1251"> When either of these two alternatives is found, the Parser parse method throws an exception, unless its third argument is true. When we first call parse however, this argument has the value false, so the exception will be thrown and will be caught by loadDocument. When this exception is thrown, the exception contains the correct encoding to be used to translate the document from a stream of bytes to Unicode. This translation is performed by the Reader that wraps the InputStream returned by the URLConnection. What we would like to do would be to change the Reader's encoding, but this cannot be done. Instead, we have to create a new Reader and wrap it around the InputStream. Unfortunately, it isn't possible to do this with the original InputStream and guarantee correctness, because the Reader is allowed to buffer what it reads from the InputStream and the Parser can also buffer data. As a result, the InputStream will probably not be positioned correctly to make it possible to continue reading without the possibility of losing data. Instead, we have to create a new InputStream and a new Reader with the correct encoding. The only way to do this is to get a new URLConnection object by calling the URL openConnection method again. If you look back at the main body of code in the loadDocument method, that is, the part in the try block in Listing 4-7, you'll see that we actually need to repeat all of it from the beginning. That, of course, is why this code is all contained in a loop. The first time it is executed, we may have the wrong character encoding. If we do, the ChangedCharSetException is thrown, we extract the correct encoding, and then restart the loop from the beginning. Before doing this, though, we do two things. First, the charSet argument is changed to reflect the correct character set. This causes the correct Reader to be created on the second pass of the loop. Second, we change the boolean variable ignoreCharSet from false to true. This variable is passed as the third argument of the parse method and it instructs the Parser to ignore the HTTP-EQUIV directive as it reads the source. Because on the second pass of the loop the Parser will reread the document from the beginning, it will certainly find the HTTP-EQUIV directive again and would otherwise throw another ChangedCharSetException, causing this loop to continue indefinitely. Core Note The Parser throws the exception when it sees an HTTP-EQUIV line that specifies content or charset it doesn't bother to check whether the character set implies by the HTTP-EQUIV matches the one being used by the Reader. This means that there will be a redundant exception if the document being read has an HTTP-EQUIV line that specifies the same encoding as the platform's default encoding, or the one supplied to loadDocument. With the current design of the Parser, there is no way to avoid this. If you feel strongly about it, you can avoid it by implementing your own Parser and overriding the getParser method of HTMLDocumentLoader. You'll need to get the encoding of the Reader that is passed to the parse method, decode the HTTP-EQUIV tag to get the target encoding (using code like that shown next), and compare the two to decide whether to throw the exception. Unfortunately, the abstract class Reader does not have a method that allows you to get the encoding, because not all Readers need be derived from an InputStream, so the concept of an encoding does not always exist You'll have to check that your Reader is derived from InputStreamReader, which has a getEncoding method to give you the encoding. If the Reader you are given is not derived from InputStreamReader, you won't be able to perform this check.
The last point to make about the HTMLDocumentLoader class is the way in which it gets the new character encoding from a ChangedCharSetException. This code is not as simple as you might think it would be; to keep the details out of the loadDocument method, this code is placed in the separate getNewCharSet method, which takes a ChangedCharSetException as its argument and returns the new character encoding in String form. The reason that this code is relatively complex is that there are two ways to specify the character encoding in an HTTP-EQUIV line, as you saw earlier. In the simpler case, the new encoding is directly specified using the charset form, like this: <META HTTP-EQUIV="Charset" content="cp1251"> When this form is found in the HTML page, the ChangedCharSetException contains the character encoding itself. The ChangedCharSetException class has a method called keyEqualsCharSet, which returns true in this case, and another method called getCharSetSpec that returns the character encoding, so in this simple case, the HTMLDocumentLoader getNewCharSet method just returns whatever getCharSetSpec returns. In the other case, the HTTP-EQUIV tag contains the character encoding as part of a content-type specifier, like this: <META HTTP-EQUIV="Content-Type" content="text/html; charset=cp1251"> In this case, the keyEqualsCharSet method returns false and getCharSetSpec contains the value of the content attribute, that is text/html; charset=cp1251. To get the character encoding, it is necessary to parse this string to find the charset attribute and extract its value. The somewhat tedious code to do this can be found in the getNewCharSet method. We're not going to discuss it any further here because it isn't particularly enlightening. It's worth noting that code to do this same job also exists in JEditorPane but we can't use it because it's in a private method. Even if it were in a public method, we wouldn't want to use it because the aim of HTMLDocumentLoader is to load HTML without requiring the creation of a JEditorPane instance. It looks like we have created an HTML document loader without involving either JEditorPane or HTMLEditorKit but, if you look back at Listing 4-7, you'll see that this isn't quite true because one of the loadDocument methods contains a reference to an instance of an HTMLEditorKit: public HTMLDocument loadDocument(URL url, String charSet) throws IOException { return loadDocument( (HTMLDocument)kit.createDefaultDocument(), url, charSet); } Here, kit is an HTMLEditorKit. However, it is a static member of the HTMLDocumentLoader class, so we only need to create one HTMLEditorKit no matter how many instances of HTMLDocumentLoader are created or how many times the loadDocument method is called. We call the createDefaultDocument method of HTMLEditorKit to obtain an HTMLDocument rather than directly creating one ourselves to ensure that the document has a properly initialized style sheet. As you'll see later in this chapter, the style sheet controls how the HTML page is rendered. If you do the obvious thing, that is HTMLDocument doc = new HTMLDocument(); the document that you create will have an empty style sheet, with the result that headings, paragraphs, lists, and all other formatted elements in the document will not be rendered properly. Loading Web Pages with and without JEditorPane Now that we've created a class that can load an HTML page without involving JEditorPane, let's use it to compare two ways of doing the same thing. Earlier in this chapter, you saw an example that loaded HTML (or any other kind of content for which it has support) into a JEditorPane from a given URL. Here, we'll extend that example so that you have the option to either load the page directly into the JEditorPane or to perform an offline load using HTMLDocumentLoader and then slot the complete HTMLDocument into the JEditorPane. We'll also add some code that measures the time taken for each of these alternatives, so that we can decide whether there is anything to choose between these two approaches. The complete code for this program is shown in Listing 4-8. Listing 4-8 Using Two Different Ways to Load HTML package AdvancedSwing.Chapter4; import java.awt.*; import java.awt.event.*; import java.beans.*; import java.io.*; import java.net.*; import javax.swing.*; import javax.swing.text.*; import javax.swing.text.html.*; public class EditorPaneExample9 extends JFrame { public EditorPaneExample9() { super("JEditorPane Example 9"); pane = new JEditorPane(); pane.setEditable(false); // Read-only getContentPane().add(new JScrollPane(pane), "Center"); // Build the panel of controls JPanel panel = new JPanel(); panel.setLayout(new GridBagLayout()); GridBagConstraints c = new GridBagConstraints(); c.gridwidth = 1; c.gridheight = 1; c.anchor = GridBagConstraints.EAST; c.fill = GridBagConstraints.NONE; c.weightx = 0.0; c.weighty = 0.0; JLabel urlLabel = new JLabel("URL: ", JLabel.RIGHT); panel.add(urlLabel, c) ; JLabel loadingLabel = new JLabel("State: ", JLabel.RIGHT); c.gridy = 1; panel.add(loadingLabel, c); JLabel typeLabel = new JLabel("Type: ", JLabel.RIGHT); c.gridy = 2; panel.add(typeLabel, c); c.gridy = 3; panel.add(new JLabel(LOAD_TIME), c); c.gridy = 4; c.gridwidth = 2; c.weightx = 1.0; c.anchor = GridBagConstraints.WEST; onlineLoad = new JCheckBox("Online Load"); panel.add(onlineLoad, c); onlineLoad.setSelected(true); onlineLoad.setForeground(typeLabel.getForeground()); c.gridx = 1; c.gridy = 0; c.anchor = GridBagConstraints.EAST; c.fill = GridBagConstraints.HORIZONTAL; textField = new JTextField(32); panel.add(textField, c); loadingState = new JLabel(spaces, JLabel.LEFT); loadingState.setForeground(Color.black); c.gridy = 1; panel.add(loadingState, c); loadedType = new JLabel(spaces, JLabel.LEFT); loadedType.setForeground(Color.black); c.gridy = 2; panel. add (loadedType, c) ; timeLabel = new JLabel(""); c.gridy = 3; panel.add(t imeLabel, c) ; getContentPane().add(panel, "South"); // Change page based on text field textField.addActionListener(new ActionListener() { public void actionPerformed(ActionEvent evt) { String url = textField.getText(); try { // Check if the new page and the old // page are the same. URL newURL = new URL(url); URL loadedURL = pane.getPage(); if (loadedURL != null && loadedURL.sameFile(newURL)) { return; } // Try to display the page textField.setEnabled(false); // Disable input textField.paintInunediately(0, 0, textField.getSize().width, textField.getSize().height); setCursor(Cursor.getPredefinedCursor( Cursor.WAIT_CURSOR)); // Busy cursor loadingState.setText("Loading..."); loadingState.paintImmediately(0, 0, loadingState.getSize().width, loadingState.getSize(}.height); loadedType.setText(""); loadedType.paintImmediately(0, 0, loadedType.getSize().width, loadedType.getSize().height); timeLabel.setText(""); timeLabel.paintImmediately(0, 0, timeLabel.getSize().width, timeLabel.getSize().height); startTime = System.currentTimeMillis(); // Choose the loading method if (onlineLoad.isSelected()) { // Usual load via setPage pane.setPage(url); loadedType.setText(pane.getContentType()); } else { pane.setContentType("text/html"); loadedType.setText(pane.getContentType()); if (loader == null) { loader = new HTMLDocumentLoader(); } HTMLDocument doc = loader.loadDocument( new URL(url)); loadComplete(); pane.setDocument(doc); displayLoadTime(); } } catch (Exception e) { System.out.println(e); JOptionPane.showMessageDialog(pane, new String[] { "Unable to open file", url }, "File Open Error", JOptionPane.ERROR_MESSAGE); loadingState.setText("Failed"); textField.setEnabled(true); setCursor(Cursor.getDefaultCursor()); } } }); // Listen for page load to complete pane.addPropertyChangeListener( new PropertyChangeListener() { public void propertyChange( PropertyChangeEvent evt) { if (evt.getPropertyName().equals("page")) { loadComplete(); displayLoadTime(); } } }); } public void loadComplete() { loadingState.setText("Page loaded."); textField.setEnabled(true); // Allow entry of // new URL setCursor(Cursor.getDefaultCursor()); } public void displayLoadTime() { double loadingTime = ((double)( System.currentTimeMillis() - startTime))/lOOOd; timeLabel.setText(loadingTime + " seconds"); } public static void main(String[] args) { JFrame f = new EditorPaneExample9(); f.addWindowListener(new WindowAdapter() { public void windowClosing(WindowEvent evt) { System.exit(0); } }); f.setSize(500, 400); f.setVisible(true); } static final String spaces = " "; static final String LOAD_TIME = "Load time: "; private JCheckBox onlineLoad; private HTMLDocumentLoader loader; private JLabel loadingState; private JLabel timeLabel; private JLabel loadedType; private JTextField textField; private JEditorPane pane; private long startTime; } This program is a development of one that you first saw in Listing 4-3 when we were looking at how to gain control when an HTML page finishes loading. Here, we have added a label that will display how long the loading process takes for each file loaded and a checkbox that allows you to select the loading method, as you can see in Figure 4-12. You can start this application using the command: Figure 4-12. Loading HTML with and without using JEditorPane. java AdvancedSwing.Chapter4.EditorPaneExample9 When the checkbox is in the selected state, as is the case in Figure 4-12, an online load is performed. That is to say, the file at the given URL is loaded directly into the JEditorPane using setPage. If the checkbox is unselected, the file is loaded offline using HTMLDocumentLoader and then connected to the JEditorPane using the setDocument method. The code that performs the loading is reproduced here: startTime = System.currentTimeMillis(); // Choose the loading method if (onlineLoad.isSelected()) { // Usual load via setPage pane.setPage(url); loadedType.setText(pane.getContentType()); } else { pane.setContentType("text/html") ; loadedType.setText(pane.getContentType()); if (loader == null) { loader = new HTMLDocumentLoader(); } HTMLDocument doc = loader.loadDocument(new URL(url)); loadComplete(); pane.setDocument(doc); displayLoadTime(); } The first part of the if statement is the code from the original example that loads the file using JEditorPane setPage method. As you saw earlier in this chapter, when you use setPage, the loading takes place in a separate thread and you can get notification that the load is complete by registering a PropertyChangeListener. Because we want to measure the time taken to load the file in both the online and offline load cases, the start time is stored in the startTime member before the file is loaded. The total loading time is measured and displayed in the displayLoadTime method, which is called when the PropertyChangeEvent for the bound property page is delivered in the case of an online load and by a direct call for an offline load. If the checkbox is not selected, an offline load is carried out. Here, we are going to assume that the file is HTML, so we directly set the content type in the JEditorPane and on the screen to text/html. Setting the JEditorPane content type selects and installs an HTMLEditorKit. We don't need to use this to perform the document load, but it will be needed when we finally connect the loaded document to the JEditorPane, so that the HTMLDocument is correctly interpreted and the right Views are used to display HTML (recall from Chapter 3 that the Views are created by a ViewFactory which, in the case of JEditorPane, is part of the EditorKit). Performing the offline load is a simple matter. First, an HTMLDocument instance is created if one does not already exist. In this example, we'll only be loading one document at a time but, in fact, if you load documents in separate threads, a single HTMLDocumentLoader can be used to load as many documents as you like, because it doesn't store any per-document state that might be shared between its methods and the methods that create the Parser and the ParserCallback are synchronized. Notice also that the default implementations of the getParser and getParserCallback methods create new Parser and ParserCallback instances for each document loaded. If you override either of these methods to provide your own implementations of these objects, you should be careful to provide separate instances each time the method is called if you want to be able to load more than one document at a time. Once the HTMLDocumentLoader object has been created, the document is loaded by calling the loadDocument method, passing the URL from the URL input field. Unlike the JEditorPane setPage method, loadDocument works synchronously in the thread in which it is invoked, so if you want to perform an asynchronous load you would need to create a separate thread and add your own mechanism to indicate when page loading is complete, if this is required. In this case, there is nothing to do while the page is being loaded, so the AWT event thread is used. When loadDocument returns, the loadComplete method and the displayLoadTime methods are called. These methods update the display to show that the page has been loaded and to show how long the operation took. To give a fair comparison with the online load case, before displayLoadTime is invoked, the newly loaded document is installed in the JEditorPane using its setDocument method. To try this example out, type a URL into the URL field and press RETURN. By default, an online load (using setPage) is performed and, when the page has been loaded, the total time to complete loading is shown near the bottom of the window. You'll notice that the first time you load a file there is quite a long delay before anything seems to happen. Much of this time is spent loading and initializing classes that are being used for the first time. To eliminate this time from your measurements, you should load the same page several times and note how long each attempt takes. You can't do this directly, however, because JEditorPane will not load a page if it believes it has already been loaded. Also, the example code explicitly checks for an attempt to reload the same page because it relies on a PropertyChangeEvent for the page to re-enable the input field, and no such event will be generated when the page does not actually change. Instead, you will need to alternately load two (or more) files and record the times taken for each. Two suitable URLs are: file:///c:\AdvancedSwing\Examples\AdvancedSwing\Chapter4\LM.html file:///c:\AdvancedSwing\Examples\AdvancedSwing\Chapter4\SinplePage.html assuming, as always, that you have installed the book's examples in the directory c:\AdvancedSwing\Examples. To properly compare online and offline loading, you should start the program and then load these two files several times with online loading selected, and then restart it, select offline loading, and repeat the process. Table 4-5 shows the results of a series of measurements on my laptop; all the times are given in seconds. Table 4-5. Comparing Offline and Online Load Times for HTML Documents | Online | LM.html | 9.89 | 1.32 | 1.1 | 0.71 | 0.87 | 0.5 | | | SimplePage.html | 1.48 | 0.72 | 0.61 | 0.71 | 0.44 | 0.66 | | Offline | LM.html | 6.15 | 0.33 | 0.44 | 0.27 | 0.11 | 0.11 | | | SimplePage.html | 0.60 | 0.33 | 0.33 | 0.06 | 0.11 | 0.11 | As you can see, in all cases there is a large difference between the initial measurement and the ones that follow it, due to the time taken to load and initialize the HTML package classes. After this, the times are still slightly inconsistent, but you can see that the offline load times are much shorter than the corresponding times for online loading even ignoring the single occasion on which offline loading reloaded SimplePage.html in 0.06 seconds, the best offline time for LM.html is almost five times shorter than the fastest online time, and the longest online time of 1.32 seconds compares to the longest offline time of 0.44 seconds a factor of three improvement. Looking at SimplePage.html, the best online time here (0.44 seconds) is four times longer than the best achieved by offline loading (0.11 seconds), while the ratio of worst times is 0.72 seconds to 0.33 a factor of just over two. The message from this experiment is that it is faster to load HTML using HTMLDocumentLoader rather than setPage. However, if all you need to do is load an HTML page on demand for a user to view, there are two caveats that you should bear in mind: -
The gains to be made for a single read of a page, represented by the first column in Table 4-5, are not huge. These benefits increase for the second HTML page to be fetched because the required classes will already have been loaded and initialized by the VM. However, the time taken to load the second and subsequent pages is comparatively short and the difference may not be significant to the end user. -
The setPage method automatically fetches the page in a separate thread so that the application will continue to respond to the user while the page is being read and formatted. To achieve the same effect with HTMLDocumentLoader, you need to create your own thread to do the loading, and then schedule the set-Document call to install it into the JEditorPane in the AWT event thread using the SwingUtilities. invokeLater method. Whether this is worthwhile depends on your application and the expectations of your users. Using HTML/Document to Analyze HTML Using HTMLDocumentLoader, you can fetch an HTML page and parse it into an HTMLDocument without needing to display its content in a JEditorPane. One reason for doing this might be to analyze the content of the HTML to find hypertext links or to index its content in the same way that Web crawlers do. The structure of HTMLDocument makes it very simple to scan an HTML page to extract information, because the parser has done all the hard work of organizing the data for you. In particular, the tags and text content are separated from each other in the sense that the text is held in the HTMLDocument's content model, while the tags are stored as attributes of the elements that are mapped over the content. Therefore, you can independently extract plain text or search for specific tags or HTML attributes. In this section, we'll see two examples that demonstrate how to load an HTML page and then extract information from it. In the first example, we'll load and display an arbitrary page and then walk through it looking for hypertext links. Any links that we find will be made available so that the user can select one and immediately jump to the target page. The second example will show how to manipulate both tags and text from the same document by finding all the HTML heading tags and extracting them, together with the associated heading text. We'll use this information to build a structure that shows how the headings are nested and display it in a JTree. We'll also arrange for selection events from the tree to cause the HTML page in the JEditorPane to scroll so that the selected heading is visible, making it very easy to navigate around the original document. Searching for Hypertext Links The basic feature that we're going to use to examine the structure of an HTMLDocument is a class called ElementIterator, which, as its name suggests, allows you to iterate over the Elements of a Document.ElementIterator is in the javax. swing, text package and works with any kind of Document, not just HTML. It has two constructors: public ElementIterator(Element elem); public ElementIterator(Document doc); The first constructor creates an ElementIterator rooted at the given Element, while the second creates one that will scan the entire Document given as its argument. The basic idea is that each invocation of the next method returns the next Element in sequence: public Element next(); There is also a previous method that allows you to reverse the traversal direction and a first method that returns to the start point. The iteration terminates when every Element below the starting point has been returned, at which point the next method will return null. A typical way to use ElementIterator to traverse a Document is as follows: HTMLDocumentLoader loader = new HTMLDocumentLoader(); HTMLDocument doc = loader.loadDocument(url); ElementIterator iter = new ElementIterator(doc); Element elem; while ((elem = iter.next()) != null) { // Process element "elem" } This small piece of code will load an HTML page from a Web server, parse it into an HTMLDocument, and then examine every tag that it contains (ignoring any errors). This simple loop is the basis of both of the examples in this section. Core Note The extract shown previously demonstrates that, thanks to HTMLDocumentLoader, you can fetch and analyze HTML pages offline, without the user ever seeing them displayed in a JEditorPane. With a little more code written along the lines of the example you are about to see, you can use this mechanism to fetch a Web page at a given URL, find all of its hypertext links, and then fetch each of those and extract their links and so on. If each time you fetch a new page you were to store the URL, the document title, and the first paragraph of useful text, you would have a simple Web crawler that could automatically create an index of an entire Web site. You would, of course, need to take care of small details such as error handling, preventing recursion, and arranging for multiple threads to fetch different documents in parallel, but the basic features of the job are covered in this section.
Before we look at the code for this example, let's see how it works. If you start the program using the command java AdvancedSwing.Chapter4.EditorPaneExample10 you'll see that it is the same as the last example we used, except that the URL text field has changed to a combo box. At the moment, there is nothing in the combo box pop-up window, but you can type a URL directly into the combo box editor field and, when you press ENTER, the page will be loaded as usual. If you have the Java 2 documentation loaded on your system, you can use the HTML pages that it contains for experimentation without incurring the delays of loading over the Internet. If you have the documentation installed in the directory c:\jdk1.2.2\docs, for example, a useful starting page can be found at file:///c:\jdk1.2.2\docs\api\help-doc.html After the page has been loaded, if you open the combo box you should find that it has been populated with hypertext links from the page that has just been loaded, as shown in Figure 4-13. Figure 4-13. Extracting hypertext links from an HTML page. If you now select a link from the combo box, the target page will be loaded and any links that it contains will replace those already in the combo box popup window. As far as the implementation is concerned, most of this example is the same as the other similar programs that you have seen in this chapter. Scanning the loaded document for links and populating the combo box are activities that have been added to the code shown in Listing 4-9. A few minor changes were needed to replace the text field with a combo box, but we're not going to reproduce the entire listing here; if you are interested in seeing all of the code, you'll find it on the book's CD-ROM. Instead, we'll just look at how the list of hypertext links was created. Listing 4-9 Extracting a List of Hypertext Links from an HTML Document public URL[] findLinks(Document doc, String protocol) { Vector links = new Vector(); Vector urlNames = new Vector(); URL baseURL = (URL)doc.getProperty( Document.StreamDescriptionProperty); if (doc instanceof HTMLDocument) { Element elem = doc.getDefaultRootElement(); ElementIterator iterator = new ElementIterator(elem); while ((elem = iterator.next()) != null) { AttributeSet attrs = elem.getAttributes(); Object link = attrs.getAttribute(HTML.Tag.A); if (link instanceof AttributeSet) { Object linkAttr = ((AttributeSet)link). getAttribute(HTML.Attribute.HREF); if (linkAttr instanceof String) { try { URL linkURL = new URL( baseURL, (String)linkAttr); if (protocol == null || protocol.egualsIgnoreCase( linkURL.getProtocol())) { String linkURLName = linkURL.toString(); if (urlNames.contains( linkURLName) == false){ urlNames . addElement (linkURLName) ; links.addElement(linkURL); } } } catch (MalformedURLException e) { // Ignore invalid links } } } } } URL[] urls = new URL[links.size()]; links.copyInto(urls); links . removeAllElements () ; urlNames.removeAllElements () ; return urls; } The code that extracts the links from the document is contained in the findLinks method, shown in Listing 4-9. This method takes a Document as its argument along with an optional protocol specifier and returns an array of URL objects, one for each link that it finds. In practice, this implementation is only useful if the Document that it is passed is an HTMLDocument; if you wish, you can make this dependency explicit by changing the type of the first argument to HTMLDocument but you will, of course, have to check before calling this method that the document loaded into the JEditorPane is actually HTML. With this implementation, this test is performed by findLinks and an empty array of links is returned for anything other than HTML, which would result in no links being inserted in the combo box. The main body of this method is a loop that uses ElementIterator to walk through the entire document, looking for hypertext links. How do we identify a link? What we are looking for is a tag that originally looked something like this: <A HREF="overview-summary.html">Overview</A> Although it looks like a fully fledged HTML tag (and in fact that is exactly what it is), <A>is not represented within HTMLDocument in the same way as most other tags. In most cases, a tag becomes an Element in which the associated AttributeSet has the HTML.Tag value stored as the NameAttribute, as you saw in "The Structure of an HTMLDocument", but the <A> tag is actually stored as an attribute of the text that it is associated with. Here is how the <A> tag shown above would be stored in an HTMLDocument: ===== Element Class: HTMLDocument$RunElament Offsets [13, 21] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] (a, href=overview-summary.html ) [HTML$Tag/SimpleAttributeSet] [Overview] As you can see, the Element itself is a RunElement of type HTML.Tag.CONTENT and it covers the characters Overview, which is the text wrapped by the hypertext link. The <A> tag is to be found in the Element's AttributeSet; you can see that the type of this attribute is HTML.Tag.A, and that its associated value is another set of attributes. Locating hypertext links, then, is just a matter of looking for Elements that have an attribute called HTML.Tag.A. If you look at Listing 4-9, you'll see that this is exactly what it does, by getting the AttributeSet associated with each Element that it finds and then calling getAttribute with HTML.Tag.A as the argument. If this call returns an object of type AttributeSet, we have found a hypertext link. Core Note This code that performs this test is an example both of defensive programming and of a little shortcut that you will often find useful. First, note that in a correctly constructed HTMLDocument, if the HTML.Tag.A attribute is present, its value should always be an object of type AttributeSet. However, if a particular element does not contain an HTML.Tag.A attribute (which will be true for by far the majority of the Elements in the document, the get Attribute call will return null. As an alternative to this code, we could get away with the following: Object link = attrs.getAttribute(HTML.Tag.A); if (link != null) { AttributeSet attrSet = (AttributeSet)link; Technically, though, we are open to the possibility of a classCastException here because we haven't verified that the value of the HTML.Tag.A attribute is of the type that we expect That's why the actual code looks like this: Object link = attrs.getAttribute(HTML.Tag.A); if (link instanceof AttributeSet) { Object linkAttr = ((AttributeSet)link).getAttribute( HTML.Attribute.HREF); Now we check the type of the returned object, which is the defensive aspect, but we don't verify that it isn't null. The slightly tricky part of this code is that this test is a side effect of instanceof if the reference ft is given is null, ft returns false no matter what the type that ft is being asked to check against happens to be. Whether you use this technique in your code is a matter of personal preference, but it can save you a small amount of code occasionally.
The AttributeSet associated with an HTML.Tag.A object contains the HTML attributes that were specified along with the <A> tag in the HTML page. In the example you saw earlier, the AttributeSet would contain an attribute of type HTML.Attribute.HREF with an associated String value, which is the target of the link. As you can see from Listing 4-9, the next step is to extract this attribute and verify that it is a String. All that remains is to convert the link target to a URL and add it to the set of URLs that findLinks will return to its caller. There are a couple of issues to deal with first, though. First, HTML links are often relative to the page that they are found in, as in the following case: <A HREF="overview-summary.html">Overview</A> Here, the link overview-summary.html would be interpreted by a Web browser in the context of the URL of the page itself, which, in this example, is file: ///c:\jdk1.2.2\docs\api\help-doc.html, to produce the absolute URL file:/// c:\jdk1.2.2\docs\api\overview-summary.html This is the URL that we need to return to the caller, because this is more convenient than returning a relative URL and requiring the caller to retain and use the URL of the original page when interpreting the set of hypertext links that the page contained. Fortunately, the java.net. URL class has a constructor that builds a URL from a relative URL string and the URL of the page from which that link was extracted: URL(URL context, String spec); To use this constructor, however, we need the URL of the original page. This information was not directly passed to the findLinks method but, as you saw earlier in this chapter, the base URL is stored with the HTMLDocument as the property Document.StreamDescriptionProperty. The value of this property is extracted at the start of the findLinks method and passed to the constructor of the URL class, together with the link from the document itself. This approach still works if the <A> tag contained an absolute link, like this: <A HREF="www.phptr.com">Prentice Hall</A> because the URL constructor will ignore the context argument when the spec is an absolute URL. Every URL has an associated protocol, which determines the way in which the URL will be used. Web pages have the protocol http or, if they are stored on the local system, the alternative protocol file. Other protocols are also commonly found in HTML pages for example, you can include a link that sends mail using the mailto protocol: Send <A HREF="mailto:kt@topley.demon.co.uk">mail to the author</A> Having constructed a URL, you can use the getProtocol method to get its protocol. The findLinks method has an argument that allows you to extract links of a specific protocol, ignoring all others. For example, calling findLinks with its second argument set to http will find all links to Web pages that are not on the local disk. If you pass this argument as null, all links will be returned, irrespective of their protocol. As you can see from Listing 4-9, the filtering is performed by simply extracting the protocol from the URL and comparing it (ignoring case) with the protocol supplied to findLinks. The second issue we need to take care of in constructing the set of URLs to return is ensuring that we don't return any duplicates. As we find URLs, we add them to a Vector called links. The Vector class has a method called contains that allows you to check whether an element that you want to add is already present. Using this method, to ensure that we don't add a duplicate entry to the Vector we could write the following: // linkURL is the new URL if (!links.contains(linkURL)) { links.addElement(linkURL); } This looks fine, but there is a minor drawback here. The contains method works by comparing its argument to each entry in the Vector; it returns true when a match is found. The comparison is performed by calling the equals method of the object to be compared and passing it an item from the Vector. Both of these objects will be of type URL; the URL class overrides the equals method of java.lang.Object to perform the correct test for equality of two URLs which involves, for http URLs, checking that they refer to the same Internet host (that is, to the same Web server). However, this test is not as simple as a simple text comparison. Consider the case of the ACME company that hosts a Web server for PC sales on an Internet host called http://www.pcsales.acme.com. A typical URL served from this host might be http://www.pcsales.acme.com/index.html This company might also think that it may attract more customers by using another name for the same host, such as http://www.pcsales.com. This is, after all, a much more likely URL to come up with if you were guessing where to look for companies that sell PCs on the Internet. As a result, the following URL will also reach the same Web page on the same Web server: http://www.pcsales.com/index.html However, there is no way to see from the text forms of these URLs that they correspond to the same host. In fact, the only way to work out whether they are the same or not is to get the Internet Protocol (IP) addresses that correspond to these names and compare them. This is exactly what the URL equals method does. There is a problem with this, however, if your computer is set up to use the Domain Name Service to resolve host names to addresses and you are not connected to the network when you run these examples, because the code that performs the name lookup will be unable to connect to the Domain Name Service. On my laptop, this causes the program to hang forever. To enable you (and me) to run this example without being connected to the Internet, the findLinks method maintains a second Vector called urlNames that holds the URLs in String form, so that each entry looks like the one shown previously. Instead of checking in the links vector to see whether it has found a duplicate link, it performs a simple name comparison with the items in the urlNames Vector. Of course, this is not technically correct because it will see http://www.pcsales.acme.com and http://www.pcsales.com as different Web servers, but it is good enough for this example and it solves the problem. If you want to use this code in a production application, you can choose whether you leave this workaround in or use the correct code. When the ElementIterator next method returns null, all the Elements in the document will have been scanned and all the hypertext links loaded into the links vector. Because it is usually easier and more efficient to manipulate an array than a Vector, findLinks completes its job by allocating an array of URL references of the right size and copying the contents of the links Vector into it. It was impossible to create an array of the right size at the beginning, of course, because the number of links that would be found was not known at that point. Another Way to Scan for Tags Before we leave this example, it's worth mentioning that HTMLDocument has a method called getIterator that we could have used to help us implement the search for hypertext links, which is defined like this: public Iterator getIterator(HTML.Tag t); Given a tag, this method returns an Iterator (actually an object of type HTMLDocument.Iterator) that allows you to traverse the whole document, but only processes Elements that are associated with the tag that you supply as its argument. Listing 4-10 shows a version of the findLinks method that uses this facility. Listing 4-10 Another Way to Extract a List of Hypertext Links from an HTML Document public URL[] findLinks(Document doc, String protocol) { Vector links = new Vector(); Vector urlNames = new Vector(); URL baseURL = (URL)doc.getProperty( Document.StreamDescriptionProperty); if (doc instanceof HTMLDocument) { HTMLDocument.Iterator iterator = ((HTMLDocument)doc).getIterator(HTML.Tag.A); for ( ;iterator.isValid(); iterator.next()) { AttributeSet attrs = iterator.getAttributes(); Object linkAttr = attrs.getAttribute(HTML.Attribute.HREF); if (linkAttr instanceof String) { try { URL linkURL = new URL( baseURL, (String)linkAttr); if (protocol == null || protocol.equalsIgnoreCase( linkURL.getProtocol())) { String linkURLName = linkURL.toString(); if (urlNames.contains(linkURLName) == false) { urlNames.addElement(linkURLName); links.addElement(linkURL); } } } catch (MalformedURLException e) { // Ignore invalid links } } } } URL[] urls = new URL[links.size()]; links.copyInto(urls); links.removeAllElements(); urlNames.removeAllElements(); return urls; } If you compare this with Listing 4-9, you'll see that there aren't that many differences all the important ones have been highlighted in bold. As you can see, the first difference is that we get an Iterator object from the HTMLDocument instead of dealing directly with Elements in fact, this code doesn't use Elements at all. The loop now calls the next method of the Iterator after checking that it is positioned over a valid tag by calling its isValid method. When the Iterator is created, it is automatically placed over the first occurrence of the tag that you specify, so you should only call next after you've processed the first tag. If the document does not contain an instance of the tag you are looking for, isValid will return false straight away, so the loop shown here will not execute at all. The next difference is in how you get hold of the information provided by the Iterator. In Listing 4-9, the next method of ElementIterator returned us the next Element, which we used to extract the attributes and then look for the <A> tag. The next method of Iterator, however, is declared like this: public void next () ; So how do you get access to any information about the Element that the Iterator is positioned over? You can't get direct access to the Element, but Iterator does have three accessor methods that you can use: public HTML.Tag getTag(); public int getStartOffset(); public AttributeSet getAttributes(); The getTag method just returns the tag that was used to create the Iterator while the getstartoffset method returns the start offset of the Element that the Iterator is currently looking at. The most useful method from the point of view of this example is getAttributes. This method does not return the AttributeSet of the Element that the tag has been found in it actually returns the AttributeSet associated with that tag. In other words, this returns the set of attributes that contains the HTML.Attribute.HREF attribute that has the hypertext link target so, as you can see from Listing 4-10, we invoke getAttributes on the Iterator itself and then look for this attribute in the returned AttributeSet. The rest of the code in this method is unchanged from Listing 4-9. The choice between using getIterator as in Listing 4-10 and implementing the searching logic as we did in Listing 4-9 will depend on what you are trying to achieve. If you are searching for a single tag like <A> that is actually stored as an attribute name, you should be able to use getIterator and simplify your code a little. On the other hand, you can't use getIterator if you are looking for more than one tag or if the tag is stored as the value of the NameAttribute of the AttributeSet, as is often the case. Indeed, our next example is just such a case. At the time of writing, there is another case in which you can't use the getIterator method. If the tag you want to search for is defined as a block tag, the getIterator method returns null because the code that handles this case has not yet been written. If you want to search for a block tag, you will need to check whether the version of Swing that you are using has this feature implemented. To check whether a tag is a block tag, call its isBlock method. For example, HTML.Tag.A.isBlock() returns false, but HTML.Tag.H1.isBlock() returns true. Core Note If you want to search a document for a particular tag or set of tags and you don't know how it is stored, the easiest thing to do is to create an HTML page that contains the tag and then look at it using the showHTMLDocument application that we used earlier in this chapter. This application loads the page into a JEditorPane and then writes the content of the HTMLDocument onto standard output, so you might want to redirect its output into a file, particularly if you are using a platform that doesn't allow you access to much of the output from the commands that you run (such as DOS).
Building a Hierarchy of Document Headings Now lets look at a slightly more complex example. This time, we're going to traverse the document looking for all the heading tags that is H1, H2, H3, H4, H5, and H6. Each time we find such a tag, we'll extract the heading text and we'll use this information to build a JTree that shows the heading hierarchy within the document. This example gives you the ability to present a quick overview of what's in a document. As an added bonus, we'll implement a listener that detects selections made on the tree and scrolls the displayed Web page so that the heading selected in the tree is visible in the JEditorPane. Although this sounds like quite a challenging example, there really isn't very much to it once you've worked out how to get the information you want from the HTMLDocument. As we did last time, before looking at the code let's look at how the example itself works by typing the command: java AdvancedSwing.Chapter4.EditorPaneExample11 When the program starts, you'll see that it looks almost the same as the last example, apart from the empty JTree displayed to the right of the JEditorPane. Type the URL of an HTML page into the combo box editor and press Enter to load it and, as before, the combo box will be populated with a list of links from the page. The tree will also be populated and will show the main headings from the document in most cases, it will show the H1 tags but, if the document doesn't use any H1 tags it will show the H2 headings (or whatever the highest level of headings is). You'll also notice that the root node of the tree has the documents title associated with it. A good example that shows how this works is the Java 2 API Help page. which you can load by typing the URL file:///c:\jdk1.2.2\docs\api\help-doc.html if you have the Java 2 documentation installed in c:\jdk1.2.2\docs. Figure 4-14 shows the result of loading this page and then expanding the tree to its fullest extent. Figure 4-14. Creating a hierarchy of headings from an HTML document. As before, we're not going to bore you with all of the details of creating the JTree and adding it to the layout; instead, we'll concentrate on the most interesting new pieces of code in this example. Here is the code that builds and installs a new heading hierarchy in the tree after the page has been loaded: TreeNode node = buildHeadingTree(pane.getDocument()); tree.setModel(new DefaultTreeModel(node)); The real work is done in the buildHeadingTree method, which we'll see shortly. This method creates a TreeNode that represents the root of the document. Each heading tag will have its own TreeNode, which will be placed in the tree hierarchy in the appropriate place. When the buildHeadingTree method completes, it just returns the TreeNode for the root, which is used to create a new DefaultTreeModel that is then installed in the tree. Changing the TreeModel will cause the tree to redraw itself, so there is no need to call repaint explicitly. Incidentally, this example also creates a single instance of a TreeModel that contains only a root node and the associated text Empty, which is installed just before loading a new page so that the heading hierarchy of the old page is not left on display when the next page is being fetched and analyzed. Every TreeNode in the tree returned by the buildHeadingTree method contains information relating to one heading. For the purposes of this example, we need to retain the following details for each heading: The heading text, for display purposes. The offset of the heading within the Document model, so that we can scroll the heading into view when the part of the tree that represents the heading's TreeNode is selected. The heading level, which is used when deciding where to place the TreeNode in the tree hierarchy and could also be used to render different heading levels with different fonts if we were to provide a custom renderer for the tree (although we don't actually go that far in this example). One way to store this information would be to subclass DefaultMutableTreeNode to include the required information and add instances of this subclass directly into the tree hierarchy. While this is a perfectly feasible approach, we don't use it here. Instead, we save all the header-related information in a separate class called Header. The tree is then built using DefaultMutableTreeNode objects in which the Header is stored as the user object of each node. This allows us to keep the header information separate from the tree, making the code that extracts headings from an HTMLDocument more reusable because it doesn't need to create an object that is specific to building a tree. The code that searches for headings is contained in a single method called getNextHeading, which requires an HTMLDocument and an ElementIterator as arguments; it calls the ElementIterator's next method until it finds a header tag, then constructs a Header object and returns it. When the end of the document is reached, null is returned. None of this involves building TreeNodes. A typical way to use this method would look like this: Element elem = doc.getDefaultRootElement(); ElementIterator iterator = new ElementIterator(elem); Heading heading; while ((heading = getNextHeading(doc, iterator)) != null) { // Use the Heading object referenced by "heading" } Inside the while loop, you can do anything appropriate with the Heading object. This code is, in fact, the skeleton around which the buildHeadingTree method used in this example is based. Before looking in more detail at how the tree is built, let's examine the getNextHeading method and the Heading class, which are the reusable pieces of this example. The Heading class is a simple repository for a small amount of information. The three attributes that we need to store are passed to its constructor and there are accessor methods that can be used to retrieve them. In this example, there is no requirement to be able to change any of the attributes after the object has been created, so no mutator methods are provided. Listing 4-11 shows the implementation of this class. Listing 4-11 Storing the Attributes of a Document Heading static class Heading { public Heading(String text, int level, int offset) { this.text = text; this.level = level; this.offset = offset; } public String getText() { return text; } public int getOffset() { return offset; } public int getLevel() { return level; } public String toString() { return text; } protected String text; protected int level; protected int offset; } Notice that we have provided a toString method that returns the heading text. This is done so that the tree will display the text of the heading when it renders each TreeNode. We'll revisit this point later in this section. Now let's look at the implementation of the getNextHeading method. This method needs to do two things: -
Given an ElementIterator, advance it until it finds the next heading tag. -
Once a heading tag has been found, extract the text and build a Heading object. Finding header tags is very similar to searching for hypertext links. However, we can't use the getIterator method because headings are not stored like the <A> tag a heading tag actually creates a BlockElement with an AttributeSet in which the NameAttribute is HTML.Tag.H1 in the case of <H1>, HTML.Tag.H2 for <H2>, and so on. As noted earlier, getIterator does not work for block tags (at least not at the time of writing). The other reason we can't use getIterator (even if it worked for block tags) is that we need to search for six different tags and retrieve them all in their order of appearance within the document so that we can build the heading hierarchy properly. Because of this, we have to manually search for heading tags, as we did for hypertext links in Listing 4-9, by using the next method to advance the ElementIterator, and then getting the AttributeSet from each Element and extracting the NameAttribute. If the NameAttribute is one of the tags HTML.Tag.H1 through HTML.Tag.H6, the Element corresponds to a heading and the tag itself identifies the level of the heading. The process of identifying a heading and returning its level number (1 through 6) is implemented by the getHeadingLevel method: public int getHeadingLevel(Object type) { if (type instanceof HTML.Tag) { if (type == HTML.Tag.H1) { return 1; } if (type == HTML.Tag.H2) { return 2; } if (type == HTML.Tag.H3) { return 3; } if (type == HTML.Tag.H4) { return 4; } if (type == HTML.Tag.H5) { return 5; } if (type == HTML.Tag.H6) { return 6; } } return -1; } This method accepts an Object of any kind and checks whether it corresponds to a header tag. If it does, it returns the corresponding heading level; otherwise, it returns -1. In this example, we will always invoke getHeadingLevel with the value of the NameAttribute from an Element. In fact, we'll call this method for every Element in the document and well use the return value to distinguish Elements that correspond to heading tags from all the other Elements within the document. Using an ElementIterator in conjunction with the getHeadingLevel method allows us to identify all the headings. Now we need to get the text of the heading itself. This is not quite as simple as you might think because, as we said earlier, heading tags create BlockElements, so they don't actually contain the heading text. Instead, the text is distributed over one or more RunElements that are the children of the heading's BlockElement. This arrangement is necessary to allow for formatting within the heading text. As an example, consider what would happen in the case of the following piece of HTML: <H1>A header with <I>italic</I> text</H1> The HTMLDocument created from an HTML page with this heading would contain the following sequence of Elements: ===== Element Class: HTMLDocument$BlockElement Offsets [3, 29] ATTRIBUTES: (name, h1) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$RunElement Offsets [3, 17] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [A header with ] ===== Element Class: HTMLDocument$RunElement Offsets [17, 23] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] (font-style, italic) [CSS$Attribute/CSS$StringValue] [italic] ===== Element Class: HTMLDocument$RunElement Offsets [23, 28] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ text] ===== Element Class: HTMLDocument$RunElement Offsets [28, 29] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ ] The first Element is the BlockElement corresponding to the H1 tag as you can see, its AttributeSet contains a NameAttribute whose value is HTML.Tag.H1. This Element has three children that contain respectively the text before the italicized part, the italicized word (together with the italic attribute stored as a CSS. Attribute object, which will be described in "Style Sheets and HTML Views" ), and the text after the italicized word together with a fourth child that contains a newline. To get the heading text, we need to process all these Elements, extracting the text that they map from the Document model and concatenating it all. The complete implementation of the getNextHeading method is shown in Listing 4-12. Listing 4-12 Locating Heading Tags in ah HTMLDoeument public Heading getNextHeading(Document doc, ElementIterator iter) Element elem; while ((elem = iter.next()) != null) { AttributeSet attrs = elem.getAttributes(); Object type = attrs.getAttribute( StyleConstants.NameAttribute); int level = getHeadingLevel(type); if (level > 0) { // It is a heading - get the text String headingText = ""; int count = elem.getElementCount(); for (int i = 0; i < count; i++) { Element child = elem.getElement(i); AttributeSet cattrs = child.getAttributes(); if (cattrs.getAttribute( StyleConstants.NameAttribute) == HTML.Tag.CONTENT) { try { int offset = child.getStartOffset(); headingText += doc.getText(offset, child.getEndOffset() - offset); } catch (BadLocationException e) { } } } headingText = headingText.trim(); return new Heading(headingText, level, elem.getStartOffset()); } } return null; } For each Element returned by the ElementIterator, getNextHeading extracts the NameAttribute and passes it to the getHeadingLevel method. If this method returns -1, the Element does not correspond to a heading and the iterators next method is called to move on to the next Element. If there are no more Elements, null is returned. If the Element is a heading, the text is extracted from its RunElement children and merged into a single String and the trailing newline and any other white space at the beginning and end of the text are removed by calling the String trim method. Finally, a new Header object is created using the heading text, the heading level returned by getHeadingLevel, and the start offset of the heading's BlockElement returned to the caller. Now let's look at the code that uses getNextHeading to build a heading hierarchy in a form that can be plugged directly into a JTree. You've already seen the oudline of this method at the beginning of this section it creates an ElementIterator and repeatedly calls getNextHeading until the entire document has been traversed. As each Header object is returned by getNextHeading, it must be added to the hierarchy of TreeNodes to form the correct representation of the document's headings, reflecting the order in which they occur in the document and their relationship to each other as determined by their levels. An HTML document has up to six levels of heading, ranging from H1 at the top of the hierarchy to H6 at the bottom. Let's consider a simple example of a document containing just headings and look at how we would want to structure the TreeNodes to properly reflect the document's content: <H1>A: Level 1, number 1</H1> <H2>B: Level 2, number 1</H2> <H2>C: Level 2, number 2</H2> <H4>D: Level 4, number 1</H4> <H3>E: Level 3, number 1</H3> <H1>F: Level 1, number 2</Hl> <H4>G: Level 4, number 2</H4> For convenience, the text of each heading starts with a single letter that we'll use to refer to it in what follows. You'll notice that this is rather a disorganized document usually you would not expect to see an <H4> tag follow an <H2> with no intervening <H3>, but there is nothing in the HTML specification to make this illegal, so we will need to cater for this possibility. You'll also notice that the last tag, an <H4>, directly follows an <H1>. Let's first change the layout to show how these headings actually relate to each other, using one level of indentation each time we move down a header level: <H1>A: Level 1, number 1</H1> <H2>B: Level 2, number 1</H2> <H2>C: Level 2, number 2</H2> <H4>D: Level 4, number 1</H4> <H3>E: Level 3, number 1</H3> <H1>F: Level 1, number 2</H1> <H4>G: Level 4, number 2</H4> If you replace each line with a TreeNode, this is exactly how the TreeNodes should be connected, where the use of indentation signifies a parent-child relationship so that, for example, the TreeNodes for headings B and C will be sibling children of the TreeNode for heading A. The TreeNode for heading G will be a sibling of that for node A and both will be children of the root TreeNode (not shown here), which will contain the documents title instead of a heading. The getNextHeading method will return the headings in the order shown previously, reading from the top down. Each call will return a Heading object containing the header level (from 1 to 6). To build the tree, the buildHeadingTree method allocates a DefaultMutableTreeNode for each Heading as it is returned and connects the two by making the Heading the user object of the DefaultMutableTreeNode by passing it to the constructor: DefaultMutableTreeNode hNode = new DefaultMutableTreeNode(heading); Now let's work out how to build the correct hierarchy. The first heading, at level 1, is easy to deal with it is installed as a child of the root TreeNode. The next heading is also simple because it is a level 2 heading and the previous heading was at level 1, it should be a child of the TreeNode for heading A. The problem is, however, how do we keep a reference to the TreeNode for heading A? We could remember the last TreeNode we created, but this won't always work we don't always want to add a new TreeNode directly under the previous one, as is the case with heading C, which needs to be added beneath the TreeNode for heading A, not that of its predecessor (heading B). What we need to know, at any given time, is the location of the last TreeNode for each level of heading. To do this, we create an array of TreeNode references with one entry for each heading level and another for the root node. This gives us seven entries, with entry 0 corresponding to the root node and entries 1 through 6 for the six heading levels. You can see the code that implements this in Listing 4-13. Listing 4-13 Building a Tree of Heading Tags public TreeNode buildHeadingTree(Document doc) { String title = (String)doc.getProperty(Document.TitleProperty); if (title == null) { title = "[No title]"; } Heading rootHeading = new Heading(title, 0, 0); DefaultMutableTreeNode rootNode = new DefaultMutableTreeNode(rootHeading); DefaultMutableTreeNode lastNode[] = new DefaultMutableTreeNode[7]; int lastLevel = 0; lastNode[lastLevel] = rootNode; if (doc instanceof HTMLDocument) { Element elem = doc.getDefaultRootElement(); ElementIterator iterator = new ElementIterator(elem); Heading heading; while ((heading = getNextHeading(doc, iterator)) != null) { // Add the node to the tree DefaultMutableTreeNode hNode = new DefaultMutableTreeNode(heading); int level = heading.getLevel(); if (level > lastLevel) { for (int i = lastLevel +1; i < level; i++) { lastNode[i] = null; } lastNode[lastLevel].add(hNode); } else { int prevLevel = level - 1; while (prevLevel >= 0) { if (lastNode[prevLevel] != null) { break; } lastNode[prevLevel] = null; prevLevel--; } lastNode[prevLevel].add(hNode); } lastNode[level] = hNode; lastLevel = level; } } return rootNode; } The lastNode array holds the heading references. As you can see, the first entry in this array is initialized with the DefaultMutableTreeNode object for the document root. We also maintain a variable called lastLevel that records the level at which we last installed a heading you'll see why this is required shortly. Let's see how the tree is built up using the lastNode array to determine where to place nodes as they are created. At the start, every entry in lastNode (apart from entry 0) is null and lastLevel has value 0 (indicating that the document title has just been inserted). The first call to getNextHeading returns a heading at level 1. Because this is greater than the last installed level (because lastLevel is 0), we simply add its TreeNode object as a child of the root object that is, a child of the TreeNode in array entry 0. We also need to record the fact that the last heading added at level 1 was heading A, so we set lastNode [1] to point to the TreeNode for heading A and change lastLevel to 1. The next call to getNextHeading returns heading B at level 2. Again, this level is greater than the level recorded in lastLevel, so we add its TreeNode as a child of the TreeNode at lastNode [lastLevel] that is the TreeNode for heading A and then set lastNode [2] to the TreeNode for heading B (because this is a level 2 heading) and change lastLevel to 2. The third heading (heading C) is also at level 2, which is the same as lastLevel. Now the algorithm needs to be different we can't add it to the last TreeNode we installed, because that was also a level 2 heading. What we need to do is place it under the TreeNode for the previous level 1 heading. We can get this directly from lastNode[l], which refers to heading A. We also set lastNode [2] to the TreeNode for heading C and set lastLevel to 2 (which results in no change). Heading D is at level 4, which is again greater then lastLevel. According to the reasoning we used for the last heading, we should add the TreeNode for this heading under that for the last level 3 heading, which we will find in lastNode [3]. However, there has not yet been a level 3 heading, so lastNode [3] is null. What we need to do here is work back up the hierarchy looking for a level 2 heading, or a level 1 heading if there is no level 2 heading, or the root node if there are no level 2 or level 1 headings. The code in Listing 4-13 implements this by looping up the lastNode array from the level of the heading that we want to insert the new heading under (level 3) until it finds a non-null entry. In this case, it will find that lastNode [2] is not nul1 and that it contains the entry for heading C, so the TreeNode for heading D will be added as a child of the one for heading C. Finally, lastNode [4] will be set to point to heading D's TreeNode and lastLevel will be set to 4. The next heading is a strange one it is an <H3> following an <H4> that did not have a preceding <H3> of its own. Logically, you might think that the <H3> should appear higher in the hierarchy then the <H4> it follows, but this isn't going to be the case because the <H4> and the <H3> are both children of the heading C at level 2. In other words, the hierarchy that we will get will not be this: <H2>C: Level 2, number 2</H2> <H4>D: Level 4, number 1</H4> <H3>E: Level 3, number 1</H3> but this: <H2>C: Level 2, number 2</H2> <H4>D: Level 4, number 1</H4> <H3>E: Level 3, number 1</H3> If you think this is wrong, you could modify the code to introduce a "phantom" level 3 heading to act as the parent of heading D. However, without a lot of extra work, you won't be able to stop the JTree displaying your phantom heading, which doesn't really correspond to anything in the document. Now let's follow through what happens when heading E is returned by getNextHeading. At this point, we have the following state: lastNode[0] = the root TreeNode lastNode[1] = TreeNode for heading A lastNode[2] = TreeNode for heading C lastNode[3] = null lastNode[4] = TreeNode for heading D lastLevel = 4 Heading E is at level 3, so we want to add it as the child of lastNode [2], which is the correct thing to do because lastNode [2] is the TreeNode for heading C. This corresponds to the hierarchy shown earlier. We now set lastNode [3] to point to the TreeNode for heading E and set lastLevel to 3, giving us this state: lastNode[0] = the root TreeNode lastNode[1] = TreeNode for heading A lastNode[2] = TreeNode for heading C lastNode[3] = TreeNode for heading E lastNode[4] = TreeNode for heading D lastLevel = 3 However, there is a potential problem with this. Suppose the next heading were an <H5> in other words, we had the following sequence: <H2>C: Level 2, number 2</H2> <H4>D: Level 4, number 1</H4> <H3>E: Level 3, number 1</H3> <H5>E1: Level 5, number 1</H5> It is obvious from this that the <H5> is actually a child of heading E at level 3, so the hierarchy should be set up like this: <H2>C: Level 2, number 2</H2> <H4>D: Level 4, number 1</H4> <H3>E: Level 3, number 1</H3> <H5>E1: Level 5, number 1</H5> However, according to the logic we used before, when we get a heading at level 5, we look first for a heading at level 4 and attach its TreeNode under it. As you can see, at this point lastNode [4] points to heading D, so according to this algorithm, the TreeNode for heading El would be added under that for heading D, giving this hierarchy: <H2>C: Level 2, number 2</H2> <H4>D: Level 4, number 1</H4> <H5>E1: Level 5, number 1</H5> <H3>E: Level 3, number 1</H3> This is obviously wrong, because it looks like heading El precedes heading E in the document. We should have added it under heading E. In fact, because heading E was higher in the hierarchy than heading D, it should have blocked access to heading D for all future headings the paragraph that heading D is in has been effectively closed out by the appearance of heading E. We forgot to take account of this when updating the lastNode array. What we need to do is to set the lastNode entries for all the headings with a higher heading than the one we are inserting to null when we insert a heading at a numerically lower-level number than the previous one. This means that, after inserting heading E at level 3, we would null out the entries for headings 4, 5, and 6. In fact, we only need to null out the entries between our new level and lastLevel, because we know that there won't be any non-null lastNode entries after lastNode [lastLevel]. If we did this, the lastNode array would look like this after inserting heading E: lastNode[0] = the root TreeNode lastNode[1] = TreeNode for heading A lastNode[2] = TreeNode for heading C lastNode[3] = TreeNode for heading E lastNode[4] = null lastLevel = 3 Now if we encounter an <H5>, we see that lastNode [4] is null, so we move up to lastNode[3] which is non-null, and add its TreeNode beneath the TreeNode in lastNode [3]. In terms of this example, we would add the <H5> heading El directly under the <H3> heading E, which is the desired effect. If you look at Listing 4-13, you'll see that we do, indeed, null out the intervening entries in lastNode when the new heading level is less than lastLevel: int prevLevel = level - 1; while (prevLevel >= 0) { if (lastNode[prevLevel] != null) { break; } lastNode[prevLevel] = null; prevLevel--; } lastNode[prevLevel].add(hNode); Of the remaining two headings (F and G), the level 1 heading is the same case as the <H3> following an <H4> and the final <H4> is the same as heading C because the level number is increasing. Once the TreeNode hierarchy has been built, a new DefaultTreeModel is created and plugged into the JTree to cause the display to be updated. The tree renders each TreeNode using a default TreeCellRenderer that invokes the toString method of the node to get the text to display alongside its icon. When the tree nodes are DefaultMutableTreeNodes, as they are in this case, the toString method simply calls the toString method of the nodes user object, which, as we saw earlier, is the Header object for the associated document heading. This returns the heading text that was collected and stored by getNextHeading. The only case for which this is not true is the root node, the user object of which is a String containing the document title. The last feature of this example that we'll look at is scrolling the JEditorPane to show the heading associated with a node in the tree. To do this, we create a TreeSelectionListener and register it with the JTree, as shown in Listing 4-14. Listing 4-14 Scrolling a Document Heading into View tree.addTreeSelectionListener(new TreeSelectionListener() { public void valueChanged(TreeSelectionEvent evt) { TreePath path = evt.getNewLeadSelectionPath(); if (path != null) { DefaultMutableTreeNode node = (DefaultMutableTreeNode)path.getLastPathComponent(); Object userObject = node.getUserObject(); if (userObject instanceof Heading) { Heading heading = (Heading)userObject; try { Rectangle textRect = pane.modelToView(heading.getOffset()) ; textRect.y += 3 * textRect.height; pane.scrollRectToVisible(textRect); } catch (BadLocationException e) { } } } } }); When the user selects a node, the ValueChanged method is invoked and the TreePath object corresponding to the node is obtained from the event. The TreePath contains an entry for each TreeNode in the path from the root of the tree to the node that was selected, so we use getLastPathComponent to get a reference to the node that the user actually selected, which will be one of the DefaultMutableTreeNodes created by buildHeadingTree. To scroll the corresponding heading into view in the JEditorPane, we need the document offset of the heading that has been selected, which we get from the Heading, which is, of course, the DefaultMutableTreeNodes user object. Having obtained the document offset, we convert it to a location within the JEditorPane using the modelToView method, and then invoke scrollRectToVisible to arrange for the scrolling to take place. Because the Rectangle returned by scrollRectToVisible is only tall enough to expose the heading line itself at the bottom of the JScrollPane, we change its y coordinate so that a point three lines below the heading is brought into view. The result of this is that the actual heading appears a little way up from the bottom of the JScrollPane's viewport, allowing some of the text after the heading to be seen. Note that having obtained the user object from the selected node, we check that it is a Header object before casting it and extracting the offset. This is necessary because the user object for the root node is not a Header object it is a String containing the document title. If this test were omitted, we would get a ClassCastException when the user clicked on the document title next to the root node of the tree. Hypertext Links With the changes made to our simple HTML viewer during the development of the last two examples, we can now extract the headings from a document and allow the user to scroll immediately to a specific heading just by clicking on its node in the tree displayed to the right of the JEditorPane. The user can also activate any of the hypertext links in the document by selecting them from the combo box that is displayed below the JEditorPane. This is a useful option if the user wants to see all of the links in one place, but users expect to be able to activate hypertext links within the document itself by clicking on them. If you run the previous example again, find a hypertext link in the body of the document, and click on it, you'll find that nothing happens. In fact, when you click on a link an event is generated, but it is the programmer's job to catch the event and take the necessary action. The event used to notify the activation of a hypertext link is a HyperlinkEvent. This event is generated by the JEditorPane in the following circumstances: When the user clicks on a hypertext link within the document. As with Web browsers, active links are underlined by default for easy identification. When the mouse moves over a hypertext link having not been over a link. When the mouse moves off a hypertext link. To handle these events, you must register a HyperlinkListener using the JEditorPane addHyperlinkListener method. The HyperlinkEvent has a getEventType method that allows you to retrieve the event type; there are three possible return values, which correspond to the three events listed above: HyperlinkEvent.EventType.ACTIVATED HyperlinkEvent.EventType.ENTERED HyperlinkEvent.EventType.EXITED Note that these values are not integers, so you can't code the event handler as a switch statement with cases based on the event type. Instead, you have to write an if statement that takes account of the three possible values, as shown in Listing 4-15. Core Note Versions of Swing earlier than Swing I.I.I Beta 2 (including the first customer release of Java 2) did not generate the ENTERED and EXITED events. If you have one of these Swing releases, some of the code you'll see in this section will not work on your system.
Listing 4-15 Handling HyperlinkEvents pane.addHyperlinkListener(new HyperlinkListener(){ public void hyperlinkUpdate(HyperlinkEvent evt) { // Ignore hyperlink events if the frame is busy if (loadingPage == true) { return; } if (evt.getEventType() == HyperlinkEvent.EventType.ACTIVATED) { JEditorPane sp = (JEditorPane)evt.getSource(); if (evt instanceof HTMLFrameHyperlinkEvent) { HTMLDocument doc = ( HTMLDocument)sp.getDocument(); doc.processHTMLFrameHyperlinkEvent( (HTMLFrameHyperlinkEvent)evt); } else { loadNewPage(evt.getURL()); } } else if (evt.getEventType() == HyperlinkEvent.EventType.ENTERED) { pane.setCursor(handCursor); } else if (evt.getEventType() == HyperlinkEvent.EventType.EXITED) { pane.setCursor(defaultCursor); } } }); As well as the event type, a HyperlinkEvent has three other attributes: The event source, which can be retrieved using the getSource method. This is always the JEditorPane itself. The target URL in the form of a java.net.URL object. You can get the URL using the getURL method. A string description, to which you can get access using the getDescription method. This attribute is always the value of the HREF parameter for the link associated with the event. The event handler shown in Listing 4-15 comes from another iteration of our ongoing example program. You can try this example by typing the command java AdvancedSwing.Chapter4.EditorPaneExamplel2 This version of program looks exactly the same as the last one, but now the hypertext links have been activated. If you load a page with hypertext links in it, you'll notice three things: -
If you move the mouse over an active link, the cursor changes to a hand cursor. -
If you move the mouse away from the link, the cursor reverts to the usual default arrow cursor. -
If you clink an active link, the target page is loaded. There is a suitable HTML page in the examples for this chapter, which you can load using the URL file:///C:\AdvancedSwing\Examples\AdvancedSwing\Chapter4\linksl.html All of this behavior is implemented in the HyperlinkListener shown in Listing 4-15. When the cursor moves over a link, you get an event with type HyperlinkEvent.Event.ENTERED and when it moves away from the link, you get the corresponding Hyperlink.Event.EXITED event. When these events are received, the cursor for the JEditorPane is switched to whatever the platform supplies for the predefined hand cursor or back to the default cursor, as appropriate. However, there is a small issue to beware of here. If you select a new document from the combo box pop-up window (or click a hypertext link in the document), a new page load is started and the cursor is changed to show that the application is busy. If you are performing an offline load, the page will actually be fetched in a background thread, leaving the AWT event thread free to continue with other work. In particular, mouse events will still be tracked and it would be possible to receive a HyperlinkEvent while a page load is in progress. Naturally, we don't want to respond to these events because we want the wait cursor to remain displayed, so we invented a boolean variable called loadingPage that is set true when a page load begins and false when it ends. This variable is inspected at the top of the HyperlinkListener's hyperlinkUpdate method; if it is true, the event is ignored. This also blocks handling of the other type of event the one that is delivered when the user clicks on a hypertext link to load a new page. This, of course, is absolutely essential, because we don't want to start loading yet another page when we already have a page load in progress. The code that is executed when a HyperlinkEvent.Event.ACTIVATED event is received is, perhaps, a little more complex than you might have expected. In fact, there are two types of HyperlinkEvent. A simple HyperlinkEvent is delivered when the document in the JEditorPane is not a document that contains frames. For this type of document, switching to a new page means removing the old one completely and installing a new one. You've already seen the code to do this in the actionPerformed method of Listing 4-8. Because there is now more than one way to activate this code (from the combo box or via a hypertext link), we extracted it and placed it in a method of its own called loadPage which is used in Listing 4-15. If you need to see the details, the code is on the CD-ROM that accompanies this book. When the document in the JEditorPane has frames, however, an HTMLFrameHyperlinkEvent is delivered instead of a HyperlinkEvent. HTMLFrameHyperlinkEvent is actually a subclass of HyperlinkEvent that contains an additional attribute called target that determines where the document will be loaded. This parameter takes one of the following values: | _self | The new document replaces the frame in which the original document resides. | | _parent | The document replaces the parent of the current frame, which may be the entire HTML document, or another frame if the document contains frames within frames. | | _top | The document replaces the whole document in the JEditorPane. This has the same effect as clicking a link in a document that did not have frames. | | name | The new document is loaded into an existing frame within the current document called name. | Handling all these cases properly is not a simple matter. In fact, you need to know a lot about the internals of HTMLDocument and its Views to implement it at all. Fortunately, HTMLDocument provides a convenience method called processHTMLFrameHyperlinkEvent that does the job for us, so all we need to do to get the correct effect is to call it. This is what the code in Listing 4-15 does. Note that we only check whether the event is an HTMLFrameHyperlinkEvent for the case in which a link is being activated. However, although the code does not clearly show this, within a frame of a frame document, all three event types are actually HTMLFrameHyperlinkEvents. The code in Listing 4-15 still works, however, because an HTMLFrameHyperlinkEvent is a HyperlinkEvent we don't need any special checks for this case because we don't need to take different action as the mouse moves over a hypertext link when the document is in a frame. You can try out the behavior of a framed document by loading the Java 2 Documentation index page, which is at URL file:///c:\jdk1.2.2\docs\api\index.html if you have installed the documentation in the directory c:\jdkl.2.2\docs. The result of loading this page is shown in Figure 4-15. Figure 4-15. An HTML document with frames. As you can see, this document consists of three frames, the largest containing the API document being viewed while the other two contain various sets of links to other parts of the API. If you select a link in the main document, you'll see that only the content of that frame changes. When you selected the link, an HTMLFrameHyperlinkEvent was delivered and the code in Listing 4-15 called the processHTMLFrameHyperlinkEvent convenience method provided HTMLDocument to replace only that frame. If you look a little more closely at what is happening, however, you'll soon see that there are a few deficiencies in the current implementation of frame support that make it almost impossible to provide the same user interface when dealing with a framed document as we have achieved for a document without frames. The problems that exist at the time of writing, and the reasons that they exist, are summarized below. Core Note This description is based on Swing I.I.I with JDK 1.1.8 and Java 2 version 1.2.2. If you are using a later version of Swing or Java 2, you should check whether any of these shortcomings have been fixed.
When you move the mouse over a hypertext link in a nonframed document, an event will be delivered from the JEditorPane in response to which the cursor will be changed to show a hand. If you try this with a framed document, however, this does not happen. You can see this immediately if you move the mouse over any of the links on any of the three frames in the Java 2 API index page. The reason for this is that frames within an HTML page are actually displayed by separate instances of JEditorPane. One new JEditorPane is created for each frame. In Figure 4-15, there are actually three JEditorPanes arranged over the top of the one created by the program itself. These JEditorPanes actually load what looks to them like a nonframed document (unless, of course, there is frame nesting, in which case these nested JEditorPanes may have other JEditorPanes nested inside themselves). When the mouse moves over a link in one of these documents, a HyperlinkEvent is generated by the nested JEditorPane, but it is not visible to our application because we did not register a HyperlinkListener on it. In fact, our application doesn't know anything about these hidden JEditorPanes (nor should it), so it is not feasible to register a listener with them. As a result, there is nothing to indicate that the cursor should be changed. When you clink on a hypertext link in a frame, the event goes to the nested JEditorPane. However, for this case, there is special code that redirects the event to the "outermost" JEditorPane, on which the application has its event registered. As a result, this event is seen by our application, even though the ENTERED and EXITED events that would have been used to change the cursor were not redirected to us. Because of this, our listener will pass the request to HTMLDocument, which works out which frame should be loaded and hence which JEditorPane is affected. Notice, though, that when the page load starts, the busy cursor is not shown. When we load an ordinary page, we change the cursor in the loadPage method and change it back when we get the PropertyChangeEvent for the bound property page, which indicates that the background thread has finished fetching the page. If you look at Listing 4-15, you'll see that we don't change the cursor if we get an HTMLFrameHyperlinkEvent. The reason for this is that we wouldn't know when to switch it back! To do that, we would need to get the PropertyChangeEvent, but that, of course, is delivered not to our JEditorPane, but to the nested one into which the document is actually loaded. To make matters worse, we can't register a PropertyChangeListener with that JEditorPane for the duration of the load because the HTMLFrameHyperlinkEvent has a source object that indicates that it came from the application's JEditorPane, not the hidden one. Hence, there is no practical way for us to get a reference to the target JEditorPane. When you first load a framed document, the cursor changes to indicate that the frame is busy. When the page is loaded, the cursor changes back and the user can interact with the application again. Unfortunately, this happens long before the documents in each individual frame have finished loading. In an ideal world, the busy cursor should not be reset until all of the nested documents have been fetched, but it is very difficult to arrange for this to happen. In fact, if you are prepared to do some research into the source code of the HTML package, you can come up with solutions to all the problems described earlier. However, they are complex and may not be portable from one version of Swing to the next, so we won't attempt to go into them here. Despite the minor problems that we've outlined, the Swing frame support is worth using if you must display an HTML page that has frames. If you are in control of the HTML pages that you display to your user, however, you might be well advised to avoid or minimize your use of frames for the time being. Style Sheets and HTML Views Having looked in some detail at HTMLDocument, now let's examine how the document content is actually rendered. Earlier in this chapter, we looked at the content of the HTMLDocument produced for a simple HTML page and noted that the attributes that were created for the Elements that reflect the HTML tags contained the tags themselves and any HTML attributes that accompanied those tags. These HTML attributes do not look anything like the attributes that you saw in connection with JTextPane, which directly encoded the color and font information used by the Views to render the text that corresponding Element mapped. Nevertheless, when an HTML document is loaded into a JEditorPane, the level 1 headings look different from the level 2 headings, which in turn do not look at all like the main body text. So how do the Views know how to render the document content if they don't have the appropriate attributes in the document Elements? The answer lies with style sheets, a topic that we'll look at in the first part of this section. When you've seen how the Swing HTML package handles style sheets, we'll conclude this section with a brief look at the HTML Views that do the actual text rendering. Style Sheets It used to be the case that the browser was completely in control of the way in which the various elements of an HTML page were rendered. There was no way, for example, for the author of the Web page to influence how the browser would represent a level 1 heading and, as a result, the precise appearance of headings and other elements of the page would vary from browser to browser. This was, in fact, in line with the original design aims of HTML the Web page author was supposed to specify what should appear on the page and the browser would decide exactly how to represent it. However, with the widespread adoption of HTML as the lingua franca of the World Wide Web, the emphasis shifted from the ability to present data in an accessible fashion for the benefit of scientists, researchers, and programmers to the need to create eye-catching, professional-looking Web sites for commercial purposes. In this new environment, presentation became a major (and often the main) concern. Because HTML was not designed with precise control over presentation in mind, Web masters in charge of commercial Web sites had to resort to various techniques (or tricks) that stretched the capabilities of HTML and often relied on proprietary features of specific browsers to obtain the effects that they needed. This was not a situation that could be allowed to continue. In response to the need for greater control over the way in which HTML is presented by browsers, the World Wide Web consortium (http://www.w3c.org) created a way for the Web developer to specify how the browser should render HTML elements. Instead of making major changes to HTML, W3C created a separate feature called style sheets. A style sheet effectively supplies attributes that are applied to headings, paragraphs, and text to change the way in which they appear. The mapping between HTML tags and the required attributes is specified as a set of rules, using a style sheet language. The style sheet language in common use today is called Cascading Style Sheets, usually abbreviated to CSS, the specification for which can be found on the W3C Web site. A full description of CSS and style sheets in general is beyond the scope of this book; instead, we'll confine ourselves to looking at a few simple examples that demonstrate the mechanism and how it influences the way in which HTML documents are rendered by JEditorPane. If you are already familiar with style sheets, you can skip the next section and continue from "HTML Attributes and View Attributes". Style Sheet Overview There are three ways to use style sheets to change the appearance of an HTML document: By including a link to an external file containing a style sheet. By adding an inline style sheet in the HEAD block. Using attributes associated with individual HTML tags. You can use any combination of these three mechanisms within a single document; if you use more than one of them, there are rules that determine which rules apply in the event of a clash. The fact that there is a hierarchical relationship between style rules specified in these three ways is the reason why the word "cascading" is used to describe the CSS style sheet language rules cascade down from the most general level of specification (an external file) through the inline style sheet and finally to the tag-level overrides, with the tag-level rules having highest precedence. Lets look at a (contrived) example that uses all three techniques to see how styles sheets work and how rule clashes are resolved. Consider the HTML page shown in Listing 4-16. Listing 4-16 Using Style Sheets with HTML <HTML> <HEAD> <STYLE> <!-- H1 { color: red; font-size: 36; } --> </STYLE> <LINK REL=STYLESHEET HREF="styles.ess"> <TITLE>Document Title</TlTLE> </HEAD> <BODY> <H1>Ordinary Heading 1</H1> <H1 >Special heading 1</H1> <H1 STYLE="color: teal">Teal heading</H1> <H2>Level two heading</H2> <H3>Level three heading</H3> <P> Text in a paragraph body <P > Text in a bold italic paragraph. </BODY> </HTML> If you're not familiar with style sheets, some of the tags in this page may look unfamiliar to you. When rendered by Microsoft Internet Explorer 5.0, this page looks like Figure 4-16. Figure 4-16. An HTML document with style sheets. Although you can't see the colors of the text in this figure, it should be apparent that the various headings are colored and sized differently from each other. If you'd like to try loading this page on your own system, you'll find it in the file c:\AdvancedSwing\Examples\AdvancedSwing\Chapter4\ShowCSS.html assuming that you installed the example code in the directory c:\AdvancedSwing\Examples. Depending on how well your browser supports style sheets, you may or may not get the same result as that shown previously. Some older browsers (such as Netscape Version 3.0) don't have style sheet support at all, in which case the page will be processed exactly as if the style sheet information were not present. Ignoring for the moment the tags in the header block, you can see that this page begins with three consecutive level 1 headings, all of which are rendered differently by the browser. The first heading appears with the browser's default color and font style, but may not use the same font size as level 1 headings on pages without style sheets. The next two headings, however, are displayed in blue and teal, respectively. What makes these heading as different? The first of them is declared as follows; <H1 >Special heading 1</H1> The CLASS attribute refers to a style called Special, which is defined by the style sheet applied to this page. The presence of this attribute is what makes the heading color change from the default of black to blue. There are actually two styles sheets in operation here. The first of them is an inline style sheet in the header, bounded by <STYLE> tags: <STYLE> <!-- H1 { color: red; font-size: 36; } --> </STYLE> Within a style sheet, rules have the general form shown earlier. Each rule starts with the name of the tag to which it applies and is followed by the rule body in braces. Each entry in the body consists of a CSS attribute name, a colon, the value of the attribute, and a semicolon. In this case, the rule applies to all level 1 headings and changes their foreground color to red and their font size to 36. The complete set of CSS attribute names can be found in the CSS specification on the W3C Web site. Inline styles can only be defined within the <head> block of a Web page. To protect them from older browsers that do not recognize the STYLE tag, they are usually hidden within a comment, as shown in this example. The second style sheet connected to this HTML page is in an external file referenced by the LINK tag, which must also appear in the header block: <LINK REL=STYLESHEET HREF="styles.ess"> This tag causes the browser to read the style sheet at URL styles.css, relative to the location of the original page. Placing styles in a separate file is a useful technique that can be used to give a uniform look-and-feel to a set of Web pages because the style of all of them can be changed by simply editing the single style sheet file. In this example, the file styles .css contains the following rules: H1.Special { color: blue; } H2 { color: green; /} H3 { color: pink; } P.italicBold { font-style : italic; font-weight : bold; } The first rule in this file has the selector H1.Special, which selects level 1 headings in which the attribute CLASS has the value Special, as is the case with the second H1 tag in our example page. This rule is the reason for that heading being rendered in blue. The next two rules obviously change the foreground colors of level 2 and level 3 headings to green and pink, respectively, examples of which you can see in the Web page used in Figure 4-16, while the last rule affects paragraphs with class italicBold, changing the font style to italic and the weight to bold. In our example HTML page, this style is applied to the final paragraph: <P > Text in a bold italic paragraph. which, as you can see from Figure 4-16, is actually rendered in an italic bold font. Rules specified in the header block of an HTML page, either inline or by inclusion from an external file, affect the entire Web page. You can, however, arrange for a style change to affect only a single instance of a tag by supplying an explicit STYLE attribute with that tag, like this example: <H1 STYLE="color: teal">Teal heading</H1> which changes the foreground color of that single level 1 heading to teal. Sometimes a tag may be affected by more than one rule. This example has three rules that refer to level 1 headings the local style applied to the single tag that you have just seen and the following two from style sheets in the header block: H1 { color: red; font-size: 36; } H1.Special { color: blue; } The second of these rules applies only to level 1 headings with the CLASS attribute set to Special, but the first one applies to all level 1 headings. Both of these rules specify a change to the foreground color. When there is a clash, the more specific rule has preference, which results in headings tagged as Special being blue, not red. The font-size attribute, however, applies to all level headings, even those that do not take their foreground color from this rule. As a result, the font size of every level 1 heading will be 36, although this can be overridden by a STYLE attribute for individual tags. There are other cases in which the potential for ambiguity can arise for example, it is possible to include more than one external style sheet by adding extra LINK tags to the header block. When this is the case, the rules in files included later take precedence over those included earlier (that is, the last definition wins). By contrast, though, styles defined in the <STYLE> block override those in external style sheets, whether or not they precede the LINK tag in the HTML page. Note, however, that selection only takes place for those parts of duplicate rule other parts of an apparently overridden rule can still apply. As an example of this, suppose the following rule were added to the styles.css file included in our example HTML page: H1 { color : yellow; text-decoration: underline; } On its own, this would change the foreground color of all level 1 headings to yellow and would underline the text in those headings. However, the page itself has the following rule in its inline style sheet, which appears to clash: H1 { color: red; font-size: 36; } The rules in the inline style sheet will override those from external files, but only on an attribute-by-attribute basis so that the yellow color change in the external file will be hidden by the specification of red in the inline style sheet.The text-decoration attribute still applies, however, even though the rest of its rule has been overridden, with the result that all level 1 headings that do not have an explicit text-decoration specified in a local STYLE attribute and do not have a CLASS attribute indicating a style that changes this attribute will be underlined. You now know enough about style sheets and CSS attributes to continue with our examination of how these features determine the way in which JEditorPane renders HTML. If you're interested in learning more about style sheets, I recommend Marty Halls book Core Web Programming, which is also published by Prentice Hall. HTML Attributes and View Attributes Style sheets are the bridge from the HTML attributes stored in HTMLDocument and the way in which the content is rendered by the HTML Views. In fact, the Views map the HTML attributes to CSS attributes using a StyleSheet object associated with the HTMLDocument and use only the resulting CSS attributes for rendering; other than for this conversion process, the Views do not make use of HTML attributes at all. You can see the actual attributes that are used for rendering an HTML page by typing the following command: java AdvancedSwing.Chapter4.ShowHTMLViews url This program writes a representation of both the HTMLDocument and of the Views generated to display the document to standard output. You can use this to analyze the page shown in Figure 4-16 by specifying the URL file:///c:\AdvancedSwing\Examples\AdvancedSwing\ Chapter4\ShowCSS.html Because there is likely to be quite a lot of output, you might want to redirect it to a file to avoid losing information. Let's look at some of the Elements within the HTMLDocument and compare the attributes stored in the model with those used by the Views. Here, for example, is the Element structure corresponding to the first level 1 heading: ===== Element Class: HTMLDocument$BlockElement Offsets [25, 43] ATTRIBUTES: (class, Special) [HTML$Attribute/String] (name, h1) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$RunElement Offsets [25, 42] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [Special heading 1] ===== Element Class: HTMLDocument$RunElement Offsets [42, 43] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ ] The Views corresponding to these Elements are as follows: javax.swing.text.html.ParagraphView; offsets [25, 43] ATTRIBUTES: (margin-bottom, 10) [CSS$Attribute/CSS$LengthValue] (font-size, x-large) [CSS$Attribute/CSS$FontSize] (margin-top, 10) [CSS$Attribute/CSS$LengthValue] (name, h1) [StyleConstants/String] (font-weight, bold) [CSS$Attribute/CSS$FontWeight] javax.swing.text.ParagraphView$Row; offsets [25, 43] ATTRIBUTES: (margin-bottom, 10) [CSS$Attribute/CSS$LengthValue (font-size, x-large) [CSS$Attribute/CSS$FontSize] (margin-top, 10) [CSS$Attribute/CSS$LengthValue] (name, h1) [StyleConstants/String] (font-weight, bold) [CSS$Attribute/CSS$FontWeight] javax.swing.text.html.InlineView; offsets [25, 42] ATTRIBUTES: [Special heading 1] javax.swing.text.html.InlineView; offsets [42, 43] ATTRIBUTES: [ ] It should be apparent that there is some similarity between this View hierarchy and the ones that we saw in Chapter 3 in connection with JTextPane. The level 1 heading has actually become a paragraph of its own mapped by a ParagraphView. Because the text fits on one line, the ParagraphView has a single child of type ParagraphView.Row, which in turn has a child of type Inlineview that directly contains the heading text. Don't worry too much at this stage about what these Views are we'll cover the Views used by the HTML ViewFactory in the next section. Turning to the attributes, the only one of interest in the model is the NameAttribute with value HTML.Tag.H1 in the first Element, which indicates a level 1 heading tag. Other than this, the model is remarkably devoid of attributes by comparison to the Views, which seem to be overloaded with them! The situation is not quite as bad as it might appear, however, because the Paragraphview.Row object inherits the AttributeSet of its parent Paragraphview, so we are actually seeing the same attributes twice. Where do all these attributes come from? The attribute tag for the level 1 heading obviously comes from the Element, but what about the others? These attributes are actually the standard CSS attributes for a level 1 heading as determined by this document's style sheet. When an HTMLDocument is created, it is initialized with a StyleSheet object that contains default CSS attributes for all HTML tags that need them. This StyleSheet is read from a plain text file that is included in the Java Active (JAR) .file from which the Swing classes are loaded. If you have the Swing source code installed on your system, you'll find it in a file called default.css in the javax\swing\text\html directory. Perhaps not surprisingly, it's written in CSS so it looks very much like the examples that we showed earlier. If you scan through the file, you'll find that it contains the following entry: h1 {font-size: x-large; font-weight: bold; margin-top: 10; margin-bottom: 10} These are, of course, exactly the attributes in the CSS attribute set that accompanies the View for the level 1 heading. The attribute set for a View is created from the Element's AttributeSet as follows: The NameAttribute is extracted and, if its value is of type HTML.Tag (which it should be), it is looked up in the StyleSheet to locate the rule containing the default CSS attributes for the tag. In the case of the level 1 heading shown previously, this is how the font-size, font-weight, margin-top, and margin-bottom attributes and their values are obtained. Any attributes whose keys are of type HTML.Tag are examined. If their associated values are of type AttributeSet, the accompanying attributes are translated one-by-one into CSS attributes and added to the View's AttributeSet. You saw an example of this type of HTML tag in "The Structure of an HTMLDocument" where a <FONT SIZE="+2" color="red"> sequence was translated into an attribute of type HTML.Tag.FONT whose value was a SimpleAttributeSet containing attributes called HTML.Attribute.SIZE and HTML.Attribute.COLOR along with the values from the original HTML. In this case, the resulting CSS AttributeSet for the View will contain a font-size attribute and a color attribute. The tag itself is not required and does not appear in the View AttributeSet. Attributes of type HTML.Attribute are converted to the corresponding CSS attribute and their values are mapped to the appropriate CSS value. We'll say more about this process shortly. Attributes of type CSS.Attribute in the Element's AttributeSet are copied over directly together with their values. No value translation is required in this case. You might find it surprising that the Element AttributeSet could contain an item of type css.Attribute you'll see how this can come about in a moment. Creating the View AttributeSet is a relatively expensive process, so the translated attributes are cached in the View and used during the rendering process. The translation process only occurs when the View is first created and when the HTMLDocument generates a DocumentEvent indicating that the HTML attributes for the Element that the View maps have changed. Core Note Actually, not all views bother with the translation from HTML to CSS attributes. As an example of this, the View that renders the HR tog uses the HTML.Attribute.WIDTH attribute if it is present. Instead of creating a new AttributeSet with CSS attributes, it just caches a reference to the AttributeSet in the Element itself. In other cases, the View converts the attributes but stores them in a private instance variable, so the showHTMLViews program that we used earlier will not be able to display them at all. Imageview, which renders inline images for the IMG tag is an example of this.
The actual translation from HTML attributes to CSS attributes is performed by a method in the class javax.swing.text.html.css, which uses a hash table that maps a key in the form of an HTML.Attribute to one or more CSS.Attribute types. The actual mapping performed is summarized in Table 4-6. Table 4-6. Mapping from HTML to CSS Attributes | HTML | CSS | Value Mapping Type | | ALIGN | Vertical-align, text-align, float | String Value | | BACKGROUND | background- image | String Value | | BGCOLOR | background-color | Color Value | | BORDER | border-width | Length Value | | CELLPADDING | padding | Length Value | | CELLSPACING | margin | Length Value | | COLOR | color | Color Value | | FACE | font-family | Font Family Value | | HEIGHT | height | Length Value | | HSPACE | padding-left, padding-right | Length Value | | MARGINWIDTH | margin-left, margin-right | Length Value | | MARGINHEIGHT | margin-top, margin-bottom | Length Value | | SIZE | font-size | Font Size Value | | TEXT | color | Color Value | | VALIGN | vertical-align | String Value | | VSPACE | padding-bottom, padding-top | Length Value | | WIDTH | width | Length Value | Although most HTML attributes map to a single CSS attribute, there are some that map to more than one. For example, the HSPACE attribute specifies the amount of space to leave to both the left and right of an image or a table. While HTML requires the same amount of space to be allocated on both sides of the object, the CSS specification allows you to specify the gap on each side individually via the padding-left and padding-right attributes. When converting an HSPACE attribute, a pair of padding-left and padding-right attributes will be generated, both specifying the same value. Converting the attribute name is half of the process it is also necessary to convert the associated value. In the View AttributeSet, an attribute value is stored as an instance of an inner class of javax.swing.text.html.CSS. The rightmost column of Table 4-6 shows the type of each HTML attribute that may be converted for storage in a View AttributeSet. The way in which this conversion is done for each of these types, and the class of the object in which it is stored, is summarized in Table 4-7. This table also describes how CSS attributes like font-weight, which may be created as a result of applying a CSS rule to an HTML tag, are stored. As an example, the usual CSS rule for the tag H1 produces bold text, which is stored as the CSS attribute CSS.Attribute.FONT_WEIGHT with a value that represents bold. There is, however, no HTML attribute that directly converts to the CSS font-weight attribute, so it does not appear in Table 4-6. Table 4-7. Mapping from HTML to CSS Attributes | Border Style Value | The CSS border-style attributes take a string value from the set DASHED, DOTTED, DOUBLE, GROOVE, INSET, NONE, OUTSET, RIDGE, SOLID. The attribute is stored in an object of type CSS.BorderStyle, which contains both the string representation and a type-safe object that represents the border style. There is one such object for each of the legal styles. | | Color Value | The color encoding for both HTML and CSS attributes is the same. If the color value starts with a #, the rest of the string (up to six characters) is treated as a red-green-blue (RGB) value encoded in hexadecimal so that, for example, #000000 is black. Otherwise, the color names black, silver, gray, white, maroon, red, purple, fuchsia, green, lime, olive, yellow, navy, blue, teal, and aqua are recognized, regardless of case. The color is converted to an instance of java.awt.Color, which is held inside a CSS.ColorValue that will be stored as the value of the CSS attribute. | | Font Family Value | The font family is a string that is copied directly, except for the value monospace, which is converted to Monospaced. The string is stored in a CSS.FontFamily object from which it is retrieved at rendering time. | | Font Size Value | A font size is stored in a CSS.FontSize object. If the font size begins with + or - , it is taken as a numeric offset to the document's base font size, otherwise the value is assumed to be a valid number. The font size, or the result of adding an offset to the base font, must be in the range 0 to 6 inclusive. If the value is outside this range, it is forced to the nearest legal value. The resulting integer is stored in the CSS.FontSize object. During rendering, this integer is used as an index into a fixed array of integers that contains the values 8, 10, 12, 14, 18, 24, and 36, representing the actual font size in point. | | Font Weight Value | A font weight is stored in a CSS.FontWeight object. The string values bold and normal are recognized and are stored as the numeric values 700 and 400 respectively. Alternatively, an explicit numeric value may be supplied. At rendering time, the value is used to determine whether to use a bold font; any value in excess of 400 selects a bold font, while any lower value uses a plain font. | | Length Value | The length value in the HTML attribute is in the form of a string. It is stored in a CSS.LengthValue object. During rendering, the numeric value is extracted from the string. The numeric value may be followed by pt to signify a size in points. | | String Value | The value of this attribute is stored unchanged, as a CSS.StringValue. | You can see how this works by looking at the View attributes that were stored for the level 1 heading in our example. Here is the complete View AttributeSet for this heading: (margin-bottom, 10) [CSS$Attribute/CSS$LengthValue] (font-size, x-large) [CSS$Attribute/CSS$FontSize] (margin-top, 10) [CSS$Attribute/CSS$LengthValue] (name, h1) [StyleConstants/String] (font-weight, bold) [CSS$Attribute/CSS$FontWeight As you can see, the attributes are all stored as objects of type CSS.Attribute and the value is stored in another object of a class that depends on the attribute type, as shown in Table 4-7. As well as HTML attributes, it is also possible to find StyleConstants attributes in the HTMLDocument attribute set. The most common of these is, of course, StyleConstants.NameAttribute which contains the tag name, but it is possible to include other attributes, typically by applying actions of the StyledEditorKit to a range of text from the HTML document itself. Applying the StyledEditorKit BoldAction, for example, will include the StyleConstants.Bold attribute. Many of these StyleConstants attributes will be mapped to the corresponding CSS attribute in the View's AttributeSet as shown in Table 4-8. Table 4-8. Mapping from StyleConstants Attributes to CSS Attributes | StyleConstants | CSS | | Alignment | text-align | | Background | background-color | | Bold | font-weight | | FirstLineIndent | text-indent | | FontFamily | font-family | | FontSize | font-size | | Foreground | color | | Italic | font-style | | LeftIndent | margin-left | | RightIndent | margin-right | | SpaceAbove | margin-top | | SpaceBelow | margin-bottom | | StrikeThrough | text-decoration | | Subscript | vertical-align | | Superscript | vertical-align | | Underline | text-decoration | Returning to our HTML page, the third level 1 heading looks like this: <H1 STYLE="color: teal">Teal heading</Hl> and here's what this heading generates in the HTMLDocument: ===== Element Class: HTMLDocument$BlockElement Offsets [43, 56] ATTRIBUTES: (color, teal) [CSS$Attribute/CSS$ColorValue] (name, h1) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$RunElement Offsets [43, 55] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [Teal heading] ===== Element Class: HTMLDocument$RunElement Offsets [55, 56] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ ] You can see that the attributes for the H1 tag contain the CSS attribute color with its associated value teal, from the STYLE clause in the heading tag. This example shows that it is possible to have attributes of type CSS.Attribute in the HTMLDocument. As we said earlier, these attributes are just copied directly to the view's AttributeSet. Because of this, by using the STYLE attribute, you can often get more precise control over the way in which an HTML element is rendered. An example of this is the ability to individually specify top, left, bottom, and right margins around inline images using the CSS attributes padding-top, padding-left, and so on, whereas HTML provides only VSPACE and HSPACE which make the left and right padding amounts equal and similarly for the top and bottom. There are, in fact, several other cases in which CSS attributes are stored within the Element AttributeSets. Common examples are the <B> and <I> tags, which are not stored within the model as HTML.Tag.B and HTML.Tag.I instead, the affected text run is allocated an Element of its own, with name HTML.Tag.CONTENT, and the CSS attribute font-weight with value bold or font-style with value italic are stored directly in the Element's AttributeSet. Changing an HTML Document's Style Sheet You've seen that the mapping between HTML attributes and the CSS attributes used by the Views to display the contents of an HTML document is determined by the content of the StyleSheet object that is associated with the document. HTMLDocument has three constructors, two of which include a StyleSheet object as arguments: public HTMLDocument(); public HTMLDocument(StyleSheet styles); public HTMLDocument(Content c, StyleSheet s); If you use the default constructor to create an HTMLDocument, you get an empty StyleSheet, which you will almost certainly need to populate yourself. StyleSheet is derived from the StyleContext class used by HTMLDocument's superclass, DefaultStyledDocument, to hold Styles, so the empty StyleSheet actually has the default style that is associated with all instances of DefaultStyledDocument, which means that all text will be rendered using a default font and a default foreground color, both of which will track the font and foreground color associated with the JEditorPane. Neither HTMLDocument nor its superclasses has a method that allows the StyleSheet to be changed after the HTMLDocument has been created, which would seem to imply that you need to create the StyleSheet for an HTMLDocument in advance and that it thereafter cannot be changed. As we'll see, though, this is not the case. If you use the setPage method to load content into a JEditorPane, the HTMLDocument for the page will be created by the createDefaultDocument method of HTMLEditorKit, which creates a default StyleSheet for you. This StyleSheet is initialized with the result of reading the default.css file referred to earlier in this section, which establishes a default set of rules for the attributes to be applied to HTML tags. This file is read only once and a single StyleSheet instance created from it, to which you can get a reference using the following method of HTMLEditorKit: public StyleSheet getStyleSheet(); The result of this is that all HTMLDocuments share one copy of the default StyleSheet, which saves memory. However, what can you do if you want to use a different StyleSheet or if you want to make some adjustments to the default StyleSheet that will affect all instances of HTMLDocument, or make changes that affect only a single document? There are several approaches that you can take, which will be explained in the following sections. You only need to concern yourself with most of these techniques if you don't have direct control over the HTML pages that you are going to load but you want to enforce your own look-and-feel on them in some way. If you can change the HTML pages themselves, of course, the easiest thing to do would be to change them to reference a different external style sheet (using the LINK tag) or, for minor and isolated changes, add inline styles sheets or even insert STYLE attributes in the individual tags. Which of these techniques is appropriate depends on how many HTML pages you need to use and the extent of the change that you want to make. If you cannot change the pages themselves, you will need to apply style sheet modifications at the HTMLDocument level. The Style Sheet Hierarchy So far, we have described the StyleSheet mechanism rather loosely and you may have got, the impression that each HTMLDocument has only a single StyleSheet associated with it. This is not strictly true: There is only one StyleSheet object associated with any given HTMLDocument, but that StyleSheet may contain nested StyleSheets. This facility is required to make it possible to load multiple style sheets using several LINK tags within an HTML page. Let's look at an example to see exactly what happens. Suppose an HTML page starts with the following set of tags: <HEAD> <LINK REL="STYLESHEET" HREF="OrgStyles.ess"> <LINK REL="STYLESHEET" HREF="JavaStyles.ess"> </HEAD> This set of tags imports what is presumably a global style sheet for an entire organization (from OrgStyles.css), followed by one that contains definitions for use within a specific team (from JavaStyles.css). Because later definitions override earlier ones, rules defined in the team style sheet will take precedence over those in the organization-wide one, which itself overrides rules in the default style sheet. If a particular style sheet does not define a rule for itself, it inherits that of its predecessor. Therefore, if OrgStyles.css defines rules for H1 and H2 tags but not for H3, and JavaStyles.css has a definition for H2 but not for H1 or H3, the style applied to H2 will be that specified in JavaStyles.css, the style for H1 will come from OrgStyles.css, and the H3 rule will be the one in the default StyleSheet. In terms of the StyleSheet associated with the HTMLDocument for this case, the situation is as shown in Figure 4-17. Figure 4-17. Management of linked style sheets.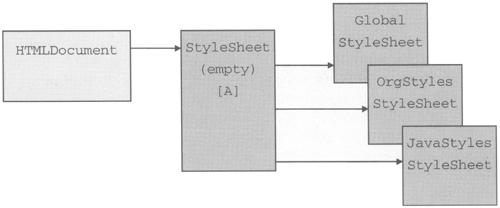 The StyleSheet that's installed in the HTMLDocument ( [A] in Figure 4-17) actually points to the set of linked style sheets, the first of which contains the default attributes loaded from the default.css file, which we will refer to here as the default style sheet. The HTMLDocument StyleSheet may also contain its own rules, which take precedence over those in the linked style sheets, including the default style sheet. Installing a New Default StyleSheet If the rules in the default style sheet do not suit the needs of your application, one possible approach is to install a completely new default style sheet in place of the one in the Swing JAR file. This style sheet is loaded by HTMLEditorKit the first time it needs to create an HTMLDocument and a reference to it is held as a static member variable called defaultStyles. All HTMLDocuments share a single instance of this style sheet, retrieved from defaultStyles, when they are created. You can change the reference held in defaultStyles, and therefore the default style sheet, using the setStyleSheet method: public void setStyleSheet(StyleSheet ss); The remaining problem is how to create the StyleSheet itself. One way to do this is to start with an empty sheet and add individual rules program-matically and we'll show you how to do this in "Making Changes to the Default StyleSheet". A simpler approach is to create a text file containing the new style sheet and read that instead of the default.css file. Listing 4-17 shows a method that can be used to load a new default style sheet from an external file. Core Note In some circumstances, you may be able to modify the default.css file and dispense with any programming. However, this is only likely to be possible in a development environment because it involves creating a new Swing JAR file with the modified version of default.css, or manipulating the CLASSPATH variable so that it finds an alternative version before looking in the JAR file. We're not going to cover those alternative mechanisms here.
Listing 4-17 Loading a New Style Sheet public StyleSheet loadStyleSheet(InputStream is) throws IOException { StyleSheet s = new StyleSheet(); BufferedReader reader = new BufferedReader(new InputStreamReader(is)); s.loadRules(reader, null); reader.close(); return s; } To load a style sheet, you need to create a StyleSheet object and invoke its loadRules method, passing it a Reader corresponding to the style sheet file. In this case, the loadStyleSheet method is given an InputStream and converts it to a Reader by wrapping it first with an InputStreamReader and then with a BufferedReader, to achieve the best possible performance. The loadRules method is defined as follows: public void loadRules(Reader in, URL ref) throws IOException In our example, the second argument is passed as null, but you can supply a URL that corresponds to the original file. This URL is used to resolve any relative references to other styles sheets within the file being read. If the file does not contain any external references, you can give this argument the value null. You can see how this works by typing the following command: java AdvancedSwing.Chapter4.EditorPaneExamplel3 This program loads a drastically reduced style sheet that defines styles for the document body, the paragraph tag (<P>), the anchor tag (<A>), and for headings at level 1, 2, and 3: body { font-size: 12pt; font-family: Serif; margin-left: 0; margin-right: 0; color: black } P ( font-size: 14pt; font-family: Serif; font-weight: normal; margin-top: 12 } h1 { font-size: 24pt; font-weight: bold; color: red; margin-top: 10; margin-bottom: 10 } h2 { font-size: 16; font-weight: bold; color: blue; margin-top: 10; margin-bottom: 10 } h3 { font-size: medium; font-weight: bold; font-style: italic; text-decoration: underline; color: green; margin-top: 10; margin-bottom: 10 } a { color: orange; text-decoration: underline } If you type the URL of an HTML file into the URL field, you should see that the change in style sheet makes it look very different from the way it would look when loaded into a browser or using the other examples in this chapter. You can use the following URL to load a suitable HTML page: file:///C:\AdvancedSwing\Examples\AdvancedSwing\Chapter4\links1.html The level 1 headings will be in a 24-point, bold font, and will be colored red; level 2 headings will be blue; and the text for level 3 headings will be green, italicized, and underlined. Because all the formatting is specified by the style sheet, the effect of removing most of the rules is that much of the document reverts to default formatting using the rule associated with the <P> tag, which in this case is a 14-point Serif font. Here's the code that actually loads the modified style sheet: InputStream is = EditorPaneExample13.class.getResourceAsStream( "changedDefault.ess"); if (is != null) { try { StyleSheet ss = loadStyleSheet(is); editorKit.setStyleSheet(ss); } catch (IOException e) { System.out.println("Failed to load new default style sheet"); } } The style sheet itself is in a file called changedDefault.css in the same directory as the class file for the example program; the getResourceAsStream method of java.lang.Class allows you to get an InputStream for this file given only its location relative the class file against which it is invoked. This method of locating a file does not require you to know exactly where your software has been installed on the system on which it is running. Alternatively, if you know the absolute file path of the style sheet file, you can use a FileInputStream instead: InputStream is = new FileInputStream(fileName); The InputStream is passed to the loadStyleSheet method shown in Listing 4-17, which creates a StyleSheet from the input file. This is then installed as the default style sheet by the following line of code: editorKit.setStyleSheet(ss); where editorKit is a reference to an instance of HTMLEditorKit. Note that, although the default style sheet is held as a static member of HTMLEditorKit, the method that sets it is not static, so you have to instantiate a copy of HTMLEditorKit to use it. It is important that you call this method before loading the first HTML page because, as noted earlier, HTMLEditorKit automatically loads its own default style sheet the first time it creates an HTMLDocument if a custom style sheet has not been installed. Once you have installed your own style sheet, it will be attached to every HTMLDocument, as you can verify by loading other documents into the example program either by supplying the URL or following hypertext links. Making Changes to the Default StyleSheet Loading an entirely new style sheet is sometimes much more than you need to do very often, all you'll want to do is make a few changes to the default styles. You can achieve this by using the loadRules method to import a set of changes from an external file into an existing StyleSheet. Where the rules being loaded conflict with those already in the StyleSheet, the new ones replace the old ones. To make your changes effective for all documents, just call the HTMLEditorKit getstyleSheet method to get the default style sheet (which will be loaded if necessary) and then call loadRules in the same way as was shown in Listing 4-17. Listing 4-18 shows how to modify an existing StyleSheet using the content of an external file. Listing 4-18 Modifying an Existing Style Sheet public void addToStyleSheet(StyleSheet s, InputStream is) throws IOException { BufferedReader reader = new BufferedReader(new InputStreamReader(is)); s.loadRules(reader, null); reader.close(); } The code here is almost identical to that shown in Listing 4-17, except that the new rules are loaded into the StyleSheet passed as the first argument rather than into a new StyleSheet. The code that installs the changes into the default style sheet is just as simple: // Modify the default style sheet InputStream is = EditorPaneExample14.class.getResourceAsStream ( "changedDefault.css"); if (is != null) { try { addToStyleSheet(editorKit.getStyleSheet() , is); } catch (IOException e) { System.out.println("Failed to modify default style sheet"); } } Here, the addToStyleSheet method is called, passing it the default style sheet, obtained by invoking the getStyleSheet method of HTMLEditorKit. As with setStyleSheet, this is an instance method. The change is effective for all documents created after the changes have been installed, so you needn't invoke it right away if you want to have some documents loaded with the usual styles. Usually, however, you would use this code early on in your application. You can see how this differs from the previous example with the command java AdvancedSwing.Chapter4.EditorPaneExample14 This example loads the same style sheet as shown previously, but styles in the default style sheet for which the file being read does not have a rule will be unaffected. In particular, the style sheet being loaded does not define the style for a level 4 heading. If you use the URL file:///C:\AdvancedSwing\Examples\AdvancedSwing\Chapter4\1inks1.html with both this example and the previous one, you'll see that the level 4 headings are rendered differently.This is because in the first example, the usual style for this heading level is removed as a result of replacing the default style sheet with our smaller one, whereas in the second example, because the level 4 style is not mentioned in the new style sheet, it is left unchanged. Changing the StyleSheet for Individual Documents The techniques we've used so far allow you to make global changes to the default style sheet. What should you do if you want to make style changes that are restricted to individual documents? As we've said, the style sheet mechanism supports multiple linked style sheets for a document, so you might think that the most natural way to make changes for a single document would be to create a new StyleSheet, read the rules into it using the code shown in Listing 4-17, and then link it into the document's global StyleSheet. However, at the time of writing, this is not possible because the StyleSheet methods that add and remove linked StyleSheets, which were public in earlier versions of Swing, and the instance variables that they control, have package scope and so are not accessible to application code. Instead, the only way to change the StyleSheet for an individual document is to modify the rules of the StyleSheet itself. If you refer to Figure 4-17, the StyleSheet labeled [A] is private to the HTMLDocument, so changes made here will not affect other documents. By constrast, the modifications we made in the previous two examples affected the default StyleSheet (at the top right of Figure 4-17), which is not private to the document. There are two ways to change the documents private StyleSheet. The first is to use the addToStyleSheet method that you saw in Listing 4-18 to read a new set of rules into it from a file. To do this, you need to get a reference to the private StyleSheet, which is done using the getStyleSheet method of HTMLDocument. Here's an example that loads the rules from a file called fileName into the HTMLDocument referred to by the variable doc: InputStream is = new FileInputStream(fileName); StyleSheet ss = doc.getStyleSheet(); addToStyleSheet(ss, is); Note carefully that we obtain the StyleSheet reference from HTMLDocument, not from HTMLEditorKit, which would return a reference to the default StyleSheet, and not from the private StyleSheet for this document. An alternative way to add rules to a StyleSheet is to use the StyleSheet addRule method: public void addRule(String rule); The rule argument is written with CSS grammar and may, in fact, consist of any number of rules separated by white space. Here's an example that modifies the rules used to render level 1 headings and paragraphs: StyleSheet s = doc.getStyleSheet(); s.addRule( "h1 { color: teal; text-decoration: underline; text-style: italic }" + " p { color: blue; font-family: monospace }") ; You can see the effect that this code has in practice using the command java AdvancedSwing.Chapter4.EditorPaneExample15 As with the earlier examples in this chapter, this example allows you to choose between online and offline loading using the JEditorPane setPage method or our HTMLDocumentLoader class respectively. So that you can see that style sheet changes made this way do not apply to all documents, the code shown earlier has been added into the code that is executed after an HTML page loaded using HTMLDocumentLoader has been read into its HTMLDocument. As a result, if you load documents with the Online Load box checked, an unmodified style sheet will be used. If you clear the checkbox, HTMLDocumentLoader will be used and the document's StyleSheet will be modified. As a result, all level 1 headings will be colored teal, italicized, and underlined, while text formatted by the <P> tag will be blue and rendered in a monospaced font. The easiest way to see this effect is to leave the Online Load box checked and type the URL file:///C:\AdvancedSwing\Examples\AdvancedSwing\Chapter4\links1.html to load a page and display it using the default styles. Then, clear the Online Load box and click the link at the bottom of the page. This causes another page to be loaded with a modified style sheet, as a result of which the heading and text styles will change as described above. This example works only because of the fact that the StyleSheet has the structure shown in Figure 4-17. In particular, it depends on the fact that the actual StyleSheet object installed in the HTMLDocument ([A] in Figure 4-17) is private to that document. If you allow the HTMLEditorKit to create the HTMLDocument, that will always be the case. However, when you use HTMLDocumentLoader (see Listing 4-7), you can create your own HTMLDocument or use a default one created by HTMLDocumentLoader. The code that creates the default document actually does so by invoking the createDefaultDocument method of HTMLEditorKit, which builds a StyleSheet with the appropriate structure. If you create an HTMLDocument of your own without using this method, you won't be able to apply the techniques shown in this section to it, because there is no way to create a StyleSheet like that in Figure 4-17 from application code. If the StyleSheet addStyleSheet method, which has package scope at the time of writing, is made public in the future, this situation will change. At present, if you want to modify a single document's style sheet, you can take one of the following approaches: Use HTMLDocumentLoader and allow it to create the HTMLDocument, and then apply your modifications to the style sheet after the loadDocument method returns. Use HTMLDocumentLoader, but pass it an HTMLDocument originally created using HTMLEditorKit's createDefaultDocument method. Use the JEditorPane setPage method and modify the style sheet in the PropertyChangeEvent handling code for the bound property page. The last of these choices is not very useful, however, because by the time the PropertyChangeEvent is delivered to your application, some or all of the HTML page may already have been displayed in the JEditorPane using the original style sheet. Changing the style sheet in the event handler may well cause the text to be reformatted in full view of the user. Finally, note that you can use the addRule method to make programmatic changes to any style sheet, so we could have used it when we showed you how to replace or make modifications to the default style sheet. Usually, however, it will be more convenient (and flexible) to take the approach we used in those cases and read replacement rules from an external file. The HTML Views In Chapter 3, we took a close look at the Views that are used to render the simpler text component and those managed by StyledEditorKit and saw how to customize them and to create new Views that change the appearance of the text component that they are installed in. When an HTML page is loaded in a JEditorPane, the Views that it uses are supplied by the ViewFactory of HTMLEditorKit. The basic design of the Views in the HTML package is the same as the ones that you saw in Chapter 3, except that many of them create a set of CSS attributes that are used for rendering instead of the attributes associated with the underlying document Elements. There are, as you might expect, more HTML Views than there are in the javax.swing.text package. Because these Views are very similar to the ones already described in Chapter 3, we're not going to take up much space describing them in detail here. A list of the HTML Views, the tags that they are connected with and a brief description of each of them appears in Table 4-9. Table 4-9. Views in the HTML Pakage | View | Tags | Description | | BlockView | <BLOCKQUOTE>, <BODY>.<CENTER>, <DD>, <DIV>, <DL>,<HTML>, <LI>,<PRE> | An HTML-specific subclass of the BoxView described in Chapter 3. This View lays out its children vertically, one above the other, and can provide a border if the appropriate CSS attributes are present in the associated CSS attribute set. | | BRView | <BR> | Maps the <BR> element by forcing a line break (see the description of ForcedBreakWeight under "Paragraph Size, Line Layout, and Wrapping" in Chapter 3 to see how this is achieved). | | CommentView | <COMMENT> | Displays comments from the HTML file in an editable area surrounded by a box. This View is only visible when the associated JEditorPane is editable. | | EditableView | N/A | Superclass of HiddenTagView. Not used directly. | | FormView | <INPUT>, <SELECT>, <TEXTAREA> | A subclass of javax.swing.text.ComponentView that displays an appropriate component for the input tags of an HTML form. The component will be a JTextArea for <TEXTAREA> and a JList or JComboBox for <SELECT>, depending on whether the MULTIPLE attribute is defined and whether the SIZE attribute is present and greater than 1 (either of which causes a JList to be used). The <INPUT> tag causes one of several possible components to be used, depending on its TYPE attribute: SUBMIT or RESET creates a JButton with the appropriate text displayed. IMAGE creates a JButton displaying the image given by the SRC attribute. CHECKBOX creates a JCheckBox. RADIO creates a JRadioButton. TEXT creates a JTextField. PASSWORD creates a JPasswordField. | | FrameSetView | <FRAMESET> | Manages a FRAMESET tag. Its job is to lay out its child FRAME or FRAMESET Views according to the number of rows and columns given by its ROWS and COLS attributes. | | FrameView | <FRAME> | Manages a single frame within a FRAMESET. Each frame is implemented as an independent JEditorPane that can be loaded with its own HTML document. Hyper-link events from within the JEditorPane are handled by the FrameView. At the time of writing, ACTIVATED events are sent to the top-level JEditorPane so that the new document can be loaded. ENTERED and EXITED events are currently ignored (but this may change in later versions of Swing). The FrameView is responsible for drawing a border around the JEditorPane and supplying a JScrollPane, but placement and sizing of the frame is the responsibility of the FrameSetView. | | HiddenTagView | Unknown tags, <APPLET>, <AREA>, <HEAD>, <LINK>, <MAP>, <META>, <PARAM>, <SCRIPT>, <STYLE>, <TITLE> | This view is responsible for handling tags that do not normally cause anything visible to appear in the JEditorPane. When the JEditorPane is not editable, HiddenTagView is not visible. However, when it is editable, HiddenTagView displays the tag in a box containing an editable text field that allows the user to change the tag's content. | | HRuleView | <HR> | Displays a horizontal line. Various attributes determine how wide and tall the line is and whether any vertical space is left above or below it. | | ImageView | <IMG> | Displays an image given by the SRC .attribute of the IMG tag. Images are loaded asynchronously and can be stored in a cache held at the HTMLDocument level for performance reasons. In practice, the caching is only done if a Dictionary to hold the cache is stored as a property of the HTMLDocument; there is currently no code that will create such a Dictionary. A border will be supplied around the image if the IMG tag appears within an <A> tag. If the image load fails, a suitable default icon is displayed. Another default icon is used while the image is in the process of being loaded. | | InlineView | (Content) | This is the View that displays text from the HTML page. It is derived from the javax.swing.text.LabelView described in Chapter 3, so it inherits all its capabilities including the ability to display bi-directional text (described later in this book). | | IsIndexView | <ISINDEX> | This View implements the ISINDEX tag by displaying a fixed prompt string ("This is a searchable index. Enter search keywords:"), followed by a JTextField. When the user enters some text and presses RETURN, a question mark followed by the value from the text field is appended to the page URL and the result passed to the setPage method, which should result in a query being performed by the Web server and the resulting page being loaded into the JEditorPane. | | LineView | <PRE> | This View maps a single line of a block of text delimited by <PRE>, </PRE> tags. It has the ability to expand tabs by looking for a TabSet property in the mapped elements AttributeSet (see Chapter 3 for a discussion of tabbing). If there is no such property, tabs are deemed to be set every eight characters. | | ListView | <DIR>, <MENU>, <OL>, <UL> | This is a subclass of BlockView that is used to map various list-related elements that need special painting. The actual painting is delegated to a ListPainter that is obtained from the document's StyleSheet object, the intention being that you can change the way in which these lists are drawn by implementing your own ListPainter and installing a StyleSheet subclass with an overridden getListPainter method that returns an instance of your ListPainter. The default ListPainter in the StyleSheet class processes an LI tag associated with the block that the ListView is mapping and draws the appropriate decorator for the tag, which may be a circle, a square, a letter (in lower or uppercase), a number, or a Roman numeral. | | NoFramesView | <NOFRAMES> | The <NOFRAMES> tag is used to provide alternative HTML for a browser that does not understand frames. Because the HTML package supports frames, any HTML inside the NOFRAMES tag should be ignored. The NoFramesView accordingly renders nothing. | | ObjectView | <OBJECT> | This View is a restricted implementation of the OBJECT tag, which is used to include ActiveX controls, Applets, and other active content into a Web page. Browsers provide varying levels of support for this tag. The Swing HTML package supports very limited use of this tag to load a Java class file whose name is given as the CLASSID attribute. The class must be derived from Component and must have a default constructor. After loading the class, a new instance is created and any associated PARAM tags are used to set its properties. If the OBJECT tag has a PARAM tag with name FONT, for example, the class must supply a setFont method that takes a single argument of type String. This method will be invoked with the VALUE part of the PARAM tag as its argument. | | ParagraphView | <DT>, <H1>, <H2>, <H3>, <H4>, <H5>, <H6>, <P> | ParagraphView is derived from the java.swing.text.ParagraphView class that was described in Chapter 3. It adds support for CSS attributes mapped from the HTML attributes on the corresponding Element. | | TableView | <TABLE> | A View that maps the HTML TABLE tag. | | TableView.CellView | <TD>, <TH> | A View that renders a single cell of an HTML table. Most of the functionality is provided by the BoxView class in the text package. | Creating a Custom View As you saw in Chapter 3, you can use custom Views to modify the way in which a document is displayed. Views are created by the editor kit's ViewFactory, based on the Element that the View is mapping. The relationship between Views and the tag represented by the model Elements for HTMLDocument is shown in Table 4-9. To use a custom View in place of the standard one, you need to replace the HTMLEditorKit ViewFactory. In Chapter 3, you saw how to use a replacement ViewFactory in conjunction with JTextPane by subclassing StyledEditorKit and overriding the getviewFactory method to return an instance of it (see Listing 3-3). The basic idea is the same for JEditorPane we create a custom ViewFactory and a corresponding subclass of HTMLEditorKit with its getViewFactory method overridden. Well see later how to make use of this editor kit. Let's first look at an example implementation of a custom HTML View. JEditorPane has two operating modes. If you want to use JEditorPane as a cut-down browser, you set its editable property to false. In this mode, the user cannot type anything into the JEditorPane and only the usual tags that would be displayed by a browser are visible. On the other hand, you can also create an editable JEditorPane in which the user (presumably a developer) can change the content of the page. As we saw earlier in this chapter, you can arrange to write out the modified content of an HTMLDocument to an external file. Thus, you can use JEditorPane as a basic HTML editor and we'll see more about this in "The HTML Editor Kit". You can see an example of an editable JEditorPane by typing the command java AdvancedSwing.Chapter4.EditorPaneExamplel6 This program allows you to load an HTML page and, using the checkbox at the bottom of the window, you can choose whether the JEditorPane should be editable. You can toggle this checkbox before loading the page or after it has loaded. An example of a page loaded in editable mode is shown in Figure 4-18. Figure 4-18. An HTML page in an editable JEditorPane. As you can see, when the page is editable, tags in the header block that would not normally be visible are shown as text fields with lined borders. You'll find that comments that appear anywhere in the document are also visible. The content of these text fields is actually editable and, if you provide code to write the content of the HTMLDocument to a file on demand, you can use this facility to make changes to the HTML comments or to modify the other tags that you normally cannot see. This facility may be useful for a Web page developer, but it is of less use if you want to provide a facility for the user to be able to change the text content of the page, but not its structure. To make this possible, you need to be able to stop the structural tags being displayed even when the JEditorPane is editable. For that, you need a custom View. The header and comment tags are actually rendered by the HiddenTagview (see Table 4-9), which is derived from EditableView. Editableview is implemented to request zero space in the View layout if the JEditorPane that it resides in is not editable and the appropriate space to display whatever it contains if it resides in an editable JEditorPane.HiddenTagView extends this to supply the JTextField that will show the tag itself. Commentview is a subclass of HiddenTagView that displays the comment text instead of the tag itself, thus making it possible to change the comment. To arrange for all these tags to remain invisible even when the JEditorPane is editable, we need to change the ViewFactory to return a different View whenever it would create a HiddenTagView or a Commentview. The code to do this is very simple and is shown in Listing 4-19. Listing 4-19 An EditorKit with a Modified ViewFactory package AdvancedSwing.Chapter4; import j avax.swing.text.*; import j avax.swing.text.html.*; public class HiddenViewHTMLEditorKit extends HTMLEditorKit { public Object clone() { return new HiddenViewHTMLEditorKit(); } public ViewFactory getViewFactory() { return new HiddenViewFactory(); } public static class HiddenViewFactory extends HTMLEditorKit.HTMLFactory { public View create(Element elem) { Object tag = elem.getAttributes().getAttribute( StyleConstants.NameAttribute); if (tag instanceof HTML.Tag) { for (int i = 0; i < hiddenTags.length; i++) { if (hiddenTags[i] == tag) { return new RealHiddenTagView(elem); } } } if (tag instanceof HTML.UnknownTag) { return new RealHiddenTagView(elem); } return super.create(elem); } static HTML.Tag[] hiddenTags = { HTML.Tag.COMMENT, HTML.Tag.HEAD, HTML.Tag.TITLE, HTML.Tag.META, HTML.Tag.LINK, HTML.Tag.STYLE, HTML.Tag.SCRIPT, HTML.Tag.AREA, HTML.Tag.MAP, HTML.Tag.PARAM, HTML.Tag.APPLET }; } } This class extends HTMLEditorKit to override the getViewFactory method and return an extended ViewFactory that takes special action for the tags in Table 4-9 that would result in the creation of a HiddenTagView or a Commentview. The new ViewFactory is derived from HTMLEditorKit.HTMLFactory, which is the factory used by HTMLEditorKit itself. This allows us to make use of the factory's create method to return the appropriate View for all of the other tags and avoid having to repeat the tag to View mapping in the custom factor)'. As you can see, the affected tags are held in an array called hiddenTags. If the tag associated with the Element passed to the factory is one of the tags in hiddenTags, an instance of the class RealHiddenTagView is returned instead of the usual HiddenTagView or Commentview. The same View is returned if the tag is an instance of the class HTML.UnknownTag, which is a base class provided to allow the use of nonstandard tags in an HTML page, provided that custom Views are implemented to handle them. In our case, we're not going to provide such support, but we do want to hide these tags from the user. RealHiddenTagView is a custom View that will not display anything for the Element that it maps. The ideal way to implement this would be to derive it from EditableView, which acts as an invisible view when its container is not editable. We would simply change this behavior so that the derived class would always act as if the JEditorPane were not editable. Unfortunately, this is not possible, because EditableView has package scope and so cannot be subclassed outside the javax.swing.text.html package (incidentally, the same is true of HiddenTagView). Instead, we derive RealHiddenTagView from View itself. View is an abstract class that requires the implementation of only a small number of methods in addition to the ones that are important for the functionality of this class. The code for RealHiddenTagView is shown in Listing 4-20. Listing 4-20 A View That Is Always Invisible package AdvancedSwing.Chapter4; import java.awt.*; import javax.swing.text.*; import javax.swing.text.html.*; public class RealHiddenTagView extends View { public RealHiddenTagView(Element elem) { super(elem); } public float getMinimumSpan(int axis) { return 0; } public float getPreferredSpan(int axis) { return 0; } public float getMaximumSpan(int axis) { return 0; } public void paint(Graphics g, Shape a) { } public Shape modelToView(int pos, Shape a, Position.Bias b) throws BadLocationException { return a; } public int viewToModel(float x, float y, Shape a, Position.Bias[ ] biasReturn) { return getStartOffset(); } } The basic idea behind this View is simply that it requests no space in the View layout and that its paint method does nothing. It is easy to arrange for this we just have to return zero from the getMinimumSpan, getPreferredSpan, and getMaximumSpan methods (refer to Chapter 3 for a discussion of these methods), and we implement the paint method to do nothing at all. If we were able to extend EditableView, these would be the only methods that we would implement for ourselves. Because we have to derive this class from View itself, however, we are obliged to provide implementations for the modelToView and ViewToModel methods. Fortunately, however, providing support for these methods for a View that occupies no space is trivial, as you can see. The remaining problem is how to arrange for the JEditorPane to use HiddenViewHTMLEditorKit instead of HTMLEditorKit so that the correct ViewFactory is used. In Chapter 3, we did something similar when we created a custom editor kit for JTextPane; making use of it in that case was a simple matter of installing the new editor kit in the JTextPane when it was created. With JEditorPane, however, things are not quite so simple, because the appropriate editor kit is installed as each document is loaded, based on the content type of the document itself. Earlier in this chapter, we covered the mechanism by which the content type is mapped to the correct editor kit (see "The setContentType Method"). As you may recall, the content type is mapped to an editor kit using a registry, which is initialized using the static registerEditorKitForContentType method of JEditorPane. To arrange for our modified editor kit to be used instead of HTMLEditorKit for documents with content type text/html, you need the following code to have been executed before any HTML is loaded: // Register a custom EditorKit for HTML JEditorPane.registerEditorKitForContentType("text/html", "AdvancedSwing.Chapter4.HiddenViewHTMLEditorKit", getClass().getClassLoader()); We noted earlier in this chapter that there are two forms of registerEditorKitForContentType, one of which explicitly supplies a class loader to be used to load the named EditorKit class and another that does not specify the ClassLoader to be used. If the simpler form is used, when the editor kit needs to be loaded, JEditorPane uses the ClassLoader used to load the JEditorPane itself. In JDK 1.1, this will not cause a problem, but there are extra security checks in Java 2 that prevent this approach from working. In Java 2, JEditorPane will have been loaded from the so-called "boot class path" using a class loader that will only load classes from the Java core packages. Core Note You can find out about the boot class path and how classes are loaded in Java 2 from the online documentation supplied by Sun. If you installed the Java 2 documentation set in the directory C:\jdk1.2.2\docs, point your Web browser at the file C:\jdk1,2.2\docs\tooldocs\findingclasses.html.
If an attempt is made to use this ClassLoader to load a user-defined class, an exception will occur. To make it possible to load the EditorKit, we need to supply a different ClassLoader that has access to the class that contains the EditorKit implementation. One way to do this would be to use the expression AdvancedSwing.Chapter4.HiddenViewHTMLEditorKit.class.get- ClassLoader() which returns the ClassLoader that would naturally be used to load the editor kit itself. The drawback with this is that it actually causes the class to be loaded, which is not desirable in general because the editor kit may not actually be required. Instead, in this example we take advantage of the fact that the editor kit and the example code will be loaded using the same ClassLoader and supply the ClassLoader that was used to load the class that registers the HiddenViewHTMLEditorKit. You can see how the modified editor kit works by typing the command java AdvancedSwing.Chapter4.EditorPaneExample17 and loading an HTML page that has header and/or comment tags. Most of the HTML pages in the JDK API documentation have suitable tags. If you have installed the documentation in the directory c:\jdk1.2.2\docs, you could try using the URL file:///c:\jdkl.2.2\docs\api\help-doc.html This is the file that was loaded in Figure 4-18 and rendered using the standard HTMLEditorKit Views. If you load this page now, however, you'll see that the header and comment tags are no longer displayed and, if you use the Editable checkbox to toggle the JEditorPane between editable and readonly modes, you'll see that its appearance does not change. If you try the same with EditorPaneExamplel6, however, you'll find that toggling the editable property makes the header tags appear or disappear. The HTML Editor Kit To use JEditorPane as an HTML editor capable of anything other than simply inserting and deleting text, you need to make full use of HTMLEditorKit. In Chapter 1, you saw that all the text components come with a set of built-in editing features, most of which are provided by their editor kits. HTMLEditorKit is derived from StyledEditorKit, which provides a range of editing and formatting actions, as shown in Table 1-6 and these actions are, theoretically, applicable to any document (other than plain text) that can be loaded into either a JTextPane or a JEditorPane. Most of them operate by manipulating the AttributeSets of the Elements of the underlying Document, so the extent to which they are effective for a particular type of Document depends on how its associated Views interpret those attributes. As we've seen, the HTML Views use CSS attributes for rendering rather than the StyleConstants attributes that are manipulated by the style-related actions of StyledEditorKit, but many of these attributes are translated directly to their CSS equivalents as they are being stored within an HTMLDocument (see Table 4-8 for a list of the conversions provided at the time of writing). As a result, all of the actions supplied by StyledEditorKit work equally well with HTMLEditorKit. Using the HTML Editor Kit Text and HTML Actions As you saw in Chapter 1, you can get the set of editing features that a text component supports by invoking its getActions method: public Action[] getActions(); The list of Actions that will be returned is made of the set supported by the component itself and those of its editor kit. In the case of JEditorPane, the exact content of this list will depend on the type of editor kit installed, which is determined by the content type of the document that has been loaded. A simple and convenient way to make the Actions supported by an editor kit available to the user is to add them to the application's menu bar. If you were writing an HTML page editor, for example, you would want to extract the various Actions supplied by HTMLEditorKit and build suitable menus from them, structured according to action type so that, for example, all the font related items would be held together and separated from the actions that let you create and manipulate HTML tags. Unfortunately, it's not particularly simple to build menus of related actions unless you know in advance what the complete set of Actions is because, although each Action has a name, it is difficult to see how they relate to each other without analyzing the name. Furthermore, the names themselves are not very user-friendly, as you can see from the set of Actions supported by StyledEditorKit in Table 1-6. Nevertheless, the number of different functional areas that the complete Action set for the editor kits in the Swing text package cover is small and the set of Actions does not change very often, so that it is possible to build a set of menus by assigning meaningful names to each Action, and then using these names to create menu items. In this section, we'll show the beginnings of a program that could be used as the basis for an HTML (or RTF, or plain text) editor. Constructing Menus from Editor Kit Actions To build our editor, we need to address several problems: -
How to specify the relationship between the names to be used for the menu items and the Actions supported by the Swing editor kits. -
How to arrange for the menu items to be organized into a useful menu hierarchy. -
Because different editor kits support different sets of Actions, how to make sure that only the appropriate set of Actions is available on the menu bar for the type of document loaded into the editor. The simplest way to address all these problems is to create a simple class that maps a meaningful name that can be added to a menu to the name of an Action, the idea being that a menu can be specified as an array of objects of this type. Scanning through the array would enable us to build a menu with one menu item for each entry in the array, and would also show which Actions to attach to them. If we call this class MenuSpec, we might define a menu that has entries to change the style of the font associated with text like this: private static MenuSpec[] styleSpec = new MenuSpec[] { new MenuSpec("Bold", "font-bold"), new MenuSpec("Italics", "font-italic"), new MenuSpec("Underline", "font-underline") }; In this example, the strings Bold, Italics, and Underline will appear on an as-yet-unnamed menu and will map to Actions called font-bold, font-italic, and font-underline respectively. If you refer to Table 1-6, you'll see that these are three of the Actions supplied by StyledEditorKit. This simple structure allows us to build a single menu, but it is usually desirable to provide several small menus with closely related features than one large one. To do this, we need to be able to create menus that have submenus. We could achieve this by just creating several MenuSpec arrays like that shown earlier, using them to generate a set of JMenu objects and then assembling them into larger menus by hand. That, however, would be very inflexible. Instead, what we'll do is to extend MenuSpec so that it can also map a menu name to an array of other MenuSpec objects. This enables us to create a cascading menu, in which the MenuSpec array specifies the content of the child menu. Here, for example, is how we would specify a menu with three child menus: // Menu definitions for fonts private static MenuSpec[] fontSpec = new MenuSpec[] { new MenuSpec("Size", sizeSpec), new MenuSpec("Family", familySpec), new MenuSpec("Style", styleSpec) }; When this array of MenuSpec objects is used, we'll get a menu with items labeled Size, Family, and Style, each of which has an associated child menu. The content of the Style menu, for example, will be determined by the MenuSpec array pointed to by the variable styleSpec, the definition of which you saw earlier. Figure 4-19 shows how this looks in the completed application. Figure 4-19. A menu created dynamically from EditorKit actions. Listing 4-21 shows the simple implementation of the MenuSpec class. As you can see, this class has no real behavior of its own it exists only to store information about a menu and, once the MenuSpec has been created, its content cannot be changed. Listing 4-21 A Specification for Menu package AdvancedSwing.Chapter4; import javax.swing.Action; public class MenuSpec { public MenuSpec(String name, MenuSpec[] subMenus) { this.name = name; this.subMenus = subMenus; } public MenuSpec(String name, String actionName) { this.name = name; this.actionName = actionName; } public MenuSpec(String name, Action action) { this.name = name; this.action = action; } public boolean isSubMenu() { return subMenus != null; } public boolean isAction() { return action != null; } public String getName() { return name; } public MenuSpec[] getSubMenus() { return subMenus; } public String getActionName() { return actionName; } public Action getAction() { return action; } private String name; private String actionName; private Action action; private MenuSpec[] subMenus; } The constructors simply store their arguments for later retrieval. The first constructor allows you to create a MenuSpec that specifies a child menu that will be attached to another menu with the given name. The second constructor is for a menu item mapping a named Action from the set of Actions provided by a text component. We'll use both of these constructors in the next example in this section. The third constructor, which we won't use here, maps a menu item name to an Action. The intent here is to allow you to mix text component Actions with extra Actions that are specific to an application and which the application can create for itself. For example, if an application implements an Action in a class called DeleteAllAction, you might use the following to create a MenuSpec that can be used to add it to a menu: MenuSpec deleteAllSpec = new MenuSpec ("Delete All", new DeleteAllAction()); The methods getActionName, getSubMenus, and getAction can be used to extract the specification for the menu or menu item that should be constructed for this MenuSpec. For any given MenuSpec, only one of these three methods will return a non-null result. To determine the type, the methods isSubMenu and isAction can be used. A menu is built from an array of MenuSpec items. The details of this process are encapsulated in a class called MenuBuilder, which has a single static method called buildMenu that constructs a complete menu, with any necessary submenus, based on its arguments. The implementation is shown in Listing 4-22. Listing 4-22 Building a Complete Menu package AdvancedSwing.Chapter4; import javax.swing.*; import java.util.*; import java.awt.event.*; public class MenuBuilder { public static JMenu buildMenu(String name, MenuSpec[] menuSpecs, Hashtable actions) { int count = menuSpecs.length; JMenu menu = new JMenu(name); for (int i = 0; i < count; i++) { MenuSpec spec = menuSpecs[i]; if (spec.isSubMenu()) { // Recurse to handle a sub menu JMenu subMenu = buildMenu(spec.getName(), spec.getSubMenus(), actions); if (subMenu != null) { menu.add(subMenu); } } else if (spec.isAction()) { // It's an Action - add it directly to the menu menu.add(spec.getAction()); } else { // It's an action name - add it if possible String actionName = spec.getActionName(); Action targetAction = (Action)actions.get(actionName); // Create the menu item JMenuItem menuItem = menu.add(spec.getName()); if (targetAction != null) { // The editor kit knows the action menuItem.addActionListener(targetAction); } else { // Action not known - disable the menu item menuItem.setEnabled(false); } } } // Return null if nothing was added to the menu. if (menu.getMenuComponentCount() ==0) { menu = null; } return menu; } } The implementation is fairly straightforward. The name of the menu to be constructed is passed as the first argument, the MenuSpecs that describe the menu items on the menu as the second argument, and a set of Actions as the third. An empty JMenu is created and then a loop is entered that processes each MenuSpec in turn, creating a single menu item for each entry in the MenuSpec array. There are three possible ways for the menu item to be created, depending on the type of the MenuSpec: If the MenuSpec contains an Action (that is, isAction returns true), the reference to the Action stored in the MenuSpec is obtained from getAction and added directly to the menu using the JMenu add method, which creates and returns a JMenuItem. If isSubMenu returns true, the getSubMenus method is used to get the array of MenuSpec objects that specifies the content of the child menu and the buildMenu method is invoked again to build a new JMenu, which is then added to the original menu. In Figure 4-19, this is how the Size, Family, and Style submenus were created. Finally, if neither of those methods return true, the MenuSpec specifies the name of an Action, which may be in the Hashtable passed as the third argument to buildMenu. The Action name (obtained using the getActionName method) is used as the key to obtain the desired Action from the Hashtable and, if it is present, it is added to the menu under the name specified in the MenuSpec. However, not all editor kits support all the Actions you might want to add to an application menu; those that are not supported by the editor kit being used will not be passed in the Hashtable (you'll see how the Hashtable is constructed shortly). If this is the case, the menu item is still added, but it is disabled. This allows the user to see the full range of possibilities supported by the application, even if they are not available at any given time. As you'll see in our example application, as you load different document types, the set of enabled menu items will change accordingly. This addresses the third of the set of issues shown in the list above. Because an array of MenuSpec objects can contain any mixture of these three types, the buildMenu method can be used to create a menu with any combination of menu items and submenus and the same applies to any submenu. Using Editor Kit Actions Now that we've got the means to build a set of menus from a specification, it's a relatively simple matter to add a suitable menu bar to our ongoing example. Before we look at the small amount of extra code that's needed to make the Actions supported by the various Swing editor kits available to the end user, let's try out the modified example. You can do this using the command java AdvancedSwing.Chapter4.EditorPaneExample18 The main window of this application looks very much like that of the previous versions of this program, except that it now has a menu bar at the top and a Save button at the bottom, as shown in Figure 4-20. Figure 4-20. The Editor Pane example with a Font Size menu. When the application has started, pull down all the menus in turn. You'll find that the Font menu has the three submenus for Size, Family, and Style that you saw in the code extract shown earlier. If you activate each of these menus in turn, you'll see that they are fully populated but every menu item is disabled. Figure 4-20 shows the Font Size menu, each entry on which has been created from a single MenuSpec. When a JEditorPane is created, it has a PlainDocument and a DefaultEditorKit installed, which does not support any of the Actions referenced by the set of MenuSpecs created in this example. As a result, although the menus are created, none of the Actions that they correspond to will be present in the Hashtable passed to the buildMenu method and so the menu items are all disabled. The same situation results if you actually load a plain document, as is the case in Figure 4-20. Core Note We're not going to show the complete set of MenuSpec objects used in this example. If you want to see them, you'll find them in the source code on the CD-ROM that accompanies this book.
Now load an HTML document into the JEditorPane by typing an appropriate URL and pressing RETURN. If you have installed the example code in the recommended location, you'll find a suitable HTML page at the URL file:///c:\AdvancedSwing\Examples\AdvancedSwing\Chapter4\SimplePage.html Now if you walk through the menus, you'll find that all the menu items have been activated, because they are all supported by the HTMLEditorKit that is now installed in the JEditorPane. The non-HTML Actions connected to the menus, namely those on the Font and Layout menus, operate by manipulating the AttributeSets in the Document's Elements. These Actions are implemented by StyledEditorKit, which is the superclass of HTMLEditorKit and of RTFEditorKit, which means that the menu items created from them will be available when you load either an HTML or an RTF document. To see how they work, first select some text and then select a menu item. The Action associated with the menu item will then be applied to the selected text. For example, if you have loaded SimplePage.html, you can change font of the large red words by selecting them, and then opening the Font menu followed by the Size submenu and then clicking on the menu item for the font size that you want to apply. The actionPerformed method of the Action connected to the menu item applies the font to the AttributeSet of the Elements covered by the selected area as character attributes. You can also use the menus to set styles for new text as it is typed into the JEditorPane. To do this, click anywhere inside the JEditorPane with the mouse, so that nothing is selected. If you start typing, the characters that appear will match the style of those already at the cursor location. You can change the style by selecting the attributes you want from the menus. For example, select a 24-point font from the Font Size submenu and Bold and Underline from the Font Style menu. As you make the menu selections, nothing appears to happen but, in fact, the input attribute set is being changed to reflect the attributes chosen from the menu. As you may recall from Chapter 2, the input attribute set contains character attributes that will be applied to newly inserted text. When you place the cursor, the input attribute set is initialized from the attributes at the cursor location, which is why new text inherits the appearance of the text that surrounds it. Now if you start typing, you'll find that the text is larger, is rendered in bold, and is underlined (see Figure 4-21). Figure 4-21. Using Editor Kit Actions to change the style of input text. At the bottom of the window, you'll find a button labeled Save. If you press this button, the editor kit will save the current content of the document in its usual form on standard output, which will be the window from which you started the program. If you do this now, you'll see the HTML that corresponds to what is being displayed by the JEditorPane and you'll notice that the text that you just typed is there, with the appropriate tags to have it displayed with the attributes set from the menu, shown here in bold: <p> Standard paragraph with <font color="red" size="+2"> large red</font> text <u><b><font size="24"> and some in bold and underlined</font></b></u>. </p> As noted earlier in this section, this works because the StyledEditorKit actions apply StyleConstants attributes held in the AttributeSet to the text as it is entered. When an HTMLEditorKit is installed in the JEditorPane, these attributes will be converted directly to their CSS equivalents and stored with the content Elements associated with the text in the underlying HTMLDocument. When the HTMLEditorKit write method is called to save the model in HTML form, these attributes cause the tags you see above to be generated. As you can see, using only the MenuSpec and MenuBuilder classes shown in the section and the Actions supplied by StyledEditorKit, you can turn a JEditorPane into a simple editor that you can use to enter text in a variety of styles and fonts and, using the Actions on the Align menu, you can also arrange for individual paragraphs to be left-, center-, or right-aligned. Moreover, these features apply equally to HTML pages or to RTF documents, as you can see by loading the RTF document LM.rtf from the same directory as SimplePage.html. Before we look at the HTML-specific Actions, let's go back to our example program and complete the discussion of the implementation of the menu bar. Core Note If you load an RTF document, the menu items on the Font and Layout menus remain enabled, but the ones on the HTML menu are no longer available, because they are provided by HTMLEditorKit but not by RTFEditorKit.
Creating the Application Menu Bar When our example program is loaded, it creates a JMenuBar and then calls the createMenuBar method to populate it. This method is shown in Listing 4-23. As you can see, it first removes whatever is currently on the menu bar, and then uses the getActions method of JEditorPane to get the current set of supported text Actions, which combines those provided by JEditorPane itself with the ones available from the underlying editor kit. The set of Actions is returned as an array, which is then converted to a Hashtable in which each Action is stored with its name as the key. The content of this Hashtable will, of course, be different for each editor kit. Next, the three menus that appear on the menu bar are constructed by invoking the buildMenu method of MenuBuilder with the menu name, the array of MenuSpec objects for that menu, and the Hashtable of the currently available Actions. The JMenus returned are added directly to the menu bar. Core Note Technically, buildMenu can return null instead of a JMenu. This only happens if the MenuSpec it is given doesn't result in the creation of any menu items. In our case, this will not happen. If it did, the corresponding menu would not appear in the menu bar.
Listing 4-23 Creating the Application Menu Bar Content public void createMenuBar() { // Remove the existing menu items int count = menuBar.getMenuCount(); for (int i = 0; i < count; i++) { menuBar.remove(menuBar.getMenu(0)); } // Build the new menu. Action[] actions = pane .getActions(); Hashtable actionHash = new Hashtable(); count = actions.length; for (int i = 0; i < count; i++) { actionHash.put(actions[i].getValue(Action.NAME), actions[i]); } // Add the font menu JMenu menu = MenuBuilder.buildMenu("Font", fontSpec, actionHash); if (menu != null) { menuBar.add(menu); } // Add the alignment menu menu = MenuBuilder.buildMenu("Align", alignSpec, actionHash); if (menu ! = null) { menuBar.add(menu); } // Add the HTML menu menu = MenuBuilder.buildMenu("HTML", htmlSpec, actionHash); if (menu != null) { menuBar.add(menu); } } Why do we need to clear the menu bar at the start of this method? Although this operation is initially redundant the first time this method is called, we will call it again every time the installed editor kit is changed (in fact, we call it after each document has been loaded). We need to do this because changing the editor kit implies a possible change in the set of available Actions. When the set of Actions changes, we need to change the enabled state of the menu items to reflect what is now available. Because in this example we are dealing with a fixed set of MenuSpecs, the actual set of menu items on all the menus on the menu bar will not change, so we could do this by creating the menu hierarchy once and simply walking through them on subsequent occasions, changing the enabled state as appropriate. The implementation shown here is, however, much clearer and easier to understand. It does, however, have the consequence that we repeatedly add the same menus to the menu bar, so to avoid duplicates we need to remove all the menus each time this method is invoked. Using HTML Actions When you load an HTML document into the JEditorPane, you'll find that the menu items on the HTML menu are enabled. These menu items, which represent all the Actions provided by HTMLEditorKit at the time of writing (in Swing 1.1.1 and Java 2 version 1.2.2), are as follows: | Menu Label | Action Name | | Table | InsertTable | | Table Row | InsertTableRow | | Table Cell | InsertTableDataCell | | Unordered List | InsertUnorderedList | | Unordered List Item | InsertUnorderedListItem | | Ordered List | InsertOrderedList | | Ordered List Item | InsertOrderedListItem | | Preformatted Paragraph | InsertPre | | Horizontal Rule | InsertHR | All these Actions insert HTML into the document. To use them, place the cursor where you want the insertion to take place and then click on the menu item. To insert a table, for example, place the cursor and click the Table menu item to get a table with one empty cell. Once you've got a cell, you can add content to it directly just by typing it in and you can apply the styles and layout constraints on the other menus as necessary. The Table Cell menu item adds a new cell to the right of the cursor location, moving any cells already to the right of the cursor over by one position to make room for it. Similarly, Table Row inserts a complete new row. The newly created row is not fully populated with cells only a single cell is added, leaving any other positions in the row blank, as shown in Figure 4-22. You can fill out these unoccupied locations using Table Cell. To remove a cell, place the cursor inside it and press the DELETE key until its content has been removed, and then press it once more to delete the cell itself. Cells to the right of the deleted cell are moved left to occupy the newly created space, leaving blank space at the right side of the row; deleting the last cell in a row removes the entire row. You can also select multiple cells and delete them together. Figure 4-22. Using HTMLEditorKit actions to add a table. The other menu items all work in the same way, allowing you to insert lists with bullets or numbers, a horizontal separator, or create a paragraph for preformatted text which uses a monospaced font and is suitable for entering content that must appear exactly as it is typed, such as a code listing. The current set of Actions allows you only limited access to the underlying HTML support, but may be expanded as the Swing HTML package is developed. To take advantage of any new Actions that might be added, you will only need to modify the MenuSpecs for the HTML menu by adding the new Action names, along with the labels that should appear on the associated menu items. Adding Custom HTML Actions All the HTMLEditorKit Actions that appear on the HTML menu in our example application are derived from an inner class of HTMLEditorKit called InsertHTMLTextAction. One instance of this class is returned from the HTMLEditorKit getActions method for each of the available HTML Actions. You can use this class to create new Actions of your own and in this section we'll demonstrate how to do this by adding to our example application a Headings menu that contains menu items to insert level 1 and level 2 headings into an HTMLDocument. To provide new HTML Actions, we need to do two things: Once we've done both of the above, it is a simple matter to extend our example application to expose the new Actions in the menu hierarchy. Creating New HTML Actions For relatively simple operations like inserting pre-defined HTML sequences, the easiest way to expand the capabilities of HTMLEditorKit is to use InsertHTMLTextAction. This class has two public constructors: public InsertHTMLTextAction(String name, String html, HTML.Tag parentTag, HTML.Tag addTag); public InsertHTMLTextAction(String name, String html, HTML.Tag parentTag, HTML.Tag addTag, HTML.Tag alternateParentTag, HTML.Tag alternateAddTag) In both cases, the name argument is the name of the Action itself, while the second argument is the actual string of HTML tags that will be inserted into the document. In terms of some examples that you have already seen, the Action that inserts a table has the name InsertTable and the HTML that it inserts is <table border=1><tr><td></td></tr></table> which creates a table with a single empty cell. Both constructors then have two arguments of type HTML.Tag called parentTag and addTag. The parentTag argument effectively specifies the level within the document Element structure at which the HTML will be inserted, while addTag is the HTML.Tag value for the first inserted tag. For the InsertTable Action, these arguments have the values HTML.Tag.BODY and HTML.Tag.TABLE, which specifies that a TABLE tag should be inserted in the body of the document. It may seem confusing that you have to explicitly state the first tag to be inserted when that tag appears in the HTML string given as the second argument and that you need to specify that the HTML should be inserted in the document body. To understand why these two arguments are necessary and why there is a second constructor that has an alternate pair of tag and parent tags, let's look at an example that shows how these arguments are used. Suppose the following simple HTML page has been loaded into the JEditorPane: <HTML> <BODY> <H1>Heading</H1> <P> First paragraph text. </BODY> </HTML> This page contains a level 1 heading and a single line of text. Now suppose you want to insert a table above the text but below the heading. You start by placing the cursor to the left of the text as shown in Figure 4-23, and then open the HTML menu and select the Table Action. This invokes the InsertTable Action to insert the HTML string shown earlier at the cursor location. This sounds straightforward, but there is a complication. Figure 4-23. Inserting a table into an HTML page. To see what the complication is, we need to look at the HTMLDocument that is created for this page. The part of the document content relevant to this example is shown here. ===== Element Class: HTMLDocument$BlockElement Offsets [3, 34] ATTRIBUTES: (name, body) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$BlockElement Offsets [3, 11] ATTRIBUTES: (name, h1) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$RunElement Offsets [3, 10] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [Heading] ===== Element Class: HTMLDocument$RunElement Offsets [10, 11] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [ ] ===== Element Class: HTMLDocument$BlockElement Offsets [11, 33] ATTRIBUTES: (name, p) [StyleConstants/HTML$Tag] ===== Element Class: HTMLDocument$RunElement Offsets [11, 32] ATTRIBUTES: (name, content) [StyleConstants/HTML$Tag] [First paragraph text.] When you place the cursor just before the content of the first paragraph, it is located at offset 11 within the document. When the InsertTableAction is activated from the menu, it uses this offset as the position at which the table is to be inserted. If you look at the Element structure shown previously, you'll see that there are actually three Elements that occupy document offset 11: The body element, which covers offsets 3 to 34. The block element for the paragraph containing the single line of text in this document, which begins at offset 11 and ends at offset 33. The run element containing the text itself, which runs from offset 11 to 32. Clearly, it's not enough to specify that the HTML should be inserted at the current location of the cursor (or, actually, at the start of the current selection if there is one) because this is ambiguous. In practice, it only makes sense to insert the table at the body level of the document and that's what the parentTag argument is for it resolves the ambiguity by determining which of the possible insertion locations is correct. Every Action created using InsertHTMLTextAction specifies a parent tag; the InsertTable Action, like all Actions that insert a major structural element, specifies insertion at the body level. Here's exactly how this Action is defined: new InsertHTMLTextAction("InsertTable", INSERT_TABLE_HTML, HTML.Tag.BODY, HTML.Tag.TABLE), As yet we haven't explained why there is a need to include the HTML.Tag.TABLE argument, or why there is an alternative constructor that allows you to specify a pair of alternate tags. To see why these are needed, consider what happens if you want to insert a new row into your newly created table. The Action that inserts a table row is defined as follows: new InsertHTMLTextAction("InsertTableRow", INSERT_TABLE_HTML, HTML.Tag.TABLE, HTML.Tag.TR, HTML.Tag.BODY, HTML.Tag.TABLE) You might expect that when a table row is to be inserted the HTML string argument would be <TR><TD></TD></TR> which produces a new row with an empty cell in it. In fact, the HTML in the Action shown earlier is exactly the same as that used to insert a complete table, namely <TABLE BORDER=l><TR><TD></TD></TR></TABLE> However, if you actually use the HTML menu to insert a new row, you'll see that it does just insert a table row, not an entire new table in other words, not all the HTML string in the InsertHTMLTextAction is being used. This poses two questions: -
Why bother specifying the HTML to create an empty table when only a new row is needed? -
How did the code that updated the document know which part of the HTML string should actually be used and which parts should be ignored? The answer to the first question lies in what happens if you try to create a new table row before creating a table at all. This seems like a strange thing to do, but nothing stops you from selecting the Table Row? item from the menu before selecting Table. If you run the last version of our JEditorPane example, load up the SimplePage.html page, position the cursor at the bottom of the page, and select Table Row from the HTML menu, you'll find that a new table is created with one empty cell. In fact, the complete HTML string associated with the InsertTableRow Action has been inserted. However, as you know, if there had already been a table present, only the part of the HTML needed to create a new row would have been used. Here, you've seen the same Action used in two different contexts; on both occasions, the correct results were obtained. That's the reason why there are two sets of tags in the InsertHTMLTextAction. The first parent tag/insert tag pair is intended to be used when the Action is applied in its expected context, while the second is used in an alternate context. In the case of the InsertTableRow Action, the primary tag pair is: HTML.Tag.TABLE, HTML.Tag.TR, which states that the expected context for this Action is at the level of the TABLE element and that the inserted HTML should start with a <TR> tag. The alternate pair looks like this: HTML.Tag.BODY, HTML.Tag.TABLE which says that if the Action is used at the BODY level, the inserted HTML should begin with a <TABLE> tag. In fact, wherever you insert HTML in the part of an HTML page displayed in a JEditorPane, there will always be a surrounding BODY element, so a tag pair of this type will always permit insertion to take place because there is a surrounding body tag at every location. In fact, a tag pair of this type specifies the default operation if the primary tag context does not apply. The remaining issue is what the second tag of the pair is used for. Looking at the primary tag pair, it specifies that the inserted HTML should start with a <TR> tag. The HTML string provided with this Action does, of course, contain a <TR> tag: <TABLE BORDER=l><TR><TD></TD></TR></TABLE> The effect of the HTML.Tag.TR is to specify that everything preceding it in the HTML string should be excluded from the tags inserted in the document. Likewise, the matching </TR> tag and the </TABLE> tag will be excluded. This is why the same HTML string can be used whether the HTML will be inserted in its expected context or at the BODY level. Of course, if the alternate tag pair is used, the start tag is <TABLE>, so the entire HTML string will be used, resulting in the creation of a new table to enclose the table row. The Action that adds a new table cell is similar: new InsertHTMLTextAction("insertTableDataCell", INSERT_TABLE_HTML, HTML.Tag.TR, HTML.Tag.TD, HTML.Tag.BODY, HTML.Tag.TABLE), The same HTML string is specified here as for the previous two actions. The primary context for this operation is with an HTML.Tag.TR Element, which is a table row as you might expect, and the HTML inserted begins with the <TD> tag. As a result, only the <TD></TD> pair will be used. The fallback is to create a complete new table, which would be the correct behavior. Now that you've seen how the InsertHTMLTextAction class works, using it to add new Actions is simple. Suppose you wanted to add an Action to allow a level 1 header to be inserted. The tags you need to have added to the document are <Hl></Hl> If you specify this as the HTML string in the constructor of an InsertHTMLTextAction object, it will work, but it won't be visible to the person trying to insert the heading. To make it more obvious that the heading tags have been inserted, you can supply some default heading text that makes the header visible. To do this, just change the HTML to <H1>[H1]</H1> Headings should be included at the body level, so the parent tag should be <BODY> and the whole HTML string should be used, so the start tag should be HTML.Tag.H1. Here's how the InsertHTMLTextAction object for this Action should be created: new InsertHTMLTextAction("Heading 1", "<hl>[H1]</hl>", HTML.Tag.BODY, HTML.Tag.H1) The same technique works for other heading levels; for good measure, we'll also create an Action to insert a level 2 heading that looks like this: new InsertHTMLTextAction("Heading 2", "<h2>[H2]</h2>", HTML.Tag.BODY, HTML.Tag.H2) Returning New Actions from the getActions Method You've seen how to create the Actions to insert HTML. The next problem is how to use them from an application. There are two ways to do this. The simplest way is just to create an instance of the action and add it to a menu. If you create the two Actions as shown earlier, you can add them to menu simply by doing this: JMenu headings = new JMenu("Headings"); headings.add(new InsertHTMLTextAction("Heading 1", "<h1>[H1]</h1>", HTML.Tag.BODY, HTML.Tag.H1); headings.add(new InsertHTMLTextAction("Heading 2", "<h2>[H2]</h2>", HTML.Tag.BODY, HTML.Tag.H2); This is not a very general solution, however. Instead, it is better to arrange for these Actions to be returned from the JEditorPane's getActions method when an HTML document is loaded. To do this, you need to have the HTMLEditorKit getActions method return them along with its usual set of Actions, which means creating a subclass of HTMLEditorKit and overriding the getActions method, and then installing the subclass as the editor kit that JEditorPane will use when loading HTML documents. You've already seen how to arrange for a different editor kit to be used when we looked at how to create a different ViewFactory so that we could arrange for hidden tags to be invisible when an HTML document is being edited. For convenience, we'll use the editor kit from Listing 4-19 as the base class from which to create one with our new Actions installed, so that hidden tags will remain invisible. The implementation is shown in Listing 4-24. Listing 4-24 Adding New HTML Actions to an Editor Kit package AdvancedSwing.Chapter4; import javax.swing.*; import javax.swing.text.*; import javax.swing.text.html.*; public class EnhancedHTMLEditorKit extends HiddenViewHTMLEditorKit { public Object clone() { return new EnhancedHTMLEditorKit(); } public Action[] getActions() { return TextAction.augmentList(super.getActions(), extraActions); } private static final InsertHTMLTextAction[] extraActions = new InsertHTMLTextAction[] { new InsertHTMLTextAction("Heading 1", "<h1>[H1]</h1>", HTML.Tag.BODY, HTML.Tag.H1), new InsertHTMLTextAction("Heading 2", "<h2>[H2]</h2>", HTML.Tag.BODY, HTML.Tag.H2), }; } The new Actions are created and installed in a static array; like all editor kit actions, the same set is shared by every instance of the editor kit. We need to have these Actions included in the set returned by getActions, so we override the getActions method and use the static augmentList method of the TextAction class (which was described in Chapter 1) to merge the our Actions with those provided by our superclass, which inherits its getActions method directly from HTMLEditorKit. Now any JEditorPane that uses EnhancedHTMLEditorKit will have Actions to insert level 1 and level 2 headings available to it. To see how this works, use the following command: java AdvanceedSwing.Chapter4.EditorPaneExamplel9 and load an HTML page (such as SimplePage.html). If you open the HTML menu, you'll find that it has a submenu labeled Headings, on which there are menu items labeled Heading 1 and Heading 2, as shown in Figure 4-24. Figure 4-24. A JEditorPane with actions to add headings. If you place the cursor at the end of the document and activate the Headings 1 menu item, you'll find that a level 1 heading with the text [H1] will appear and that you can overwrite the text with your own, which will appear in the appropriate font for a level 1 heading. The same also works for level 2 headings and, if you press the Save button, you'll see that the HTML has the correct tags added to it. This example is almost unchanged from EditorPaneExamplel8. To register the editor kit to be used for all HTML documents, the line JEditorPane.registerEditorKitForContentType("text/html", "AdvancedSwing.Chapter4.EnhancedHTMLEditorKit", getClass().getClassLoader() ); was added. The menus were included by adding a new MenuSpec array: private static MenuSpec[] headingSpec = new MenuSpec[] { new MenuSpec("Heading 1", "Heading 1"), new MenuSpec("Heading 2", "Heading 2") }; which causes menu items that refer to the new Actions to be created. Finally, this menu is added to the HTML menu by adding the highlighted line to the MenuSpec array for that menu: private static MenuSpec[] htmlSpec = new MenuSpec[] { new MenuSpec("Table", "InsertTable"), new MenuSpec("Table Row", "InsertTableRow"), new MenuSpec("Table Cell", "InsertTableDataCell"), new MenuSpec("Unordered List", "InsertUnorderedList"), new MenuSpec("Unordered List Item", "InsertUnorderedListItem"), new MenuSpec("Ordered List", "InsertOrderedList"), new MenuSpec("Ordered List Item", "InsertOrderedListItem"), new MenuSpec("Preformatted Paragraph", "InsertPre"), new MenuSpec("Horizontal Rule", "InsertHR"), new MenuSpec("Headings", headingSpec) }; |