FIRST-GENERATION SOLUTIONS FOR TIME
| only for RuBoard - do not distribute or recompile |
FIRST-GENERATION SOLUTIONS FOR TIME
We now go on to describe some solutions to the problems of the representation of time that have been used in first-generation data warehouses.
One of the main problems is that the business requirements with respect to time have not been systematically captured at the conceptual level. This is largely because we are unfamiliar with the temporal semantics due to the fact that, so far, we have not encountered temporal applications.
Logical models systematically follow conceptual models, and so a natural consequence of the failure to define the requirements in the conceptual model is that the requirements are also absent from the logical and physical implementation. As a result, practitioners have subsequently found themselves faced with problems involving time and some have created solutions. However, the solutions have been developed on a somewhat ad hoc basis and are by no means comprehensive. The problem is sufficiently large that we really do need a rigorous approach to solving it. As an example of the scale of the problem, there is, as previously mentioned, evidence in a government-sponsored housing survey that, in the United Kingdom, people change their addresses, on average, every 10 years . This means that an organization can expect to have to implement address details changes to about 10 percent of their customers each year. Over a 10-year period, if an organization has one million customers, it can expect to have to deal with one million changes of address. Obviously, some people will not move, but others will move more than once in that period. This covers only address changes. There are other attributes relating to customers that will also change, although perhaps not with the same frequency as addresses.
One of the major contributors to the development of solutions in this area is Ralph Kimball (1996). His collective term for changes to dimensional attributes is slowly changing dimensions. The term has become well known within the data warehouse industry and has been adopted generally by practitioners. He cites three methods of tracking changes to dimensional attributes with respect to time. These he calls simply types one, two, and three.
Within the industry, practitioners are generally aware of the three types and, where any support for time is provided in dimensional models, these are the approaches that are normally used. It is common to refer to products and methods as being consistent with Kimball's type one, two, or three. In a later work Kimball (1998) recognizes a type zero that represents dimensions that are not subject to change.
The Type 1 Approach
The first type of change, known as Type 1, is to replace the old data values with the new values. This means that there is no need to preserve the previous value. The advantage of this approach, from a system perspective, is that it is very easy to implement. Obviously there is no temporal support being offered in this solution. However, this method sometimes offers the most appropriate solution. We don't need to track the historical values of every single database element and, sometimes, overwriting the old values is the right thing to do. In the Wine Club example, attributes like the customer's name are best treated in this way. This is an attribute for which there is no requirement to retain historical values. Only the latest value is deemed by the organization to be useful. All data warehouse applications will have some attributes where the correct approach is to overwrite the previous values with the new values.
It is important that the updating is effected on a per attribute basis rather than a per row basis. Each table will have a mixture of attributes, some of which will require the type one replacement approach, while others will require a more sophisticated approach to the treatment of value changes over time.
The worst scenario is a full table replacement approach where the dimension is, periodically, completely overwritten. The danger here is that any rows that have been deleted in the operational system may be deleted in the data warehouse. Any rows in the fact table that refer to rows in the dimension that have been deleted will cause a referential integrity violation and will place the database in an invalid state.
Thus, the periodic update of dimensions in the data warehouse must involve only inserts and updates. Any logical deletions (e.g., where a customer ceases to be a customer) must be processed as updates in the data warehouse. It is important to know whether a customer still exists as a customer, but the customer record must remain in the database for the whole lifespan of the data warehouse or, at the very least, as long as there are fact table records that refer to the dimensional record.
Due to the fact that Type 1 is the simplest approach, it is often used as the default approach. Practitioners will sometimes adopt a Type 1 solution as a short-term expedient, where the application really requires a more complete solution, with the intention of providing proper support for time at a later stage in the project. Too often, the pressures of project budgets and implementation deadlines force changes to the scope of projects and the enhancements are abandoned . Sometimes, Type 1 is adopted due to inadequate analysis of the requirements with respect to time.
The Type 2 Approach
The second solution to slowly changing dimensions is called Type 2. Type 2 is a more complex solution than Type 1 and does attempt to faithfully record historical values of attributes by providing a form of version control. Type 2 changes are best explained with the use of an example. In the case study, the sales area in which a customer lives is subject to change when they move. There is a requirement to faithfully reflect regional sales performance over time. This means that the sales area prevailing at the time of the sale must be used when analyzing sales. If the Type 1 approach was used when recording changes to the sales area, the historical values will appear to have the same sales area as current values. A method is needed, therefore, that enables us to reflect history faithfully.
The Type 2 method attempts to solve this problem by the creation of new records. Every time an attribute's value changes, if faithful recording of history is required, an entirely new record is created with all the unaffected attributes unchanged. Only the affected attribute is changed to reflect its new value. The obvious problem with this approach is that it would immediately compromise the uniqueness property of the primary key, as the new record would have the same key as the previous record. This can be turned into an advantage by the use of surrogate keys. A surrogate key is a system-generated identifier that introduces a layer of indirection into the model. It is a good practice to use surrogate keys in all the customer and dimensional data. The main reason for this is that the production key is subject to change whenever the company reorganizes its customers or products and that this would cause unacceptable disruption to the data warehouse if the change had to be carried through. It is better to create an arbitrary key to provide the property of uniqueness. So each time a new record is created, following a change to the value of an attribute, a new surrogate key is assigned to the record. Sometimes, a surrogate approach is forced upon us when we are attempting to integrate data from different source systems where the identifiers are not the same. There are two main approaches to assigning the value of the surrogate:
-
The identifier is lengthened by a number of version digits. So a customer having an identifier of 1234 would subsequently have the identifier 1234001. After the first change, a new row would be created that would have an identifier of 1234002. The customer would now have two records in the dimension. Most of the attribute values would be the same. Only the attribute, or attributes, that had changed would be different.
-
The identifier could be truly generalized and bear no relation to the previous identifiers for the customer. So each time a new row is added, a completely new identifier is created.
In a behavioral model, the generalized key is used in both the dimension table and the fact table. Constraining queries using a descriptive attribute, such as the name of the customer, will result in all records for the customer being retrieved. Constraining or grouping the results by use of the name and, say, the sales area attribute will ensure that history is faithfully reflected in the results of queries, of course assuming that uniqueness in the descriptive attribute can be guaranteed .
The Type 2 approach, therefore, will ensure that the fact table will be correctly joined to the dimension and the correct dimensional attributes will be associated with each fact. Ensuring that the facts are matched to the correct dimensional attributes is the main concern.
An obvious variation of this approach is to construct a composite identifier by retaining the previous number 1234 and adding a new counter or version attribute that, initially, would be 1. This approach is similar to 1, above. The initial identifier is allocated when the customer is first entered into the database. Subsequent changes require the allocation of new identifiers. It is the responsibility of the data warehouse administrator to control the allocation of identifiers and to maintain the version number in order to know which version number, or generalized key, to allocate next .
In reality, the requirement would be to combine Type 1 and Type 2 solutions in the same logical row. This is where we have some attributes that we do want to track and some that we do not. An example of this occurs in the Wine Club where, in the customer's circumstances, we wish to trace the history of attributes like the address and, consequently, the sales area but we are not interested in the history of the customer's name or their hobby code. So in a single logical row, an attribute like address would need to be treated as a Type 2, whereas the name would be treated as a Type 1.
Therefore, if the customer's name changes, we would wish to overwrite it. However, there may be many records in existence for this customer, due to previous changes to other attributes. Do we have to go back and overwrite the previous records? In practice, it is likely that only the latest record would be updated. This implies that, in dimensions where type two is implemented, attributes for which the type one approach would be preferred will be forced to adopt an approach that is nearly, but not quite, Type 2.
In describing the problems surrounding time in data warehousing, we saw how the results of a query could change due to a customer moving. The approach taken was to simply overwrite the old addresses and the sales area codes with the new values. This is equivalent to Kimball's Type 1 approach.
If we implement the same changes using the Type 2 method, the results would not be disrupted, as new records would be created with a new surrogate identifier.
Future insertions to the sales fact table will be related to the new identifying customer codes, and so the segmentation will remain consistent with respect to time for the purposes of this particular query.
One potential issue here is that, by making use of generalized keys, it becomes impossible to recognize individual customers by use of the identifying attribute. As each subsequent change occurs, a new row is inserted and is identified by a key value that is in no way associated with the previous key value. For example Lucie Jones's original value for the customer code attribute might be, say, 1136, whereas the value for the new customer code for the new inserted row could be anything, say, 8876, being the next available key in the domain range.
This means that, if it was required to extract information on a per customer basis, the grouping would have to be on a nonidentifying attribute, such as the customer's name, that is:
select customer_name "Name", sum(quantity) "Bottles",sum(value) "Revenue" from sales s, customer c where c. customer _code=s. customer _code group by customer _name order by customer _name
Constraining and grouping queries using descriptive attributes like names are clearly risky, since names are apt to be duplicated and erroneous results could be produced.
Another potential issue with this approach is that, if the keys are truly generalized, as with key hashing, it may not be possible to identify the latest record by simply selecting the highest key. Also, the use of generalized keys means that obtaining the history of, say, a customer's details may not be as simple as ordering the keys into ascending sequence.
One solution to this problem is the addition of a constant descriptive attribute, such as the original production key, that is unique to the logical row. Alternatively, a variation as previously described, in which the original key is retained but is augmented by an additional attribute to define the version, would also provide the solution to this.
The Type 2 method does not allow the use of date columns to identify when changes actually take place. For instance, this means that it is not possible to establish with any accuracy when a customer actually moved. The only date available to provide any clue to this is the transaction date in the fact table. There are some problems associated with this. A query such as List the names and addresses of all customers who have purchased more than twelve bottles of wine in the last three months might be useful for campaign purposes. Such a query will, however, result in incorrect addresses being returned for those customers who have moved but not since placed an order. The query in Query Listing 4.4 shows this.
Listing 4.4 Query to produce a campaign list.
select c.customer_code, customer_name, customer_address,sum(quantity) from customer c, sales s, time t where c.customer_code = s.customer_code and s.time_code = t.time_code and t.month in (200010, 200011, 200012) group by c.customer_code,customer_name, customer_address having sum(quantity) > 12
The table in Table 4.1 is a subset of the result set for the query in Listing 4.4.
Table 4.1. List of Customers to be Contacted
| Customer Code | Customer Name | Customer Address | Sum (Quantity) |
|---|---|---|---|
| 1332 | A.J. Gordon | 82 Milton Ave, Chester, Cheshire | 49 |
| 1315 | P. Chamberlain | 11a Mount Pleasant, Sunderland | 34 |
| 2131 | Q.E. McCallum | 32 College Ride, Minehead, Somerset | 14 |
| 1531 | C.D. Jones | 71 Queensway, Leeds, Yorks | 31 |
| 1136 | L. Jones | 9 Broughton Hall Ave, Woking, Surrey | 32 |
| 2141 | J.K. Noble | 79 Priors Croft, Torquay, Devon | 58 |
| 4153 | C. Smallpiece | 58 Ballard Road, Bristol | 21 |
| 1321 | D. Hartley | 88 Ballantyne Road, Minehead, Somerset | 66 |
The highlighted row is an example of the point. Customer L. Jones has two entries in the database. Because Lucie has not purchased any wine since moving, the incorrect address was returned by the query. The result of a simple search is shown in Table 4.2.
Table 4.2. Multiple Records for a Single Customer
| Customer Code | Customer Name | Customer Address |
|---|---|---|
| 1136 | L. Jones | 9 Broughton Hall Ave, Woking, Surrey |
| 8876 | L. Jones | 44 Sea View Terrace, West Bay, Bridport, Dorset |
If it can be assumed that if the generalized key is always ascending, then the query could be modified, as in the following query, to select the highest value for the key.
select customer_code, customer_name, customer_address from customer where customer_code = (select max(customer_code) from customer where customer_name = 'L. Jones')
This query would return the second of the two rows listed in Table 4.2.
Using the other technique to implement the Type 2 method, we could have altered the customer code from 1136 to 113601 for the original row and, subsequently, to 113602 for the new row containing the changed address and sales area.
In order to return the correct addresses, the query in Query Listing 4.5 has to be executed.
Listing 4.5 Obtaining the latest customers details using Type 2 with extended identifiers.
select c1.customer_code,customer_name, customer_address,sum(quantity) from customer c1, sales s, time t where c1.customer_code = s.customer_code and c.customer_code = (select max(customer_code) from customer c2 where substr(c1.customer_code,1,4) = substr(c2.customer_code,1,4)) and s.time_code = t.time_code and t.month in (200010, 200011, 200012) group by c1.customer_code,customer_name,customer_address having sum(quantity) > 12
The query in Listing 4.5 is another correlated subquery and contains the following line:
where substr(c1.customer_code,1,4) = substr(c2.customer_code,1,4)
The query matches the generic parts of the customer code by use of a substring function, provided by the query processor. It is suspected that this type of query may be beyond the capability of most users.
This approach is dependent on the fact that all the codes are of the same fundamental format. That is, they have four digits plus a suffix. If the approach was to start from 1 through 9,999, then this technique could not be adopted, because the substring function would not produce the right answer.
The obvious variation on the above approach is to add an extra attribute to distinguish versions. The identifier then becomes the composite of two attributes instead of a single attribute. In this case, the original attribute remains unaltered, and the new attribute is incremented, as shown in Table 4.3.
Table 4.3. A Modification to Type 2 Using Composite Identifiers
| Customer Code | Version Number |
|---|---|
| 1136 | 01 |
| 1136 | 02 |
| 1136 | 03 |
Using this technique, the following query is executed:
select c1.customer_code,customer_name, customer_address,sum(quantity) from customer c1, sales s, time t where c1.customer_code = s.customer_code and s.counter = c1.counter and c.counter = (select max(counter) from customer c2 where c1.customer_code = c2.customer_code) and s.time_code = t.time_code and t.month in (200010, 200011, 200012) group by c1.customer_code,customer_name,customer_address having sum(quantity) > 12
The structure of this query is the same as in Query Listing 4.5. However, this approach does not require the use of substrings to make the comparison. This means that the query will always produce the right answer irrespective of the consistency, or otherwise , of the encoding procedures within the organization.
These solutions do not resolve the problem of pinpointing when a change occurs. Due to the absence of dates in the Type 2 method, it is impossible to determine precisely when changes occur. The only way to extract any form of alignment with time is via a join to the fact table. This, at best, will give an approximate time for the change. The degree of accuracy is dependent on the frequency of fact table entries relating to the dimensional entry concerned . The more frequent the entries in the fact table, the more accurate will be the traceability of the history of the dimension, and vice versa. It is also not possible to record gaps in the existence of dimensional entries. For instance, in order to track precisely the discontinuous existence of, say, a customer, there must be some kind of temporal reference to record the periods of existence.
Problems With Hierarchies
So far in this chapter, attention has focused on so-called slowly changing dimensions and how these might be supported using the Type 2 solution. Now we will turn our attention to, what we shall call, slowly changing hierarchies. As an example, we will use the dimensional hierarchy illustrated in Figure 3.4. The attributes, using a surrogate key approach, are as follows :
Sales_Area ( Sales_Area_Key , Sales Area Code, Manager key, Sales Area Name)
Manager ( Manager_Key , Manager Code, Manager Name)
Customer ( Customer_Key , Customer code, Customer Name, Customer Address, Sales Area key, Hobby Code, Date Joined)
Let's say the number of customers and the spread of sales areas in the case study database is as shown in Table 4.4.
Table 4.4. Customers Grouped by Sales Area
| Sales Area | Count |
|---|---|
| North East | 18,967 |
| North West | 11,498 |
| South East | 39,113 |
| South West | 28,697 |
We will assume that we have implemented the type two solution to slowly changing dimensions.
If sales area SW was to experience a change of managers from M9 to M12, then a new sales area record would be inserted with an incremented counter, together with the new manager_code. So if the previous record was (1, SW, M9, South West ), the new record with its new key, assumed to be 5, would contain (5, SW, M12, South West ).
However, that is not the end of the change. Each of the customers, from the SW sales area still have their foreign key relationship references pointing to the original sales area record containing the reference to the old manager (surrogate key 1). Therefore, we also have to create an entire set of new records for the customers, with each of their sales area key values set to 5 . In this case, there are 11,498 new records to be created. It is not valid to simply update the foreign keys with the new value, because the old historical link will be lost.
Where there are complex hierarchies involving more levels and more rows, it is not difficult to imagine very large volumes of inserts being generated. For example, in a four-level hierarchy where the relationship is just 1:100 in each level, a single change at the top level will cause over a million new records to be inserted. A relationship of 1:100 is not inordinately high when there are many data warehouses in existence with several million customers in the customer dimension alone.
The number of extraneous insertions generated by this approach could cause the dimension tables to grow at a rate that, in time, becomes a threat to performance.
For the true Star Schema advocates, we could try flattening the hierarchies into a single dimension (de-normalizing). This converts a snowflake schema into a star schema. If this approach is taken, the effect is that, in the four-level 1:100 example, the number of insertions reduces from 1.01 million insertions to 1 million insertions. So reducing the number of insertions is not a reason for flattening the hierarchy.
Browse Queries
The Type 2 approach does cause some problems when it comes to browsing. It is generally reckoned that some 80 percent of data warehouse queries are dimension-browsing queries. This means that they do not access any fact table.
A typical browse query we might wish to perform is to count the number of occurrences. For instance, how many customers do we have? The standard way to do this in SQL is shown in the following query:
Select count(*) from <table> where <predicate>
In a Type 2 scenario, this will produce the wrong result. This is because for each logical record, there are many physical records that result in a number of duplicated rows.
Take the example of a sales exec entity and a customer entity shown in Figure 4.8.
Figure 4.8. Simple general business hierarchy.
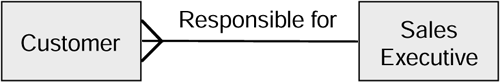
In order to count the number of customers that a sales exec is responsible for, a nonexpert user might express the query as shown in Query Listing 4.6.
Listing 4.6 Nonexpert query to count customers.
Select count(*) from Sales_Exec S,Customer C where S.SalesExecNum=C.SalesExecNum And S.Name = 'Tom Sawyer'
When using the Type 2 approach to allow for changes to a customer attribute, this will produce the wrong result. This is because for each customer there may be many rows, resulting from the duplicates created when an attribute value changes. With more careful consideration, it would seem that the query should instead be expressed as follows:
Select count(distinct <logical primary key>) from <table> where <predicate>
In our example, it translates to the following query:
Select count(distinct CustNum) from Sales_Exec S,Customer C where S. SalesExecNum =C.SalesExecNum and S.Name = 'Tom Sawyer'
Unfortunately, this query does not give the correct result either because the result set contains all the customers that this sales executive has ever been responsible for at any time in the past. The query includes the customers that are no longer the responsibility of Tom Sawyer. When comparing sales executives, this would result in customers being double counted. On further examination, it might appear that this problem can be resolved by selecting the latest entry for each customer to ensure that they are counted as a customer for only their current sales executive. Assuming an incremented general key, this can be expressed by the following query:
Select count(*) from Sales_Exec S,Customer C1 where S. SalesExecNum=C1.SalesExecNum And S.Name = 'Tom Sawyer' and C1.Counter =(Select max(Counter from Customer C2) where C1.CustNum=C2.CustNum)
In fact, this query also gives invalid results because it still includes customers that are no longer the responsibility of Tom Sawyer. That is, the count includes customers who are not currently the responsibility of any sales executive, because they are no longer customers, but whose records must remain because they are referenced by rows of the fact table.
This example should be seen as typical of data warehouses, and the problem just described is general in this situation. That is, using the Type 2 approach, there are simple dimensional queries that cannot be answered correctly. It is reasonable to conclude that the type two approach does not fully support time in the dimensions. Its purpose, simply, is to ensure that fact entries are related to the correct dimensional entries such that each fact, when joined to any dimension, displays the correct set of attribute values.
Row Timestamping
In a much later publication, the lifecycle toolkit, Kimball (1998) recognizes the problem of dimensional counts and appears to have changed his mind about the use of dates. His solution is that the type two method is embellished by the addition of begin and end timestamps to each dimension record. This approach, in temporal database terms, is known as row timestamping. Using this technique, Kimball says it is possible to determine precisely how many customers existed at any point in time. The query that achieves this is shown here:
Select count(*) from Sales_Exec S,Customer C1 where S. SalesExecNum=C1.SalesExecNum And S.Name = 'Tom Sawyer' and C.EndDate is NULL
For the sake of example, the null value in the end date is assumed to represent the latest record, but other values could be used, such as the maximum date that the system will accept , for example, 31 December 9999. In effect, this approach is similar to the previous example because it does not necessarily identify ex-customers. So instead of answering the question How many customers is Tom Sawyer responsible for? it may be asking How many customers has Tom Sawyer ever been responsible for? This method will produce the correct result only if the end date is updated when the customer becomes inactive.
The adoption of a row timestamping approach can provide a solution to queries involving counts at a point in time. However, it is important to recognize that the single pair of timestamps is being used in a multipurpose way to record:
-
Changes in the active state of the dimension
-
Changes to values in the attributes
-
Changes in relationships
Therefore, this approach cannot be used where there is a requirement to implement discontinuous existences where, say, a customer can become inactive for a period because it is not possible to determine when they were inactive. The only way to determine inactivity is to try to identify two temporally consecutive rows where there is a time gap between the ending timestamp of the earlier row and the starting timestamp of the succeeding row. This is not really practical using standard SQL.
Even where discontinuous existences are not present, the use of row timestamping makes it difficult to express queries involving durations because a single duration, such as the period of residence at a particular address or the period that a customer had continuously been active before closing their account, may be spread over many physical records.
For example, in order to determine how many of the customers of the Wine Club had been customers for more than a year before leaving during 2001 could be expressed as follows:
Select '2001' as year, count(*) From customer c1, customer c2 Where c1.start_date = (select min(c3.start_date) from customer c3 where c3.customer_code = c1.customer_code) and c2.end_date = (select max(c4.end_date) from customer c4 where c4.customer_code = c2.customer_code) and c2.end_date between '2001/01/01' and '2001/12/31' and c1.customer_code = c2.customer_code and c2.end_date - c1.start_date > 365 group by year
This query contains a self join and two self correlated sub queries. So the same table is used four times in the query. It is likely that the customer dimension is the one that would be subjected to this type of query most often and organizations that have several million customers are, therefore, likely to experience poor browsing performance.
This problem is exacerbated when used with dimensions that are engaged in hierarchies because, like the Type 2 solution, changes tend to cause the problem of cascaded extraneous rows to be inserted.
The second example has a further requirement which is to determine length of time that a customer had resided at the same address. This requires the duration to be limited by the detection of change events on attributes of the dimension. This is not possible to do with absolute certainty because of the fact that circumstances, having changed, might later on revert to the previous state. For instance, students leave home to attend university but might well return to the previous address later. In the Wine Club, a supplier might be reinstated as the supplier of a wine they had previously supplied. This is, in effect, another example of a discontinuous existence and cannot be detected using standard SQL.
The Type 3 Approach
The third type of change solution (Type 3) involves recording the current value, as well as the original value, of an attribute. This means that an additional column has to be created to contain the extra value. In this case, it makes sense to add an effective date column as well. The current value column is updated each time a change occurs. The original value column does not change. Intermediate values, therefore, are lost. In terms of its support for time, type three is rather quirky and does not add any real value and we will not be considering it further.
TSQL2
TSQL2 has been proposed as a standard for the inclusion of temporal extensions to standard SQL but has not so far been adopted by any of the major RDBMS vendors . It introduces some functions that a temporal query language must have. In this book we are concerned with providing a practical approach that can be implemented using today's technology and so, therefore, we cannot dwell on potential future possibilities. However, some of the functions are useful and can be translated into the versions of SQL that are available right now. These functions enable us to make comparisons between two periods (P1 and P2) of time (a period is any length of time, i.e., it has a start time and an end time).
There are four main temporal functions:
-
Precedes. For this function to return true, the end time of P1 must be earlier than the start time of P2.
-
Meets. For this to be true, the end time of P1 must be one chronon earlier than the start time of P2, or vice versa. A chronon is the smallest amount of time allowed in the system. How small this is will depend on the granularity of time in use. It might be as small as a microsecond or as large as one day.
-
Overlaps. In order for this function to return true, any part of P1 must be the same as any part of P2.
-
Contains. The start of P1 must be earlier than the start of P2 and the end of P1 must be later than the end of P2.
The diagram in Figure 4.9 illustrates these points.
Figure 4.9. Graphical representation of temporal functions.
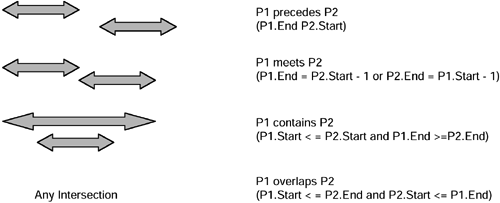
This introduction on how to interpret the TSQL2 functions such as Precedes, Overlaps, etc., in standard (nontemporal) SQL is very useful, as it shows how these functions can be used in standard SQL.
Upon closer examination, the requirements in a dimensional data warehouse are quite simple. The contains function is useful because it enables queries such as How many customers did the Wine Club have at the end of 2000? to be asked. What this is really asking is whether the start and end dates of a customer's period of existence contain the date 31-12-2000. This can be restated to ask whether the date 31-12-2000 is between the start and end dates. So the contains from TSQL2 can be written almost as easily using the between function. Other functions such as meets can be useful when trying to detect dimensional attribute changes in an implementation that uses row timestamps. The technique is to perform a self-join on the dimension where the end date of one row meets the start date of another row and to check whether, say, the addresses or supplier codes are different.
Temporal Queries
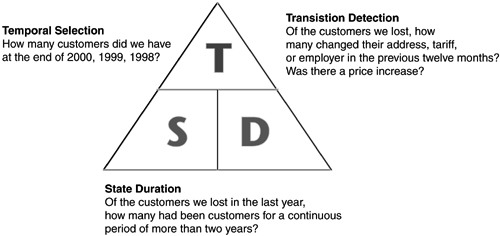
While we are on the subject of temporal extensions to existing technology, it is worth mentioning, but not dwelling upon, the considerable research that has been undertaken into the field of temporal databases. Although there have been more than 1,000 papers published on the subject, a solution is not close at hand. However, some temporal definitions have already been found to be useful in this book. For instance, the valid time and transaction time illustrate the difference between the time an event occurred in real life and the time that the event becomes known to the database. Another useful result is that it is now possible to define three principal types of temporal query that are highly relevant to data warehousing (see Snodgrass, 1997):
-
State duration queries. In this type of query, the predicate contains a clause that specifies a period. An example of such a query is: List the customers who lived in the SW sales area for a duration of at least one year. This type of query selects particular values of the dimension, utilizing a predicate associated with a group definition that mentions the duration of the row's period.
-
Temporal selection queries. This involves a selection based on a group definition of the time dimension. So the following query would fall into this category: List the customers who lived in SW region in 1998. This would involve a join between the customer dimension and the time dimension, which is not encouraged. Kimball's reasoning is that the time constraints for facts and dimensions are different.
-
Transition detection queries. In this class of query, we are aiming to detect a change event such as: List the customers who moved from one region to another region. This class of query has to be able to identify consecutive periods for the same dimension. The query is similar to the state duration query in that, in order to write it, it is necessary to compare row values for the same customer.
We'll be using these terms quite a bit, and the diagram in Figure 4.10 is designed as an aide memoir for the three types of temporal query.
Figure 4.10. Types of temporal query.
| only for RuBoard - do not distribute or recompile |
EAN: 2147483647
Pages: 96