PROBLEMS INVOLVING TIME
| only for RuBoard - do not distribute or recompile |
PROBLEMS INVOLVING TIME
There are several areas in data warehousing where time presents a problem. We'll now explore those areas.
The Effect of Time on the Data Model
Organizations wishing to build a data warehouse have often already built a data model describing their operational business data. This model is sometimes referred to as the corporate data model. The database administrator's office wall is sometimes entirely obscured by a chart depicting the corporate data model.
When building a data warehouse, practitioners often encounter the requirement to utilize the customer's corporate data model as the foundation of the warehouse model. The organization has invested considerably in the development of the model, and any new application is expected to use it as the basis for development. The original motivation for the database approach was that data should be entered only once and that it should be shared by any users who were authorized to have access to it.
Figure 4.1 depicts a simple fragment of a data model for an operational system. Although the Wine Club data model could be used, the model in Figure 4.1 provides a clearer example.
Figure 4.1. Fragment of operational data model.
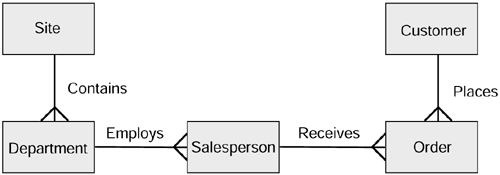
Figure 4.1 is typical of most operational systems in that it contains very little historical data. If we are to introduce a data warehouse into the existing data model, we might consider doing so by the addition of a time variant table that contained the history that is needed.
Taking the above fragment of a corporate data model as a starting point, and assuming that the warehouse subject area is Sales, a dimensional warehouse might be created as in Figure 4.2.
Figure 4.2. Operational model with additional sales fact table.
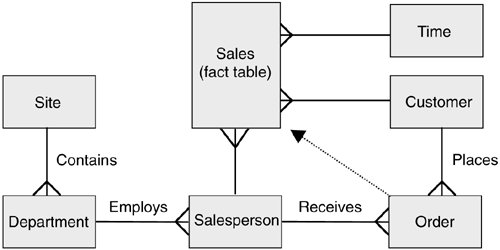
Figure 4.2 shows a dimensional model with the fact table (Sales) at the center and three dimensions of analysis. These are time, customer, and salesperson. The salesperson dimension participates in a dimensional hierarchy in which a department employs salespeople and a site contains many departments. Figure 4.2 further shows that the sales fact table is populated by the data contained in the orders table, as indicated by the dotted arrow (not part of standard notation). That is, all new orders that have achieved the state required to enable them to be classified as sales are inserted into the sales table and are appended to the data already contained in the table. In this way the history of sales can be built.
At first sight, this appears to be a satisfactory incorporation of a dimensional data warehouse into an existing data model. Upon closer inspection, however, we find that the introduction of the fact table Sales has had interesting effects.
To explain the effect, the sales dimensional hierarchy is extracted as an example, shown in Figure 4.3. This hierarchy shows that a site may contain many departments and a department may employ many salespeople. This sort of hierarchy is typical of many such hierarchies that exist in all organizations.
Figure 4.3. Sales hierarchy.

The relationships shown here imply that a salesperson is employed by one department and that a department is contained in one site. These relationships hold at any particular point in time.
The addition of a fact table, which contains history, is attached to the hierarchy as shown in Figure 4.4.
Figure 4.4. Sales hierarchy with sales table attached.

The model now looks like a dimensional model with a fact table (sales) and a single dimension (salesperson). The salesperson dimension participates in a dimensional hierarchy involving departments and sites.
Assuming that it is possible, during the course of ordinary business, for a salesperson to move from one department to another, or for a department to move from one site to another, then the cardinality (degree) of the relationships Contains and Employs no longer holds. The hierarchy, consisting of salespeople, departments, and sites contains only the latest view of the relationships. Because sales are recorded over time, some of the sales made by a particular salesperson may have occurred when the salesperson was employed by a different department.
Whereas the model shows that a salesperson may be employed by exactly one department, this is only true where the relationship is viewed as a snapshot relationship. A more accurate description is that a salesperson is employed by exactly one department at a time. Over time, a salesperson may be employed by one or more departments. Similarly, a department is contained by exactly one site at a time. If it is possible for departments to move from one site to another then, over time, a department may be contained by one or more sites. The introduction of time variance, which is one of the properties of a data warehouse, has altered the degree of the relationships within the hierarchy, and they should now be depicted as many-to-many relationships as shown in Figure 4.5.
This leads to the following observation:
The introduction of a time-variant entity into a time-invariant model potentially alters the degree of one or more of the relationships in the model.
Figure 4.5. Sales hierarchy showing altered relationships.

A point worth noting is that it is the rules of the business, not a technical phenomenon , that cause these changes to the model. The degree to which this causes a problem will vary from application to application, but dimensions typically do contain one or more natural hierarchies. It seems reasonable to assume, therefore, that every organization intending to develop a data warehouse will have to deal with the problem of the degree of relationships being altered as a result of the introduction of time.
The above example describes the kind of problem that can occur in relationships that are able to change over time. In effect, the cardinality (degree) of the relationship has changed from one to many to many to many due to the introduction of time variance. In order to capture the altered cardinality of the relationships, intersection entities would normally be introduced as shown in Figure 4.6
Figure 4.6. Sales hierarchy with intersection entities.
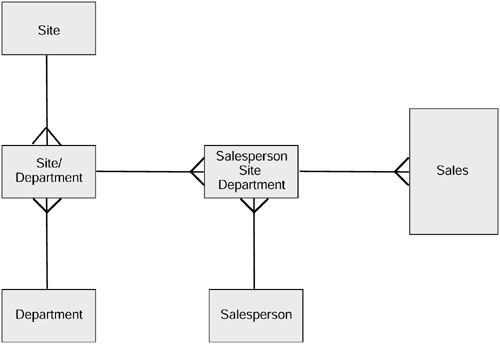
This brief introduction to the problem shows that it is not really possible to combine a time-variant data warehouse model with a non-time -variant operational model without some disruption to the original model. If we compare the altered data model to the original model, it is clear that the introduction of the time-variant sales entity has had some repercussions and has forced some changes to be made. This is one of the main reasons that forces data warehouses to be built separately from operational systems. Some practitioners believe that the separation of the two is merely a performance issue in that most database products are not able to be optimized to support the highly disparate nature of operational versus decision support type of queries. This is not the case. The example shows that the structure of the data is actually incompatible. In the future it is likely that operational systems will be built with more decision support awareness, but any attempt to integrate decision support systems into traditional operational systems will not be successful.
The Effect of Time on Query Results
As these entities change over time, in operational processing systems, the new values tend to replace existing values. This gives the impression that the old, now replaced , value never existed. For instance, in the Wine Club example, if a customer moves from one address to another and, at the same time, switches to a new region, there is no reason within the order processing system to record the previous address as, in order to service orders, the new address is all that is required. It could be argued that to keep information about the old address is potentially confusing, with the risk that orders may be inadvertently dispatched to the wrong address.
In a temporal system such as a data warehouse, which is required to record and report upon history faithfully, it may be very important to be able to distinguish between the orders placed by the customer while resident at the first address from the orders placed since moving to the new address. An example of where this information would be needed is where regional sales were measured by the organization. In the example described above, the fact that the customer, when moving, switched regions is important. The orders placed by the customer while they were at the previous address need to have that link preserved so that the previous region continues to receive the credit for those orders. Similarly, the new region should receive credit for any subsequent orders placed by the customer during their period of residence at the new address. Clearly, when designing a data warehouse in support of a CRM strategy, such information may be very important. If we recall the cause-and-effect principle and how we applied it to changing customer circumstances, this is a classic example of precisely that. So the warehouse needs to record not only the fact that the data has changed but also when the change occurred. There is a conflict between the system supplying the data, which is not temporal, and the receiving system, which is. The practical problems surrounding this issue are dealt with in detail later on in this chapter.
The consequences of the problem can be explored in more detail by the use of some data. Figure 4.7 provides a simple illustration of the problem by building on the example given. We'll start by adding some data to the entities.
Figure 4.7. Sales hierarchy with data.
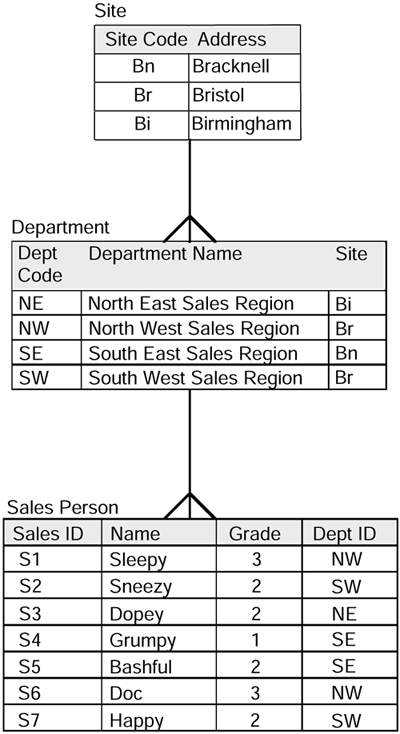
The example in Figure 4.7 shows a Relational style of implementation where the relationships are implemented using foreign key columns . In the data warehouse, the Salesperson dimension would be related directly to the sales fact table. Each sales fact would include a foreign key attribute that would contain the sales identifier of the salesperson who was responsible for the sale.
In order to focus on the impact of changes to these relationships, time is omitted from the following set of illustrative queries.
In order to determine the value of sales by salesperson, the SQL query shown in Query Listing 4.1 could be written:
Listing 4.1 Total sales by sales-person.
Select name, sum(sales_value) from sales s1, sales_person s2 where s1.sales_id = s2.sales_id group by name
In order to determine the value of sales by department, the SQL query shown in Query Listing 4.2 could be written:
Listing 4.2 Total sales by department.
Select department_name, sum(sales_value) from sales s1, sales_person s2, department d where s1.sales_id = s2.sales_id and s2.dept_id = d.dept_code group by department_name
If the requirement was to obtain the value of sales attributable to each site, then the query in Query Listing 4.3 could be used:
Listing 4.3 Total sales by site.
Select address, sum(sales_value) from sales s1, sales_person s2, department d, site s3 where s1.sales_id = s2.sales_id and s2.dept_id = d.dept_id and d.site = s3.site_code group by address
The result sets from these queries would contain the sum of the sales value grouped by salesperson, department, and site.
The results will always be accurate so long as there are no changes in the relationships between the entities. However, as previously shown, changes in the dimensions are quite common.
As an example, if Sneezy were to transfer from department SW to department NW, his relationship between the salesperson entity and the department entity will have changed. If the same three queries are executed again, the results will be altered.
The results of the first query in Query Listing 4.1, which is at salesperson level, will be the same as before because the sales made by Sneezy are still attributed to him.
However, in Query Listing 4.2, which is at the department level, all sales that Sneezy was responsible for when he worked in department SW will in future be attributed to department NW. This is clearly an invalid result.
The result from the query in Query Listing 4.3, which groups by site address, will still be valid because, although Sneezy moved from SW department to NW department, both SW and NW reside at the same address, Bristol. If Sneezy had moved from SW to SE or NE, then the Listing 4.3 results would be incorrect as well.
The example so far has focused on how time alters the cardinality of relationships. There is, equally, an effect on some attributes. If we look back at the salesperson entity in the example, there is an attribute called Grade. This is meant to represent the sales grade of the salesperson. If we want to measure the performance of salespeople by comparing volume of sales against grades, this could be achieved by the following query:
Select grade, sum(sales_value) from sales s1, sales_person s2 where s1.sales_id = s2.sales_id group by grade
If any salesperson has changed their grade during the period covered by the query, then the results will be inaccurate because all their sales will be recorded against their current grade. In order to produce an accurate result, the periods of validity of the salesperson's grades must be kept. This might be achieved by the introduction of another intersection entity.
If no action is taken, the database will produce inaccurate results. Whether the level of inaccuracy is acceptable is a matter for the directors of the organization to decide. Over time, however, the information would become less and less accurate, and the value of the information is likely to become increasingly questionable.
How do the business people know which are the queries that return accurate results and, more importantly, which ones are suspect?
Unfortunately for our users, there is no way of knowing.
The Time Dimension
The time dimension is a special dimension that contains information about times. For every possible time that may appear in the fact table, an entry must exist in the time dimension table. This time attribute is the primary key to the time dimension. The non “key attributes are application specific and provide a method for grouping the discrete time values. The groupings can be anything that is of interest to the organization. Some examples might be:
-
Day of week
-
Week end
-
Early closing day
-
Public holidays/bank holidays
-
24- hour opening day
-
Weather conditions
-
Week of year
-
Month name
-
Financial month
-
Financial quarter
-
Financial year
Some of the groupings, listed above, could be derived from date manipulation functions supplied by the database management system, whereas others, clearly, cannot.
The Effect of Causal Changes to Data
Upon examination, it appears that some changes are causal in nature, in that a change to the value of one attribute implies a change to the value of some other attribute in the schema. The extent of causality will vary from case to case, but the designer must be aware that a change to the value of a particular attribute, whose historical values have low importance to the organization, may cause a change to occur in the value of another attribute that has much greater importance. While this may be true in all systems, it is particularly relevant to data warehousing because of the disparate nature of the source systems that provide the data used to populate the warehouse. It is possible, for instance, that the source system containing customer addresses may not actually hold information about sales areas. The sales area classification may come from, say, a marketing database or some kind of demographic data. Changes to addresses, which are detected in the operational database, must be implemented at exactly the same time as the change to the sales area codes.
Acknowledgment of the causal relationship between attributes is essential if accuracy and integrity are to be maintained . In the logical model it is necessary to identify the dependencies between attributes so that the appropriate physical links can be implemented.
| only for RuBoard - do not distribute or recompile |
EAN: 2147483647
Pages: 96