Poly Model Pattern
IntentTo be able to provide a dynamic data model that can be edited without affecting a physical data model and with minimal to no impact on an existing data services framework. ProblemThe core patterns of this chapter lie in the assembly units of the Poly Model pattern. For this reason, this particular pattern can be considered a "composite" pattern of sorts. No, it isn't a pattern implemented in a strange new language, so you can continue reading. A composite pattern is simply an ensemble of highly related design and architecture patterns that, as a whole, make up a pattern itself, sort of like a miniature framework. This idea gets into some of the subtle nuances of pattern naming and classification, so consider this somewhat subjective of the author. Also I think a different pattern classification is necessary here because, unlike design patterns, a composite pattern does not limit itself to one primary object model and relates more to architecture and implementation than design. However, unlike both architecture patterns and implementation patterns, it is not tied to any one technology. This is important to remember because XML and schemas in particular benefit from the fact they are not implementation-specific. It is only a matter of topic that the Poly Model pattern presented here happens to be implemented using .NET and more specifically , XML schemas. Also, like design, architecture, and implementation patterns, a composite pattern is still repeatable and, thus, can be named and reused in many scenarios. One of the scenarios the Poly Model pattern fits into is one that involves an application that has an ever-changing data model. Have you ever tried to design a framework that could never sit still because the data model behind changed so often? Those of you who have implemented N- tier frameworks should all be familiar with how data modeling changes impact a system and the effect it has on each and every layer above the data layer. If one field is changed, it can have a radiating effect with each layer by forcing the design to be altered in many places instead of just one. A data model has always been one of those "design" pieces that need to be solidified before production. This issue came up for me in the commercial product featured here, and it is exactly where the Poly Model pattern idea was spawned. What if you could build into a data tier design the ability for the data tier to retrofit itself into any ERD ”dynamically? Take that a step further: How would you like to be able to alter the ERD with little to no impact on the rest of the system? Does this s ound too good to be true ? Creating such a model does present its drawbacks, as we will uncover. However, if implemented strategically, the Poly Model pattern can save many man hours and, more important, eliminate some of the down time of any production applications that have continually changing databases. Unfortunately, implementing the Poly Model pattern will take a little patience. It is recommended that the following patterns be understood and implemented before completely assembling the Poly Model pattern. In fact, as mentioned earlier, this pattern differs in that it is a sum of the parts (or patterns, in this case) that make up this chapter. It is presented first only to "frame" the rest of the contents. If you want to skip ahead and read how each of the following patterns are presented, you may skip this for now and come back. However, to get a feel for the following patterns, such as Schema Field, I suggest you keep reading. ForcesUse the Poly Model pattern when:
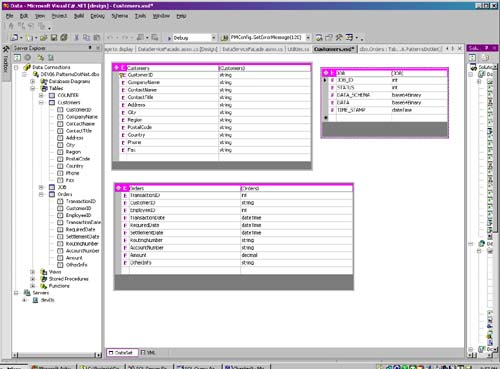
StructureUnlike most of the structure sections in this book, the Poly Model does not contain the typical class diagram. That is because the Poly Model is a composite of other patterns and practices described in this chapter. To begin the Poly Model, you first need a data schema. Fortunately for you, Visual Studio .NET could not have made it any simpler to create XML schemas. In fact, if you prefer to model your schema in a database such as SQL Server, you also have this option. Visual Studio .NET will allow you to drag and drop a table from any compliant database into the schema design workspace using the Server Explorer. For those more comfortable with designing tables in enterprise data bases such as SQL Server or for those new to Visual Studio .NET, this presents a very convenient option. You may also create a data schema from scratch inside of Visual Studio. The choice is yours. The following schema (Figure 5.1) will be used for the implementation examples in this chapter. I've presented both the Visual Studio view and the XML output (to get a feel for what our XML schema will resemble) for three tables, two of which will be manipulated in the patterns that follow. Figure 5.1. DataSet view of the XML schema design used in this chapter. As you can see on the left of Figure 5.1, the Server Explorer can be used to drag a preexisting table into Visual Studio (layout only) and thus avoid having to create the schema from scratch. Keep in mind that the actual table will not be used to store the actual data in this example; this is the main premise of the pattern. The database shown here is used only to create our XML schema. So where will the instance data go? In Figure 5.2, you will see the actual physical model that will hold not only our instance data but the XML schema itself. Figure 5.2. XML view of the XML schema design used in this chapter.
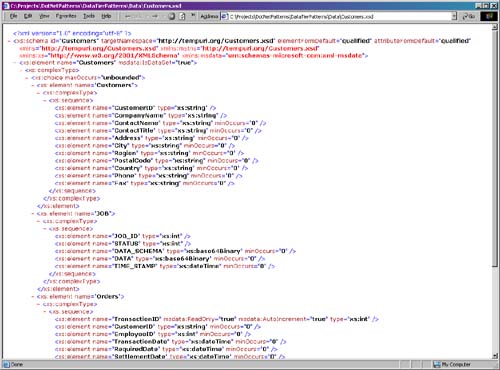
As you can see in Figure 5.2, the schema used is nothing more than an XSD XML schema generated in Visual Studio. The only main difference between this schema and a typical XML schema is the msdata :IsDataSet="true" attribute in the first element tag. This basically tells us that this is meant to be used in an ADO.NET DataSet, which is something we will get to shortly. To get a better understanding of what this pattern accomplishes and what elements you need, you should be aware of the activities that occur in a framework that supports dynamic modeling. Applying the Poly Model pattern comes down to the following six main runtime activities that are covered, in part, in every helper pattern contained within this composite:
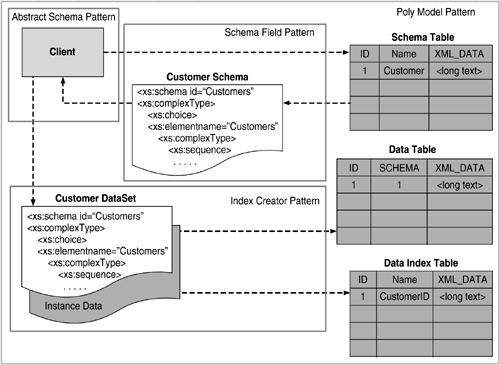
These activities combined make up the Poly Model pattern as outlined here but each can be useful in its own right and, thus, have been divided into the child patterns that follow. Many more elements must go into a product-ready system, some of which I talk about in this book. The featured commercial application in Chapter 6 uses each of these patterns to implement this dynamic data model, using these patterns and many more not covered in this book. For example, to be able to throw a large amount of data at something like a dynamic model requires a little more thought in the areas of caching and other optimizations that should be implemented in order for the system to perform well. That is not to say that using the Poly Model will guarantee a slow system, but be forewarned that it will be slightly slower than a more traditional physical model . For the "batch-oriented" type product featured in Chapter 6, the primary goal was flexibility, with performance coming in at a close second. This was not as much of an issue as it would be in a more transactional system. Also, the Poly Model does not have to be utilized in its entirety. For example, columns can be added to any normalized physical model for those parts of that model that may change often. That way, you get the best of both worlds . Performance-sensitive data can be normalized, indexed, and queried as you've always done. Those parts of the model that you feel may change can then be added to a schema-based dynamic model (as shown in this chapter) to continue to provide you with some flexibility. The following diagram will help explain some of these activities and show the main components of the Poly Model pattern. As you'll notice, the child patterns of the composite drive the implementation of it as a whole. Besides the activities, the components involved are a mix of business classes, actual XML schemas, and the physical tables. These components include the following:
As you can see from Figure 5.3, a driver initiates a Poly Model conversation by first requesting a schema. This has to be done only once and can be done during application startup or even installation; caching the schema will obviously improve performance and, thus, avoid unnecessary repetitive requests . Once the schema is retrieved, it can then be used to initialize the DataSet. At this point, the DataSet becomes a strongly typed DataSet (see the schema technology backgrounder section earlier in this chapter). This allows specific tables and columns to be directly accessible from the client or driver using method names specific to the schema. Any data that then flows from the client to the actual data store will utilize this DataSet containing the originally requested schema, along with any instance data. The instance data comes from two sources. The first source comes from those scenarios where the client needs to save transaction data to the database, in which case the instance data will come from the client. The second source comes from scenarios where data is simply retrieved from the database. Here the schema and instance data should be returned in an already strongly typed DataSet to be consumed from the client as needed. To make use of a schema, you have to generate, store, and eventually retrieve one. That is where the Schema Field pattern comes in and is the next featured pattern. Figure 5.3. Overall flow of activity of the Poly Model "composite" pattern. Consequences
Participants
ImplementationWhat if your business object could use the same method to store a transaction, no matter what table you write or what fields you populate? What if the same applied for retrieving instance data or any query, for that matter? Most application architectures would call for the business object to aggregate a specific data object that is tied directly to one or more tables and contains the SQL for those entities. The Poly Model completely abstracts this need, providing a generic data access framework, no matter what physical model is used. The beauty of the Poly Model is that it is rather simple, compared with some of the more complicated dynamic modeling out there using XML. So what does the Poly Model look like in code? Storing a transaction, for example, looks like the simplified code snippet in Listing 5.9. Keep in mind that a Packet object is simply a wrapped DataSet object. Listing 5.9 StoreTransaction method that drives the Poly Model persistence engine. public virtual bool StoreTransaction(Packet oTrans) { try { . . . // Delegates to provider-specific call bResult = DBStoreTransactionRecord(oTrans); if(bResult) { // Schema Indexer used for storing lookups // see schema Indexer Pattern later in this // chapter return StoreKeys(oTrans); } . . . return false; } The code in Listing 5.9 delegates to a provider-specific implementation of the same function. After that, it calls StoreKeys. StoreKeys implements the Schema Indexer pattern, which is another child pattern I'll cover in this chapter. Until then, I will focus only on the actual data and data log storage. The following code takes the packet, stores the data in the data log, and finally stores the entire DataSet as XML in the instance data table, using the displayed stored procedures: Listing 5.10 Called by StoreTransaction to store data in the DATA table and DATA_LOG table. public override bool DBStoreTransactionRecord(Packet oTrans) { try { . . . if(oTrans == null) return false; int iNumTries = 0; bool bResult = false; StringBuilder sb = null; while(iNumTries < DTPConstants.MAX_DB_ATTEMPTS) { // Write the database log record to the // DATA_LOG table bResult = DBStoreTransactionRecord(oTrans, "sp_DNPaternsUpdateDataLog"); if(bResult) { . . . // Write the database record to // the DATA table return DBStoreTransactionRecord(oTrans, "sp_DNPatternsUpdateData"); } . . . iNumTries++; } . . . return false; } . . . return false; } Listing 5.11 Storing the actual instance data passed, using a DataSet and passed-in stored procedure. public override bool DBStoreTransactionRecord(Packet oTrans, string sStoredProcedureName) { try { if(oTrans == null) return false; if(sStoredProcedureName.Length == 0) return false; PolyModelData oDB = null; oDB = ModelFactory.CreatePolyModelData(sStoredProcedureName, CommandType.StoredProcedure); if(oDB == null) return false; v// Bind input stored procedure parameter vSqlParameter oInParm1 = null; oInParm1 = (SqlParameter) oDB.AddDataParameter("@TransID", SqlDbType.BigInt, ParameterDirection.Input); if(oInParm1 == null) return false; oInParm1.Value = oTrans.TransactionID; // Bind input stored procedure parameter SqlParameter oInParm2 = null; oInParm2 = (SqlParameter) oDB.AddDataParameter("@schemaID", SqlDbType.BigInt, ParameterDirection.Input); if(oInParm2 == null) return false; oInParm2.Value = oTrans.ProductschemaID; // Bind input stored procedure parameter SqlParameter oInParm3 = null; oInParm3 = (SqlParameter) oDB.AddDataParameter("@xmlData", SqlDbType.Image, ParameterDirection.Input); if(oInParm3 == null) return false; string sxml = string.Empty; sxml = oDB.WriteXml(oTrans.RawData, XmlWriteMode.Ignoreschema); oInParm3.Value = Encoding.ASCII.GetBytes(sxml); SqlParameter oOutParm = null; oOutParm = (SqlParameter) oDB.AddDataParameter("@RowCount", SqlDbType.Int, ParameterDirection.ReturnValue); if(oOutParm == null) return false; // Execute the stored procedure int iRowCount = 0; iRowCount = oDB.ExecuteNonQuery(); // Get the result of the stored procedure int iCount = 0; iCount = Convert.ToInt32(oDB.GetDataParameterValue("@RowCount")); if(iCount == 1) return true; } . . . return false; } Both stored procedures are straightforward but are worth showing. The following is the stored procedure used for updating the data log: Listing 5.12 Stored procedure used for saving to the DATA_LOG table. [View full width] CREATE PROCEDURE dbo.sp_DNUpdateDataLog @TransID BIGINT, @schemaID BIGINT, @xmlData IMAGE AS . . . INSERT INTO dbo.[DATA_LOG] (TRANS_ID, SCHEMA_ID, xml_DATA, TIME_STAMP) VALUES (@TransID, The next stored procedure is not much different. It will save data to the main instance data table that will be used for queries later: Listing 5.13 Stored procedure used for saving XML instance data to the main DATA table.CREATE PROCEDURE dbo.sp_DNUpdateData @TransID BIGINT, @schemaID BIGINT, @xmlData IMAGE AS . . . IF EXISTS (SELECT * FROM dbo.[DATA] WHERE TRANS_ID = @TransID) BEGIN UPDATE dbo.[DATA] WITH (HOLDLOCK) SET TRANS_ID = @TransID, SCHEMA_ID = @schemaID, xml_DATA = @xmlData, TIME_STAMP = GETDATE() WHERE TRANS_ID = @TransID END ELSE BEGIN INSERT INTO dbo.[DATA] (TRANS_ID, SCHEMA_ID, xml_DATA, TIME_STAMP) VALUES (@TransID, @schemaID, @xmlData, GETDATE()) END . . . GO Much like the remaining code in this chapter, the above snippets are straightforward. They do not rely heavily on any specific technology other than using XML and its schema from a generated DataSet. For every transaction that is stored, a reference to its schema will also get stored, along with the instance data, as XML. The fields that make up the physical model are used solely for storing the XML content, indexing the schema, and providing a transaction ID for later lookup (see the Schema Indexer section later in this chapter). Gone is the need to map each individual field of an object to individual fields of the database through a more traditional "data services" layer. Other than generating the appropriate keys for lookup, we now have given the developer a great deal of flexibility. This frees you from the daunting tasks of maintaining such a data services layer and all of the data objects that go along with it. For those systems that can put up with slightly slower transaction throughout and slightly larger DataSets, the Poly Model can really begin to shine . Once the framework is in place, the Poly Model allows much faster time to market and the elimination of hours of tedious data class development and maintenance. Creating the Poly Model can have some great value propositions but data isn't very useful if you can't look up what you've now stored. Your data isn't much good to you if you cannot easily query for it. This is especially true during your development and debugging efforts because you will not be able to simply view the data in SQL Server ”the instance data itself is now an "image" field stored in one column of the DATA table. This does present a slight problem in that tools have to be built to view this data. Tools specifically designed to view Poly Model data, such as the SQL tools, have been built to construct a complex filter so that you can get to specific rows of data while developing your business applications. But rest assured, those tools are not difficult to implement. The foundation for building these tools lies in designing a facility so that queries can be made against this denormalized physical model. This will be covered in detail when we discuss the Schema Indexer pattern later in this chapter. Related Patterns
|
EAN: 2147483647
Pages: 70