Optimizer Diagnostics and Tuning
| < Day Day Up > |
| MySQL offers an array of diagnostic information from the optimizer, as well as commands that you can use to help tune and guide this vital engine component. Most database administrators and developers will want to rush right in and start using the EXPLAIN command. However, EXPLAIN does not exist in a vacuum: There are complex interrelationships with other optimizer management commands, such as ANALYZE TABLE and OPTIMIZE TABLE. The following sections look at these first and then turn the attention to EXPLAIN. The ANALYZE TABLE CommandThe optimizer relies on accurate, up-to-date information to make its decisions. Statistics about indexes, including their keys, distribution, and structure, are critical factors in determining the most optimal results. For the InnoDB, MyISAM, and BDB engines, MySQL offers the ANALYZE TABLE command to calculate and store this information: mysql> ANALYZE TABLE customer_master; +--------------------------+---------+----------+----------+ | Table | Op | Msg_type | Msg_text | +--------------------------+---------+----------+----------+ | high_hat.customer_master | analyze | status | OK | +--------------------------+---------+----------+----------+ 1 row in set (0.47 sec) It's a good idea to run this command periodically, especially for those tables subject to frequent updates that involve indexed columns. To help you in choosing when to run the command, note that the engine places a read lock on the table for the duration of the study. However, if there are no changes to the underlying table, MySQL simply skips the analysis. The OPTIMIZE TABLE CommandThe storage advantages of variable-length rows were discussed earlier in the book. At that time, fragmentation was also cited as a potential performance risk. Fortunately, MySQL's OPTIMIZE TABLE command can defragment these tables, thereby restoring them to a more efficient structure while sorting any necessary indexes at the same time: mysql> OPTIMIZE TABLE customer_master; +--------------------------+----------+----------+----------+ | Table | Op | Msg_type | Msg_text | +--------------------------+----------+----------+----------+ | high_hat.customer_master | optimize | status | OK | +--------------------------+----------+----------+----------+ 1 row in set (3 min 51.78 sec) Note that like its cousin ANALYZE TABLE, this command locks a table for the duration of processing. However, because it often restructures the table, OPTIMIZE TABLE generally takes much longer to complete, so be careful when selecting your launch time. Disk management best practices are reviewed in more detail later in the book, especially in Chapter 13, "Improving Disk Speed." For now, take a look at a specific example of how OPTIMIZE TABLE can affect the disk usage and index structure of a table. For this example, we created a sample table as follows: CREATE TABLE optimize_example ( col1 INT AUTO_INCREMENT PRIMARY KEY, col2 VARCHAR(30), col3 VARCHAR(100), col4 VARCHAR(255) ) ENGINE = INNODB; We then loaded one million rows of random data into this table, followed by creating an index on col2: CREATE INDEX opt_ix1 ON optimize_example(col2); After building the index, MySQL reported this table's size at 215.8MB, and the indexes consumed a further 37.6MB. Next, to simulate significant changes to the quantity of data in the table and index, we deleted every fifth row: DELETE FROM optimize_example WHERE mod(col1,5) = 0; After these large-scale deletions, MySQL continues to report this table's size at 215.8MB and the indexes at 37.6MB. We then loaded 250,000 more rows of random data. The reported size is now 218.8MB of data and 35.6MB of index. At this point, we ran the OPTIMIZE TABLE command to defragment the table and re-sort its indexes: mysql> OPTIMIZE TABLE optimize_example; +---------------------------+----------+----------+----------+ | Table | Op | Msg_type | Msg_text | +---------------------------+----------+----------+----------+ | high_hat.optimize_example | optimize | status | OK | +---------------------------+----------+----------+----------+ 1 row in set (4 min 56.69 sec) After the command ran, the sample table had been compressed to 175.7MB of data and 33.6MB of index: a significant size reduction and defragmentation. The EXPLAIN CommandDatabase designers and developers use MySQL's EXPLAIN in one of two ways:
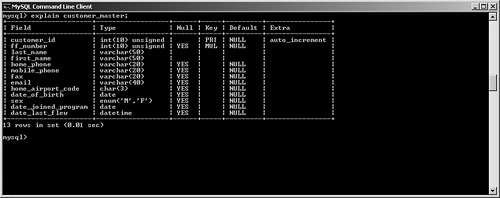
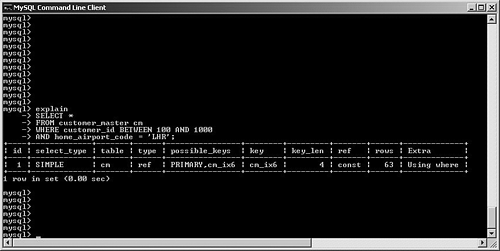
The first question about EXPLAIN is simple: When should you use it? Fortunately, the answer is simple as well. You should use this command whenever you are designing queries against a large and/or complex database, because you may elect to use the results to alter your indexing strategy or even override the optimizer's query plan. Next, how do you launch EXPLAIN? Whether you're using the command-line interface or the MySQL Query Browser, simply prefix your SQL SELECT statement with EXPLAIN. The optimizer then returns a detailed report on the suggested query plan. Let's review these reports in more detail. Before beginning, use the following tables and related indexes throughout the balance of this chapter to help illustrate our examples: CREATE TABLE customer_master ( customer_id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY, ff_number CHAR(10), last_name VARCHAR(50) NOT NULL, first_name VARCHAR(50) NOT NULL, home_phone VARCHAR(20), mobile_phone VARCHAR(20), fax VARCHAR(20), email VARCHAR(40), home_airport_code CHAR(3), date_of_birth DATE, sex ENUM ('M','F'), date_joined_program DATE, date_last_flew DATETIME ) ENGINE = INNODB; CREATE INDEX cm_ix1 ON customer_master(home_phone); CREATE TABLE customer_address ( customer_id INT UNSIGNED NOT NULL, customer_address_seq SMALLINT(2) UNSIGNED NOT NULL, address1 VARCHAR(50), address2 VARCHAR(50), address3 VARCHAR(50), city VARCHAR(50), state VARCHAR(50), country VARCHAR(70), postal_code VARCHAR(20), PRIMARY KEY (customer_id, customer_address_seq) ) ENGINE = INNODB; CREATE INDEX ca_ix1 ON customer_address(postal_code); CREATE INDEX ca_ix2 ON customer_address(country); CREATE TABLE transactions ( transaction_id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY, transaction_date DATETIME NOT NULL, customer_id INT NOT NULL, amount DECIMAL (5,2) NOT NULL, transaction_type ENUM ('Purchase','Credit') ) ENGINE = MYISAM; CREATE INDEX tr_ix2 on transactions(customer_id); CREATE TABLE airports ( airport_id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY, airport_code CHAR(3) NOT NULL, airport_name VARCHAR(40), vip_club SMALLINT(1), club_upgrade_date DATE ) ENGINE = INNODB; CREATE UNIQUE INDEX air_ix1 ON airports(airport_code); CREATE TABLE flights ( flight_id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY, flight_number SMALLINT UNSIGNED NOT NULL, flight_date DATE NOT NULL, flight_departure_city CHAR(3), flight_arrival_city CHAR(3) ) ENGINE = INNODB; CREATE TABLE customer_flights ( customer_flight_id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY, customer_id INT UNSIGNED NOT NULL, flight_id SMALLINT UNSIGNED NOT NULL, FOREIGN KEY (customer_id) REFERENCES customer_master(customer_id), FOREIGN KEY (flight_id) REFERENCES flights(flight_id) ) ENGINE = INNODB; Figure 6.2 shows a sample query as well as its related EXPLAIN output. Figure 6.2. Sample query and its EXPLAIN output.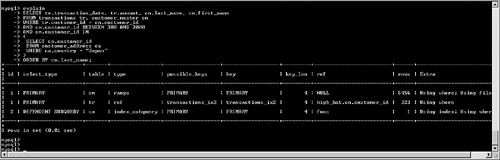 How can you interpret these results? This section first looks at a field list of the returned information, and then provides a detailed explanation of each value, along with examples. Table 6.1 lists the columns returned by the EXPLAIN command, along with each column's purpose.
The following sections look at each of the columns in more detail. idRemember that MySQL processes tables in the order in which they are listed in the EXPLAIN output. As you evaluate the proposed query plan and ponder making adjustments, keep an eye on the sequence number for each table. select_typeDepending on query structure, SELECT statements are classified as one of the following:
tableMySQL cites the table name for each step of the query plan. Derived tables are identified as such; tables to hold the results of UNIONs are prefixed with union. typeAs you saw earlier, type refers to the kind of join that MySQL performs to retrieve your information. This is crucial to estimating performance because a bad join strategy can really bog down your application. The following list looks at each of the potential values for this column, along with the scenarios that trigger the result. Because the goal is optimization, the list begins with the most sluggish values, and then works its way toward the fastest. As you experiment with your queries, always strive to achieve values toward the end of this list:
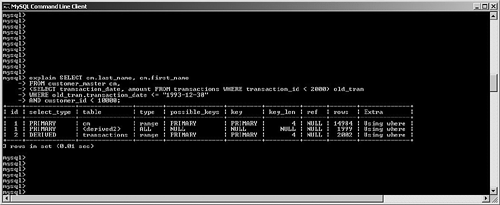
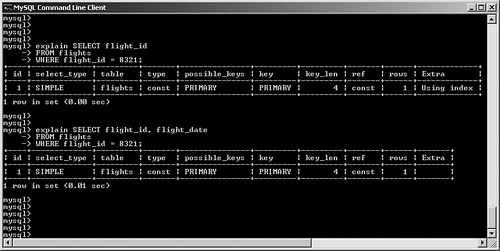
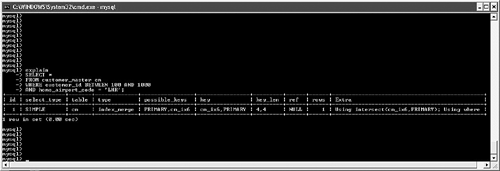
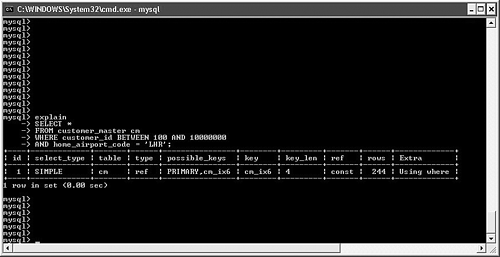
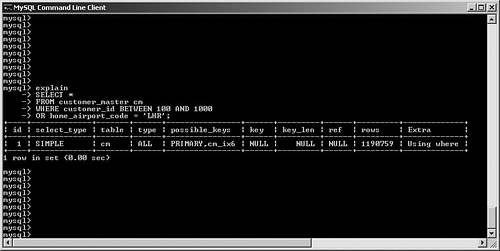
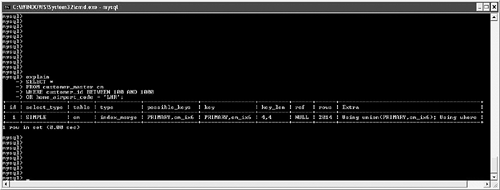
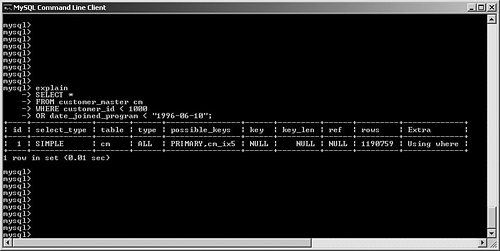
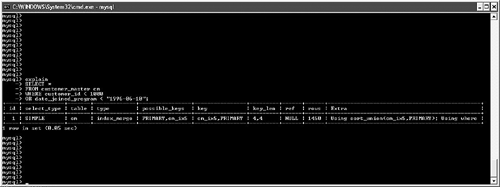
possible_keys and keyMySQL often has multiple indexes at its disposal when trying to decide on a query plan. Viewing possible_keys lets you see the full list of potential indexes that the optimizer is evaluating, whereas the key value tells you what MySQL ended up choosing, as shown in Figure 6.4. Figure 6.4. EXPLAIN output for a query that uses the primary key.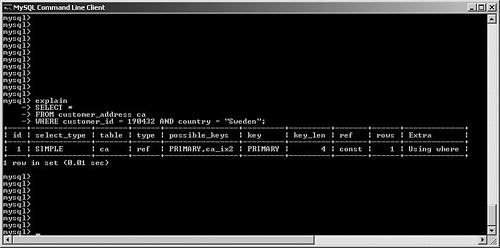 In this case, MySQL had a choice between the primary key (customer_id) and the ca_ix2 index (country). The optimizer selected the primary key. If you're curious to learn more about how the optimizer chooses a plan, try experimenting with queries. For example, observe what happens when you change one word in the query (from AND to OR), as shown in Figure 6.5. Figure 6.5. Query plan radically changed by substitution of OR for AND.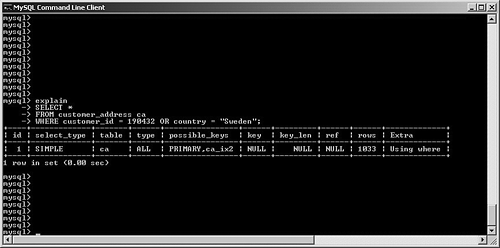 What happened? Why can't MySQL use our well-thought-out indexes? In this case, the search is written with an OR clause that refers to a single table. This forces the engine into a sequential table scan (ALL), or at least it did until version 5.0. MySQL version 5.0 features much more robust optimizer algorithms that can speed these kinds of queries. Figure 6.6 shows the same query after version 5.0. Figure 6.6. Version 5.0 now uses the index_merge algorithm to avoid a table scan by taking advantage of multiple indexes.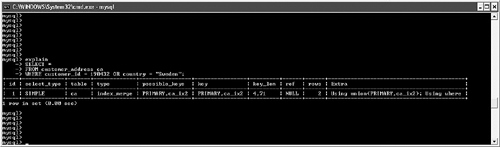 With version 5.0, MySQL can now make use of multiple indexes on a single table to speed results. These new algorithms are explored a little later in this chapter. You'll also examine how to override the optimizer's analysis. Finally, Chapter 7, "Indexing Strategies," spends much more time probing indexing strategies. key_lenAfter MySQL has selected a key, this field shows the length of the chosen option. The example shown in Figure 6.7 uses the integer-based primary key for the customer_address table, which is four bytes in length. The second example searches on an indexed string field. SELECT * FROM customer_address ca WHERE customer_id = 190432 OR country = "Sweden"; SELECT * FROM customer_address ca WHERE country = "Singapore"; Figure 6.7. Different query plans based on the type of index key chosen.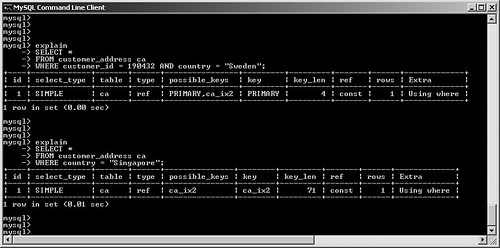 MySQL reports the length of the field if it's a single field. For a multifield index, MySQL reports the full length of all fields (working from left to right) that will be used. For example, suppose you create a multifield index (ca_ix3) on the customer_address city and state columns and then query against those values, as shown in Figure 6.8. Figure 6.8. Query that uses a new multifield index.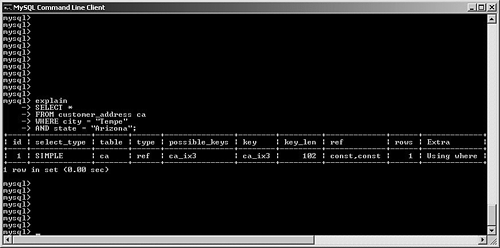 As you can see, MySQL was able to use the multifield index to satisfy the query; the key length is the sum of the two fields (50 + 50), plus one overhead byte per field. refThis field tracks the values or columns that will be used to look for the row(s), as shown in Figure 6.9. Figure 6.9. Query plan showing candidate columns for searching.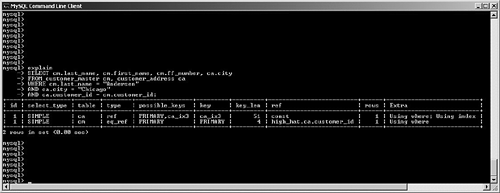 In this example, MySQL is able to filter the customer_address table on the newly created index, and then use the customer_id field as the lookup field for the second part of the query: matching the customer_address rows with their counterparts in customer_master. It might be somewhat difficult to analyze and understand the results in this field because there will be times that MySQL reports NULL on a search when you might expect a const instead, as shown in Figure 6.10. Figure 6.10. Two similar queries with different types of ref results.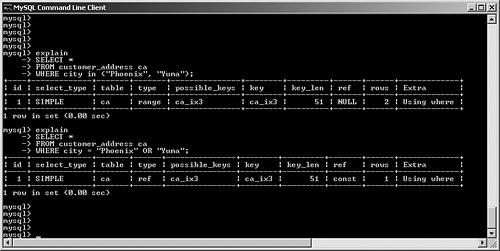 The first query performs a range search, which results in NULL in the ref column: SELECT * FROM customer_address ca WHERE city in ("Phoenix", "Yuma") The second search performs a ref search, so you see const in the ref column: SELECT * FROM customer_address ca WHERE city = "Phoenix" OR "Yuma" rowsMySQL uses its internal table and index statistics to provide this number, which is its best estimate of the quantity of records that should be read to produce the results. Pay attention to very large numbers in this column: It usually indicates a table scan or highly duplicate index. As you saw earlier, this can become an even bigger problem when many tables in the query require the reading of large numbers of rows. To keep MySQL's statistics up to date, it's also important to run ANALYZE TABLE or OPTIMIZE TABLE for those tables that change frequently. ExtraThe EXPLAIN command offers additional diagnostic information on top of the helpful data you've seen so far. These messages are placed in the exTRa column, and can include one or more of the following:
As you saw earlier in the discussion on the type portion of EXPLAIN's output, MySQL's optimizer features enhanced algorithms beginning with version 5.0. These new capabilities let MySQL exploit two or more indexes on a single table to speed queries. The following list looks at how the extra portion of the EXPLAIN command reports on these new algorithms.
As you experiment with your queries, see if you can construct your indexes and searches to take advantage of these new 5.0 features. Helping the OptimizerAs you've seen, MySQL's optimizer conducts a sophisticated analysis of the facts before coming up with a query plan. However, it is not infallible, and there might be times when it could use your help. This section investigates several ways to provide assistance to the optimizer. Remember that it's always a good idea to take a scientific approach to your query tuning, and track the impact your suggestions have on query plans and actual response. Also, remember that this section only looks at ways to directly affect the optimizer's behavior (including query plan choice). In particular, this section examines SELECT STRAIGHT_JOIN and USE INDEX, IGNORE INDEX, and FORCE INDEX. You'll look at ways to tune your SQL statements and engine behavior in later chapters. These optimizer-affecting SQL statement options include the following:
SELECT STRAIGHT_JOINFor a multitable join, you might elect to change the order in which the optimizer joins your tables. By specifying STRAIGHT_JOIN in your SQL, MySQL is forced to join the tables in the order in which they're specified in your query. Note that this is an extension by MySQL to standard SQL. You can look at a few examples to see when this might help (or even hurt!) performance. For simplicity, let's not consider the impact of query caching, memory, or other engine configuration. First, suppose you want to perform a very simple join between the customer_master and customer_address tables: SELECT cm.last_name, cm.first_name, ca.postal_code, ca.country FROM customer_master cm, customer_address ca WHERE cm.customer_id = ca.customer_id; For this join, MySQL first performs a table scan through the customer_address table. It reads each row, and then performs an eq_ref join to the customer_master table, using its primary key customer_id field. Assuming that the customer_master table has four million rows, the total number of rows read for this query is more than eight million: four million rows read from the customer_address table via a table scan, and one customer_master row read via the primary key per returned row. Suppose, however, that the customer_master table is only one fourth as large as customer_address, and only contains one million rows. How could this be? Perhaps each customer has multiple addresses (home, office, billing, warehouse, and so on). In any case, what would happen if you forced the optimizer to first look at the customer_master table and then join to customer_address? SELECT STRAIGHT_JOIN cm.last_name, cm.first_name, ca.postal_code, ca.country FROM customer_master cm, customer_address ca WHERE cm.customer_id = ca.customer_id; In this case, MySQL churns through the one million row customer_table, picking up rows one-by-one and then performing a rapid lookup into the customer_address table, using the indexed customer_id field. The number of rows read for this query is approximately five million: one million table-scanned rows from customer_master and an average of four customer_address rows to match the indexed join. For this example, it might be worth it to force MySQL first to read through the smaller table and then do an indexed lookup. Unfortunately, it's easy to imagine a scenario in which you damage performance by incorrectly forcing a straight join, so be careful when experimenting. Let's look at an experiment gone wrong: a badly designed optimizer override. Suppose that you want to retrieve a list of all customers, along with the name of their home airport: SELECT cm.last_name, cm.first_name, ai.airport_name FROM airports ai, customer_master cm WHERE cm.home_airport_code = ai.airport_code; Note that the airport_code field is uniquely indexed in the airports table (but not in the customer_master table), and this table has 1,000 rows. For this query, MySQL correctly performs a table scan on the customer_master table, reading its four million rows one-by-one and then performing a single read into the airports table for each customer_master record. What happens if you change the query to force MySQL to first read the airports table? SELECT STRAIGHT_JOIN cm.last_name, cm.first_name, ai.airport_name FROM airports ai, customer_master2 cm WHERE cm.home_airport_code = ai.airport_code; MySQL dutifully reads a row from the airports table, and then runs a table scan to read every one of the four million row customer_master table. After the table scan finishes, MySQL reads the next row from airports, and starts the table scan again to look for a new match. This is hundreds of times slower than if you had just left it alone. Of course, this query would run much more efficiently if the airport_code field was indexed in customer_master, but this isn't the case in the example. So far, you've looked at simple, two-table queries. Imagine the amount of time needed to study the potential impact (good or bad) of forcing straight joins on a five, six, or more table join. How would you know which table should go first, second, and so on? The number of permutations that you would need to test could become enormous. This is why, in most cases, it's a good idea to just let the optimizer do its job, unless you really do know better. Forcing Index SelectionIt's quite likely that many of your queries will access tables with multiple indexes. Generally, MySQL's optimizer uses its internal statistics to identify and choose the most efficient index. However, there might be situations in which you need to override this behavior. This section reviews several options that you can use in your SELECT statements to control how the optimizer picks an index. Recall that we're only looking at how to affect the optimizer's choice of index; Chapter 7 delves much more deeply into best practices for indexing. To keep this as simple as possible, this example only looks at a single-table query; MySQL uses this index selection to find rows in a particular table, and only then processes any subsequent joins. To save you the effort of flipping pages, the customer_master table is redisplayed here, along with some additional indexes: CREATE TABLE customer_master ( customer_id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY, ff_number CHAR(10), last_name VARCHAR(50) NOT NULL, first_name VARCHAR(50) NOT NULL, home_phone VARCHAR(20), mobile_phone VARCHAR(20), fax VARCHAR(20), email VARCHAR(40), home_airport_code CHAR(3), date_of_birth DATE, sex ENUM ('M','F'), date_joined_program DATE, date_last_flew DATETIME ) ENGINE = INNODB; CREATE INDEX cm_ix1 ON customer_master(home_phone); CREATE INDEX cm_ix2 ON customer_master(ff_number); CREATE INDEX cm_ix3 ON customer_master(last_name, first_name); CREATE INDEX cm_ix4 ON customer_master(sex); CREATE INDEX cm_ix5 ON customer_master(date_joined_program); CREATE INDEX cm_ix6 ON customer_master(home_airport_code); USE INDEX/FORCE INDEXIt's quite possible that MySQL will need to choose from a candidate pool of more than one index to satisfy your query. If, after reading the EXPLAIN output, you determine that MySQL is picking the wrong index, you can override the index selection by adding either USE INDEX or FORCE INDEX to the query. Take a look at some examples. First, suppose that you want to issue a search to find all customers who have a home phone number in the city of Boston, and whose home airport is Boston Logan, as shown in Figure 6.19. Figure 6.19. Optimizer correctly chooses between two candidate indexes to process a query.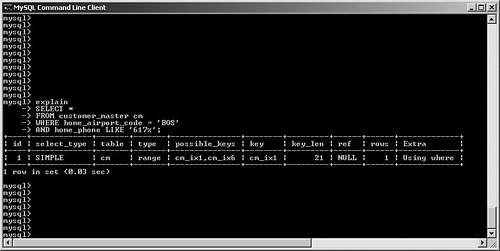 What does this tell us? MySQL correctly identified two candidate indexes to speed the search: cm_ix1 (on home_phone) and cm_ix6 (on home_airport_code). In the end, it chose the index on home_phone (because it is much more selective than the home_airport_code field). However, what if you wanted to force MySQL to use the index on home_airport_code? You would specify the USE INDEX option in your SQL statement, as shown in Figure 6.20. Figure 6.20. User intervention to force selection of a particular index to process a query.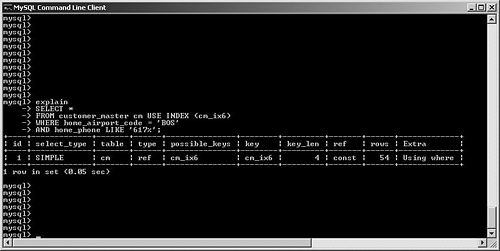 Observe that MySQL no longer even reports the availability of the cm_ix1 key; it only specifies the key you requested. What happens if you mistype the key (see Figure 6.21)? Figure 6.21. A typo produces an expensive table scan.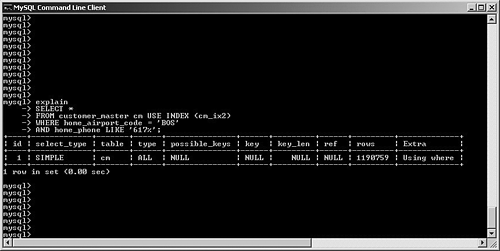 This is a costly mistake: MySQL does not warn us that this index is irrelevant for this query, and instead performs a table scan because of our typing error. The moral here is to pay attention when you override the optimizer! Where does FORCE INDEX fit in? FORCE INDEX (first enabled in version 4.0.9) is very similar to USE INDEX; the main difference between the two options is that FORCE INDEX demands that MySQL use the index (if possible) in lieu of a more expensive table scan, whereas USE INDEX still allows the optimizer to choose a table scan. IGNORE INDEXSometimes, tables are overindexed, and might confuse the optimizer into choosing an inefficient query plan. Fortunately, MySQL lets you "hide" certain indexes from the optimizer. Suppose you put the query shown in Figure 6.22 to MySQL. Figure 6.22. Optimizer chooses a very nonselective index.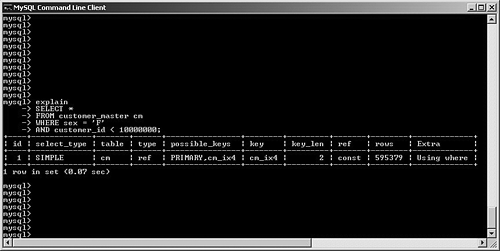 MySQL has correctly identified two candidates indexes the primary key (customer_id) and cm_ix4 (sex) and has chosen the latter. Unfortunately, this is not a very selective index, and probably shouldn't even exist. Chapter 7 discusses indexing in much more detail, but for now, you can use the IGNORE KEY option to tell the optimizer to avoid this key, as shown in Figure 6.23. Figure 6.23. Removing an index from consideration by the optimizer.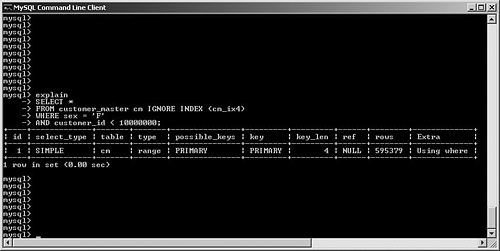 It's important to understand that overriding the optimizer will be a rare event as long as you keep your data and index statistics up to date (via ANALYZE TABLE and/or OPTIMIZE TABLE). Optimizer Processing OptionsRecall that it's the job of the optimizer to select the best plan among all possible alternatives. For relatively simple queries, the number of different choices might not be too large. But what happens if you construct very complex queries, involving more than a dozen large tables and very intricate search criteria? In these kinds of situations, it's possible that MySQL might spend more time picking a query plan from the millions of potential permutations than actually executing the query! Fortunately, versions 5.01 and beyond offer two system variables that give the database developer some control over how much time the optimizer spends calculating its query plan. optimizer_prune_levelThe optimizer_prune_level variable, set to 1 (enabled) by default, tells the optimizer to avoid certain query plans if it determines that the number of rows processed per table will be excessive. If you are confident that this avoidance is hurting performance and that MySQL should examine more query plans, set the variable to zero (disabled). Of course, this kind of experiment is a much better candidate for your performance testing platform, rather than your production system. optimizer_search_depthAs you saw earlier, queries that touch numerous tables can cause the optimizer to spend more time calculating the query plan than actually running the query. Setting the optimizer_search_depth system variable lets you control how exhaustive these computations will be. If you make this number large (close to the actual number of tables in the search), MySQL checks many more query plans, which could drastically degrade performance. On the other hand, a small number causes the optimizer to come up with a plan much faster, at the risk of skipping a better plan. Finally, setting this value to zero lets the optimizer make its own decision, and is probably the safest course of action in most cases. |
| < Day Day Up > |
EAN: 2147483647
Pages: 131