Page #40 (Interface Definition Language (IDL))
| < BACK NEXT > |
IDL Design Goals
While developing the COM infrastructure, the COM committee had many goals. Some of these goals had a direct impact on the design of IDL.
Let s take a look at how these goals were addressed in the IDL.
Remote Transparency
One of the main goals of COM was to provide communication between the client and the server even when they were running as two different processes, either on the same machine (locally) or on two different machines on the network (remotely). A process, in the simplest term, is an executing application. It consists of a private virtual address space, code, data, and other operating system resources, such as files, pipes, etc. Two processes do not share their address spaces. [1] In order for one process to pass data to another process, it requires writing low-level communication code involving complex data-handling mechanism. The complexity increases when the processes are running on separate machines on a network. The complexity increases further if the two machines are running disparate operating systems. For example, one OS may treat integers as big-endian (the most significant byte stored first) and the other as little-endian. In this case, the low-level communications code will have to handle transformations between the two formats.
[1] Though there are ways to share a portion of memory between two processes, it is not relevant to this discussion.
While this complexity could be interesting architecturally, few developers want to program low-level communications code. COM alleviated this pain from the software developers. The developers can focus on writing the code instead of worrying whether the client and the server are in the same process (termed in-process) or in two different processes (termed out-of-process). The COM infrastructure took care of handling communication details in the most efficient manner.
Method Remoting
With a standard programming model, when the caller invokes a method, the caller and the callee are typically in the same process space. In this case, the parameters to the method are placed on the stack. The callee reads the parameters from the stack and writes a return value back to the stack before returning.
Under COM, however, the callee (the server) could be running in a different process space than the caller (the client), either on the same machine or on a remote machine. A valid memory location in the client s address space may not have any meaning in the server s address space. Therefore, the client and the server cannot just communicate directly using the stack.
The communication problem could be solved if some piece of the client code could a) read all the parameters from the stack, and b) write them to a flat memory buffer so they can be transmitted to the server. On the server side, some piece of the server would need to a) read this flattened parameter data, b) recreate the stack in the server address space such that it is a replication of the original stack set by the caller, c) invoke the actual call on the server side, d) pack the return values, and e) send it back to the client.
The process of serializing parameters from the stack into a flat memory buffer is called marshaling. The process of reading the flattened parameter data and recreating the stack is called unmarshaling.
Developers, however, would like to focus on using interface pointers, and would rather not deal with marshaling and unmarshaling. We need some mechanism that would make the marshaling process transparent to the developers. The solution offered by COM is to intercept every method call a client makes and transfer the control into the server s address space. For such method remoting to work, when the client requests an interface pointer, handing over the real interface pointer would not work. A logical choice that COM made was to provide a proxy interface pointer to the client. This proxy pointer supports all the methods of the real interface, except now it gives COM the ability to intercept every method call on the interface and marshal the data.
Note that the code implementing the proxy interface has to be in-process with the client. Otherwise, you will need a proxy to a proxy, and so on.
On the server side, COM provides a similar mechanism to unmarshal the data and pass the control to the actual server method. The code that does this is referred to as the stub. Just like the proxy, the stub has to be in-process with the server implementation.
Marshaling is a nontrivial task, as parameters can be arbitrarily complex they can be pointers to arrays or pointers to structures. Structures can, in turn, contain arbitrary pointers and many other data structures. In order to successfully remote a method call with such complex parameters, the marshaling code has to traverse the entire pointer hierarchy of all parameters and retrieve all the data so that it can be reinstated in the server s address space. Clearly, writing marshaling code could easily defocus the developers from their main course of business.
Fortunately, COM provides a way to generate the marshaling logic based on the interface definition. Marshaling based on COM-generated logic is referred to as standard marshaling.
With standard marshaling, the method parameters are represented in a flat data buffer using a well-known data format called network data representation (NDR). The data format is specified by DCE RPC. It takes into account platform and architectural issues, and is very efficient in terms of performance.
By default, method remoting uses the COM Object RPC (ORPC) communication protocol. [2] The flow of method remoting is shown in Figure 2.1.
[2] ORPC is layered over MS-RPC, a DCE derivative.
Figure 2.1. Standard marshaling.
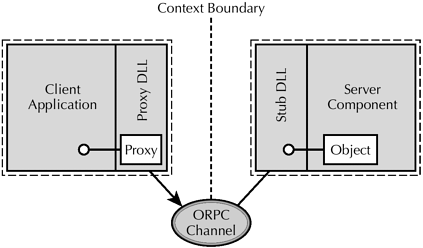
Figure 2.1 introduces a new term, context. As we will see in later chapters, marshaling is not just limited to process boundaries; marshaling is needed whenever an interface has to be intercepted. To clearly delineate when an interface needs interception, COM defined the term context. A context is a collection of objects that share run-time requirements. The run-time requirements that constitute a context will become clearer as we go through the next few chapters. Process boundary happens to be one such run-time requirement.
To generate the proxy/stub code that is needed for marshaling, each method parameter in an interface has to have at least one attribute that indicates if the parameter is being used for input, output, or both. This is done by attributes [in], [out], and [in, out], respectively. The following example shows their use:
void Divide([in] long numerator, [in] long denominator, [out] long* quotient, [out] long* remainder);
The above function definition indicates that the function Divide takes two parameters as input, the numerator and the denominator, and fills two parameters, the quotient and the remainder, as return values to the caller.
Marshaling architecture is really outside the scope of this book. We will cover it on a need-to-know basis. Those interested can read Al Major s book, COM IDL and Interface Design [Maj-99]. For the current discussion, it is important to know that we may have to define many attributes, besides [in] and [out], to assist the IDL compiler to generate efficient and, in some cases, necessary code.
Note that C++ does not provide any language constructs to specify the direction of method parameters.
Programming Language Independence
The software community always has a need to automate frequently-used functionalities of any application. Earlier versions of many commercial applications, such as Microsoft Excel and Microsoft Visual C++, had supported such automation by defining macro languages specific to each application. It was desired that a more general purpose, easy-to-use language be used for automation. The ease of use of BASIC language spawned many development environments such as Microsoft Visual Basic (VB) and Microsoft VBScript, a general purpose scripting language that is used by applications such as Microsoft Internet Explorer and Microsoft Windows Scripting Host (WSH). What was needed was an application that desires its functionality to be automated to somehow expose the functionality to other applications. This was a lofty goal, considering that the manipulator application could be based on a programming language different than the manipulatee application, and that the data types in one language need not necessarily map to a data type in another language.
COM addressed this cross-language issue and provided a way that makes it possible for one application to manipulate objects implemented in another application, irrespective of the programming language used, or to expose objects so they can be manipulated. This technology is referred to as automation (formally known as OLE automation).
An automation client is an application that can manipulate exposed objects belonging to another application. An automation client is also called an automation controller.
An automation server, sometimes referred to as an automation component, is an application that exposes programmable objects to other applications. The exposed objects are also called automation objects.
Based on COM support for automation, a slew of new technologies called Active (formerly called ActiveX) technologies were born. Some examples are Active documents, ActiveX controls, and ActiveX scripting.
Although, theoretically, it is possible to use a COM component in any programming language, the main languages of interest in the programming community have been Visual Basic (VB), Java, and ActiveX scripting languages such as VBScript and JScript.
Semantic Information
The binary form representation of the interface definition is sufficient to satisfy the development environment in terms of checking the syntax and producing appropriate machine language code to make a method call. However, quite often it is necessary to provide helpful hints to the developers on what the interface is about and when to use a specific method. Under C++ language, this is achieved by adding comments in the header file.
Though C++-style comments can be specified in an IDL file, IDL supports a formal attribute called helpstring that can be used to describe an interface, the methods in the interface, and many other constructs that we will cover later in this chapter. The following text fragment taken from a Microsoft-supplied IDL file for Web Event Browser ActiveX control shows the usage of the helpstring attribute:
[ uuid(EAB22AC1-30C1-11CF-A7EB-0000C05BAE0B), helpstring("Web Browser interface"), ... ] interface IWebBrowser : IDispatch { [ id(100), helpstring("Navigates to the previous item in the history list."), helpcontext(0x0000) ] HRESULT GoBack(); [ id(101), helpstring("Navigates to the next item in the history list."), helpcontext(0x0000) ] HRESULT GoForward(); [ id(102), helpstring("Go home/start page.") helpcontext(0x0000) ] HRESULT GoHome(); ... } Note that IDL will honor C/C++-style comments. However, such comments get stripped out when the IDL compiler processes the IDL file, as we will see later.
Standardized Calling Conventions
In the previous chapter we discovered that in order to ensure a smooth interoperability between two C++ components, certain aspects of C++ language have to be treated uniformly. For your convenience, some of the important aspects are listed once again:
-
Run-time representation of basic data types should be uniform
-
Run-time representation of composite data type should be uniform
-
Argument passing order should be uniform
-
Argument passing convention should be uniform
-
Stack-maintenance responsibility should be uniform
-
Implementation of virtual functions should be uniform
These conditions hold true for the interface definitions as well. After all, an interface definition is nothing but a decorated C++ class. However, COM goes a step further. It specifies the precise standards to follow in defining and using the interfaces.
In view of COM s ability to interoperate between various architectures, platforms, and programming languages, some of these standards deserve special attention.
Return Value From a Function
Except in special circumstances, nearly every interface member method (and almost all COM API functions) returns a value of type HRESULT. HRESULT is a 32-bit integer. Its structure is shown in Figure 2.2.
Figure 2.2. Structure of HRESULT.

The severity bit indicates the success or failure of the operation. The SDK header file defines the bit as SEVERITY_SUCCESS (value 0) and SEVERITY_ERROR (value 1). The SDK also defines two macros, SUCCEEDED and FAILED, to check the HRESULT for this bit. The following code shows their usage:
HRESULT hr = Some_COM_API(); If (SUCCEEDED(hr)) { DoSomething(); } ... if (FAILED(hr)) { ReportFailure(); } ...
 | There are many possible reasons for an interface method call or COM API calls to fail, even though the reasons are not evident sometimes. Therefore, always use SUCCEEDED or FAILED macros to check the return status of the interface method or COM API call. |
As there are many possible success and error codes, the SDK follows a naming convention for different codes. Any code with an E_ in it, either at the beginning or in the middle, implies that the function failed. Likewise, any name with an S_ in it, either at the beginning or in the middle, implies the function succeeded. Some examples of error codes are E_OUTOFMEMORY and CO_E_BAD_SERVER_NAME. Some examples of success codes are S_OK and CO_S_NOTALLINTERFACES.
The reserved bits are reserved for the future and are not currently used.
The facility code indicates which COM technology the HRESULT corresponds to, and the information code describes the precise result within the facility. Table 2.1 shows some pre-defined facility codes.
| Code | Facility |
|---|---|
| 0x000 | FACILITY_NULL |
| 0x001 | FACILITY_RPC |
| 0x002 | FACILITY_DISPATCH |
| 0x003 | FACILITY_STORAGE |
| 0x004 | FACILITY_ITF |
| 0x005 | Not defined |
| 0x006 | Not defined |
| 0x007 | FACILITY_WIN32 |
| 0x008 | FACILITY_WINDOWS |
| 0x009 | FACILITY_SSPI |
| 0x00A | FACILITY_CONTROL |
| 0x00B | FACILITY_CERT |
| 0x00C | FACILITY_INTERNET |
| 0x00D | FACILITY_MEDIASERVER |
| 0x00E | FACILITY_MSMQ |
| 0x00F | FACILITY_SETUPAPI |
Most facility codes have a self-explanatory name and are well documented in SDK. For our current discussion, FACILITY_NULL and FACILITY_ITF deserve special attention.
Any HRESULT that is universal and is not tied to a particular technology belongs to FACILTY_NULL. Table 2.2 shows some commonly seen HRESULTs from this facility.
| HRESULT | Description |
|---|---|
| S_OK | Function succeeded |
| S_FALSE | Function succeeded but semantically returns a boolean FALSE |
| E_OUTOFMEMORY | Function failed to allocate enough memory |
| E_NOTIMPL | Function not implemented |
| E_INVALIDARG | One or more arguments are invalid |
| E_FAIL | Unspecified error |
FACILITY_ITF is used to define interface-specific errors as well as user-defined errors. The SDK header files define interface-specific HRESULT s up to the information code value of 0x1FF. However, a developer can use any information code value above 0x200 to compose a custom HRESULT. The SDK provides a macro called MAKE_HRESULT to accomplish this. Its usage is shown in the following code snippet:
const HRESULT MYDATA_E_QUERYERROR = MAKE_HRESULT(SEVERITY_ERROR, FACILITY_ITF, 0x200+1);
Note that the information code need only be unique within the context of a particular interface. Thus, one interface s custom HRESULT s may overlap with another.
| | Use FACILITY_ITF and MAKE_HRESULT to define your own HRESULT. Use a value above 0x200 for the information code. |
Most valid HRESULT s have a text-based human readable description stored in the system message table. Win32 API FormatMessage can be used to obtain this description. The following code fragment shows how to obtain a description for a given HRESULT.
void DumpError(HRESULT hr) { LPTSTR pszErrorDesc = NULL; DWORD dwCount = ::FormatMessage( FORMAT_MESSAGE_ALLOCATE_BUFFER | FORMAT_MESSAGE_FROM_SYSTEM, NULL, hr, MAKELANGID(LANG_NEUTRAL, SUBLANG_DEFAULT), reinterpret_cast<LPTSTR>(&pszErrorDesc), 0, NULL); if (0 == dwCount) { cout << "Unknown HRESULT: " << hex << hr << endl; return; } cout << pszErrorDesc << endl; LocalFree(pszErrorDesc); }
 | HRESULT s that use FACILITY_ITF and have the information code above 0x200 are user-defined HRESULT s and obiviously cannot be obtained from the system. |
Visual C++ native support for COM defines a class, _com_error, that makes it easy to obtain the error description. Using this class function, DumpError, for example, can be redefined as follows:
void DumpError2(HRESULT hr) { cout << _com_error(hr).ErrorMessage() << endl; } Visual C++ ships with a utility called ERRLOOK.EXE that can also be used to look up the description of an HRESULT.
| | To obtain the description for an HRESULT-type variable while debugging an application, specify hr as the display option in the watch window (as shown below) for a variable hMyResult. hMyResult, hr |
Stack Frame Setup
In order to produce a COM-compliant stack frame for any COM-related function call, the SDK defines a macro called STDMETHODCALLTYPE. Under Visual C++, this macro expands to _stdcall when targeting Win32 platforms. The implications of this compiler directive were explained in Chapter 1 (Table 1.1).
Almost all COM API functions and nearly every interface member method use this macro as their call type. The following code example shows its usage:
HRESULT STDAPICALLTYPE MyFictitousComFunction();
The SDK defines all the COM APIs as external C functions (keyword extern "C") . The SDK also defines a macro for extern "C" as EXTERN_C. In fact, EXTERN_C HRESULT STDAPICALLTYPE is so commonly used for COM functions that the SDK combines them under one macro STDAPI.
#define STDAPI EXTERN_C HRESULT STDAPICALLTYPE
For Win32 compatibility, the SDK also defines another macro, WINOLEAPI, that maps to STDAPI.
#define WINOLEAPI STDAPI
The following is an example of a COM API called CoInitialize that uses WINOLEAPI.
WINOLEAPI CoInitialize(LPVOID pvReserved);
For COM functions whose return types are something other than HRESULT, the SDK defines another macro, STDAPI_(type), and its WINOLEAPI equivalent, WINOLEAPI_(type).
#define STDAPI_(type) EXTERN_C type STDAPICALLTYPE #define WINOLEAPI_(type) STDAPI_(type)
As an example, the prototype for a frequently used COM API, CoUnitialize, is shown below:
WINOLEAPI_(void) CoUninitialize(void);
This basically expands to:
extern "C" void _stdcall CoUninitialize(void);
Interface methods are a little different than COM API functions in the sense that they are not EXTERN_C type and that they all need to be marked as virtual. To indicate a function as an interface method, the SDK defines a macro called STDMETHOD that takes the method name as the parameter, as shown in the following example:
STDMETHOD(MyXYZMethod)();
This statement expands to:
virtual HRESULT STDMETHODCALLTYPE MyXYZMethod();
Under Win32, this expands to:
virtual HRESULT _stdcall MyXYZMethod();
The declaration used in the implementation of this method is slightly different than that of the prototype, as C++ requires that the keyword virtual be dropped in the implementation.
// method implemented by a class CMyClass HRESULT _stdcall CMyClass::MyXYZMethod() { ... } For the developers convenience, the SDK defines a macro called STDMETHODIMP that can be used in the implementation code, as shown below:
STDMETHODIMP CMyClass::MyXYZMethod() { ... } What about defining those interface methods whose return types are something other than HRESULT? The SDK defines a variation of the STDMETHOD macro that takes the return type as an extra parameter:
#define STDMETHOD_(type, method) \ virtual type STDMETHODCALLTYPE method
The following code shows its usage for an interface method, AddRef:
STDMETHOD_(ULONG, AddRef)();
Under Win32, this essentially expands to:
virtual ULONG _stdcall AddRef();
The developers can avail another macro, STDMETHODIMP_(type), for the implementation of the above method. The following code snippet illustrates its usage for implementing CMyClass::AddRef:
STDMETHODIMP_(ULONG) CMyClass::AddRef() { ... } Table 2.3 summarizes the usage of these macros for declaring interface methods.
| Return Type | Method Definition or Implementation | Usage |
|---|---|---|
| HRESULT | Definition | STDMETHOD |
|
| Implementation | STDMETHODIMP |
| Other than HRESULT | Definition | STDMETHOD_(type) |
|
| Implementation | STDMETHODIMP_(type) |
Memory Management
Consider the following C++-based caller/callee scenario. The callee implements a method, GetList, that returns an array of numbers. The implementation allocates the appropriate amount of memory for this operation as shown below:
void CMyImpl::GetList(long** ppRetVal) { *ppRetVal = new long[m_nSize]; // allocate memory as a long // array of size m_nSize // fill the array ... return; } Under this setup, when a caller invokes method GetList, it is the caller s responsibility to free the allocated memory.
long* aNumbers; pImpl->GetList(&aNumbers); // use aNumbers ... delete [] aNumbers; // deallocate memory allocated by the callee
The above technique of memory allocation (by the callee) and deallocation (by the caller) works fine under the standard programming model. However, this same technique under COM has a few problems:
-
The semantics of new and delete are not standardized across various compilers and programming languages. Consequently, the results of memory deallocation in the client code are unpredictable.
-
A more challenging problem arises when the client and the server are running as two different processes. Separate processes do not share their address space with each other. Consequently, the memory allocated using the operator new (or any of its variants such as malloc, LocalAlloc, etc.) does not get reflected in the client address space.
In order to make such memory allocation and deallocation work between the client and the server, there must be a standard mechanism accessible to both parties to deal with memory management, even across process/machine boundaries. This mechanism is COM s task memory allocation service. All the COM components are required to use this service whenever there is a need to exchange allocated memory between them.
The SDK provides two APIs, CoTaskMemAlloc and CoTaskMemFree, to allocate and free memory, respectively. The syntax for these functions is shown below:
// Prototype WINOLEAPI_(LPVOID) CoTaskMemAlloc(ULONG cb); WINOLEAPI_(VOID) CoTaskMemFree(void* pv);
Using these APIs, the previous code for caller/callee can be redefined as follows:
// Callee void CMyImpl::GetList(long** ppRetVal) { *ppRetVal = reinterpret_cast<long*> (CoTaskMemAlloc(nSize * sizeof(long)); // fill the array return; } // Caller long* aNumbers; pImpl->GetList(&aNumbers); // use aNumbers CoTaskMemFree(aNumbers); // deallocate memory allocated by // the callee APIs CoTaskMemAlloc and CoTaskMemFree go through the COM task memory allocator, a thread-safe implementation of memory allocator implemented by COM.
Identification
An interface class requires a human-readable name to identify it. This creates an interesting problem when two different interfaces (possibly from different vendors) share the same interface name. Consider the following scenario: two vendors decide to create a spell-checker component. Both vendors define their respective spell-checking interfaces. Both interface definitions will probably be similar in functionality, but in all likelihood the actual order of the method definitions and perhaps the method signatures will be somewhat different. However, both vendors will most likely use the same logical interface name, ISpellCheck.
If the client uses such a name-based mechanism to obtain an interface, it has the potential to accidentally connect to the wrong component, thereby obtaining the vptr to the wrong interface. This will inevitably result in an error or a crash, even though the component had no bugs and worked as designed.
Different vendors in different places develop components and interfaces at different times. There is no central authority that mediates issuing a unique interface name among all the vendors. Under such circumstances, how can one possibly guarantee a unique identification to each interface? COM s answer is GUID.
Globally Unique Identifiers (GUIDs)
A GUID (pronounced goo-id) is a 128-bit integer that is virtually guaranteed to be unique across space and time. This integer can be assigned to any element of COM that requires a unique identity. For each type of COM element, the GUID is referred to by a more appropriate term. Table 2.4 shows some elements of COM that require unique identification.
| Element | Referred to as |
|---|---|
| Interface | Interface ID (IID) |
| COM Class | Class ID (CLSID) |
| Category | Category ID (CATID) |
| Application | Application ID (APPID) |
| Data Format | Format ID (FMTID) |
A GUID has the following data structure:
typedef struct _GUID { DWORD Data1; WORD Data2; WORD Data3; BYTE Data4[8]; } GUID; All other forms of GUIDs are just a typedef representation of this structure, as shown below:
typedef GUID IID; typedef GUID CLSID; ...
The SDK provides a macro called DEFINE_GUID to fill this structure with values. The following example defines the GUID for our interface, Ivideo:
DEFINE_GUID(IID_IVideo, 0x3e44bd0, 0xcdff, 0x11d2, 0xaf, 0x6e, 0x0, 0x60, 0x8, 0x2, 0xfd, 0xbb);
This basically maps to:
extern "C" const GUID IID_IVideo = { 0x3e44bd0, 0xcdff, 0x11d2, { 0xaf, 0x6e, 0x0, 0x60, 0x8, 0x2, 0xfd, 0xbb } }; A GUID can also be represented as a string in a format dictated by the OSF DCE. The following example shows the string representation of our IVideo interface. Note that the curly braces and the hyphens are all part of the standard.
{03E44BD0-CDFF-11d2-AF6E-00600802FDBB} The SDK provides an API called CoCreateGUID to generate a GUID. This API employs an algorithm that originated from OSF DCE. To guarantee uniqueness with a very high degree of certainty, the algorithm uses, among other things, the current date/time and globally unique network card identifier. If the network card is not present, the algorithm still synthesizes an identifier from a highly variable state of the machine.
Most development environments include an application called GUIDGEN.EXE that can be used to generate one or more GUIDs and paste them in the source code.
Compiled Type Information
Entering interface information in an ASCII file is very convenient. You can use your favorite text editor to edit the IDL file. However, developing code using an IDL file as a direct source is not practical. It requires that the IDL file be parsed. Unfortunately, parsing is subject to interpretation. Each language may interpret the information in a slightly different way, which may cause the client-server interaction to break down.
There is also a more fundamental issue. COM is supposed to be a binary standard for interoperatibility. The actual interface should really be defined in terms of binary memory layouts and method calls, and not as a text file.
It makes sense to provide the interface information in a binary form a form that is free from any ambiguities or misinterpretations and one that is truly interoperable in the context of multiple architectures and OS platforms.
Under COM, such a binary form of the interface definition is called a type library. A type library is a binary file that contains tokenized interface information, obtained directly from the source IDL file, in an efficiently parsed form. It allows COM-aware environments to produce language mappings for the interfaces defined in the original IDL file. It is the equivalent of a C++ header file, but for all COM-aware environments.
| | Strictly speaking, a type library is not a true representation of a source IDL file. Some information is lost during translation. Perhaps the COM task force will define a better binary representation in the future. Currently, a type library is the only binary representation of a source IDL file. |
Any interface information that needs to be saved into the type library needs to be defined in a section called library in the IDL file. As with interfaces, the library is uniquely identified by a GUID, though in this case, it is referred to as a Library ID or LIBID.
Component Identification
From the previous chapter we know that, under COM, clients deal only with interfaces. We also know that once a client has one interface pointer to an object, it could navigate through and get other appropriate interface pointers. Two questions arise:
-
How does the client uniquely identify a component in order to instantiate the object?
-
How does the client get the first interface pointer to the object?
The answer to the second question will be covered in chapter 3. Let s see how we can solve the first problem.
In order to help a COM client identify a component, an abstract term called COM class has been coined. A COM class, or coclass, is a named declaration that represents concrete instantiable type and the potential list of interfaces it exposes. Like interfaces, a COM class requires unique identification. Associating a GUID to the class does this, though in this case it is referred to as a Class ID, or CLSID.
| < BACK NEXT > |
EAN: N/A
Pages: 129