Section 4.2. Using Spring JDBC Templates
|
|
4.2. Using Spring JDBC TemplatesAlthough persistence frameworks like EJB container-managed persistence, JDO, and Hibernate have attracted fans at various times, JDBC remains the bread-and-butter of database development with Java. You can write it all yourself, or you can use some frameworks to help manage the details. Spring lets you do JDBC development in a variety of ways. In this example, you'll use JDBC templates. If Spring offered nothing more than a little configuration, a smattering of user interface development, and a slightly different programming model, then this book would be done, but Spring offers much more, including tremendous advantages over roll-your-own JDBC:
In short, you'll write less code, and build programs that are easier to maintain and read. You'll let Spring, instead of tedious, handwritten code do the heavy lifting. 4.2.1. How do I do that?Spring uses a concept called templates. You'll pass each template an SQL query, and a method that will process each row in a result set. Normally, that code, in an inner class, will map the results from a query onto objects. Spring will do the rest. You'll put the template code into an implementation of our façade layer. Since you've already got an interface, a test implementation and the object model for the application, you'll create the JDBC implementation, which extends a Spring-provided class called JdbcDaoSupport that makes life easier (Example 4-6). Example 4-6. JDBCRentABike.javapublic class JDBCRentABike extends JdbcDaoSupport implements RentABike { private String storeName; private static final int MANUFACTURER = 2; private static final int MODEL = 3; private static final int FRAME = 4; private static final int SERIALNO = 5; private static final int WEIGHT = 6; private static final int STATUS = 7; public List getBikes( ) { final ArrayList results = new ArrayList( ); JdbcTemplate template = getJdbcTemplate( ); template.query("SELECT * FROM bikes", new RowCallbackHandler( ) { public void processRow(ResultSet rs) throws SQLException { Bike bike = new Bike(rs.getString(MANUFACTURER), rs.getString(MODEL), rs.getInt(FRAME), rs.getString(SERIALNO), rs.getDouble(WEIGHT), rs.getString(STATUS)); results.add(bike); } }); return results; } public Bike getBike(String serialNo) { final Bike bike = new Bike( ); JdbcTemplate template = getJdbcTemplate( ); template.query("SELECT * FROM bikes WHERE bikes.serialNo = '" + serialNo + "'", new RowCallbackHandler( ) { public void processRow(ResultSet rs) throws SQLException { bike.setManufacturer(rs.getString(MANUFACTURER)); bike.setModel(rs.getString(MODEL)); bike.setFrame(rs.getInt(FRAME)); bike.setSerialNo(rs.getString(SERIALNO)); bike.setWeight(rs.getDouble(WEIGHT)); bike.setStatus(rs.getString(STATUS)); } }); return bike; } //etc...This may look a bit muddy, until you compare it to a traditional JDBC method. The inner class syntax is a little awkward, but you'll learn it quickly. Next, add the data source and the JDBC connection to the context. Also, we need to point the application to the new façade implementation (Example 4-7). Example 4-7. RentABikeApp-Servlet.xml<bean > <property name="driverClassName"> <value>com.mysql.jdbc.Driver</value> </property> <property name="url"> <value>jdbc:mysql://localhost/bikestore</value> </property> <property name="username"><value>bikestore</value></property> </bean> <bean > <property name="storeName"><value>Bruce's Bikes</value></property> <property name="dataSource"><ref bean="dataSource"/></property> </bean> Don't forget to wrap any calls to the JdbcTemplate in appropriate error handling. Any time you invoke your own or somebody else's code to access a database, things can go wrong (failed connection, invalid permissions, locked data, etc.). You should have a plan for dealing with these kinds of exceptions and treat any call to the JdbcTemplate as a potential for failure. 4.2.2. What just happened?For the code that sits above the façade, you're not seeing much of a difference between the test version and the database version. That's the beauty of the test façade that you built early in Chapter 1. However, now multiple applications can share the database, and it will retain changes between invocations, just as you'd expect. In the façade, we used a JDBC template. We provide three pieces of data to the JDBC template:
Notice that all of the code that we specify is necessary. These are the things that change from one JDBC invocation to the next. Instead of specifying the control structures (like a while loop) to iterate through the result set, we hand control to Spring. It then does the grunt work:
But what happened is not nearly as important as how it happened. Go back and read the code in the façade once again. Think again about all of the things that Spring does for us:
Figure 4-1 shows the work that nearly all JDBC programs must do. The blocks in grey show the operations that Spring handles for you. You've got to do the rest yourself. Figure 4-1. JDBC requires all of these operations, but Spring handles the ones in grey automatically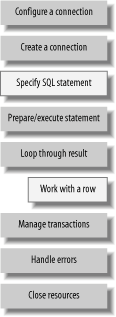 4.2.3. What about......persistence frameworks? We introduce a few in the next chapter. With the advent of Hibernate and the resurgence of JDO, you might be convinced that there's never any reason to use JDBC, but remember, you don't need a flamethrower to swat a fly. Like that flamethrower in the living room, your persistence framework may have some unintended consequences. If you've got a flyweight problem, grab a flyswatter. On the other hand, the previous code tied the object fields to specific database datatypes. If a developer is supporting both Oracle and MySql, and a field might grow longer than Oracle's VARCHAR will handle, it must be defined as a CLOB. JDBC's CLOB handling does not match VARCHAR handling at all. MySQL doesn't present this problem. You'd either need to handle the difference yourself, or reach for a more robust persistence solution. |
|
|
EAN: 2147483647
Pages: 90