Using Fault Detection and Recovery Tools
| I l @ ve RuBoard |
| This section provides a sampling of tools for database fault management. By knowing the processes that are critical to the database, you can do some basic fault monitoring. You can set up scripts to do ps and parse the output, to ensure that the processes you care about are still active. More sophisticated application monitoring can be done with Compuware's EcoSNAP, which can detect application failures and report problems, with diagnostic information included. The rest of this section describes tools that are specifically for databases. MC/ServiceGuardMC/ServiceGuard is a high availability product from Hewlett-Packard that is used to protect your critical applications and servers. MC/ServiceGuard is most commonly used in a multisystem or clustered environment. The MC/ServiceGuard software on each system monitors the other systems in the cluster. MC/ServiceGuard can detect the failure of systems, networks, and applications. For example, if a LAN card fails, MC/ServiceGuard transparently recovers from the failure by activating a standby LAN card. After deciding which applications need to be protected, you configure them as packages, using MC/ServiceGuard commands or the GUI accessible from SAM. Several attributes of the application need to be defined, such as the following:
MC/ServiceGuard monitors these services and dependencies. If a failure occurs, the package is either restarted locally or moved and restarted on another system. Similarly, when a system failure occurs, MC/ServiceGuard software can detect the problem and automatically restart critical applications on an alternate node. MC/ServiceGuard software detects a variety of error conditions, but does not have a sophisticated notification mechanism for customers to learn what happened. Errors often are written to the system log file (/var/adm/syslog/syslog.log) or to application-specific logs, which helps to retrace what happened . Because MC/ServiceGuard can automatically move applications to other systems, it may be difficult for you to know the current status of an application. MC/ServiceGuard commands, such as cmviewcl, can tell you the current state of a cluster and its packages. This information is also contained in the MC/ServiceGuard MIB. To learn why a package has failed, check the system log file on each system in the cluster for specific MC/ServiceGuard messages. MC/ServiceGuard can provide some level of protection for database availability by encapsulating the database application into a package. Redundant hardware components can help to ensure that the database survives some failure scenarios. Some failures may require the database to be restarted, but this can be handled automatically by MC/ServiceGuard. In response to a catastrophic system failure, MC/ServiceGuard can restart the database on another system. MC/ServiceGuard is a general-purpose tool, and its only database-specific knowledge comes from the user -configured package definition. MC/ServiceGuard provides database templates to make this configuration easier, but this enables it to monitor only that database processes are alive . You may also want to monitor the status of database tables and check for potential deadlock situations. This requires the use of other tools, which are not integrated with the MC/ServiceGuard product. No changes to the database application need to be made for MC/ServiceGuard to monitor the application. The MC/LockManager product is modeled after MC/ServiceGuard and provides support for concurrent database access to Oracle databases by using Oracle Parallel Server. This cluster solution can provide continuous access to the database despite the loss of a server. MC/LockManager relies on the generic monitoring capabilities of MC/ServiceGuard, and also monitors the Distributed Lock Manager. MC/ServiceGuard provides help for database fault management only. It does not help you to manage database resources and performance, and provides no help for monitoring service response time to detect performance issues or uncover trends that could lead to problems. Note that MC/ServiceGuard is supported only on HP 9000 Series 800 systems running HP-UX 10. x or later operating systems. Similar high availability cluster products are available for other platforms, such as Solstice HA for Sun Solaris environments. ClusterViewClusterView is an HP OpenView application that can be used to monitor MC/ServiceGuard or MC/LockManager clusters. ClusterView presents windows for each high availability cluster in a company's environment. In each window, you can see the status of packages and the systems on which applications are running. ClusterView can show database servers and their status, if they are configured as MC/ServiceGuard packages. EMS HA MonitorsThe Event Monitoring Service (EMS) is a free set of monitoring functions for HP-UX systems. In addition to free library routines for creating your own monitors, EMS provides a set of free monitors when you purchase a system. These include hardware diagnostic monitors. More sophisticated monitors are provided with the EMS HA Monitors product, which includes a disk monitor and a database monitor, as well as other monitors. The database monitor included in the EMS HA Monitors product currently supports only Oracle environments. Both database and database server information is provided. One set of database resources is provided for each configured database (see Table 8-3), and one set of database server resources is provided for each active database server (see Table 8-4). The EMS Database Monitor can detect changes in the state of a database, and can send events before the database runs out of critical database resources. With this monitor, MC/ServiceGuard can detect a database problem before failure and start recovery actions sooner, such as restarting a package on an alternate node. The status field can be used to determine whether the database is functioning properly. The other fields in the table provide information on the amount of disk space available for the database. As mentioned earlier, process information obtained from ps or other commands can indicate whether a database instance is running or has failed. Status information obtained from EMS can give more detailed information, such as whether the server is congested or whether the transaction rate is below an acceptable value. The EMS database monitor is focused on fault management, although it does provide some performance information, such as the transaction rate for each database server. Table 8-3. EMS Database Resources
Table 8-4. EMS Database Server Resources
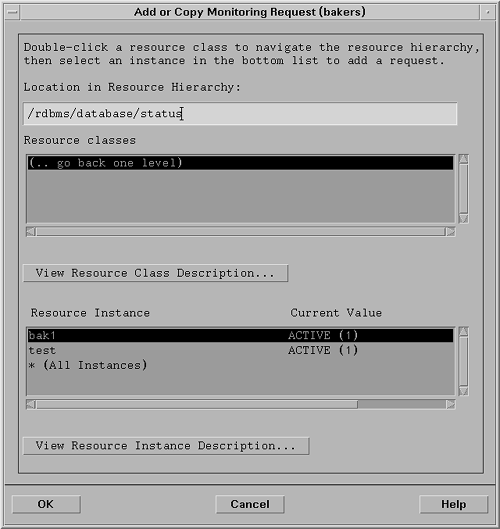
All EMS monitors support a variety of notification methods , including SNMP, e-mail, TCP or UDP messages, or writing to an arbitrary log file. EMS monitors can also notify MC/ServiceGuard directly of an event, so that appropriate recovery actions can be initiated immediately. EMS also allows for different operators to receive different events or use different notification criteria. This information is configured using the EMS configuration GUI, which is part of SAM. Thus, a system operator can get basic status information, while a database administrator receives more detailed performance alarms. Figure 8-1 shows the EMS GUI screen for adding monitoring of database status for the bak1 database instance. The status of bak1 is ACTIVE. The resource name for this resource is /rdbms/database/status/bak1. Figure 8-1. Using the EMS GUI to configure database status monitoring. |
| I l @ ve RuBoard |
EAN: 2147483647
Pages: 90
- Integration Strategies and Tactics for Information Technology Governance
- A View on Knowledge Management: Utilizing a Balanced Scorecard Methodology for Analyzing Knowledge Metrics
- Technical Issues Related to IT Governance Tactics: Product Metrics, Measurements and Process Control
- Governance in IT Outsourcing Partnerships
- Governance Structures for IT in the Health Care Industry