Joining in DB2 UDB
| In the previous version of DB2, the DB2 optimizer would normally choose between two different join methods : a nested loop join and a merge join. However, in DB2 Version 7, when the DB2_HASH_JOIN registry variable was set to YES, the optimizer was also able to consider using a hash join when optimizing the access plan. Because hash joins can significantly improve the performance of certain queries, especially in DSS environments where the queries are normally quite large and complex, hash joins are always available in DB2 UDB Version 8 but are considered only when the optimization level is five or higher. NOTE To disable the optimizer from considering hash joins, set the DB2_HASH_JOIN registry variable to NO. Join MethodsWhen joining two tables, no matter which join method is being used, one table will be selected to be the outer table, and the other table will be the inner table. The optimizer decides which will be the outer table and which will be the inner table based on the calculated cost and the join method selected. The outer table will be accessed first and will be scanned only once. The inner table may be scanned multiple times, depending on the type of join and the indexes that are present on the tables. It is also important to remember that, even though an SQL statement may join more than two tables, the optimizer will join only two tables at a time and keep the intermediate results if necessary. Nested Loop JoinWhen performing a nested loop join, for each qualifying row in the outer table, there are two methods that can be used to find the matching rows in the inner table (Figure 6.1).
Figure 6.1. Nested loop join. In nested loop joins, the decision of which is the outer table and which is the inner table is very important because the outer table is scanned only once, and the inner table is accessed once for every qualifying row in the outer table. The optimizer uses a cost-based model to decide which table will play which role in the join. Some of the factors taken into account by the optimizer when making this decision include:
NOTE The joined columns cannot be Long Varchar or LOB columns . Merge JoinMerge joins (Figure 6.2) require that the SQL statement contain an equality join predicate (i.e., a predicate of the form table1.column = table2.column). A merge scan join also requires that the input tables be sorted on the joined columns. This can be achieved by scanning an existing index or by sorting the tables before proceeding with the join. Figure 6.2. A merge join. With a merge join, both of the joined tables will be scanned at the same time, looking for matching rows. In a merge join, both the outer and inner tables will be scanned only once unless there are duplicate values in the outer table, in which case, some parts of the inner table may be scanned again for each duplicated value. Because the tables are generally scanned only once, the decision on which is the outer and which is the inner table is somewhat less important than with a nested loop join; however, because of the possibility of duplicate values, the optimizer will attempt to choose the table with fewer duplicate values as the outer table. NOTE The joined columns cannot be Long Varchar or LOB columns. Hash JoinHash joins require one or more equality join predicates between the joined tables, in which the data types for each of the joined columns must be the same. In the case of CHAR data types, even the length of the column must be the same. In the case of DECIMAL data types, the precision and scale must be the same. The fact that hash joins can handle more than one equality predicate between the joined tables is a distinct advantage over merge joins, which can handle only one equality predicate. For hash joins, the inner table (also known as the build table ) is scanned first, and the qualifying rows are copied into memory buffers. These buffers are divided into partitions based on a hash code computed from the column(s) in the join predicate(s). If there is not enough space in memory to hold the entire build table, some partitions will be written into temporary tables. Then the outer table (also known as the probe table ) is scanned. For each row in the probe table, the same hashing algorithm is applied to the join column(s). If the hash code obtained matches the hash code of a row in the build table, the actual values in the join columns will be compared. If the partition that matches the probe table row is in memory, the comparison can take place immediately. If the partition was written to a temporary table, the probe row will also be written into a temporary table. Finally, the temporary tables containing rows from the same partitions are processed to match the rows. Because of the advantages of keeping the build table in memory, the optimizer will normally choose the smaller table as the build table to avoid having to create a temporary table. If intra-partition parallelism is enabled, the hash join may be executed in parallel. When a hash join is executed in parallel, the build table is dynamically partitioned into multiple parallel tuple streams, and each stream is processed by a separate task to enter the build tuples into memory. At the end of processing the build table streams, the hash join process adjusts the contents of memory and performs any needed movement of partitions into or out of memory. Next , multiple parallel tuple streams of the probe table are processed against the in-memory partitions and may be spilled for any tuples from hash join partitions that were spilled to temporary tables. Finally, the spilled partitions are processed in parallel, with each task processing one or more of the spilled partitions. Which Join Method to Use?The previous sections have described the different join methods available in DB2 UDB, and based on these discussions, it appears that certain join methods seem to be a better choice than others. For example, merge joins have the advantage of scanning the tables only once when compared with nested loop joins that scan the inner table for every row of the outer table. At first glance, a merge join seems to be a better choice; however, if the correct index exists on the outer table, a nested loop join can end up being a better choice. Similarly, at first glance, a hash join seems to be a better choice than a merge scan join because it does not need to sort the input tables before executing. If the order of the rows in the outer table needs to be preserved, a merge join or nested loop join might be a better choice because a hash join cannot guarantee ordering of the output; it may need to spill to disk, which would disrupt the ordering of the rows. The $10,000 question then is, How does the DB2 UDB optimizer decide which join method to use for a particular join? First, the optimizer must take into account the types of the predicates in the SQL query. After examining the join predicates and the current optimization level, one or more of the join methods may be eliminated. Once the optimizer has determined which of the join methods are possible, it will decide which join method to use based on the calculated costs of the available join methods. The optimization level is a database configuration parameter that specifies the amount of optimization to be done for any given SQL statement. The higher the optimization level, the more potential access plans that will be examined in search of the best (i.e., lowest cost) access plan. In DB2 UDB Version 8, the optimization level can be: 0, 1, 2, 3, 5, 7, or 9. Not all join methods are available at all optimization levels.
How to Tune and Monitor Hash JoinsHash joins can significantly improve the performance of certain queries, especially in Decision Support Systems (DSS) that have complex queries. One of the performance advantages that hash join has over merge join is that it does not require any sorts beforehand, which could be very costly. The key for hash join is to be able to fit all (or as many as possible) rows of the build table into memory without having to spill to disk. The memory used for these buffers comes from the database sort heap, so the tuning of the SORTHEAP, SHEAPTHRES, and SHEAPTHRES_SHR configuration parameters is very important. As discussed previously, SORTHEAP is a database configurable parameter that defines the maximum amount of memory that could be used for a sort or for a hash join. Each sort or hash join has a separate SORTHEAP that is allocated as needed by the database manager. Not necessarily all sorts and hash joins allocate this amount of memory; a smaller SORTHEAP could be allocated if not all the memory is needed. SORTHEAP can be allocated from shared or private memory, depending on the requirements of the operation. A shared SORTHEAP is used only for intra-parallel queries where degree > 1; a private SORTHEAP is used when only one agent will perform the sort or hash join and there is no need to share the memory with other agents . A single query might have more than one hash join, and/or sort and multiple SORTHEAPs may be required and allocated at the same time, depending on the nature of the plan. For private sorts or hash joins, SHEAPTHRES acts as an instance-wide soft limit on the total amount of memory that all concurrent private sorts can consume . When this consumption reaches the limit, the memory allocated for additional incoming SORTHEAP requests will be reduced significantly. For shared sorts or hash joins, SHEAPTHRES_SHR acts as an instance-wide hard limit on the total amount of memory that all shared sorts can consume. When this consumption gets close to the limit, the memory allocated for additional incoming SORTHEAP requests will be reduced significantly, and eventually no more shared sort memory requests will be allowed. In uniprocessor systems, hash join uses only private SORTHEAPs. In SMP systems (with intra-parallel = ON and dft_degree > 1), hash join uses shared SORTHEAPs for the first part of the operation and private SORTHEAPs for the last phase. For more information on these parameters, see the Administration Guide: Performance that comes with DB2 UDB. How do we tune these parameters? As in most tuning exercises, you need to have a starting point: a baseline benchmark, by defining a workload to test and using the appropriate tools to measure the test results. After that, it is an iterative process of changing one parameter at a time and measuring again. In most cases, you would already have values set for SORTHEAP and SHEAPTHRES in your existing system, so we suggest that you start with what your current settings are. If you have a brand new installation, you can follow the rules of thumb for DSS systems, which are to allocate 50% of the usable memory to buffer pools and the other 50% for SHEAPTHRES. Then make your SORTHEAP equal to the SHEAPTHRES divided by the number of complex concurrent queries that would be executing at one time, multiplied by the maximum number of concurrent sorts and hash joins that your average query has. (A good starting number for this is 5 or 6.) In summary: [View full width]
The number of "complex concurrent queries" is not equal to the number of "concurrent users" in a DB2 database. There are usually many more users than complex concurrent queries executing at a time. In most DSS TPC-H benchmarks, which try to push the databases to their limits, no more than 8 or 9 is used as the number of complex concurrent queries (a.k.a. streams ) for databases up to 10 TB, so start conservatively and move up as necessary. After determining the starting SORTHEAP, SHEAPTHRES, and SHEAPTHRES_SHR values, run an average workload and collect database and database manager snapshots. DB2 offers a number of monitor elements to be able to monitor hash joins. All hash join monitor elements are collected by default, so there is no need to enable any monitor switches. For details on enabling, capturing, and examining DB2 snapshots, refer to the System Monitor and Reference Guide . Below is a description of the database monitor elements that are related to hash joins. Total hash joinsThis monitor element counts the total number of hash joins executed. This value can be collected with a database or application snapshot. Hash join overflowsThis monitor element counts the total number of times that hash joins exceeded the available SORTHEAP while trying to put the rows of the build table in memory. This value can be collected with a database or application snapshot. Hash joins small overflowsThis monitor element counts the total number of times that hash joins exceeded the available SORTHEAP by less than 10% while trying to put the rows of the build table in memory. The presence of a small number of overflows suggests that increasing the database SORTHEAP may help performance. This value can be collected with a database or application snapshot. Total hash loopsThis monitor element counts the total number of times that a single partition of a hash join was larger than the available SORTHEAP. This value can be collected with a database or application snapshot. If DB2 cannot fit all of the rows of the build table in memory, certain partitions are spilled into temporary tables for later processing. When processing these temporary tables, DB2 attempts to load each of the build partitions into a SORTHEAP. Then the corresponding probe rows are read, and DB2 tries to match them with the build table. If DB2 cannot load some build partitions into a SORTHEAP, DB2 must resort to the hash loop algorithm. It is very important to monitor hash loops because hash loops indicate inefficient execution of hash joins and might be the cause of severe performance degradation. It might indicate that the SORTHEAP size is too small for the workload or, more likely, the SHEAPTHRES or SHEAPTHRES_SHR are too small, and the request for SORTHEAP memory could not be obtained. Hash join thresholdThis monitor element counts the total number of times that a hash join SORTHEAP request was limited due to concurrent use of shared or private memory heap space. This means that hash join requested a certain amount of SORTHEAP but got less than the amount requested . It might indicate that the SHEAPTHRES or SHEAPTHRES_SHR are too small for the workload. This value can be collected with a database manager snapshot. Hash joins can provide a significant performance improvement with a small amount of tuning. Simply by following some basic rules of thumb, significant improvements can be obtained in typical DSS workloads when using hash joins. Hash joins can also improve the scalability when having many concurrently sorting applications. The main parameters that affect hash joins are SORTHEAP, SHEAPTHRES, and SHEAPTHRES_SHR, with the SORTHEAP having the largest impact. Increasing the size of the SORTHEAP can potentially avoid having hash loops and overflows, which are the biggest cause of poor performance in hash joins. The optimal method for tuning hash joins is to determine how much memory is available for the SHEAPTHRES and SHEAPTHRES_SHR, then to tune the SORTHEAP accordingly . The key for tuning hash join is: Make the SORTHEAP as large as possible to avoid overflows and hash loops, but not so large as to hit SHEAPTHRES or SHEAPTHRES_SHR. NOTE However, if the SORTHEAP is too large, it may result in paging and an increase in the number of POST_THRESHOLD_SORTs, which will take up a lot of CPU cycles. The optimizer takes into consideration the SORTHEAP size in determining the access plan. After the SORTHEAP is changed, rebind all static packages. In addition, setting the registry variable DB2_BIN_SORT to YES will enable a new sort algorithm that can reduce the CPU time and elapsed time of sorts under many circumstances. Joining in a Partitioned DatabaseWhen two tables are joined together in a partitioned database, the data being joined must be physically located in the same database partition. If the data is not physically located in the same database partition, DB2 must move the data to a database partition by shipping the data from one partition to another. The movement of data between database partitions can be costly when the database is very large. Therefore, it is important to examine the largest and most frequently joined tables in the database and to choose a partitioning key to minimize the amount of data movement. Once the appropriate data is available in the database partition, DB2 can then determine the optimal join technique to execute the SQL statement. In general, the best join strategy is to have all of the large, frequently accessed tables partitioned in such a way as to resolve the most frequent join requests on their database partitions with minimal data movement. The worst join strategy is to have the large, frequently accessed tables partitioned in such a way as to force the movement of the data to the appropriate partitions for the majority of the joins. Collocated Table JoinsA collocated join is the best performing partitioned database join strategy. For a collocated join to be possible, all the data to perform the join must be located in each of the local database partitions. With a collocated join, no data needs to be shipped to another database partition except to return the answer set to the coordinator partition. The coordinator database partition assembles the answer set for final presentation to the application. DB2 will perform a collocated join if the following conditions are true:
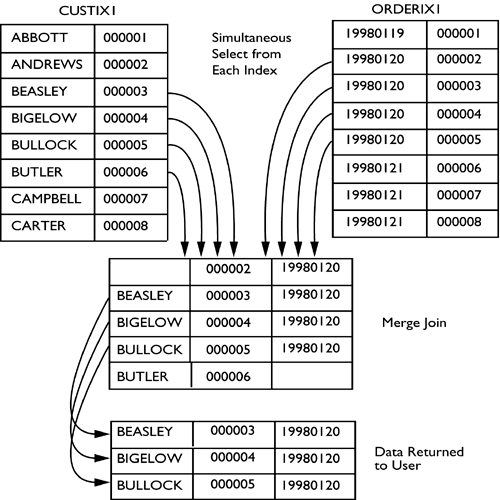
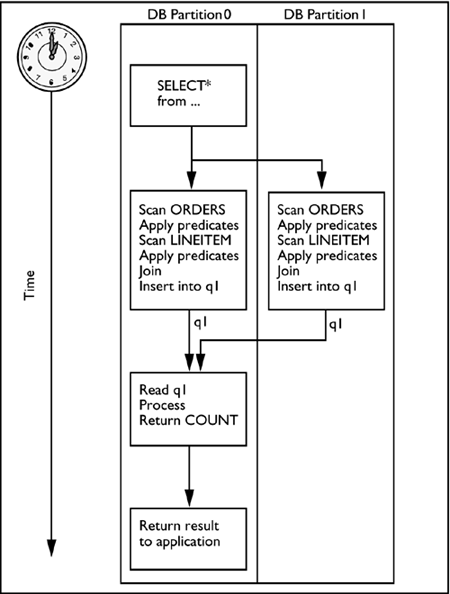
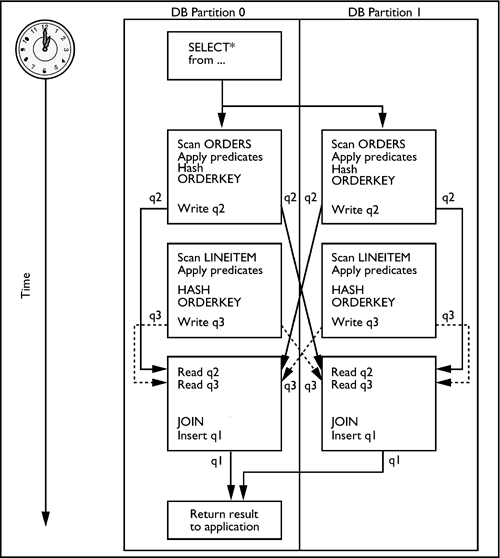
Ultimately, the data to complete the join must be found in the local database partition for DB2 to resolve the join. The collocated table join is the best performing type of join because the data already resides on the local database partition. DB2's goal in all the other join strategies is to relocate the data to the appropriate partition so that it may perform a join on each participating database partition. Figure 6.3 is a diagram of the process flow of a collocated table join. The initial request is sent to the coordinator partition. From the coordinator partition, the request is split across all appropriate database partitions. Each partition scans the ORDERS table, applies the ORDERS predicates, scans the LINEITEM table, applies the LINEITEM predicates, performs the join locally, and inserts the answer set into a table queue. The table queue is then sent to the coordinator partition, where it is read and processed. The final answer set is then returned to the originating application. Figure 6.3. The flow of a collocated join. The next sections will examine the access plan chosen for the following SQL statement: Select O_ORDERPRIORITY, COUNT(DISTINCT O_ORDERKEY) From ORDERS, LINEITEM Where L_ORDERKEY = O_ORDERKEY And L_COMMITDATE < L_RECEIPTDATE group by O_ORDERPRIORITY NOTE The output of the explain tool does not explicitly state the type of partitioned join strategy that was chosen by the DB2 optimizer. In this statement, the two tables involved in the join are ORDERS and LINEITEM. Both tables are defined in the same database partition group, and the partitioning keys for each of these tables is listed below:
The optimizer is able to choose a collocated join in this case because all of the requirements for a collocated join have been met.
Once the collocated join of the tables on each database partition completes, the answer sets will be returned to the coordinator partition for final assembly and to be returned to the application. The coordinator subsection of the explain information for this statement looks like Figure 6.4. Figure 6.4 Coordinator subsection explain output.Coordinator Subsection: Distribute Subsection #1 For an SQL statement executed in a partitioned database environment, the first subsection of each DB2 UDB explain output is the coordinator subsection. The coordinator subsection explains steps that the optimizer intends to take to execute the plan that it has decided will be the most efficient. This subsection is the key to the process flow to resolve the request. NOTE The term node is used in place of database partition in the explain snapshot in Figure 6.4. Node was the old term for database partition and is still used in some utilities, error messages, etc. From the coordinator subsection of the above explain snapshot, the first step (designated as A in the explain output in Figure 6.4) is to distribute subsection #1 to database partitions 1 and 2. Subsection #1 may be found in Figure 6.5. The activities in subsection #1 will occur on each partition.
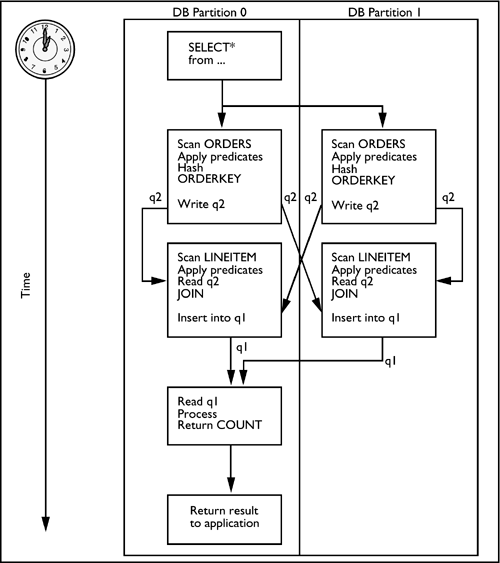
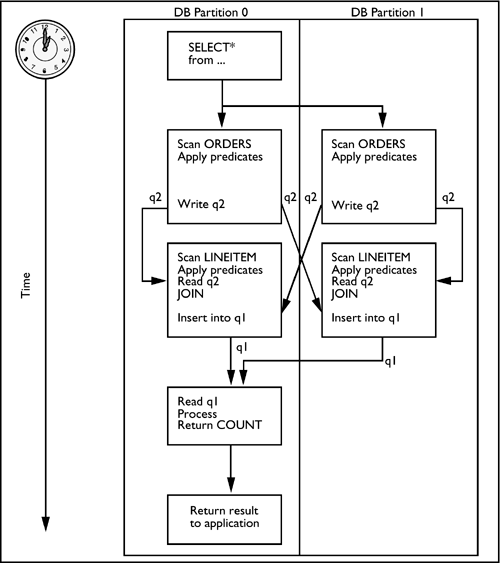
Figure 6.6 Rows in temporary table t3 inserted into table queue q1.Partial Aggregation Completion Group By Column Function(s) Insert Into Asynchronous Table Queue ID = q1 Directed Outer Table JoinsA directed outer table join can be selected between two partitioned tables only when there are equijoin predicates on all partitioning key columns. With a directed outer table join chosen by the optimizer, rows of the outer table are directed to a set of database partitions, based on the hashed values of the joining columns. Once the rows are relocated on the target database partitions, the join between the two tables will occur on these database partitions. Figure 6.7 is a diagram of the process flow for a directed outer table join strategy.
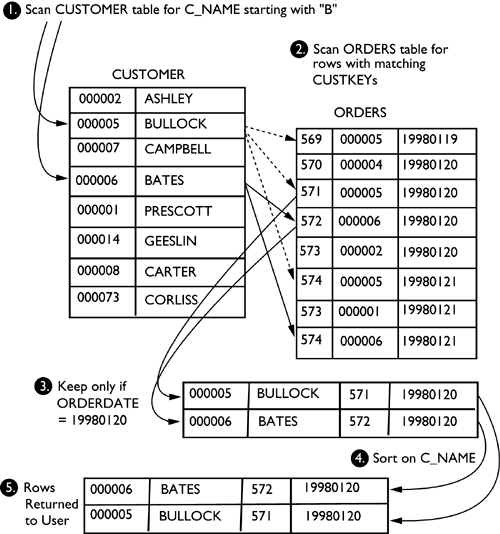
Figure 6.7. Flow of a directed outer table join. For a directed outer table join, the explain will always show the inner table as a temporary table and the outer table as a table queue that has been hashed to the target database partitions. As noted in the collocated table join strategy section, the explain output no longer explicitly states what type of partitioned join strategy is being employed to resolve the request. Directed Inner Table JoinWith the directed inner join strategy, rows of the inner table are directed to a set of database partitions, based on the hashed values of the joining columns. Once the rows are relocated on the target database partitions, the join between the two tables occurs on these database partitions. As with directed outer join, the directed inner table join may be chosen as the join strategy only when there are equijoin predicates on all partitioning key columns of the two partitioned tables. The flow of processing for a directed inner table join is identical to the process flow for the directed outer table join, except that the table that was directed to the target database partitions based on the hashed value of the joining columns is taken by DB2 as the inner table of the join on the database partition. In the directed inner table join strategy, the explain will always show the outer table as a temporary table and the inner table as a table queue that has been hashed to the target partitions. As noted previously, the explain output no longer explicitly states which join strategy has been chosen by the optimizer. The next section will examine the explain snapshot for a directed inner table join strategy. The following SQL statement was used to generate the explain snapshot. Select C_NAME, COUNT(DISTINCT O_ORDERKEY) from CUSTOMER, ORDERS where C_CUSTKEY = O_CUSTKEY and C_ACCTBAL> 0 and YEAR(O_ORDERDATE) = 1998 group by C_NAME The two tables involved in this statement are the CUSTOMER table and the ORDERS table. The partitioning keys for each of these tables are:
The CUSTOMER and ORDERS tables are not joined on their partitioning keys; therefore, this join cannot be collocated. The CUSTOMER and ORDERS join predicate from the above SQL statement is C_CUSTKEY = O_CUSTKEY. An equijoin predicate is required for a directed inner or directed outer table join; therefore, this statement is eligible for a directed table join. The next section will examine the explain output (Figure 6.8) generated for the SQL statement above. The coordinator subsection explains the steps that the optimizer intends to take to obtain the requested results. The first task (found in the explain output, Figure 6.8, A ) is to distribute subsection #2 to database partitions 1 and 2. Subsection #2 may be found on the following pages. The activities that occur in subsection #2 (Figure 6.9) are described below and occur on both database partition 1 and 2 simultaneously . Figure 6.8 Coordinator subsection explain snapshot.Coordinator Subsection: Distribute Subsection #2
In task B (Figure 6.8) in the coordinator subsection, the coordinator passes control to subsection #1, where the request is distributed to partitions 1 and 2 (Figure 6.10).
In task C (Figure 6.8) in the coordinator subsection, the table queue q1 that has been sent from each participating partition is read by the coordinator partition, final aggregation is performed, and the final result set is returned to the originating application. Figure 6.10 Subsection #1 activity.Subsection #1: Access Table Name = DB2INST1.CUSTOMER ID = 8 Directed Inner and Outer Table JoinsThe directed inner and outer table join is basically a combination of a directed inner table join and a directed outer table join. With this technique, rows of the outer and inner tables are directed to a set of database partitions, based on the values of the joining columns, where the join will occur. A directed inner and outer table join may be chosen by the optimizer when the following situation occurs:
Figure 6.11 is a diagram of the processing of a directed inner and outer join strategy. The process flow is explained below. Please note that these activities are being executed simultaneously across multiple database partitions during each step.
Figure 6.11. Flow of a directed inner and outer join. The directed inner and outer table join strategy is characterized by the local join of two hashed table queues. Broadcast Table JoinsA broadcast join is always an option for the DB2 optimizer. A broadcast table join will be chosen when the join is not eligible for any of the other join strategies or in the case where the optimizer determines that a broadcast table join is the most economical solution. A broadcast join may be chosen in the following situations:
Figure 6.12 is a diagram of the process flow of an outer table broadcast join. The process flow is explained below. Note that these activities are being executed simultaneously across multiple database partitions during each step.
Figure 6.12. Broadcast join processing flow. With a broadcast outer table join, the rows from the outer table are broadcast to the database partitions where the inner table has rows. With a broadcast inner table join, the rows from the inner table are broadcast to the database partitions where the outer table has rows. Essentially, the two broadcast join strategies are equivalent with the inner and outer tables reversed . When optimizing the following SQL statement: Select C_NAME, C_ACCTBAL from CUSTOMER, NATION where C_NATIONKEY > N_NATIONKEY and C_ACCTBAL > 0 order by C_NAME the DB2 optimizer selected a broadcast inner table join, as shown in the statement's explain snapshot (Figure 6.13). The two tables involved in this request are CUSTOMER and NATION, and the partitioning keys for these tables are:
The CUSTOMER and NATION tables are not partitioned on the same key; therefore, this join is not eligible for a collocated join. In addition, the two tables are not joined with an equijoin statement (C_NATIONKEY > N_NATIONKEY); therefore, this join is not eligible for any of the directed joins. The only option left to the optimizer is a broadcast join. When examining the explain snapshot, first start with the coordinator subsection.
Partitioned Join Strategies and PerformanceBased on the detailed descriptions of the various partitioned join strategies above, the following table is a summary of the characteristics of the various partitioned database join strategies mentioned above.
Figure 6.14 Subsection #1 activity.Subsection #1: Access Table Name = DB2INST1.CUSTOMER ID = 8 PerformanceFrom a performance point of view, the type of partitioned database join strategy that the optimizer chooses can impact performance. With the exception of a collocated join, all of the parallel join strategies require relocation of data across database partitions before the request may be resolved at the partition level. If the larger tables in the database are frequently being broadcast across database partitions, the current partition keys may need to be reevaluated to ensure they are correct for the given workload. The larger the amount of data that is moved between database partitions, the larger the impact on the performance of the query. Broadcasting small tables to the database partition where they may be joined with your largest tables is desirable. Placing small tables in a single-partition database partition group is often desirable and will force DB2 to perform a broadcast of the table to the database partitions of the larger tables. The goal in a multi-partition database is to perform as much work as possible at the partition level, not at the coordinator partition level. |
EAN: 2147483647
Pages: 121