Using Routing Protocols
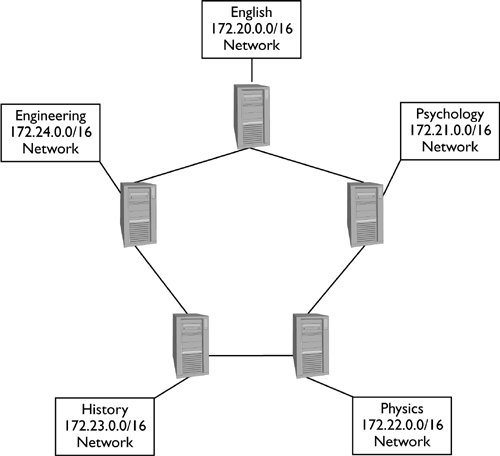
| Routers have to decide how to direct traffic. For instance, there might be two paths from the router to a packet's destination. You can use tools like the ip program in iproute2 to determine which route to use, but once you've configured that route, it's set and can't be changed except by running ip again to change it. This may be fine for a simple configuration, but there are cases when you want your router to dynamically update its routing tables to deal with changing network conditions, such as links going down or becoming available (possibly far from your own system). You might also want to be able to tell the routers that communicate with yours about changes in your own network, such as the presence of a new block of IP addresses on your network. To fulfill these needs, several routing protocols exist. Linux implements these in dedicated servers that communicate with other routers to exchange information on route availability and costs. This section covers these protocols, beginning with some background information and moving on to each of three specific protocols. Understanding Routing ProtocolsUltimately, routing is about determining what to do with specific data packets. (Technically, routing refers to the routing tables, while forwarding refers to the actual processing of packets.) Earlier sections of this chapter have described how to configure a Linux router to handle packets in ways that depend upon the packets' addresses, content, and so on. Routing protocols let you add one more component to the equation: the external network environment. This includes information on the availability of specific networks and on the cost to reach those hosts. In this context, cost doesn't refer directly to money; it's usually a measure of the number of network hops between hosts or some other measure of network performance. When a router has two network connections that lead elsewhere, the cost to reach a specific network can vary from one path to another. For instance, consider Figure 24.1, which illustrates a simple internet of five networks at a university. Each department's network has its own router, and each of these routers connects directly to two other routers, as well as to its local network. Figure 24.1. Routing protocols allow routers to exchange information, and thus determine the shortest route between two points. NOTE
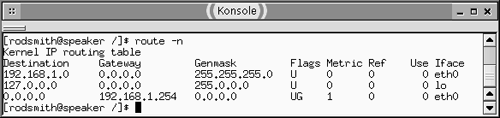
Each hop on this internet increases the latency for packets sent between the networks. For instance, sending a packet from the English department's network to the physics network requires sending the packet through at least three routers. There are, though, two paths between the English and physics networks ”one uses the psychology router as an intermediary, and the other uses the routers for both the engineering and history departments. The second (counterclockwise) path is longer. Ideally, you want a way to tell the English department's router about both paths. That way, if the psychology router fails, network traffic can still reach the destination via the less efficient route. One part of a solution is in specifying network costs. You can see these in a standard Linux routing table by using the route command For instance, Figure 24.2 shows the output of this command on one workstation. (A router would have a larger routing table, but the basic format would be the same.) Note in particular the Metric column. This shows that the number of routers involved in sending packets to the 127.0.0.0/8 (localhost) and 192.168.1.0/24 (local network) addresses is 0, but everything else requires at least one hop. This is an extremely simple example, though. In the case of a routing table for any router in Figure 24.1, there might be multiple possible paths to specific departments' networks, differing in their Metric values. Unfortunately, a standard Linux system ignores the metric information; you need to use a routing protocol like the ones described in this chapter to use this information. Figure 24.2. A routing table's Metric value specifies the cost of using a specific route. Routing protocols work by allowing routers to exchange routing information, including metric information. In the case of Figure 24.1's network, if all the routers used a routing protocol, they would learn of each others' routes and be able to build routing tables with accurate cost information. If one router goes down, this information can propagate through the internet, allowing even distant routers to redirect traffic to avoid the outage . Routing protocols use one of two algorithm types, which determine some key aspects of their operation:
Using routedRIP is the routing protocol that's most traditionally used on UNIX systems. In Linux, it's often implemented by a package called routed , which provides a daemon of the same name . RIP works by allowing routers to exchange RIP update packets, which contain information such as a network destination address (such as 172.22.0.0) and a metric (the number of routers between the one that sends the packet and the destination network). The metric ranges from 0 to 15; any route that takes more than 15 hops is eliminated from a system's routing table. RIP is a distance vector protocol, and its routing metric is fairly crude. RIP is most frequently used on small and mid- sized internets ; it's not in common use on the Internet's backbone. When a router receives an update packet, the router can do several things with the information. Specifically, the router can add a route to the destination, replace an existing route that has a higher metric, or delete the route if the new route metric plus 1 is greater than 15. Using routed in Linux is relatively straightforward: You need only start the routed program, as described in Chapter 4, Starting Servers. The server relies upon a configuration file called /etc/gateways , which contains a list of starting routing information. An example line from this file resembles the following: net 0.0.0.0 gateway 172.22.7.1 metric 1 active This information's format is fairly straightforward. This example defines a default route ( net 0.0.0.0 , which matches all entries) that uses the router (gateway) at 172.22.7.1, with a metric of 1. The final option ( active ) indicates that RIP may update this route. If you want to keep a route permanently in the routing table, you can replace active with passive . The default /etc/gateways file is normally adequate. A computer running routed will be able to locate other RIP routers via a broadcast query, and can then communicate with them to update its configuration. Using GateDAlthough RIP is the traditional UNIX routing protocol, it's not without its limitations. One of these is the 15-hop restriction, which limits the size of networks RIP can serve. Another problem is that the protocol suffers from slow convergence, which is the process of settling on a stable routing table. It can take several minutes for important changes to propagate throughout your network, depending upon your network's topology. Finally, RIP doesn't provide information on network bitmasks ; therefore, it can only provide routing information for networks that fall in the traditional Class A, B, or C address blocks. If your network uses, say, part of a traditional Class C address block, but if it's been carved up into smaller chunks , RIP propagates the addresses as if they were Class C addresses, which can cause problems if you need to contact another system in the same Class C address space that's really on a different network. The RIP version 2 (RIPv2) protocol addresses the RIP lack of a network bitmask. RIPv2 adds a network bitmask field to the RIP protocols using a field that went unused in the original RIP data structures. This and other changes, though, are substantial enough that most implementations use a new daemon for RIPv2. One such server is GateD (http://www.gated.net). This program is controlled from its configuration file, /etc/gated.conf , and via the gdc utility, which normally ships with GateD. If you use gdc to reconfigure GateD, gdc modifies the /etc/gated.conf file automatically. Like routed , GateD normally requires little or no configuration of specific routing information; instead, it communicates with other RIP and RIPv2 systems it finds via broadcasts on all available network ports, in order to adjust the current system's routing table. Like routed , GateD is started like other daemons (usually through a SysV or local startup script). In addition to handling RIP and RIPv2, GateD can handle the OSPF routing protocol. Other tools, such as Zebra, also support multiple protocols. Using ZebraA third routing tool for Linux is GNU Zebra (http://www.zebra.org). Zebra is actually a collection of several daemons that support multiple routing protocols:
You can start each of the routing daemons independently, as described in Chapter 4. For instance, you can start zebra and ripd if you want to use RIP or RIPv2, but not start the others if you don't need them. Each of these servers uses its own configuration file, which normally appears in /etc or /etc/zebra and is named after the daemon in question. For instance, /etc/zebra/ospfd.conf controls ospfd . These files all have certain common elements. They all use an exclamation mark ( ! ) or pound sign ( # ) as comment characters , and support several options, such as the following:
Once Zebra is running, you can configure it further by using a Telnet utility to access port 2601 on the router system. For instance: $ telnet localhost 2601 After you enter the password, you can enter configuration commands like enable (to gain access to configuration commands), configure (to change a configuration), or show (to display information on the configuration). At any step of the way, you can type a single question mark ( ? ) to get help on available commands or options. If you're familiar with Cisco routers, you should find Zebra's commands familiar, because they're designed to be compatible. |

EAN: 2147483647
Pages: 203