Section 12.7. Special Files
12.7. Special FilesThe HFS+ volume header contains a fork-data structure (HFSPlusForkData) for each of the five special files tagged as "special" in Figure 126three B-Trees, a bitmap, and an optional Startup file. Since a fork-data structure contains the fork's total size and the initial set of the file's extents, these files can all be accessed starting from the volume header. An HFS+ implementation reads the volume header and the appropriate special files to provide access to the user data (i.e., files, folders, and attributes) contained on a volume. The special files are not user-visible. They also do not contribute to the file count maintained in the volume header.
An important point to note about the special files is that besides being free to reside at any available locations on the volume, they need not be contiguous. Moreover, all special files, except the Extents Overflow file, can grow beyond eight extents, in which case the "overflowing" extents will be stored in the Extents Overflow file. 12.7.1. The Allocation FileThe Allocation file tracks whether an allocation block is in use. It is simply a bitmap, containing a bit for each allocation block on the volume. If a given block is either holding user data or assigned to a file system data structure, the corresponding bit is set in the Allocation file. Thus, each byte in this file tracks eight allocation blocks. Note that being a file, the Allocation file itself consumes an integral number of allocation blocks. One of its nice properties is that it can be grown or shrunk, allowing flexibility in manipulation of a volume's space. This also means that the last allocation block assigned to the Allocation file may have unused bitssuch bits must be explicitly set to zero by the HFS+ implementation.
We saw in Section 12.4 that an HFS+ volume has two reserved areas: the first 1024 bytes and the last 512 bytes. The 512-byte volume header and the 512-byte alternate volume header are adjacentafter and before, respectivelyto these two areas. The allocation blocks that encompass the reserved areas and the two volume headers must be marked as used in the Allocation file. Moreover, if the volume size is not an integral multiple of the allocation block size, there will be some trailing space that will not have a corresponding bit in the Allocation file. Even in this case, the alternate volume header is stored at a 1024-byte offset from the end of the volumethat is, possibly in the unaccounted-for area. Nevertheless, HFS+ will still consider the last Allocation-file-tracked 1024 bytes as used and will mark the corresponding allocation block (or blocks) as allocated. 12.7.1.1. Viewing the Contents of the Allocation FileWe can use hfsdebug to viewindirectlythe contents of the Allocation file. We say "indirectly" because hfsdebug can examine the Allocation file and enumerate all free extents on a volume. Thus, the Allocation file bits corresponding to the extents that hfsdebug lists are all clear, whereas the remaining bits are all set. $ sudo hfsdebug -0 # Free Contiguous Starting @ Ending @ Space 16 0x60c7 0x60d6 64.00 KB 16 0x1d6d7 0x1d6e6 64.00 KB 16 0x1f8e7 0x1f8f6 64.00 KB 32 0x23cf7 0x23d16 128.00 KB 130182 0x25f67 0x45bec 508.52 MB ... 644 0x2180d00 0x2180f83 2.52 MB 4857584 0x2180f85 0x2622e74 18.53 GB Allocation block size = 4096 bytes Allocation blocks total = 39988854 (0x2622e76) Allocation blocks free = 8825849 (0x86abf9)12.7.1.2. The Roving Next-Allocation PointerFor each mounted HFS+ volume, the kernel maintains a roving pointeran allocation block number as a hintthat is used as a starting point while searching for free allocation blocks in many (but not all) cases. The pointer is held in the nextAllocation field of the hfsmount structure. An allocation operation that uses the pointer also updates it. $ sudo hfsdebug -m ... free allocation blocks = 0x86d12b start block for next allocation search = 0x20555ea next unused catalog node ID = 3256261 ... $ echo hello > /tmp/newfile.txt $ sudo hfsdebug -m ... free allocation blocks = 0x86d123 start block for next allocation search = 0x20555eb next unused catalog node ID = 3256262 ... $ sudo hfsdebug /tmp/newfile.txt ... # Catalog File Record type = file file ID = 3256261 ... # Data Fork ... extents = startBlock blockCount % of file 0x20555eb 0x1 100.00 % 1 allocation blocks in 1 extents total. ... You can also set the value of nextAllocation for a given volume. The HFS_CHANGE_NEXT_ALLOCATION request of the fsctl() system call can be used to do so. Figure 1211 shows a program that sets nextAllocation for the given volume path. Figure 1211. Hinting to the file system where to look for free space on a volume
Let us test the program shown in Figure 1211 on a new HFS+ disk image (Figure 1212). Figure 1212. Examining allocation block consumption on a volume
Since allocation blocks 0xafa through 0x1ff4 are free on the volume shown in Figure 1212, let us use the program from Figure 1211 to set the nextAllocation value to 0xbbb. We can then create a file and see if the file starts at that allocation block. $ gcc -Wall -o hfs_change_next_allocation hfs_change_next_allocation.c $ ./hfs_change_next_allocation /Volumes/HFSHint 0xbbb start block for next allocation search changed to 0xbbb $ echo hello > /Volumes/HFSHint/anotherfile.txt $ hfsdebug /Volumes/HFSHint/anotherfile.txt ... extents = startBlock blockCount % of file 0xbbb 0x1 100.00 % 1 allocation blocks in 1 extents total. ... 12.7.2. The Catalog FileThe Catalog file describes the hierarchy of files and folders on a volume. It acts both as a container for holding vital information for all files and folders on a volume and as their catalog. HFS+ stores file and folder names as Unicode strings represented by HFSUniStr255 structures, which consist of a length and a 255-element double-byte Unicode character array. // bsd/hfs/hfs_format.h struct HFSUniStr255 { u_int16_t length; // number of Unicode characters in this name u_int16_t unicode[255]; // Unicode characters // (fully decomposed, in canonical order) }; Each file or folder on the volume is identified by a unique catalog node ID (CNID) in the Catalog file. The CNID is assigned at file creation time. In particular, HFS+ does not use an inode table. A folder's CNID (directory ID) and a file's CNID (file ID) are reported[15] as their respective inode numbers when queried through a Unix-based interface such as the stat() system call.
On traditional Unix file systems, an index node, or inode, is an object describing the internal representation of a file. Each file or directory object has a unique on-disk inode that contains the object's metadata and the locations of the object's blocks. As noted earlier, the Catalog file is organized as a B-Tree to allow for quick and efficient searching. Its fundamental structure is the same as we discussed in Section 12.2.6. However, the formats of the keys and the data stored in its records are specific to it. Each user file has two leaf records in the Catalog file: a file record and a file thread record. Similarly, each folder has two leaf records: a folder record and a folder thread record. The purposes of these records are as follows.
In traditional Unix file systems, directories are explicitly stored on disk. Storing the hierarchical structure in a B-Tree has several performance benefits, but not without costfor example, the Catalog B-Tree must be locked, sometimes exclusively, for several file system operations. Let us see how a file might be accessed given its identifying information. Depending on the programming interface it uses, a user program can specify the file system object it wishes to access on a given volume in several ways:
The volume file systemnormally mounted under /.volallows files and folders on an HFS+ volume to be looked up by their CNIDs. As we saw in Chapter 11, the /.vol directory contains a subdirectory for each mounted volume that supports the volume file system. The subdirectory names are the same as the respective volume IDs. Pathname lookups are broken down into component-wise lookup operations in the kernel. Recently looked up names are cached[16] so that the namei() function does not have to go all the way down to the file system on every lookup. At the catalog-level, tree searches are either one-step or two-step, depending on how the search key is populated. A Catalog B-Tree key is represented by the HFSPlusCatalogKey structure.
// bsd/hfs/hfs_format.h struct HFSPlusCatalogKey { u_int16_t keyLength; // parent folder's CNID for file and folder records; // node's own CNID for thread records u_int32_t parentID; // node's Unicode name for file and folder records; // empty string for thread records HFSUniStr255 nodeName; }; Figure 1213 shows an overview of how the Catalog B-Tree is searched. If we begin with only the CNID of the target object, a two-step search is required. The search key is prepared as follows: The parentID field of the HFSPlusCatalogKey structure is set to the target's CNID, and the nodeName field is set to the empty string. A B-Tree lookup performed with such a key yields the target's thread record (if it exists). The contents of the thread recordthe target's node name and its parent's CNIDare what we require to perform a one-step search. A second lookup will yield an HFSPlusCatalogFile or HFSPlusCatalogFolder record, depending on whether the target is a file or a folder, respectively. When comparing two catalog keys, their parentID fields are compared first and the nodeName fields are compared next. Figure 1213. Searching in the Catalog B-Tree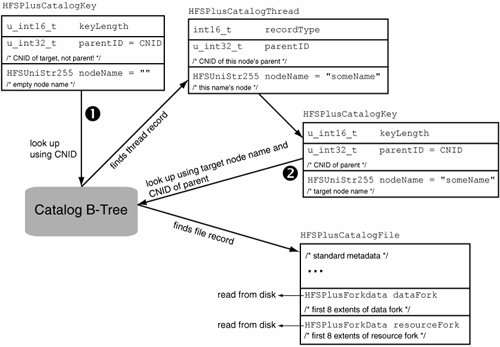 Figure 1214 shows an overall picture of how a file might be accessed by an HFS+ implementation. Suppose we wish to read a file. We will start at the volume header (1), which will provide us with the extents of the Catalog file (2). We will search the Catalog B-Tree to find the desired file record (3), which will contain the file's metadata and initial extents (4). Given the latter, we can seek the appropriate disk sectors and read the file data (5). If the file has more than eight extents, we will have to perform one or more additional lookups in the Extents Overflow file. Figure 1214. An overview of accessing a file's contents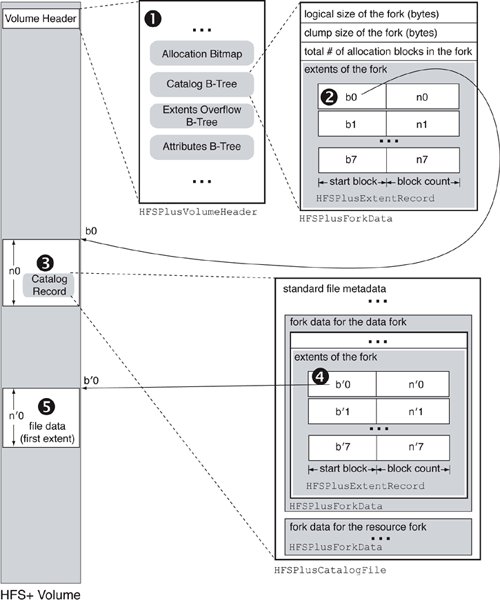 12.7.2.1. Catalog Node IDsAs noted earlier, each file and folder on an HFS+ volumeincluding the special filesis assigned a unique CNID, which is implemented as a 32-bit unsigned integer. Apple reserves the first 16 CNIDs for its own use. Table 122 shows how these CNIDs are used.
The next unused CNID is maintained in both the volume header (as the nextCatalogID field) and the hfsmount structure (as the vcbNxtCNID field). The first CNID available for user files and folders is 16. In practice, it will be assigned to a file or a folder created before the user begins to access the volumefor example, a journal file. An interesting property of HFS+ is that it allows a Unix pathname of a file system object to be determined from its inode number. With the exception of hard links, an object's CNID is used as its inode number from the standpoint of the Unix APIs. Since a thread record connects an object to its parent, a complete pathname can be constructed by repeatedly looking up thread records until we reach the root. Note that we say "a pathname" and not "the pathname" because a Unix-visible inode number may have more than one referring pathname if the file's link count is greater than onethat is, if it has several hard links.[17]
hfsdebug supports the previously mentioned methods of looking up a file system object, for example: $ sudo hfsdebug -c 16 # look up by CNID <Catalog B-Tree node = 9309 (sector 0x32c88)> path = Macintosh HD:/.journal # Catalog File Record type = file file ID = 16 ... $ sudo hfsdebug -F 2:.journal # look up by node name and parent's CNID <Catalog B-Tree node = 9309 (sector 0x32c88)> path = Macintosh HD:/.journal ... The Carbon File Manager provides the PBResolveFileIDRefSync() function to retrieve the node name and parent CNID of a file system object given its CNID. The program shown in Figure 1215 prints the Unix pathname of a file or foldergiven its CNIDresiding on the default (root) volume. It continues to find the name of each component of the given pathname until the parent ID of a given component is the same as that of the component. Figure 1215. Using the Carbon File Manager API to convert a CNID to a Unix pathname
12.7.2.2. Examining the Catalog B-TreeWe can use hfsdebug to examine the header node of the Catalog B-Tree (Figure 1216) and to list one or more types of records contained in the tree's leaf nodes. Figure 1216. The contents of a Catalog B-Tree's header node
The volume whose Catalog B-Tree's header node is shown in Figure 1216 contains over 3 million leaf nodes. We can verify that the precise number is equal to exactly twice the sum of the volume's file and folder counts, with the folder count being one more than what's displayed (to account for the root folder). Of particular interest is the tree's depthonly 4. The node size of 8KB is the default for volumes greater than 1GB in size.[18]
12.7.3. The Extents Overflow FileDepending on the amount and contiguity of free space available on a volume, allocation of storage to a file fork may be physically noncontiguous. In other words, a fork's logically contiguous content may be divided into multiple contiguous segments, or extents. We earlier defined an extent descriptor as a pair of numbers representing a contiguous range of allocation blocks belonging to a fork, and an extent record as an array of eight extent descriptors. A file record in the catalog has space for holding an extent record each for the file's data and resource forks. If a fork has more than eight fragments, its remaining extents are stored in the leaf nodes of the Extents Overflow file. Unlike the Catalog B-Tree, which has multiple types of leaf records, the Extents Overflow B-Tree has only one, consisting of a single HFSPlusExtentRecord structure. The key format is represented by the HFSPlusExtentKey structure, which consists of a fork type (forkType), a CNID (fileID), and a starting allocation block number (startBlock). Whereas the Catalog B-Tree uses variable-length keys, the Extents Overflow keys are fixed-size. Figure 1217 shows the data types used in the key format. When comparing two Extents Overflow B-Tree keys, their fileID fields are compared first, followed by the forkType fields, and finally the startBlock fields. Figure 1217. Searching in the Extents Overflow B-Tree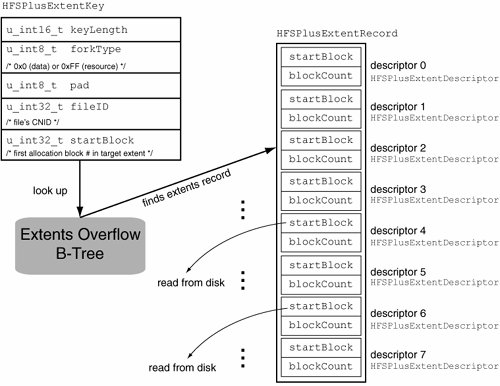 12.7.3.1. Examining FragmentationWe can use hfsdebug to display all fragmented file forks on a volume. Fragmentation in file systems has traditionally been an important factor that affects performance negatively. Modern file systems are usually less prone to fragmentation than their ancestors are. Numerous algorithms and schemes have been incorporated into file systems to reduce fragmentation and, in some cases, even undo existing fragmentationthe Mac OS X HFS+ implementation is an example of the latter. Nevertheless, fragmentation is still a cause for concern for both the designers and the users of file systems.
We can use hfsdebug to obtain summarized usage statistics for a volume. The information printed includes the total sizes of all the data and resource forks on the volume, along with the amounts of storage actually allocated. The difference between allocated storage and actual usage quantifies internal fragmentation. $ sudo hfsdebug -s # Volume Summary Information files = 1448399 folders = 149187 aliases = 10 hard links = 6010 symbolic links = 13037 invisible files = 737 empty files = 10095 # Data Forks non-zero data forks = 1437152 fragmented data forks = 2804 allocation blocks used = 31022304 allocated storage = 127067357184 bytes (124089216.00 KB/121180.88 MB/118.34 GB) actual usage = 123375522741 bytes (120483908.93 KB/117660.07 MB/114.90 GB) total extent records = 1437773 total extent descriptors = 1446845 overflow extent records = 621 overflow extent descriptors = 4817 # Resource Forks non-zero resource forks = 11570 fragmented resource forks = 650 allocation blocks used = 158884 allocated storage = 650788864 bytes (635536.00 KB/620.64 MB/0.61 GB) actual usage = 615347452 bytes (600925.25 KB/586.84 MB/0.57 GB) total extent records = 11570 total extent descriptors = 12234 overflow extent records = 0 overflow extent descriptors = 0 10418 files have content in both their data and resource forks.We can also use hfsdebug to examine the fragmented forks in more detail. When run with the -f option, hfsdebug lists all forks with more than one extent on the volume. For each fork, the output consists of the following information:
12.7.3.2. Examining the Extents Overflow B-TreeFigure 1218 shows the output for the header node of the Extents Overflow B-Tree on the volume from Figure 1216. Figure 1218. The contents of an Extents Overflow B-Tree's header node
Figure 1218 shows that there are 617 leaf records in the tree. We can list all the leaf records to determine the number of files that have more than eight extents. As shown here, there are 37 such files in our example. $ sudo hfsdebug -b extents -l any # Extent Record keyLength = 10 forkType = 0 pad = 0 fileID = 118928 startBlock = 0x175 (373) path = Macintosh HD:/.Spotlight-V100/store.db 0x180dc7 0x50 0x180f3e 0x10 0x180f9d 0x40 0x1810ee 0x80 0x191a33 0xf0 0x1961dc 0x10 0x19646d 0x10 0x19648d 0x10 # Extent Record keyLength = 10 ^C $ sudo hfsdebug -b extents -l any | grep fileID | sort | uniq | wc -l 37 12.7.4. The Attributes FileThe Attributes file is a B-Tree that allows the implementation of named forks. A named fork is simply another byte-streamsimilar to the data and resource forks. However, it can be associated with either a file or a folder, which can have any number of associated named forks. Beginning with Mac OS X 10.4, named forks are used to implement extended attributes for files and folders. In turn, the support for access control lists (ACLs) in Mac OS X 10.4 uses extended attributes for storing ACL data attached to files and folders. Each extended attribute is a name-value pair: The name is a Unicode string and the corresponding value is arbitrary data. As with node names in the Catalog B-Tree, the Unicode characters in attribute names are stored fully decomposed and in canonical order. Attribute data can have its own extents, so, in theory, attributes can be arbitrarily large. However, Mac OS X 10.4 supports only inline attributes, which can fit within a single B-Tree node while maintaining any structural overheads and other requirements for B-Tree nodes. In other words, inline attributes do not require any initial or overflow extents for their storage.
A B-Tree node must be large enough that if it were an index node, it would contain at least two keys of maximum size. This means space must be reserved for at least three record offsets. Each node also has a node descriptor. Given that the default node size for the Attributes B-Tree is 8KB, the kernel calculates the maximum inline attribute size as 3802 bytes. Figure 1219 shows the key and record formats used in the Attributes B-Tree. The key format is represented by an HFSPlusAttrKey structure, which includes a CNID (fileID), a starting allocation block number (startBlock) for attributes with extents, and a Unicode name (attrName) for the attribute. Figure 1219. Searching in the Attributes B-Tree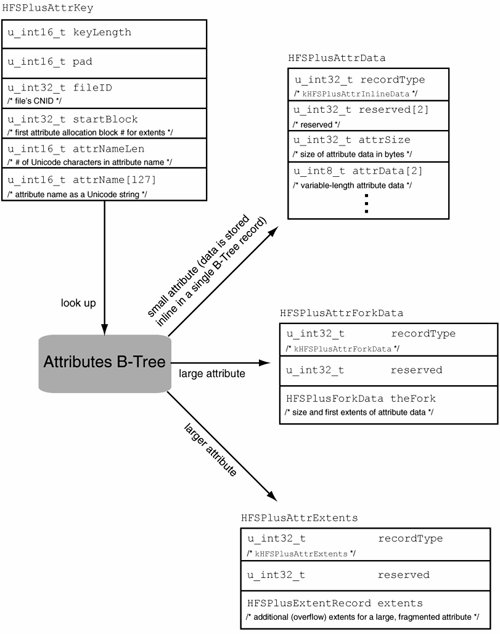 When comparing two Attributes B-Tree keys, their fileID fields are compared first, followed by the attrName fields, and finally the startBlock fields. Figure 1219 shows that there can be three types of records in the Attributes B-Tree. The one represented by an HFSPlusAttrData structure holds inline attribute data. The other two are used for larger attributes that require their extents to be tracked. HFSPlusAttrForkData includes an HFSPlusForkData structurethat is, up to eight initial extents. If an attribute's on-disk data is more fragmented, it will require one or more HFSPlusAttrExtents records, each of which will track an additional eight extents. 12.7.4.1. Working with Extended AttributesExtended attributes of HFS+ file system objects are manipulated through the BSD system calls setxattr(), getxattr(), listxattr(), and removexattr(), all of which operate on pathnames.[19] These system calls also have variantswith an f prefix in their namesthat operate on open file descriptors.
There is a single, global namespace for attributes. Although attribute names can be arbitrary, Apple recommends using a reverse-DNS-style naming scheme. Examples of attributes commonly employed by the operating system include the following:
The program shown in Figure 1220 sets and retrieves extended attributes for the given pathname. Figure 1220. Programmatically setting an extended attribute
Note that HFS+ only stores extended attributesit does not index them. In particular, it does not participate in search operations performed by the Spotlight search mechanism (see Section 11.8), which uses external index files, not extended attributes, to store metadata. 12.7.4.2. Examining the Attributes B-TreeUnlike the Catalog and Extents Overflow B-Trees, the Attributes B-Tree is not a mandatory constituent of an HFS+ volume. Even if an HFS+ implementation supports extended attributes and ACLs, an attached HFS+ volume may have a zero-length Attributes file if no file system object on that volume has ever used these features. If this is the case, the volume's Attributes file will be created when a setxattr() operation is attempted on one of the volume's files or folders, or when ACLs are enabled for the volume. $ hdiutil create -size 32m -fs HFSJ -volname HFSAttr /tmp/hfsattr.dmg $ open /tmp/hfsattr.dmg $ hfsdebug -V /Volumes/HFSAttr -v ... # Attributes File logicalSize = 0 bytes ... $ fsaclctl -p /Volumes/HFSAttr Access control lists are not supported or currently disabled on /Volumes/HFSAttr. $ sudo fsaclctl -p /Volumes/HFSAttr -e $ fsaclctl -p /Volumes/HFSAttr Access control lists are supported on /Volumes/HFSAttr. $ hfsdebug -V /Volumes/HFSAttr -v ... # Attributes File logicalSize = 1048576 bytes totalBlocks = 256 clumpSize = 1048576 bytes extents = startBlock blockCount % of file 0xaf9 0x100 100.00 % 256 allocation blocks in 1 extents total. 256.00 allocation blocks per extent on an average. ... We can create an ACL entry for a file and use hfsdebug to display the corresponding Attributes B-Tree record, which will illustrate how ACLs are stored as extended attributes on an HFS+ volume. $ touch /Volumes/HFSAttr/file.txt $ chmod +a 'amit allow read' /Volumes/HFSAttr/file.txt $ hfsdebug /Volumes/HFSAttr/file.txt # Attributes <Attributes B-Tree node = 1 (sector 0x57d8)> # Attribute Key keyLength = 62 pad = 0 fileID = 22 startBlock = 0 attrNameLen = 25 attrName = com.apple.system.Security # Inline Data recordType = 0x10 reserved[0] = 0 reserved[1] = 0 attrSize = 68 bytes attrData = 01 2c c1 6d 00 00 00 00 00 00 00 00 00 00 00 00 , m ... # File Security Information fsec_magic = 0x12cc16d fsec_owner = 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 fsec_group = 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 # ACL Record acl_entrycount = 1 acl_flags = 0 # ACL Entry ace_applicable = 53 25 a9 39 2f 3f 49 35 b0 e4 7e f4 71 23 64 e9 user = amit uid = 501 group = amit gid = 501 ace_flags = 00000000000000000000000000000001 (0x000001) . KAUTH_ACE_PERMIT ace_rights = 00000000000000000000000000000010 (0x000002) . KAUTH_VNODE_READ_DATA 12.7.5. The Startup FileHFS+ supports an optional Startup file that can contain arbitrary informationsuch as a secondary bootloaderfor use while booting the system. Since the location of the Startup file is at a well-known offset in the volume header, it helps a system without built-in HFS+ support (in ROM, say) to boot from an HFS+ volume. A Startup file is used for booting Mac OS X from an HFS+ volume on an Old World machine. Other hardware compatibility issues aside, the machine is likely to have booting problems because of its older Open Firmware. The firmware may not support HFS+. Moreover, it will be programmed to execute the Mac OS ROM instead of BootX. One solution involves storing the XCOFF version of BootX in the Startup file and creating an HFS wrapper volume containing a special "system" file that patches Open Firmware such that the firmware does not execute the Mac OS ROMinstead, it loads BootX from the Startup file. |
EAN: 2147483647
Pages: 161