Section 12.2. Integrated Services QoS
12.2. Integrated Services QoSThe integrated services approach , consisting of two service classes, defines both the service class and mechanisms that need to be used in routers to provide the services associated with the class. The first service class, the guaranteed service class , is defined for applications that cannot tolerate a delay beyond a particular value. This type of service class can be used for real-time applications, such as voice or video communications. The second, controlled-load service class , is used for applications that can tolerate some delay and loss. Controlled-load service is designed such that applications run very well when the network is not heavily loaded or congested . These two service classes cover the wide range of applications on the Internet. A network needs to obtain as much information as possible about the flow of traffic to provide optimum services to the flow. This is true especially when real-time services to an application are requested . Any application request to a network has to first specify the type of service required, such as controlled load or guaranteed service. An application that requires guaranteed service also needs to specify the maximum delay that it can tolerate. Once the delay factor is known to a service provider, the QoS unit of the node must determine the necessary processes to be applied on incoming flows. Figure 12.1 shows four common categories of processes providing quality of service.
Figure 12.1. Overview of QoS methods in integrated services The widespread deployment of the integrated services approach has been deterred owning to scalability issues. As the network size increases , routers need to handle larger routing tables and switch larger numbers of bits per second. In such situations, routers need to refresh information periodically. Routers also have to be able to make admission-control decisions and queue each incoming flow. This action leads to scalability concerns, especially when networks scale larger. 12.2.1. Traffic ShapingRealistically, spacing between incoming packets has an irregular pattern, which in many cases causes congestion. The goal of traffic shaping in a communication network is to control access to available bandwidth to regulate incoming data to avoid congestion, and to control the delay incurred by packets (see Figure 12.2). Turbulent packets at rate » and with irregular arrival patterns are regulated in a traffic shaper over equal- sized 1 /g intervals. Figure 12.2. Traffic shaping to regulate any incoming turbulent traffic If a policy dictates that the packet rate cannot exceed a specified rate even though the network node's access rates might be higher, a mechanism is needed to smooth out the rate of traffic flow. If different traffic rates are applied to a network node, the traffic flow needs to be regulated. (Monitoring the traffic flow is called traffic policing .) Traffic shaping also prevents packet loss by preventing the sudden increased usage of system bandwidth. The stochastic model of a traffic shaper consists of a system that converts any form of traffic to a deterministic one. Two of the most popular traffic-shaping algorithms are leaky bucket and token bucket . Leaky-Bucket Traffic ShapingThis algorithm converts any turbulent incoming traffic into a smooth, regular stream of packets. Figure 12.3 shows how this algorithm works. A leaky-bucket interface is connected between a packet transmitter and the network. No matter at what rate packets enter the traffic shaper, the outflow is regulated at a constant rate, much like the flow of water from a leaky bucket. The implementation of a leaky-bucket algorithm is not difficult. Figure 12.3. The leaky-bucket traffic-shaping algorithm At the heart of this scheme is a finite queue. When a packet arrives, the interface decides whether that packet should be queued or discarded, depending on the capacity of the buffer. The number of packets that leave the interface depends on the protocol. The packet- departure rate expresses the specified behavior of traffic and makes the incoming bursts conform to this behavior. Incoming packets are discarded once the bucket becomes full. This method directly restricts the maximum size of a burst coming into the system. Packets are transmitted as either fixed-size packets or variable-size packets. In the fixed-size packet environment, a packet is transmitted at each clock tick. In the variable-size packet environment, a fixed-sized block of a packet is transmitted. Thus, this algorithm is used for networks with variable-length packets and also equal-sized packet protocols, such as ATM. The leaky-bucket scheme is modeled by two main buffers, as shown in Figure 12.4. One buffer forms a queue of incoming packets, and the other one receives authorizations. The leaky-bucket traffic-shaper algorithm is summarized as follows . Figure 12.4. Queueing model of leaky-bucket traffic-shaping algorithm Begin Leaky-Bucket Algorithm
With this model, ‰ is the bucket size. The bucket in this case is the size of the window that the grant buffer opens to allow ‰ packets from the main buffer to pass. This window size can be adjusted, depending on the rate of traffic. If ‰ is too small, the highly turbulent traffic is delayed by waiting for grants to become available. If ‰ is too large, long turbulent streams of packets are allowed into the network. Consequently, with the leaky-bucket scheme, it would be best for a node to dynamically change the window size (bucket size) as needed. The dynamic change of grant rates in high-speed networks may, however, cause additional delay through the required feedback mechanism. Figure 12.5 shows the Markov chain state diagram (see Section C.5) depicting the activity of grant generation in time. At the main buffer, the mean time between two consecutive packets is 1 /» . At the grant buffer, a grant arrives at rate g . Hence, every 1 /g seconds, a grant is issued to the main buffer on times 0, 1 /g , 2 /g , ....If the grant buffer contains ‰ grants, it discards any new arriving grants. A state i ˆˆ{0, 1, ... ‰ } of the Markov chain refers to the situation in which i grants are allocated to i packets in the main buffer, and thus ‰ - i grants are left available. In this case, the i packets with allocated grants are released one at a time every 1 /g seconds. When the packet flow is slow, the grant queue reaches its full capacity, and thus grants ( ‰ + 1) and beyond are discarded. Figure 12.5. State diagram modeling the leaky-bucket traffic-shaping algorithm We define the following main variables for delay analysis:
As shown in Figure 12.5, the chain starts at state 0, implying that ‰ grants are available in the grant buffer and that no packet is in the main buffer. In this state, the first arriving packet to the main buffer with probability P X ( 1) gets a grant while a new grant arrives in the same period. This creates no changes in the state of the chain. Therefore, the transition probability at state 0 has two components , as follows: Equation 12.1 This means that P 00 is equal to the probability that no packet or only one packet arrives ( P X ( 0) + P X ( 1)). As long as i Equation 12.2 For example, two new packets arriving during a period 1 /g with probability P X ( 2) change state 0 to state 1 so that one of the two packets is allocated a grant, and thus the chain moves to state 1 from state 0, and the second packet is allocated the new arriving grant during that period of time. The remaining transition probabilities are derived from Equation 12.3 Now, the global balance equations can be formed . We are particularly interested in the probability of any state i denoted by P i . The probability that the chain is in state 0, P , implying that no grant has arrived, is the sum of incoming transitions: Equation 12.4 For P 1 , we can write Equation 12.5 For all other states, the probability of the state can be derived from the following generic expression: Equation 12.6 The set of equations generated from Equation (12.6) can be recursively solved . Knowing the probability of each state at this point, we can use Little's formula (see Section 11.1) to estimate the average waiting period to obtain a grant for a packet, E [ T ], as follows: Equation 12.7 It is also interesting to note that the state of the Markov chain can turn into "queueing of packets" at any time, as shown by dashed lines in Figure 12.5. For example at state 0, if more than ‰ + 1 packets arrive during 1 /g , the state of the chain can change to any state after ‰ , depending on the number of arriving packets during 1 /g . If this happens, the system still assigns ‰ + 1 grants to the first ‰ + 1 packets and assigns no grant to the remaining packets. The remaining packets stay pending to receive grants.
Token-Bucket Traffic ShapingTraffic flow for most applications varies, with traffic bursts occurring occasionally. Hence, the bandwidth varies with time for these applications. However, the network must be informed about the bandwidth variation of the flow in order to perform admission control and to operate more efficiently . Two parametersthe token arrival rate, v , and the bucket depth , b together describe the operation of the token-bucket traffic shaper. The token rate, v , is normally set to the average traffic rate of the source. The bucket depth, b , is a measure of the maximum amount of traffic that a sender can send in a burst. With the token-bucket traffic-shaping algorithm, flow traffic is shaped efficiently as shown in Figure 12.6. The token-bucket shaper consists of a buffer, similar to a water bucket, that accepts fixed-size tokens of data generated by a token generator at a constant rate every clock cycle. Packets with any unpredictable rate must pass through this token-bucket unit. According to this protocol, a sufficient number of tokens are attached to each incoming packet, depending on its size, to enter the network. If the bucket is full of tokens, additional tokens are discarded. If the bucket is empty, incoming packets are delayed (buffered) until a sufficient number of tokens is generated. If the packet size is too big, such that there are not enough tokens to accommodate it, a delay of input packets is carried over. Figure 12.6. The token-bucket traffic-shaping method The best operation of this algorithm occurs when the number of tokens is larger than the number of incoming packet sizes. This is not a big flaw, as tokens are periodically generated. The output rate of packets attached with tokens obeys the clock, and so the corresponding flow becomes a regulated traffic stream. Thus, by changing the clock frequency and varying the token-generation rate, we can adjust the input traffic to an expected rate. Comparison of Leaky-Bucket and Token-Bucket ApproachesBoth algorithms have their pros and cons. The token-bucket algorithm enforces a more flexible output pattern at the average rate, no matter how irregular the incoming traffic is. The leaky-bucket method enforces a more rigid pattern. Consequently, the token bucket is known as a more flexible traffic-shaping method but has greater system complexity. The token-bucket approach has an internal clock that generates tokens with respect to the clock rate. A queueing regulator then attaches incoming packets to tokens as packets arrive, detaches tokens as packets exit, and, finally, discards the tokens. This process adds considerable complexity to the system. In the leaky-bucket approach, no virtual tokens are seen, greatly increasing the speed of operation and enhancing the performance of the communication node. Our primary goal of coming up with a high-speed switching network would thus be easily attained. 12.2.2. Admission ControlThe admission-control process decides whether to accept traffic flow by looking at two factors:
For controlled-load services, no additional parameters are required. However, for guaranteed services, the maximum amount of delay must also be specified. In any router or host capable of admission control, if currently available resources can provide service to the flow without affecting the service to other, already admitted flows, the flow is admitted. Otherwise, the flow is rejected permanently. Any admission-control scheme must be aided by a policing scheme. Once a flow is admitted, the policing scheme must make sure that the flow confirms to the specified t s . If not, packets from these flows become obvious candidates for packet drops during a congestion event. A good admission-control scheme is vital to avoid congestion. 12.2.3. Resource Reservation Protocol (RSVP)The Resource Reservation Protocol (RSVP) is typically used to provide real-time services over a connectionless network. RSVP is a soft-state protocol so that it can handle link failure efficiently. The protocol adopts a receiver-oriented approach to resource reservation. This process is required to provide the desired QoS for an application. RSVP supports both unicast and multicast flows. Unlike connection-oriented resource set-up mechanisms, RSVP can adapt to router failures by using an alternative path . In order for a receiver to make a reservation at intermediate routers, the sender initially sends the t s message, which passes through each intermediate router before reaching the receiver. This way, the receiver becomes aware of the information on the flow and the path and makes a reservation at each router. This message is sent periodically to maintain the reservation. The router can accept or deny the reservation, based on its available resources. Also, the t s message is periodically refreshed to adapt to link failures. When a particular link fails, the receiver receives this message over a different path. The receiver can then use this new path to establish a new reservation; consequently, the network operation continues as usual. Reservation messages from multiple receivers can be merged if their delay requirements are similar. If a receiver needs to receive messages from multiple senders, it requests a reservation meeting the total of t s requirements of all senders. Thus, RSVP uses a receiver-oriented approach to request resources to meet the QoS requirements of various applications. 12.2.4. Packet SchedulingRSVP enables network users to reserve resources at the routers. Once the resources have been reserved, a packet-scheduling mechanism has to be in place to provide the requested QoS. Packet scheduling involves managing packets in queues to provide the QoS associated with the packet, as shown in Figure 12.7. A packet classifier is the heart of scheduling scheme and performs on the basis of the header information in the packet. Packet classifying involves identifying each packet with its reservation and ensuring that the packet is handled correctly. Figure 12.7. Overview of a packet scheduler Packets are classified according to the following parameters:
Based on that information, packets can be classified into those requiring guaranteed services and those requiring controlled-load services. Designing optimal queueing mechanisms for each of these categories is important in providing the requested QoS. For provision of a guaranteed service, weighted-fair queueing is normally used. This type of queueing is very effective. For controlled-load services, simpler queueing mechanisms can be used. Packet scheduling is necessary for handling various types of packets, especially when real-time packets and non-real -time packets are aggregated. Real-time packets include all delay-sensitive traffic, such as video and audio data, which have a low delay requirement. Non-real-time packets include normal data packets, which do not have a delay requirement. Packet scheduling has a great impact on the QoS guarantees a network can provide. If a router processes packets in the order in which they arrive, an aggressive sender can occupy most of the router's queueing capacity and thus reduce the quality of service. Scheduling ensures fairness to different types of packets and provides QoS. Some of the commonly used scheduling algorithms that can be implemented in the input port processors (IPPs) and output port processors (OPPs) of routers or main hosts are discussed in the next sections. First-In, First-Out SchedulerFigure 12.8 shows a simple scheduling scheme: first in, first out (FIFO). With this scheme, incoming packets are served in the order in which they arrive. Although FIFO is very simple from the standpoint of management, a pure FIFO scheduling scheme provides no fair treatment to packets. In fact, with FIFO scheduling, a higher-speed user can take up more space in the buffer and consume more than its fair share of bandwidth. FIFO is simple to implement from the hardware standpoint and is still the most commonly implemented scheduling policy, owing to its simplicity. With smart buffer-management schemes, it is possible to control bandwidth sharing among different classes and traffic. Delay bound of this scheduler, T q , is calculated based on the queueing buffer size, as follows: Equation 12.8 Figure 12.8. A typical FIFO queueing scheduler where K is the maximum buffer size, and s is the outgoing link speed. Certain control algorithms, RSVP, can be used to reserve the appropriate link capacity for a particular traffic flow. However, when high-speed links are active, tight delay bounds are required by real-time applications. Priority Queueing SchedulerThe priority queueing (PQ) scheduler combines the simplicity of FIFO schedulers with the ability to provide service classes. With various priority queueing, packets are classified on the priority of service indicated in the packet headers. Figure 12.9 shows a simple model of this scheduler. Lower-priority queues are serviced only after all packets from the higher-priority queues are serviced. Only a queue with the highest priority has a delay bound similar to that with FIFO. Lower-priority queues have a delay bound that includes the delays incurred by higher-priority queues. As a result, queues with lower priorities are subject to bandwidth starvation if the traffic rates for higher-priority queues are not controlled. Figure 12.9. A typical priority-queueing scheduler In this scheduling scheme, packets in lower-priority queues are serviced after all the packets from higher-priority queues are transmitted. In other words, those queues with lower priorities are subject to severely limited bandwidth if traffic rates for the higher-priority queues are not controlled. Priority queueing is either nonpreemptive or preemptive . In order to analyze these two disciplines, we need to define a few common terms. For a queue with flow i (class i queue), let » i , 1 / µ i , and i = » i / µ i be the arrival rate, mean service rate, and mean offered load (utilization), respectively. We also express a lower value of i for a higher-priority class. Non-Preemptive Priority QueuesIn nonpreemptive priority-queueing schemes, the process of lower-priority packets cannot be interrupted under any condition. Every time an in-service packet terminates from its queue, the waiting packet from the highest-priority queue enters service. This fact makes the system simple from the implementation standpoint. Let E [ T i ] be the mean waiting time for a packet in flow i (class i ) queue. This total queuing delay has three components, as follows:
Hence, E [ T q , i ] can be the sum of all these three components: Equation 12.9 The first component is computed by using the mean residual service time, r j , for a class j packet currently in service as: Equation 12.10 Using Little's formula, we can derive the second component, E [ T q , i ] 2 , by Equation 12.11 where E [ K q , j ] is the mean number of waiting packets and µ j is the mean service rate for class j packets. Since we can also write E [ T q , i ] = E [ K q , i ] / µ i , we can rewrite Equation (12.11) as Equation 12.12 Similarly, the third component, E [ T q , i ] 3 , can be developed by Equation 12.13 By incorporating Equations (12.10), (12.12), and (12.13) into Equation (12.9), we obtain Equation 12.14 Note that the total system delay for a packet passing queue i and the serverin this case, the server is the multiplexeris Equation 12.15 Recall that the E [ T i ] expression corresponds to Equation (11.22). Preemptive Priority QueuesA preemptive-priority queue is a discipline in which service in a lower-priority packet can be interrupted by an incoming higher-priority packet. Let E [ T i ] be the mean waiting time for a packet in flow i (class i ) queue. Figure 12.10 shows an example in which a class i packet has been interrupted three times by higher-priority packets. This total queueing delay has four components. The first three are identical to those for the nonpreemptive case. The fourth component, i , is the total mean completion time for the current class i packet when it is preempted in the server by higher-priority packets (classes i - 1 to 1). Therefore, by including i into Equation (12.15), we calculate the total system delay for a packet passing queue i and the server as Figure 12.10. Preemptive-priority queueing. A class i packet has been interrupted three times by higher-priority packets. Equation 12.16 During i , as many as » j i new higher-priority packets of class j arrive, where j ˆˆ{1, 2, ... i - 1}. Each of these packets delays the completion of our current class i packet for 1 / µ j . Therefore, i , which also includes the service time of the class i packet, as seen in Figure 12.10, can be clearly realized as Equation 12.17 From Equation (12.17), we can compute theta i as Equation 12.18 If we substitute i of Equation (12.18) into Equation (12.16), we obtain the total system delay for a packet passing queue i and the server: Equation 12.19 where E [ T q , i ] is the same as the one computed for the nonpreemptive case in Equation (12.14). Fair Queueing SchedulerThe fair-queueing (FQ) scheduler is designed to better and more fairly treat servicing packets. Consider multiple queues with different priorities. The fair queueing shown in Figure 12.11 eliminates the process of packet priority sorting. This improves the performance and speed of the scheduler significantly. As a result, each flow i is assigned a separate queue i . Thus, each flow i is guaranteed a minimum fair share of s/n bits per second on the output, where s is the transmission bandwidth, and n is the number of flows (or number of queues). In practice, since all the inputs (flows) may not necessarily have packets at the same time, the individual queue's bandwidth share will be higher than s/n . Figure 12.11. Overview of fair-queueing scheduler Assume that a j is the arriving time of packet j of a flow. Let s j and f j be the start and ending times, respectively, for transmission of the packet. Then, c j , as the virtual clock count needed to transmit the packet, can be obtained from c j = f j - s j , since s j = max( f i - 1 , a i ) . Then: Equation 12.20 We can calculate f j for every flow and use it as a timestamp. A timestamp is used for maintaining the order of packet transmissions. For example, the timestamp is each time the next packet is to be transmitted. In such a case, any packet with the lowest timestamp finishes the transmission before all others. Weighted Fair Queueing SchedulerThe weighted fair-queueing scheduler (WFQ) scheduler is an improvement over the fair-queueing scheduler. Consider the weighted fair-queueing scheme shown in Figure 12.12. For an n -queue system, queue i µ{1 ... n } is assigned a weight ‰ i . The outgoing link capacity s is shared among the flows with respect to their allocated weights. Thus, each flow i is guaranteed to have a service rate of at least Figure 12.12. Overview of weighted fair-queueing scheduler Equation 12.21 Given a certain available bandwidth, if a queue is empty at a given time, the unused portion of its bandwidth is shared among the other active queues according to their respective weights. WFQ provides a significantly effective solution for servicing real-time packets and non-real-time packets, owing to its fairness and ability to satisfy real-time constraints. Each weight, ‰ i , specifies the fraction of the total output port bandwidth dedicated to flow i . Assigning a higher weight to the real-time queues reduces delay for the real-time packets, so real-time guarantees can be ensured. These weights can be tuned to specific traffic requirements, based on empirical results. As mentioned, any unused bandwidth from inactive queues can be distributed among the active queues with respect to their allocated weights, again with the same fair share of Equation 12.22 where b(t) is a set of active queues at any time t . The delay bound in this scheme is independent of the maximum number of connections n , which is why WFQ is considered one of the best queueing schemes for providing tight delay bounds. As a trade-off to the effectiveness of this scheme, the implementation of a complete weighted fair-queueing scheduler scheme is quite complex. A version of this scheduler, the so-called weighted round- robin (WRR) scheduler, was proposed for asynchronous transfer mode. In WRR, each flow is served in a round-robin fashion with respect to a weight assigned for each flow i , without considering packet length. This is very similar to the deficit round-robin scheduler discussed next for fixed-size packets. Since the system deals only with same-size packets, it is very efficient and fast. The service received by an active flow during its round of service is proportional to its fair share of the bandwidth specified by the weight for each flow.
Deficit Round-Robin SchedulerIn weighted fair queueing the dependency on a sorting operation that grows with the number of flows is a concern for scalability as speed increases. In the deficit round-robin (DRR) scheduler, each flow i is allocated b i bits in each round of service, and b m is defined as the minimum bit-allocation value among all flows. Thus, we have b m = min{ b i }. In every cycle time, active flows are placed in an active list and serviced in round-robin order. If a packet cannot be completely serviced in a round of service without exceeding b i , the packet is kept active until the next service round, and the unused portion of b i is added to the next round. If a flow becomes inactive, the deficit is not accumulated to the next round of service and is eventually dropped from the node. Although DRR is fair in terms of throughput, it lacks any reasonable delay bound. Another major disadvantage of this technique is that the delay bound for a flow with a small share of bandwidth can be very large. For example, consider a situation in which all flows are active. A low-weighted flow located at the end of the active list has to wait for all the other flows to be serviced before its turn, even if it is transmitting a minimum-sized packet. Earliest Deadline First SchedulerThe earliest deadline first (EDF) scheduler computes the departure deadline for incoming packets and forms a sorted deadline list of packets to ensure the required transmission rate and maximum delay guarantees. The key lies in the assignment of the deadline so that the server provides a delay bound for those packets specified in the list. Thus, the deadline for a packet can be defined as Equation 12.23 where t a is the expected arrival time of a packet at the server, and T s is the delay guarantee of the server associated with the queue that the packet arrives from. |


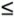
 1, state 0 can be connected to any state
1, state 0 can be connected to any state 
















EAN: 2147483647
Pages: 211