Network Load Balancing
NLB is Application Center's default option for redistributing IP requests among Web servers. In addition to balancing loads across a cluster, NLB also ensures high availability; if a member is taken offline or becomes unavailable, the load is automatically redistributed among the remaining cluster hosts.
Let's examine the NLB architecture in detail before looking at load balancing algorithms and configuration.
Network Load Balancing Architecture
NLB is a fully distributed IP-level load-balancing solution. It works by having every cluster member concurrently detect incoming traffic that's directed to a cluster IP address. (See Figure 5.1.) You can have several load-balanced IP addresses, and traffic to any IP address—except the dedicated, or management, IP address—on an NLB-enabled adapter will get load balanced.
NOTE
It's important to understand that NLB itself has no notion of a cluster or cluster members—these concepts are specific to Application Center. For the sake of documentation consistency we've used the terms cluster and member when dealing with NLB concepts and technology.
Low-Level Architecture and Integration
Application Center provides a tightly integrated interface to NLB by using Windows Management Instrumentation (WMI) to communicate with NLB and the network adapters through the Windows 2000 kernel and TCP/IP network layers. NLB runs as a network driver logically situated beneath higher-level applications protocols such as HTTP and FTP. As you can see in Figure 5.1, this driver is an intermediate driver in the Windows 2000 network stack.
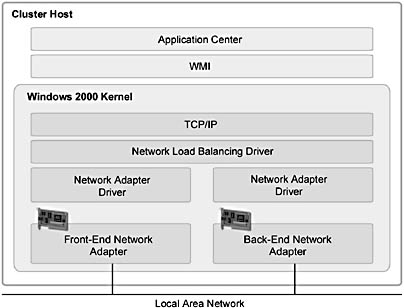
Figure 5.1 Low-level architecture for NLB as implemented by Application Center
As shown in Figure 5.1, the NLB driver can be bound to only one network adapter in Windows 2000. Figure 5.1 also illustrates how Application Center abstracts a significant amount of low-level network detail, which simplifies configuring and managing NLB on a cluster.
Application Center uses the NLB WMI provider to interact with NLB and fires WMI events for the cases shown in Table 5.1.
Table 5.1 WMI Events Related to Load Balancing
| Activity | Comment |
|---|---|
| Member starting to go offline | MicrosoftAC_Cluster_LoadBalancing_ServerOfflineRequest_Event |
| Member starting to drain | MicrosoftAC_Cluster_LoadBalancing_ServerDrainStart_Event |
| Member finished draining | MicrosoftAC_Cluster_LoadBalancing_DrainStop_Event |
| Member offline | MicrosoftAC_Cluster_LoadBalancing_ServerOffline_Event |
| Member starting to go online | MicrosoftAC_Cluster_LoadBalancing_ServerOnlineRequest_Event |
| Member online | MicrosoftAC_Cluster_LoadBalancing_ServerOnline_Event |
| Member failed, has left the cluster 1 | MicrosoftAC_Cluster_Membership_ServerFailed_Event |
| Member alive, has rejoined the cluster 1 | MicrosoftAC_Cluster_Membership_Server_Live_Event |
1. These are cluster membership events, rather than load balancing events
Network-Level Architecture
As indicated in Chapter 4, "Cluster Services," the front-end adapter on the controller has at least one static IP address that's used for load balancing.
This IP address is the cluster (or virtual) IP address. The cluster IP address—common to every cluster member—is where all inbound packets are sent. And, since the IP addresses on the front-end adapter are mapped to the same media access control (MAC in conceptual artwork) address, each member is able to receive the TCP packets. (See "Adding a Server" in Chapter 4.)
NOTE
IP address mapping to the same media access control address is only true for the default Unicast NLB mode that Application Center uses. This is not the case in a Multicast environment.
After receiving an incoming packet, each cluster host passes the packet up to the NLB driver for filtering and distribution using a hashing algorithm. Figure 5.2 shows the network level of the NLB architecture for a two-node cluster.
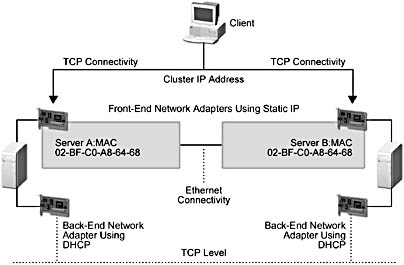
Figure 5.2 TCP and Ethernet architecture for an Application Center cluster
NLB Performance
NLB's architecture maximizes throughput by eliminating the need to route incoming traffic to individual cluster hosts. The NLB approach implements filtering to eliminate unwanted packets rather than routing packets—which involves receiving, examining, rewriting, and resending—to increase throughput.
During packet reception, NLB, which is fully pipelined, overlaps the delivery of incoming packets to TCP/IP and the reception of other packets by the network adapter driver. Because TCP/IP can process a packet while the NDIS driver receives a subsequent packet, overall processing is sped up and latency is reduced. This implementation of NLB also reduces TCP/IP and NDIS overhead and eliminates the need for an extra copy of packet data in memory.
During packet sending, NLB enhances throughput and reduces latency and overhead by increasing the number of packets that TCP/IP can send with one NDIS call.
See also: Appendix B, "Network Load Balancing Technical Overview," for detailed information about NLB performance and scalability.
Load Balancing Distribution
Load distribution on a cluster is based on one of three algorithms that are determined by the client affinity, which is part of the port rules that can be configured for the cluster.
No Affinity
In the case where no client affinity is specified, load distribution on a cluster is based on a distributed filtering algorithm that maps incoming client requests to cluster hosts.
NOTE
The load-balancing algorithm does not respond to changes in the load on each cluster host (such as CPU load or memory usage), but you can adjust load-balancing weights on a per-server basis. The other case in which the load distribution map is recalculated is when the cluster membership changes—which is to say a member is taken out of the load balancing loop, members are added or removed, or port rules are changed.
When inspecting an arriving packet, the hosts simultaneously perform a statistical mapping to determine which host should handle the request. This mapping technique uses a randomization function that calculates which cluster member should process the packet based on the client's IP address. The appropriate host then forwards the packet up the network stack to TCP/IP, and the other hosts discard it.
NOTE
The Single affinity setting assumes that client IP addresses are statistically independent. This assumption can break down if a firewall is used that proxies client requests with one IP address. In this scenario, one host will handle all client requests from that proxy server, defeating the load balancing. However, if No affinity is enabled, the distribution of client ports within a firewall will usually suffice to give good load balancing results.
The simplicity and speed of this algorithm allows it to deliver very high performance (including high throughput and low overhead) for a broad range of applications. The algorithm is optimized to deliver statistically even distribution for a large client population that is making numerous, relatively small requests.
Single Affinity
Single affinity is the default setting that the wizard uses when you create an NLB cluster. This affinity is used primarily when the bulk of the client traffic originates from intranet addresses. Single affinity is also useful for stateful Internet (or intranet) applications where session stickiness is important.
When Single affinity is enabled, the client's port number isn't used and the mapping algorithm uses the client's full IP address to determine load distribution. As a result, all requests from the same client always map to the same host within the cluster. Because there is no time-out value (typical of dispatcher-based implementations), this condition persists until cluster membership changes.
NOTE
If you have a stateful application, you should use Single affinity and enable request forwarding; otherwise, especially if you're using No affinity, you should not have request forwarding enabled for HTTP requests. For more information on request forwarding, refer to "Maintaining Session State with Network Load Balancing" later in this chapter.
Class C Affinity
As in the case of Single affinity, client port numbers aren't used to calculate load distribution. When Class C affinity is enabled, the mapping algorithm bases load distribution on the Class C portion (the upper 24 bits) of the client's IP address.
IP address basics
IP addresses are 32-bit numbers, most commonly represented in dotted decimal notation (xxx.xxx.xxx.xxx). Because each decimal number represents 8 bits of binary data, an IP address can have a decimal value from 0 through 255. IP addresses most commonly come as class A, B, or C. (Class D addresses are used for multi-cast applications, and class E are reserved for future use.)It's the value of the first number of the IP address that determines the class to which a given IP address belongs.
The range of values for these classes are given below, using the notation N=network and H=host for allocation.
Class Range Allocation A 1-126 N.H.H.H B 128-19 N.N.H.H C 192-223 N.N.N.H Using these ranges, an example of a class C address would be 200.200.200.0.
This ensures that all clients within the same class C address space map to the same host—which is why this setting isn't very useful for load balancing internal network, or intranet, traffic.
Class C affinity is typically used when the bulk of the client traffic originates on the Internet.
Figure 5.3 displays the Network Load Balancing Properties dialog box for the component that's configured for a front-end adapter. In this particular example, load balancing is configured for multiple hosts with Single affinity. By default, each member is configured to handle an equal load on the cluster. These settings are automatically created by Application Center when you create a cluster (or add a member) and enable NLB.

Figure 5.3 Affinity settings for an NLB-enabled network adapter
Convergence—Redistributing the Load on an NLB Cluster
There are several instances in which cluster traffic has to be remapped due to a change in cluster membership: when a member leaves the cluster and when a member joins the cluster. Either event triggers convergence, which involves computing a new cluster membership list—from NLB's perspective—and recalculating the statistical mapping of client requests to the cluster members. A convergence can also be initiated when several other events take place on a cluster, such as setting a member on/offline for load balancing, changing the load balancing weight on a member, or implementing port rule changes.
NOTE
Adjusting load balancing weight for a member or members makes it necessary to recalculate the cluster's load mapping, which also forces a convergence.
Removing a Member
Two situations cause a member to leave the cluster or go offline in the context of load balancing. First, the member can fail, an event that is detected by the NLB heartbeat. Second, the instance is explicit and is initiated by the system administrator, who can either take a member out of the load-balancing loop or remove it from the cluster.
The NLB heartbeat
Like Application Center, NLB uses a heartbeat mechanism to determine the state of the members that are load balanced. This message is an Ethernet-level broadcast that goes to every load-balanced cluster member.The default period between sending heartbeat messages is one second, and you can change this value by altering the AliveMsgPeriod parameter (time in milliseconds) in the registry. All NLB registry parameters are located in the HKEY_LOCAL_MACHINE\System\Current Control Set\Services\WLBS\Parameters key.
NLB assumes that a member is functioning normally within a cluster as long as it participates in the normal exchange of heartbeat messages between it and the other members. If the other members do not receive a message from a member for several periods of heartbeat exchange, they initiate convergence. The number of missed messages required to initiate convergence is set to five by default. You can change this by editing the AliveMsgTolerance parameter in the registry.
You should choose your AliveMsgPeriod and AliveMsgTolerance settings according to your failover requirements. A longer message exchange period reduces the networking overhead, but it increases the failover delay. Likewise, increasing the number of message exchanges prior to convergence will reduce the number of unnecessary convergence initiations due to network congestion, but it will also increase the failover delay.
Based on the default values, five seconds are needed to discover that a member is unavailable for load balancing and another five seconds are needed to redistribute the cluster load.
During convergence, NLB reduces the heartbeat period by one-half to expedite completion of the convergence process.
Server Failure
When a cluster member fails, the client sessions associated with the member are dropped. However, NLB does attempt to preserve as many of a failed member's client sessions as possible.
After convergence occurs, client connections to the failed host are remapped among the remaining cluster members, who are unaffected by the failure and continue to satisfy existing client requests during convergence. Convergence ends when all the members report a consistent view of the cluster membership and distribution map for several heartbeat periods.
Set Offline/Remove Server
An administrator can take a specific member offline either via the Set Offline command in the user interface or with the command-line command AC /LOADBALANCE. This action removes the member from the load-balancing loop, but it remains in the cluster. Application Center extends NLB's connection persistence by implementing draining. Draining describes a server state where existing TCP connections are resolved and the member does not accept any new TCP connection requests. Draining is primarily a feature that allows existing sessions to complete.
The default draining time is 20 minutes and is configurable via the Application Center user interface. (See Figure 6.6 in Chapter 6.)
NOTE
Whenever you initiate the action of either setting a member offline or removing it from the cluster, you are prompted to drain the member first. You can, of course, ignore this prompt and force completion of the action. See Figure 5.4.

Figure 5.4 Draining prompt when taking a member offline
Adding a Member
Convergence is also initiated when a new member is added to a cluster.
NOTE
In an Application Center NLB cluster, convergence takes place after the new member is online in the context of load balancing. If the new member is in the synchronization loop, it is set online after it's synchronized to the cluster controller; otherwise, it's set online immediately. The latter option is enabled by default and you can change it on the last page of the Add Cluster Member wizard.
After convergence is completed, NLB remaps the appropriate portion of the clients to the new member. NLB tracks TCP connections on each host, and after their current TCP connection completes, the new member can handle the next connection from the affected clients. In the case of User Datagram Protocol (UDP) data streams, the new host can handle connections immediately. This can potentially break client sessions that span multiple connections or make up UDP streams. This problem is avoided by having the member manage the session state so that it can be reconstructed or retrieved from any cluster member. The Application Center request forwarder manages the session state through the use of client cookies.
NOTE
The Generic Routing Encapsulation (GRE) stream within the Point-to-Point Tunneling Protocol (PPTP) is a special case of a session that is not affected by adding a new member. Because the GRE stream is contained within the duration of its TCP control connection, NLB tracks this GRE stream along with its corresponding control connection. This prevents disruption to the PPTP tunnel.
Network and NLB settings propagation
In order for an NLB cluster to function correctly, all cluster-wide NLB settings (for example, the IP address bound to the network adapter, default gateway settings, and client affinity) have to be replicated from the cluster controller to cluster members. Only network settings on the NLB-bound network adapter are replicated. If NLB is not used on the cluster, these settings are not replicated.In addition to the settings that have to be replicated, there are some NLB and network settings that need to be configured automatically on a per-node basis. The Application Center Cluster Service, rather than the replication drivers, handles these particular settings.
See also: Chapter 6, "Synchronization and Deployment."
EAN: N/A
Pages: 183