Enabling Highly Available and Scalable Application Services
Now that we have covered the architectural goals and elements of a business Web site, let's take our site model from Figure 1.3 and scale it out (Figure 1.5).
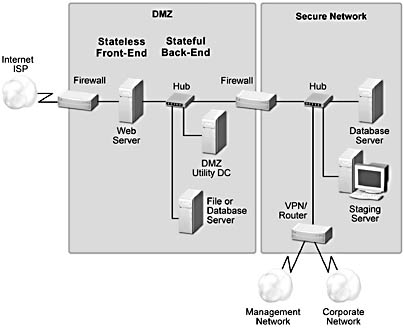
Figure 1.5 A typical n-tier Web site
Before we show you how Microsoft technologies can be used to scale this site and meet our architectural goals, we'll examine the different aspects of availability and scalability as well as the solutions that are currently available.
The Traditional Approach — Scaling Up
Availability and scalability are not new issues in the computing world; they've been around as long as we've used computers for business. The traditional approaches for handling these issues weren't really challenged until the microcomputer came into its own as a credible platform for hosting business applications.
Availability
There are several architectures that are used to increase the availability of computer systems. They range from computers with redundant components, such as hot swappable drives, to completely duplicated systems. In the case of a completely duplicated computer system, the software model for using the hardware is one where the primary computer runs the application while the other computer idles, acting as a standby in case the primary system fails. The main drawbacks are increased hardware costs—with no improvement in system throughput—and no protection from application failure.
Why is availability important?
In 1992 it was estimated that system downtime cost U.S. businesses $4.0 billion per year.1 The average downtime event results in a $140,000 loss in the retail industry and a $450,000 loss in the securities industry. These numbers were all based on computerized businesses BEFORE the Internet phenomenon.
Scalability
Scaling up is the traditional approach to scalability. This involves adding more memory and increasing the size or number of the disks used for storage. The next step in scaling up is the addition of CPUs to create a symmetric multiprocessing (SMP) system. In an SMP system, several CPUs share a global memory and I/O subsystem. The shared memory model, as it is called, runs a single copy of the operating system with applications running as if they were on a single CPU computer. These SMP systems are very scalable if applications do not need to share data. The major drawbacks are the physical limitations of the hardware, notably bus and memory speed, which are expensive to overcome. The price steps in moving from one to two, two to four, and four to eight microprocessors are dramatic. At a certain point, of course, a given computer can't be upgraded any further and it's necessary to buy a larger system—a reality that anyone who's owned a microcomputer can appreciate.
In terms of availability, the SMP approach does provide an inherent benefit over a single-CPU system—if one CPU fails, you have n more to run your applications.
Multiprocessing systems with redundant components
In February 2000, a quick survey of the mainstream manufacturers of high-end servers showed that an Intel-based server with some redundant components (for example, power supply and hot swappable disks) and four microprocessors averaged $60,000 for an entry-level server.
Scaling Out as an Alternative
The alternative to scaling up is scaling out, especially in the front-end tier, by adding more servers to distribute and handle the workload. For this to be effective, instead of increasing the capacity of a single server, some form of load balancing is necessary to distribute the load among the front-end servers. There are three typical load-balancing mechanisms that can be used: multiple IP addresses (DNS round robin), hardware-based virtual-to-real IP address mapping, and software-based virtual-to-real IP address mapping.
Multiple IP Addresses (DNS Round Robin)
Round robin is a technique used by DNS servers to distribute the load for network resources. This technique rotates the order of the resource record (RR) data returned in a query answer when multiple RRs exist of the same type for a queried DNS domain name.
As an example, let's use a query made against a computer that uses three IP addresses (10.0.0.1, 10.0.0.2, 10.0.0.3), with each address specified in its own A-type RR. The following table illustrates how these client requests will be handled.
Table 1.3 IP Address Returns with DNS Round Robin
| Client request | IP address return sequence |
|---|---|
| First | 10.0.0.1, 10.0.0.2, 10.0.0.3 |
| Second | 10.0.0.2, 10.0.0.3, 10.0.0.1 |
| Third | 10.0.0.3, 10.0.0.1, 10.0.0.2 |
The rotation process continues until data from all of the same-type RRs for a name have been rotated to the top of the list returned in client query responses.
Although DNS round robin provides simple load balancing among Web servers as well as scalability and redundancy, it does not provide an extensive feature set for unified server management, content deployment and management, or health and performance monitoring.
Hardware Solutions
Hardware-based solutions use a specialized switch or bridge with additional software to manage request routing. For load balancing to take place, the switch first has to discover the IP addresses of all of the servers that it's connected to. The switch scans all the incoming packets directed to its IP address and rewrites them to contain a chosen server's IP address. Server selection depends on server availability and the particular load-balancing algorithm in use. The configuration shown in Figure 1.6 uses hubs or switches in combination with a load-balancing device to distribute the load among three servers.
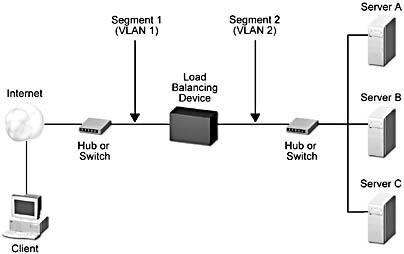
Figure 1.6 A load-balancing device used in conjunction with hubs or switches
Load-balancing devices in general provide more sophisticated mechanisms for delivering high performance load-balancing solutions than DNS round robin. These products are intelligent and feature-rich in the load-balancing arena—for example, they can transparently remove a server if it fails. However, they do not provide broad and robust Web-farm management tools.
Software Solutions
The initial software-based load-balancing solution provided by Microsoft was Windows NT Load Balancing Service (WLBS), also known as Convoy.
NOTE
Network Load Balancing (NLB) is an enhanced version of WLBS for the Windows 2000 server platform. NLB is only available with the Windows 2000 Advanced Server and Windows 2000 Datacenter versions of the operating system.
The essence of WLBS is a mapping of a shared virtual IP address (VIP) to the real IP addresses of the servers that are part of the load-balancing scheme. NLB is an NDIS packet filter driver that sits above the network adapter's NDIS driver and below the TCP/IP stack. Each server receives every packet from the VIP. NLB determines on a packet-by-packet basis which packets should be processed by a given server. If another server should process the packet, the server running NLB discards the packet. If it determines that the packet should be processed locally, the packet is passed up to the TCP/IP stack.
Load balancing is one aspect of a computing concept called clustering.
Clustering
Clustering is a computer architecture that addresses several issues, including performance, availability, and scalability. As is the case with other architectures we've covered, clustering is not a new concept. The new aspects are its implementation and the platforms that can take advantage of this architecture.
Cluster Overview
A cluster is a collection of loosely coupled, independent servers that behave as a single system. Cluster members, or nodes, can be SMP systems if that level of computing power is required. However, most clusters can be built by using low-cost, industry standard computer technology. The following features characterize clusters:
- The ability to treat all the computers in the cluster as a single server. Application clients interact with a cluster as if it were a single server, and system administrators view the cluster in much the same way: as a single system image. The ease of cluster management depends on how a given clustering technology is implemented in addition to the toolset provided by the vendor.
- The ability to share the workload. In a cluster some form of load balancing mechanism serves to distribute the load among the servers.
- The ability to scale the cluster. Whether clustering is implemented by using a group of standard servers or by using high-performance SMP servers, a cluster's processing capability can be increased in small incremental steps by adding another server.
- The ability to provide a high level of availability. Among the techniques used are fault tolerance, failover/failback, and isolation. These techniques are frequently used interchangeably—and incorrectly. See sidebar.
Fault Tolerance, Failover/Failback, and Isolation
Fault tolerance For server clusters, a fault-tolerant system is one that's always available. Fault-tolerant systems are typically implemented by configuring a backup of the primary server that remains idle until a failure occurs. At that time, the backup server becomes the primary server.Failover/Failback Failover describes the process of taking resources offline on one node, either individually or in a group, and bringing them back online on another node. The offline and online transactions occur in a predefined order, with resources that are dependent on other resources taken offline before and brought online after the resources on which they depend.
Failback is the process of moving resources back to their preferred node after the node has failed and come back online.
Isolation Isolation is a technique that simply isolates a failed server in a cluster. The remaining nodes in the cluster continue to serve client requests.
The different techniques used to provide a high level of availability are what distinguish two of the clustering technologies provided by Microsoft—Windows Clustering (formerly Wolfpack or Cluster Server), which implements failover/failback, and Application Center, which uses the isolation approach.
Both these technologies implement aspects of the "shared nothing" model of cluster architecture. (The other major clustering model is called "shared disk.")
Windows Clustering Shared Nothing Model
As implied, the shared nothing model means that each cluster member owns its own resources. Although only one server can own and access a particular resource at a time, another server can take ownership of its resources if a failure occurs. This switch in ownership and rerouting of client requests for a resource occurs dynamically.
As an example of how this model works, let's use a situation where a client requires access to resources owned by multiple servers. The host server analyzes the initial request and generates its own requests to the appropriate servers in the cluster. Each server handles its portion of the request and returns the information to the host. The host collects all the responses to the subrequests and assembles them into one response that is sent to the client.
The single server request on the host typically describes a high-level function—a multiple data record retrieve, for example—that generates a large amount of system activity, such as multiple disk reads. This activity and associated traffic doesn't appear on the cluster interconnect until the requested data is found. By using applications, such as a database, that are distributed over multiple clustered servers, overall system performance is not limited by the resources of a single cluster member. Write-intensive services can be problematic, because all the cluster members must perform all the writes and the execution of concurrent updates is a challenge. Shared nothing is easier to implement than shared disk, and scales I/O bandwidth as the site grows. This model is best suited for predominantly read-only applications with modest storage requirements.
However, this approach is expensive where there are large, write-intensive data stores because the data has to be replicated on each cluster member.
Partitions and packs
The shared disk and shared nothing concepts can also be applied to data partitions that are implemented as a pack of two or more nodes that have access to the data storage. Transparent to the application, this technique is used to foster high performance and availability for database servers.
Application Center 2000 Shared Nothing Model
Application Center takes the shared nothing idea a bit further; there is no resource sharing whatsoever. Every member in the cluster uses its own resources (for example, CPU, memory, and disks) and maintains its own copy of Web content and applications. Each member is, for all intents and purposes, a carbon copy (sometimes called a replica or clone) of the cluster controller. The advantage of this implementation of the shared nothing model is that if any node, including the controller, fails, the complete system, its settings, content, and applications, continue to be available when the failed server is isolated.
At this point you've probably begun to realize that in spite of the advances in development tools, building distributed applications that perform well, and are available and scalable, is not a trivial task. When load balancing and clustering is added to the n-tier application model, you have to start thinking in terms of cluster-aware applications.
TIP
Consider adding network-awareness to your list of application design criteria.
Cluster-Aware Applications
Although clustering technology can deliver availability and scalability, it's important to remember that applications have to be designed and written to take full advantage of these benefits. In a database application, for example, the server software must be enhanced to coordinate access to shared data in a shared disk cluster, or partition SQL requests into sub-requests in a shared nothing cluster. Staying with the shared nothing example, the database server may want to make parallel queries across the cluster in order to take full advantage of partitioned or replicated data.
As you can see, a certain amount of forethought and planning is required to build an application that will perform well and fully utilize the power of clustering technology.
Scaling Up vs. Scaling Out
Either scaling up or scaling out provides a viable solution to the scaling problem. There are pros and cons to both, and strong proponents of either strategy. Let's take a look at the issue of availability and fault tolerance, and then examine the economics of scaling.
High Availability
I don't think anyone will disagree that high availability and fault tolerance are good things to have. The question of which approach provides the best solution has to be considered in the context of the application, the risk and cost of downtime, and the cost of ensuring that the system will satisfy a business's availability requirements. (It's important not to confuse uptime with availability. Based on my own experience and that of other industry professionals, most lines of business systems can boast 99.9nn percent uptime. The problem is that they're not always available when they're needed.)
The 7-day/24-hour availability mantra is relatively new; it is one of the interesting consequences of the Internet phenomenon. It would seem that people around the world need access to information or have to be able to shop 24 hours a day, 7 days a week. Because the scaling up model is based on a single high-end system—and therefore, a single point of failure—some form of fault tolerance is needed to ensure availability. As noted in an earlier example, most high-end Intel-based server platforms have redundant power supplies, memory error checking mechanisms, and hot swappable components, such as disks.
In the hardware-based scale out model used by third-party load balancers, there is also a single point of failure, the load-balancing device itself. Figure 1.7 shows a fault-tolerant device configuration. This kind of approach to resolving the single point of failure conundrum is both complex and expensive to implement and maintain.
The software-based model provided by Application Center for scaling out does not have a single point of failure. High availability is achieved by having several identical servers available to service client requests. Because these servers are inexpensive, this approach to redundancy is cost effective. Furthermore, the more servers there are in a cluster, the lower the odds that all servers will be offline simultaneously. While performance may suffer if several servers go offline, the applications and services on the cluster remain available to the users. Of the various solutions, Application Center provides the highest level of availability for the most attractive cost.
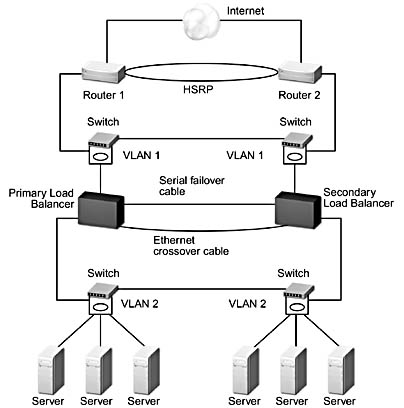
Figure 1.7 A fault-tolerant load-balancing device configuration
The Economics of Scaling
Prior to the release of Application Center, the economics of scaling was pretty straightforward.
If you had a single high-end server, it was simply a matter of upgrading it by adding more memory, additional CPUs, and so on. If the upgrade limit for the current server had been reached, you had to step up into a larger model. From this perspective, scaling up was expensive. However, operations costs remained, for the most part the same because of the simplicity of scaling up.
Scaling out by building Web farms that used DNS round robin or third-party load balancing tools was very economical from an equipment perspective. Single microprocessor, off-the-shelf servers could be used as Web servers. From the operations perspective, however, things weren't as good.
As more and more servers were added to a Web farm, the environment increased in complexity and decreased in manageability. There were a limited number of options for managing servers or their contents and applications as a group. Increased capacity was frequently accompanied by an exponential increase in operations costs.
Application Center, however, provides near-linear capacity scaling while keeping operating costs level. Figure 1.8 compares the traditional scale up model and Application Center's scale out model. The y-axis plots capacity and the x-axis shows operating cost behavior as capacity increases. This illustration also serves to demonstrate that scaling out provides a higher level of scalability than scaling up.
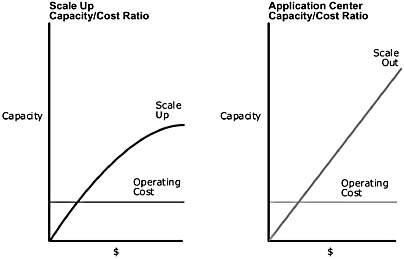
Figure 1.8 Comparison of the capacity and operating cost levels by using the scale up and scale out computing models
Scaling Out with Application Center
One of the main design objectives for Application Center is the reduction of operating costs by providing tools to manage groups of servers and their contents. The design philosophy is to automate as many activities as possible and provide an interface that enables a system administrator to manage a load-balanced cluster as a single system image. The end result is a solution that provides low-cost scalability and availability, while at the same time reducing and leveling operating costs.
Scaling n-Tier Sites with Microsoft Clustering Technology
Let's revisit the basic n-Tier site model (Figure 1.5) and show how Microsoft clustering technologies can be used to provide a highly available and scalable infrastructure for supporting business applications and services. Figure 1.9 uses the same topology and partitioning as Figure 1.5, except that load-balanced clusters and database clusters have been added to provide a higher level of availability and increase the site's capacity for handling client requests.
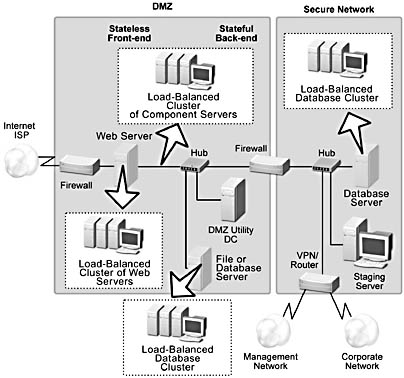
Figure 1.9 A scaled out n-tier site
As you can see, it's possible to create clusters anywhere in the computing infrastructure where availability and scalability is required. These clusters can be managed locally or remotely (by using a secure VPN connection to a cluster controller).
Notice that an intervening layer of load-balanced component servers is included in the sample site. Application Center supports Component Load Balancing (CLB) as well as NLB, so if the application design calls for it, components can be hosted on a separate load-balanced cluster. In some cases, more granularity in the partitioning of the business logic may be desirable (for security or performance reasons, for example). Support for CLB enables the developer to fully exploit object technology and build robust, fault-tolerant applications.
EAN: N/A
Pages: 183