4.7 Deploy to DB2
|
| < Day Day Up > |
|
4.7 Deploy to DB2
From the Deploy task, it is possible to perform the following actions:
-
Have MTK Create (or recreate) a local database
-
Deploy the converted objects into a local or remote database
-
Extract and store data from the source database
Figure 4-25 shows the deployment screen.
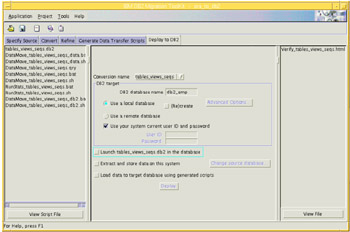
Figure 4-25: The MTK Deploy to DB2 task screen
4.7.1 Considerations
Before you start the DB2 deployment, you should consider:
-
Database creation: Manually or by MTK
-
Objects deployment strategy
-
Database access
MTK database creation
If you choose to deploy to a database that is remote to the system on which the toolkit is running, then you cannot choose to create a new database during deployment. The database must first be created on the remote system and registered in the local catalog. See CATALOG DATABASE in the DB2 Command Reference for more information
If you plan on deploying to a database that MTK will create locally, then the following information is important:
-
When MTK creates the database, a bufferpool with pages of size 32 KB and three tablespaces of the same size is created.
These provide enough space for the deployment of tables with any row length. Before launching the database into production, perform some performance tuning and adjust the size of the bufferpool as necessary.
-
When choosing MTK to create your database, only System Managed Tablespaces (SMS) can be created. If your database design requires that tables, indexes, or BLOB data be deployed into their own tablespaces, then you must use Database Managed Tablespaces (DMS). In this case, the database should be created (either locally or remotely) before the objects are deployed into it.
Deploying Objects: Extracting and deploying data
There are a few considerations for deploying objects and data depending on your environment and requirements:
-
When deploying to a local system, (Re)create must be selected unless you want to add the objects and data to what already exists on the database.
-
The converted objects and data can be deployed to DB2 at the same time or separately. For example, you might want to load the metadata during the day along with some sample data to test your procedures. Then, you can load the data at night when the database has been tested and when network usage is low.
-
You can deploy the database locally or to a remote system. No prerequisites exist for deploying the database locally. If you choose to deploy to a remote system, you can:
-
Specify that the IBM DB2 Migration Toolkit access the remote database directly. See the section "Considerations for remote database access" on page 116.
-
Copy the IBM DB2 Migration Toolkit and the project directory to the system running DB2 and then deploy the database locally.
-
-
If you are familiar with DB2 on operating systems other than Windows NT, the batch files can be modified to accommodate deployments on those systems. Ensure Java 1.3.0 is installed on the system, copy over the mtk.jar file and the batch files, and run the batch files.
-
Special consideration for large objects (BLOBS, CLOBs) should be made if there are many of them. When they are extracted, each individual LOB data type is put into its own file. Tables with many LOBs can create thousands of external files and supporting subdirectories for them. That means a file system can run out of directory space long before running out of actual mount point space. So, space planning for temporary data files during data movement of tables with these large objects should be carefully considered.
-
The Import and Load utilities use the memory area controlled by database parameter util_heap_sz. Medium to large table processing could benefit from a bump up in memory space if it is available on your server.
Considerations for remote database access
If you need to access database remotely during migration, please consider the following:
-
Make sure that the data extracted from the source database is of a type that is specific to the target DB2 database that is deployed in this step. Do not attempt to load the data into a database created by other means.
-
Ensure that you have not modified the conversion since the last time you have extracted data. You should extract and deploy the data only after the final conversion.
-
Make certain that any data that is being deployed is first extracted to the file system where the IBM DB2 Migration Toolkit is installed, and then it is loaded into DB2. If the table contains millions of rows, ensure the filesystem can accommodate the size of the largest object in the source database. On UNIX filesystems, you can modify the file size limit by using the ulimit command.
-
If you choose to deploy to a system that is remote to the system on which the toolkit is running, then you cannot choose to create a new database during deployment. The database must first be created on the remote system and registered in the local catalog. See CATALOG DATABASE in the DB2 Command Reference for more information.
-
Data cannot be loaded into LOB columns during remote deployment. The LOBPATH parameter in the LOAD or IMPORT command must refer to a directory on the DB2 server. You can load data into LOB columns by moving the generated scripts to the target machine and running them on the desired DB2 server (see Chapter 6., "Data conversion" on page 211).
-
During deployment, the connection to DB2 uses a Java native driver, not ODBC. If you encounter problems when connecting remotely (such as a "no suitable SQL driver" error), ensure the following directory and files are in the Java CLASSPATH:
-
%DB2PATH%/java/db2java.zip;
-
%DB2PATH%/java/runtime.zip;
-
%DB2PATH%/java/sqlj.zip;
-
%DB2PATH%/bin
-
4.7.2 Deployment strategy
The deployment information for the objects that were just converted is as follows:
-
The target database has been created and resides on a remote Linux server:
-
The database is designed with SMS table spaces. The tables will be stored in specified table space. The indexes and BLOB data will be stored in the table space where the associated table is placed.
-
The database has been cataloged, i.e., a connection can be made from the source system (AIX) to DB2 on the target system (Linux).
-
-
The Oracle data will be extracted onto the AIX machine where Oracle and MTK are installed.
-
All of currently converted objects will be created on the target DB2 UDB database.
-
The Oracle data will be loaded into DB2.
To follow the plan outlined above, we need to complete the required information on the Deployment screen:
-
DB2 database name
db2_emp
-
Use remote database
Selected
-
Use your system current user ID and password
Unselected
-
User ID
db2inst1
-
Password:
Enter your password
-
Launch tabs_views_seq.db2 in the database
Selected
-
Extract and store data on this system
Selected
-
Load data to target database using generated scripts
Selected
Figure 4-26 shows the Deploy to DB2 screen completed with all of the above information.
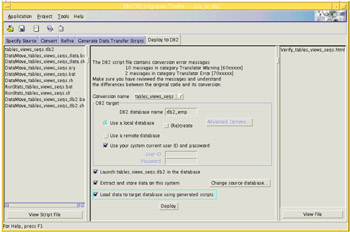
Figure 4-26: The Deploy to DB2 screen with deployment information entered
Once the deployment options are completed, we clicked the Deploy button and the deployment begins.
Deployment of Java and SQL User-Defined Functions
During deployment, MTK will automatically install JAVA and SQL User-Defined Functions (UDF). A schema called ORA8 will be specifically created to contain these functions. These UDFs are provided to simulate Oracle functions that do not have exact DB2 equivalents. The UDFs are programmed in SQL where possible but, in some cases, it is necessary to implement them in Java.
The installation of these functions in a database involves one to two files for every MTK target:
-
A script file (mtkora8.udf): containing a template for SQL UDF's source code
-
A JAR file (ora8UDFs.jar): containing the source code for Java UDFs
These files can be found in the directory where MTK was installed. That directory will also contain a script to drop all of the functions created by the mtkora8.udf script, mtkora8drop.udf, should it be necessary to drop these functions.
During deployment, the following takes place with these JAR and script files:
-
In the mtkora8.udf file
The JAVA CREATE FUNCTION statements are altered to specify the database under which the jar will be installed, such as:
Portion of the original file:
CREATE FUNCTION ORA8.jversion() RETURNS varchar(15) EXTERNAL NAME 'ora8.udfjar:com.ibm.db2.tools.mtk.mtkora8udf.Ora8UDFsv2.jversion'
After alteration:
CREATE FUNCTION ORA8.jversion() RETURNS varchar(15) EXTERNAL NAME 'ora8.db2_emp:com.ibm.db2.tools.mtk.mtkora8udf.Ora8UDFsv2.jversion'
The altered version of this file is then placed in the PROJECTS directory under a subdirectory corresponding to your project name, for example:
PROJECTS/MY_MTK_PROJECT/ mtkora8.udf.
-
The ora8UDFs.jar file is installed in the database with the following command:
CALL SQLJ.INSTALL_JAR('file:/home/db2inst1/mtk/ora8UDFs.jar','ora8.db2_emp')Once the jar file is installed on UNIX, it can be found in the following directory:
DB2INSTHOME/sqllib/function/jar/ORA8/
The DEPLOY_YourProjectName_Udf.log file will contain all the information regarding the success, or failure, of UDF deployment in your environment. It is recommended that this be examined to determine if UDF has been successfully deployed. A successful deployment will return the following message:
Creation of MTK UDFs... CALL SQLJ.INSTALL_JAR('file:/home/db2inst1/mtk/ora8UDFs.jar','ora8.db2_emp') DB20000I The CALL command completed successfully. If any other message is returned, you should verify the suitability of your DB2 Java environment.
4.7.3 Deployment results
When the deployment process has completed the Verification report opens. This report will give a clear indication of the status of your conversion project. It shows:
-
The number of objects in the source file.
-
The number of objects successfully deployed into DB2.
-
The number of objects missing from DB2.
Objects missing from DB2 appear in red; they usually indicate some error during deployment. A warning message is presented in purple and a successful deployment item is shown in black.
-
The number of foreign keys found in DB2
-
Information about Unique, Primary, and Check constraints
-
The name of an object in the source and the name as it appears in the DB2 database
-
The DB2 schema into which it was deployed
-
The type of object
-
Whether a specific object was successfully deployed into DB2
-
Whether data was successfully extracted from the source
-
Whether data was successfully loaded into DB2
Figure 4-27 shows part of the Verification report for our conversion example.
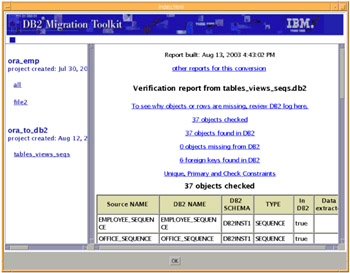
Figure 4-27: The Verification report
Additional information about the conversion may be found in the Deploy_your_file_name.log, or by choosing other reports for this conversion from the Verification report screen, or by selecting Tools ->Migration reports on the MTK menu bar. You can navigate to the reports for the current or previous migrations using the contents listing in the left frame of the browser window.
The name and information for each report is as follows:
-
Conversion summary report
The conversion summary report presents details on a particular conversion. You will most likely have many conversions during your migration of each database. You can view each of the conversion reports and compare the objects that were successfully converted, as well as various errors reported each time.
-
Translation error message reports
The error message reports detail the specific error messages found during each translation. One report presents the messages by object and the other by message. These reports can be handy when determining how to prioritize your work, for example, if the same error exists for many objects it might be a good idea to solve that problem first. Or, when viewing the messages by category, you might choose to overlook the translator information messages until the omissions are taken care of.
-
Estimate of table size report
The table size estimates are presented in this report to help you determine what kind of tablespace adjustments you might have to make.
-
Large statement warnings report
During conversion some statements are too long to be properly handled. The large statement warnings report lists each of the statements that cannot be converted.
-
Verification report and deployment log
The verification report and deployment log are generated to present to you any problems that might have occurred during deployment. If during deployment you specified in-context files, which contain objects that have not yet been deployed into DB2, both the report and log will show that the in-context files failed to deploy. Objects in in-context files are not deployed. This behavior is as designed.
|
| < Day Day Up > |
|