4.5 Distributed Software
4.5 Distributed Software
Before the Internet, computer systems mostly ran in isolation, and applications executed on a single computer. With local-area networks, and later the Internet, it is now common for applications and infrastructure programs to be partitioned across different hosts (Internet terminology for computing systems that operate at the edge of the network). As discussed in section 3.1, these distributed or networked computing applications have added communication, collaboration, and coordination as new application categories and as feature extensions in other applications.
If an application is distributed over hosts, the issue arises as to how to partition it, and why. Merely distributing an application does not by itself enable additional functionality—any functionality in a distributed environment can also be accomplished centrally. There are nevertheless some compelling reasons for distributing an application. First, performance may be improved when multiple hosts execute concurrently (see sections 2.3.1 and 3.2.6). Second, a centralized application must be administered centrally, whereas the administration and control of a distributed application can be partitioned. This is crucial for applications that span organizational boundaries, where close coordination is not feasible (see chapter 5), for example business-to-business e-commerce. Third, the security of an application is affected by its distribution (see section 3.2.8). For example, if an application must access crucial data assets of two organizations, each organization can exercise better control if each maintains its own data. Similarly, distributed data management can address privacy (see section 3.2.9) and ownership issues.
Because communication is a key differentiator of organizations and the society from the individual, the Internet has dramatically expanded the effect of computing on organizations, communities, society, and the economy (see section 3.1.4). It has also irrevocably changed software technology and the organization of the software industry (see chapter 7).
4.5.1 Network Effects in Distributed Applications
Distributed computing is substantially bringing forward direct network effects (see section 3.2.3) as a consideration and constraint on the software industry. Software has always been influenced by indirect network effects: the greatest information content and application availability flow to the most widely adopted application, and software developers flow to the most popular languages.
Direct network effects have a quantitatively greater reach and effect, however. The reality (pre- and post-Internet) is that the market provides a diversity of technologies and platforms; that is what we want to encourage. Previously, the major categories of computing (see table 2.3) coexisted largely as independent marketplaces, serving their own distinct needs and user communities. In addition, different organizations established their own procurement and administrative organizations and procedures. Before the Internet, the market was segmented for computing across platforms and organizations. Each supplier and each platform emphasized its own differentiated group of uses and functions. Indirect network effects favored technologies and platforms that gained larger acceptance, but the suppliers offering these differentiated solutions could otherwise mostly ignore one another.
With the Internet, users want to participate in applications that are distributed, like e-mail, information access and sharing, and coordination. Many of these applications exhibit a direct network effect: the value of the application depends on its intrinsic capabilities and also on the number of adopters available to participate. Users want these applications to work transparently with many technologies and platforms, and across organizational and administrative boundaries. Distributed computing applications that targeted a single platform were put at a disadvantage. Fragmented and independent markets became dependent, and users who once cared little about other users' computing platforms and applications now want shared applications.
Example The telecommunications industry has always dealt with direct network effects. Users in one organization want to converse with users in other organizations even if they have chosen different phone suppliers. With the Internet, the software industry was put in a similar situation.
One approach to meeting this new requirement would be to simply start over from scratch. This clearly isn't practical with sunk costs that are huge for both suppliers and customers, as well as switching costs that are substantial for both. Ways had to be found to incrementally modify and extend the existing hardware and software infrastructure to meet the new requirements. Fortunately, the flexibility of software and the declining importance of efficiency observed by Moore's law were enablers.
Example A virtual machine can be added to existing platforms, turning them into compatible environments. The added runtime processing of the virtual machine, while a consideration, may be far outweighed by the benefits and mitigated by the increasing performance observed by Moore's law (see section 2.3).
The transition to an infrastructure that meets these modern needs is not complete, but good progress has been made.
4.5.2 Internet Interoperability
The inspired vision of the Internet inventors was to connect heterogeneous computing platforms, allowing them to communicate with one another in common applications. They certainly could not have anticipated the results we see today, but they were confident that this capability would lead to interesting research opportunities and new distributed applications. Allowing communication falls far short of what is needed to achieve distributed computing over heterogeneous platforms, but it is a necessary first step. How the Internet pioneers approached this problem is instructive because it suggests solutions to larger problems. They conceptualized an hourglass architecture (see figure 4.6) that had only one waist at the time; we have added a second based on hindsight.
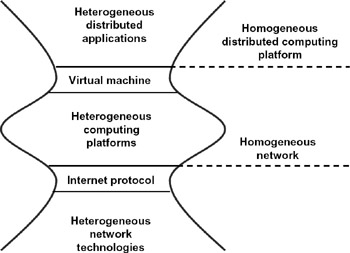
Figure 4.6: Internet hourglass architecture extended to processing.
The bottom waist of the hourglass is the internet protocol (IP). Before the Internet, there were distinct local-area networking (LAN) technologies. These existing LANs could have been replaced with new wide-area-network-compatible LANs. Instead, the Internet inventors defined a standard way to interconnect these existing (and future new) LANs by a new wide-area backbone network. Building on existing LANs was a major market success.[20]
Example The major competitors at the time were Ethernet and the IBM Token Ring. Since then, there has been continuing innovation, including a succession of faster and faster Ethernets, Ethernet switching, and several wireless networking solutions, including the IEEE 802.11b wireless LAN standard. These innovations are consistent with the requirement of Internet compatibility.
IP was the standard way for LANs to be concatenated through the Internet backbone, allowing hosts on different hosts to communicate. The solution required a piece of equipment connected to the LAN (called a gateway) that translates from internal LAN data and addressing formats to and from the common representation used in IP, and similar translation equipment added to each of the host operating systems. To avoid impeding technological progress in networking, the IP designers tried to be forward-looking to capture capabilities needed by future LAN technologies.
The virtual machine infrastructure described in section 4.4.3 can be interpreted in a similar light. It provides a common representation for programs (rather than data traversing the network) that allows them equal access to heterogeneous platforms. It is a second waist in the hourglass shown in figure 4.6, allowing heterogeneous platforms to interact with application programs (whereas the IP waist allows them to communicate with one another) in a standard way.
The hourglass approach does have a couple of drawbacks. It introduces processing overhead and sometimes added equipment cost (e.g., for gateways). Most important, if the designers of the waist are not sufficiently forward-looking in anticipating future needs, there is a danger that the waist may become a bottleneck, introducing restrictions that cannot be bypassed other than by replacement. Extensions to the waist (sometimes a sign of middle age) are no problem, but changes to the waist have remifications that spread far and wide.
Example The original designers of IP, not anticipating how successful the Internet would become, gave it too few distinct host addresses (about four billion).[21] The latest version of IP (version six) dramatically increases the number of addresses (unfortunately this is a change rather than an extension) along with a number of extensions. Since it is impractical to deploy a new version of IP instantaneously over the many nodes in an operational network, the design of a new version is greatly complicated by the need for backward compatibility and version coexistence.
4.5.3 Client-Server and Peer-to-Peer Architectures
One basic architectural question in distributed computing is why and how to partition an application across hosts. There are a number of considerations here (Messerschmitt 1999c), representative examples being performance, administration, and security:
-
Performance. Today most users access applications using a dedicated desktop host: a personal computer or workstation. Often the part of the application that interacts directly with the user is allocated to this dedicated computer so that the delay performance characteristics are improved (see section 2.3.1). Many applications support multiple users, and scalability is a concern for the operator. Scalability refers for the feasibility of expanding the number of users by adding equipment at a cost that grows no more than linearly (increasing returns to scale, in economics terms). Scalability usually requires more hosts and associated networking resources, so that the application becomes distributed.
-
Administration. Many applications have administrative responsibility shared across organizations (e.g., business-to-business e-commerce). The application will be partitioned according to administrative responsibility. Today recurring salary costs are the major consideration, so it often makes sense to provision more hosts according to administrative convenience.
-
Security. This is an important consideration in the partitioning of applications (see section 3.2.8 and chapter 5). Where data are sensitive or constitute an important organizational asset, they must be isolated from threats and protected against loss. A dedicated host (often a mainframe), isolated from the other hosts and the public network, will improve security.
Two distributed computing architectures that predominate today, sometimes in combination, are client-server and peer-to-peer (see figure 4.7). In client-server there is an asymmetry of function: the server specializes in satisfying requests, and the client specializes in initiating requests. The application communicates in a starshaped topology of communication, with each client communicating with the server and the server communicating with all clients. In a peer-to-peer architecture, there is a symmetry of function, with all hosts both initiating and satisfying requests for one another. (In effect, each host acts as both a client and a server.) Communication many occur between any pair of hosts, so the communication topology is fully connected. (Often reality is more complex than depicted here; for example, an application may involve multiple servers, or a peer-to-peer architecture may also incorporate a server.)
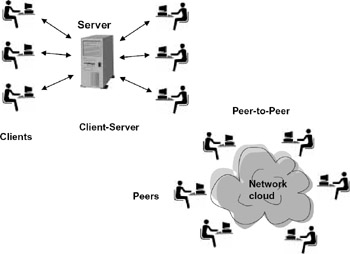
Figure 4.7: Client-server and peer-to-peer architectures are distinguished by their symmetry or asymmetry of function and by their interconnection topology.
Example The Web emphasizes a client-server architecture, with the Web server satisfying requests for Web pages initiated by clients (desktop computers in the hands of users). Napster, a popular music-sharing service that was shut down by the courts because of copyright law violations, emphasized a peer-to-peer architecture. The users' computers communicated directly with one another to share music files, and at any give time a computer might have been sending (acting as a server) or receiving (acting as a client). In these examples, aspects of the architecture violate the "pure" architectural model: Web servers may communicate with one another in a peer-to-peer fashion (this predominates in: Web services; see chapter 7), and some file-sharing applications like Napster and Groove include a centralized directory of all the files stored on users' PCs.
Client-server and peer-to-peer architectures are associated with very different business models. It is important to distinguish between the business model of the operators of an application and the business model of the software suppliers (see chapters 5 and 6).
There is a direct correspondence between these two architectures and indirect and direct network effects (see figure 3.3). The operator of a client-server application will typically put up a server with valuable services and content and hope that users will come. The intrinsic value of the services and content will attract the early users, who are not directly affected by the lack of other users. (A notable exception is community features, like discussion forums and e-mail, where the number of other users is an issue.) As the number of clients grows, more investment can be made in upgrading the services or adding content. Also, a large number of users can create congestion (a negative externality), and as a result scalability is an important issue in the management of the application. Within a single organization, coordinated decisions can be made about investing in client and servers, the number of users can be better anticipated, and investments in content can be made accordingly. Hence, network effects are less an issue.
The challenges for suppliers of a client-server application are different. For a public application they will typically distribute client software directly to users. A common business model is to distribute client software free, resulting in more clients, which encourages operators to pay for the server software. One can imagine two related business models for complementary products in the material world: "giving away the razor to sell razor blades" and "giving away razor blades to sell the razor." In the material world, giving away razor blades doesn't make much sense because the aggregate blades consumed by a given razor cost the supplier much more than the razor. In the world of software, giving away client software (analogous to giving away blades) is sensible because of low replication and distribution costs.[22]
Example RealNetworks distributes basic client software (its RealPlayer for playing streaming audio media) free but charges for complementary server software (compressing and streaming audio media) and for premium client software with additional features. By enlarging its user base through free distribution and advertising, it encourages the sale of its server and premium software. Adobe follows a similar strategy with its Acrobat document format, distributing a reader free but selling authoring tools. Microsoft provides free readers for its Excel, Word, and Power-Point formats as well as a free media player.
An obstacle in distributed applications that must work across administrative domains (a public market with individual consumers each administering their own computers is an extreme example) is the distribution of the necessary software. If the users have to install special software, even if it is free, this is an obstacle to overcome. There is the time and trouble of going through the installation process, the disk space consumed, and so on. One innovation of the Web was to establish a single client software (the Web browser) incorporated into a number of client-server applications. This software can even be extended using mobile code (see section 4.5.5). Operators of Web servers benefit from a ready supply of users able to access their server applications without special software installation.
An additional factor favoring client-server is centralized administration of the application on the server. Especially if the client software is standard (like a Web browser), many users prefer to place the administrative responsibility on someone else. This is also a driver for the application service provider model that outsources operations of an application to a service provider (see chapter 6).
Peer-to-peer establishes itself in a public market in a very different manner. Since each peer includes full application functionality, not merely the user interface elements, users always have to install special software (unless mobile code is used). If the supplier chooses to charge for the software, users bear this cost, and suppliers have no opportunity for revenue from complementary server software. Early adopters are deterred by the lack of other users. These direct network effects and adoption costs largely explain the preponderance of the client-server model today, even for applications (like community-based applications) that could be realized using peer-to-peer.[23]
4.5.4 Network Software Distribution
Since software programs are represented by data, they can be distributed over a network. A network is an attractive distribution channel, with low cost (no physical media to manufacture and transport) and low delay (low transport delay relative to physical media). This significantly affects the business model, transcending even the cost advantages:
-
One of the greatest advantages of network software distribution is psychological: the power of instant gratification. Experience has shown that purchase is encouraged by avoiding the delay between purchase and use. This was a significant factor in the popularity of the personal computer (which reduced the delay in acquiring and using applications relative to some earlier mainframe and time-sharing models) (see table 2.3).
-
By reducing adoption cost and delay, the startup obstacle of direct network effects is somewhat mitigated. For example, a peer-to-peer architecture becomes easier to establish in spite of its requirement for special software. Not surprisingly, peer-to-peer applications were rare before network distribution.
-
Software service releases (fixing defects but not adding new features; see chapter 5) can be distributed easily and quickly, and even automated. Before network distribution, service releases were rare in consumer applications and, some would say, have reduced the number of defects in earlier releases.
-
Similarly, upgrades (adding new features and fixing defects) are easier and cheaper to distribute. This is especially valuable for distributed software, where interoperability must be maintained across different hosts—an obstacle to upgrades, which may require simultaneous upgrade to two or more hosts to provide full feature flexibility. Network distribution mitigates these problems.
Today, it is common to make the first sale of consumer software by physical media, in part for rights management reasons and in part because of long download times over the network. As discussed in section 2.1.2, information and software distributed in digital form are subject to low-cost replication and redistribution. Rights management techniques (deterring distribution to other users that violates a copyright; see chapter 8) like copy protection are more effective on physical media. This is less an issue with upgrades, which need a successfully installed application as a starting point.
4.5.5 Mobile Code
Traditionally software is semipermanently installed on each computer, available to be executed on demand. With mobile code, the idea is to opportunistically transport a program to a computer and execute it there, ideally transparently to the user and without explicit software installation. This can mitigate adoption costs and network effects by transporting and executing applications in a single step. One advantage in distributed applications is that mobile code can ensure a single version of the code everywhere, bypassing interversion interoperability problems. Mobile code can dynamically move execution to the most advantageous host, for example, near the user (enhancing responsiveness) or to available processing resources (enhancing scalability).
Mobile code must overcome some challenges (see section 4.4). One is portable execution and providing a preinstalled platform that allows mobile code to access resources such as files and to display in the same way on different machines. Another is enforcing a set of (usually configurable) security policies that allow legitimate access to resources while preventing rogue code from causing damage. A final one is protecting the mobile code (and the user it serves) from rogue hosting environments. (Today, this last issue is an open research problem.)
In some circumstances, it is advantageous for a program to actually move between processors during the course of its execution. This is called a mobile agent and requires that the program carry both data[24] and code along from host to host. Mobile agents have applications in information access and in negotiation but also pose even more security and privacy challenges.
4.5.6 The Network Cloud and Its Future
Today's infrastructure for distributed applications includes three primary elements:
-
Processing resources to support the execution of applications and storage resources for retaining data over time.
-
Infrastructure software providing various processing-based services to the application. This includes the operating system as well as possibly a virtual machine and other middleware.
-
The network, which allows hosts to communicate with one another by sending packets of data. The network is thought of as a cloud in that what goes on within the network to realize the communication services it provides is largely irrelevant to applications: they care about the reliability of delivery and delay in the arrival of packets and nothing else.
As illustrated in figure 4.8, infrastructure is evolving toward making available to applications the processing and storage resources within the cloud.[25] This moves in the direction of a utility model for infrastructure, in which applications can draw upon the full suite of processing, storage, and communication capabilities shared among many users and applications (see chapter 9). This more readily accommodates uncertainties or irregularities in the required resources.
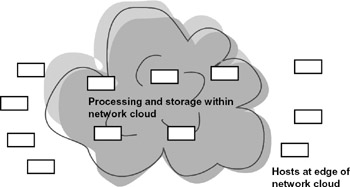
Figure 4.8: The future network cloud will include processing and storage as well as connection services made available to applications.
Why is this useful? First, as discussed in section 4.4.1, infrastructure is expanding to provide many useful capabilities to applications, some of which require processing and storage resources within the cloud.
Example Inktomi and Akamai offer a distributed caching service for the Web. Their servers are placed within the cloud in strategic locations close to users, and they temporarily store Web content that is accessed repeatedly by those users. The two companies pursue very different business models. Inktomi sells these caches to Internet service providers, who can then reduce the delay of frequently accessed Web pages (giving them competitive advantage over other providers) and reduce network traffic (lowering costs). Akamai deploys these caches around the world and then sells caching services to information providers, who gain competitive advantage over other information providers through lower delay accesses to users.
There are many capabilities like caching that would be useful to some or all applications; a partial list is given in table 4.3.
| Capability | Description |
|---|---|
| | |
| Security | Support common security needs of applications, like identification, authentication, confidentiality, authorization and access control. |
| Performance | Enhance the performance and scalability of applications, such as caching or adaptive and distributed resource management. |
| Location | Help applications find needed resources, through directory, naming, and location services. |
| New networking services | Support services, such as multicast or global event notification, not currently provided by the network. |
| Reliability | Help applications achieve reliability and availability, for example, by supporting fault detection and reconfiguration. |
| Quality of service | Support end-to-end quality-of-service objectives and guarantees not currently available from the network. |
| Mobile code | Support mobile code dynamic downloading and security. |
| Mobility | Support mobility of devices and users, for example, allowing applications to be location transparent. |
| Information representations | Support standard structured data types (XML, audio, video) widely needed by applications. |
| Accounting | Support scalable usage accounting for processing, storage, and communication. |
| Source: NSF (National Science Foundation) (2001). | |
Another reason for including processing and storage within the network cloud is that this opens up alternative business models for the operation of applications. For example, the operator of an application may want to make use of processing and storage resources provided by a utility rather than buying or leasing and operating them itself. This has long been the dominant business model for networking services,[26] and it is conceptually a small step to extend this to processing and storage.
Example The Microsoft .NET MyServices project (formerly code-named Hailstorm) aims to deliver a variety of Web services that provide services within the cloud, including authentication (Passport service) and storage.
[20]Some competing networking technologies like Frame Relay and Asynchronous Transfer Mode required that a new LAN infrastructure be deployed. By the time they rolled out, the Internet had become strongly established and was benefiting from the positive feedback of direct network effects.
[21]In fairness to those designers, providing more addresses requires more address bits in the header of each packet, reducing network efficiency. Four billion sounds sufficient in a world with a population of about six billion, but in fact the administrative realities of allocating blocks of addresses to organizations result in many unused addresses, and many Internet addresses are associated with unattended devices rather than people. The telephone network is experiencing a similar problem with block allocation of area codes to areas of widely varying populations.
[22]Not too much significance should be attached to this razor blade analogy because of two major differences. Razor use does not experience significant network effects, and both razors and blades are sold to the same consumers. In fact, we have not been able to identify a close analogy to client-server complementarity in the material world.
[23]There are difficult technical issues to overcome in peer-to-peer as well. For example, many hosts have dynamically assigned network addresses to aid in the administration of address resources. This is not a problem with clients, which normally initiate requests, but it is an obstacle for peers and servers, which must be contacted. Static address assignment is feasible for servers but likely not for (a large number of) peers.
[24]The data generated by a program that summarizes its past execution and is necessary for its future execution is called its state. A mobile agent thus embodies both code and state.
[25]The network cloud already has considerable processing and storage resources. However, these resources support embedded software that operates the network, and they are not made available to applications directly.
[26]Communication links require right-of-way, so they are a natural target for the utility model. It is not practical for operators, even large corporations, to obtain their own right-of-way for communication facilities. The sharing of these links with the provisioning of switches is a natural extension. Thus, it is to be expected that networking would adopt the utility model first.
EAN: 2147483647
Pages: 145