12.2 MVA Development
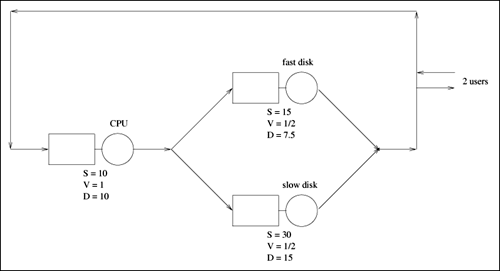
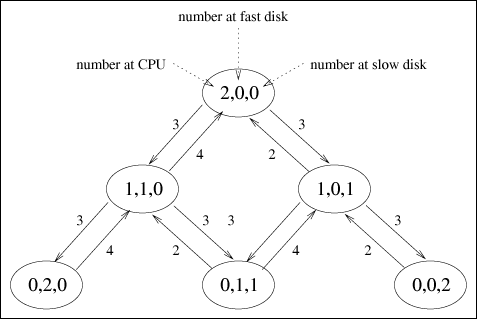
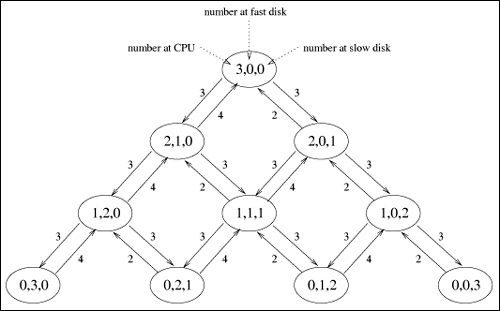
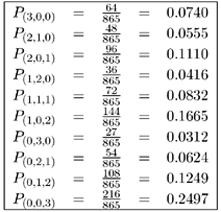
| Previous Paradigm Revisited: Reconsider the database server example from the previous chapter, whose high-level diagram is reproduced in Figure 12.1. Figure 12.1. Database server example revisited. The mean service time (S) per visit, the average number of visits (V) per transaction, and the total demand (D = S x V) per transaction is indicated for each device. The underlying Markov model is reproduced in Figure 12.2. By solving the six balance equations, the steady state probabilities were found to be: Figure 12.2. Markov model of the database server example (2 customers). From these probabilities, other useful performance metrics can be easily derived. For example, the average number of customers at the CPU is a simple weighted sum of the above probabilities. That is, there are two customers at the CPU in state (2, 0, 0) with probability 16/115, one customer at the CPU in state (1,1,0) with probability 12/115, one customer at the CPU in state (1,0,1) with probability 24/115, and no customers at the CPU in the remaining three states. Therefore, the average number of customers at the CPU is: Similarly, the average number of customers at the fast disk is: and the average number of customers at the slow disk is: The sum of these three numbers, 0.5913+0.4174+0.9913 = 2.0000, accounts for the two customers in the system. The utilization of each device can also be easily calculated knowing the steady state probabilities. For instance, the CPU is utilized in states P(2,0,0), P(1,1,0), and P(1,0,1) and is not utilized (i.e., is idle) in the remaining three states, where no customers are at the CPU. Therefore, the utilization of the CPU is: Likewise, the utilization of the fast disk is: and the utilization of the slow disk is: [Important sidenote: Since the slow disk is half as fast as the fast disk and since it is equally likely to find the required files on either disk, the demand (i.e., D) placed on the slow disk (i.e., 15 seconds) is twice as much as on the fast disk (i.e., 7.5 seconds). That is, a typical customer spends twice as much time in service at the slow disk than it does at the fast disk. It is no coincidence, therefore, that the utilization of the slow disk is twice that of the fast disk. Similarly, a typical customer spends (2/3)rds the amount of time (i.e., D = 10 seconds) at the CPU than it does at the slow disk (i.e., D = 15 seconds). The speed of the CPU is three times faster than the slow disk (i.e., a typical visit to the CPU lasts for 10 seconds as opposed to 30 seconds per visit at the slow disk), but the CPU gets twice as many visits as the slow disk because the files are equally spread over the two disks. Since the demand at the CPU is (2/3)rds that of the slow disk, its utilization, 0.4522 is, likewise, (2/3)rds that of the slow disk, 0.6783. Device utilizations are in the same ratio as their service demands, regardless of number of customers in the system (i.e., the system load).] Once device utilizations are known, device throughputs follow directly from the Utilization Law presented in Chapter 3. Device i's throughput, Xi, is its utilization, Ui, divided by its service time, Si. Thus, the throughput of the CPU is 0.4522/10 = 0.0452 customers per second, or 2.7130 customers per minute. Likewise, the throughput of each disk is 1.3565 customers per minute. This is consistent since the throughput of the CPU is split evenly between the two disks. Knowing the average number of customers, ni, at each device and the throughput, Xi, of each device, the response time, Ri, per visit to each device is, via Little's Law, the simple ratio of the two, Since a typical customer's transaction visits the CPU once and only one of the disks (with equal likelihood), the overall response time of a transaction is a weighted sum of the individual device residence times. Thus, a transaction's response time is 1 x 13.08 + 1/2 x 18.46 + 1/2 x 43.85 = 44.24 seconds. A summary of the relevant performance measures is presented in Table 12.1. Now consider the same database server example, but with three customers instead of two. The associated Markov model is an extension of Figure 12.2 and is illustrated in Figure 12.3. The ten balance equations (plus the conservation of total probability equation) are shown in Table 12.2, the steady state solution to the balance equations is shown in Table 12.3, and the associated performance metrics are given in Table 12.4. These are straight-forward extensions of the case with two customers and are left as exercises for the reader. [Sidenote: As a consistency check on the performance metrics given in Table 12.4, the sum of the average number of customers at the devices equals the total number of customers in the system (i.e., three). Also, the utilization of the CPU is (2/3)rds that of the slow disk, and the utilization of the slow disk is twice that of the fast disk (i.e., the utilizations remain in the same ratio as their service demands). The throughputs of the disks are identical and sum to that of the CPU.]
The Need for a New Paradigm: This technique of going from the two customer case to the three customer case (i.e., state space extension, balance equation derivation, solution of the linear equations, interpretation of the performance metrics) does not scale as the number of devices and the number of customers increases. A new paradigm of analyzing the relationships between the performance metrics is required. As an example, consider the relationship between the residence time at the CPU with three customers (i.e., 15.91 seconds) to the average number of customers at the CPU with two customers (i.e., 0.5913). Given that there are three customers in the network, at the instant when a customer arrives at the CPU, the average number of customers that the arriving customer sees already at the CPU is precisely the average number of customers at the CPU with two customers in the network. (This is an important result known as the "Arrival Theorem".) Therefore, in a network with three customers, an arriving customer at the CPU will expect to see 0.5913 customers already there. Thus, the time it will take for the newly arriving customer to complete service and leave the CPU (i.e., its residence time) will be the time it takes to service those customers already at the CPU plus the time it takes to service the arriving customer. Since the average service time per customer at the CPU is 10 seconds, it will take an average of 10 x 0.5913 seconds to service those customers already at the CPU, plus an additional 10 seconds to service the arriving customer. Therefore, the residence time is 10(1+0.5913) = 15.91 seconds. Figure 12.3. Markov model of the database server example (3 customers). This "discovered" relationship can be generalized. Letting Ri(n) represent the average response time per visit to device i when there are n customers in the network, letting Si represent the average service time of a customer at device i, and letting Thus, knowing the average number of customers at a device when a total of n 1 customers are in the system, the response time at the device with n customers is a simple (i.e., one addition and one multiplication) calculation. Therefore, the response time at the fast disk, when there are three customers in the network, is the product of its service time (i.e., 15 seconds) and the number of customers at the disk (i.e., the arriving customer, 1, plus the number of customers at the disk when there are only two customers in the network, 0.4174), namely 15(1 + 0.4174) = 21.36 seconds. Likewise, the residence time at the slow disk is 30(1 + 0.9913) = 59.74 seconds.
Now consider overall system response time. For a given number of customers in the network (i.e., n) and a given number of devices (i.e., K), then knowing the average number of visits that each customer makes to each device (i.e., the Vi's) and the average time spent at each device per visit (i.e., Ri(n)), the overall response time, R0(n), is simply the sum of the residence times In the database server example, with three customers, the residence times at the three devices (i.e., CPU, fast disk, and slow disk) are 15.91, 21.26, and 59.74 seconds, respectively. The number of visits to each of these devices per transaction is 1.0, 0.5, and 0.5, respectively. Thus, the overall response time is (1.0 x 15.91) + (0.5 x 21.26) + (0.5 x 59.74) = 56.41 seconds. To summarize so far, knowing only the average number of customers at each device with two customers, the device residence times when there are three customers in the network can be quickly derived. Knowing these residence times leads directly to the overall response time. Now consider overall system throughput. Little's Law indicates that the average number of customers in the system (i.e., n) is the simple product of system throughput, X0(n), and system response time, R0(n). Thus, from which the individual device throughputs can be found using the Forced Flow Law, Thus, in the database server example, with three customers, overall system throughput is X0(3) = 3/R(3) = 3/56.41 = 0.0532 customers per second, or 3.1908 customers per minute. With the Vi's being 1.0, 0.5, and 0.5 for the CPU, fast disk, and slow disk, respectively, their individual device throughputs are 3.1908, 1.5954, and 1.5954 customers per minute. To update the summary to this point, knowing only the average number of customers at each device with n 1 customers, the device residence times when there are n customers in the network can be quickly derived. Knowing these residence times leads directly to the overall response time, which, in turn, leads directly to the system and individual device throughputs. From here, the device utilizations follow from the device throughputs via the Utilization Law, The final piece is to find the average number of customers at each device when there are n customers in the system (i.e., But, from the Forced Flow Law, Xi(n) = Vi x X0(n). Thus, In the database server example, this implies that the average number of customers at the CPU when there are three customers in the system is the simple product of the CPU's throughput (i.e., 3.1908 customers per minute, or 0.0532 customers per second) and its response time (i.e., 15.91 seconds) which yields 0.8462 customers. Similarly, the average number of customers at the fast disk when there are three customers in the system is 0.0266x21.26 = 0.5653 customers. At the slow disk, there are 0.0266 x 59.74 = 1.5885 customers. The development of the MVA iteration is now complete. Given the average number of customers at each device with n 1 customers in the system, the device residence times when there are n customers in the network can be derived. Knowing these residence times leads to the overall response time, which, in turn, leads to the system and individual device throughputs. The device throughputs lead to the device utilizations and to the average number of customers at each device with n customers in the system. Knowing these, the iteration continues to derive the performance metrics with n + 1 customers in the system, and, in general, to any desired number of customers ... all without formulating and solving any of the underlying steady state balance equations. Elegant! One small detail is the initialization of the iterative process. However, this is resolved by simply noting that when no customers are in the system, the average number of customers at each device is, likewise, zero. Thus, when n = 0, | ||||||||||||||||||||||||||||||||||||||
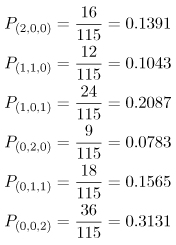
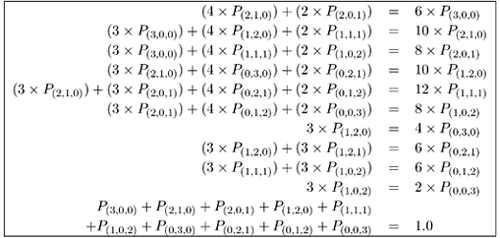
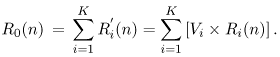
EAN: 2147483647
Pages: 166